Анна Филиппович
Исследование эффективности
системы оптического
распознавания текстов
Введение
Сегодня для ввода печатных
текстов широко используются программы класса «системы оптического распознавания
текстов» (OCR-системы — Optical Character Recognition). Эффективность
подобных программ зависит от нескольких факторов. Во-первых, это навыки оператора.
Системы данного класса имеют простой, интуитивно понятный интерфейс, поэтому
работать в них достаточно просто. Однако определение оптимальных настроек системы,
методика ввода, опыт оператора играет важную роль. Во-вторых, эффективность
работы OCR-систем зависит от характеристик текстового оригинала:
качества печати, разметки текста (верстки), шрифтовой гарнитуры, лексического
состава и т.д. А также от характеристик самой OCR-системы: набор и состав функций, настроек, алгоритма
распознавания и т.п. С учетом всех этих факторов тот или иной текст можно
ввести за определенный промежуток времени.
Для оценки эффективности OCR-системы необходимо учесть вышеуказанные факторы и
проанализировать современный рынок программ класса «Системы оптического
распознавания», рассмотреть технологический процесс ввода текста и наконец,
исследовать работу OCR-системы на примере различных
видов текстов.
Программы класса
«системы оптического распознавания текстов»
Основное назначение систем
оптического распознавания – это ввод текста для печатных и электронных изданий.
Существует большое количество современных систем подобного рода за рубежом.
Примерами могут служить следующие: Recognita
Plus DTK фирмы Recognita Corporation (Венгрия), TextBridge фирмы Xerox Imaging Systems, TypeReader фирмы ExperVision (США), СharacterEyes фирмы Ligature (Израиль), IRIS OCR фирмы I.R.I.S.
(Бельгия), Easy Reader фирмы Inovatic
International (Франция), OmniPage
Professional и WordScan Plus
фирмы Caera (США) [ЭР1, 12.2005]
Наиболее известными
программами класса «Системы оптического распознавания» в России являются: OCR CuneiForm [ЭР3, 12.2005]
-
Современный
интерфейс, панели быстрого доступа, мастер распознавания и сканирования,
контекстная помощь, уроки работы в программе.
-
Сканирование
с различных сканеров. Использование интерфейса TWAIN.
-
Импорт
и обработка изображений различных форматов.
-
Автоматическая,
ручная или полуавтоматическая, фрагментация изображений.
-
Распознавание
полиграфических и машинописных гарнитур за исключением декоративных.
-
Возможность
распознавания декоративных шрифтов с помощью обучения и создания эталонов.
-
Языковая
поддержка.
-
Словарный
контроль и возможность подключения и пополнения пользовательского словаря.
-
Поддержка
WYSIWYG.
-
Распознавание и редактирование таблиц.
-
Интеграция
с MS Word, MS Excel.
-
Пакетное
сканирование и возможность организации распределенного параллельного
сканирования в локальной сети.
Однако FineReader 8.0 –
более современная версия и имеет более широкие возможности. Так, например,
языковая поддержка включает 179 языков, для 36 предусмотрена проверка
орфографии. Это связано с развитием другой линии продуктов компании ABBYY – электронными словарями Lingvo.
Кроме этого программа
поддерживает больше форматов при импорте графических файлов (BMP, DCX, JPEG, PCX, PNG, TIFF, PDF), а также при экспорте. FineReader 8.0 позволяет экспортировать
результаты распознавания в популярные офисные приложения, такие как Microsoft PowerPoint,
Lotus Word Pro, Corel WordPerfect, Sun StarWriter.
Распознанный текст можно сохранить в следующих форматах: PDF, HTML, Microsoft Word XML, DOC, RTF, XLS, PPT, DBF, CSV,TXT и LIT.
Среди новых возможностей FineReader 8.0 отметим
следующие:
-
Распознавание
цифровых фотографий документов.
-
Дополнительные
возможности при работе с PDF-файлами.
-
Автоматическая
обработка документов.
-
Дополнительный
режим для распознавания файлов с простым оформлением.
Согласно всем этим данным
программа FineReader является более современной и обладает более широкими
возможностями, поэтому она была выбрана для дальнейших исследований
Технология ввода
текста с помощью
системы
оптического распознавания
Процесс ввода текста с
помощью системы оптического распознавания можно разделить на два этапа:
предварительный и основной (см. рис.1.). Первый включает в себя различные
предварительные процедуры, общее назначение которых настройка и подготовка
инструментальных средств для ввода текста и рабочего места оператора. В общем
случае этот этап может включать в себя следующие процедуры: установка и настройка
аппаратных и программных средств, подготовка текста для ввода, настройка
параметров системы оптического распознавания. Состав операций и процедур
предварительного этапа зависит от уже существующих настроек системы.
Установка и настройка
аппаратных средств может включать в себя следующие операции: установка,
включение ЭВМ, подключение сканера к ЭВМ, установка драйверов и ПО для сканера
и т.п. Для настройки параметров системы оптического распознавания необходимо проанализировать характеристики
вводимого текста: качество оригинала, язык, лексику и т.д., и в зависимости от
этого настроить параметры сканирования и распознавания. Кроме этого для
определения оптимальных настроек можно осуществить предварительный ввод
небольшого объема текста. В этом случае следует проанализировать качества ввода
и в зависимости от этого изменять настройки системы оптического распознавания.
Второй, основной этап – это
собственно вод текста, он включает в себя четыре последовательные процедуры:
сканирование; распознавание; корректура, проверка и исправление ошибок;
сохранение.
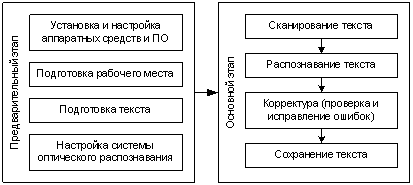
Рис. 1. Обобщенная схема технологического процесса ввода
текста с помощью системы оптического распознавания
В соответствии с этой
последовательностью организована работа в FineReader. На панели Scan&Read расположены кнопки последовательности действий (см.
рис.2). Последовательность действий циклически повторяется для каждой страницы
или ряда страниц.
![]()
![]()
![]()
![]()
Рис. 2. Панель Scan&Read.
Однако это наиболее общая
методика ввода текста. В зависимости от характеристик исходного текста какие-то
операции могут повторяться или быть исключены.
Сканирование текста
осуществляется с помощью специальной программы. Обычно она устанавливается с
драйверами для сканера и специально предназначена для работы с определенной
моделью сканера или целым модельным рядом. Например, для сканера Epson Perfection
2400 photo используется программа Epson Twain 5. Система
оптического распознавания обращается к этой программе. Однако сканирование
можно также осуществить в любом графическом редакторе. При этом выбирается
опция импорта со сканера и также вызывается программа, используемая для
сканирования.
При сканировании страницы
текста выполняется следующая последовательность операций:
1. Установка страницы в сканер;
2. Предварительное сканирование;
3. Выбор сканируемой области;
4. Анализ качества предварительного
сканирования;
5. Настройка параметров сканирования;
6. Сканирование выбранной области
(страницы) с заданными параметрами;
7. извлечение страницы из сканера.
Часто при сканировании все изображения страниц текста имеют
схожие характеристики, поэтому настройка параметров сканирования требуется
только вначале. Кроме этого, единство оформления и верстки издания в ряде
случаев позволяют исключить операции 2-4.
После сканирования текста осуществляется его распознавание.
При этом в FineReader возникает окно с изображением страницы, окно «текст» и окно
укрупненного изображения, которые впоследствии будут использованы при
корректуре.
В окне с изображением страницы следует выделить блоки для распознавания
или использовать автоматическое выделение блоков. Процедура распознавания
зависит от характеристик текста и его объема и выполняется автоматически.
При необходимости сохранения верстки для наилучшего результата
рекомендуется вручную выделять и редактировать элементы для распознавания.
Результат распознавания также зависит от настроек опций. Т.о. описывая
процедуру распознавания можно выделить две операции: 1) выделение блоков для
распознавания; 2) распознавание.
Проверка текста или корректура в большинстве случаев представляется
наиболее трудоемкой и зависит от навыков оператора. После распознавания текста
программа выделяет символы, форма которых вызвала сомнение при распознавании – неуверенно распознанные символы. Кроме
этого текст может проверяться на орфографические ошибки с помощью словаря
спеллера – несловарные слова. Программа
также позволяет откорректировать некоторые нарушения в наборе – пробелы после
знаков препинания.
Процесс корректуры аналогичен проверке текста с помощью словаря
спеллера, используемого в текстовых редакторах. В Fine Reader появляется стандартное окно проверки
(см. рис.3.), в котором последовательно рассматриваются все помеченные символы
и слова. Если встречается «несловарное слово», то программа предлагает варианты
исправления из слов словаря, отличных на один символ. Характеризуя процедуру корректуры,
можно выделить следующие операции: 1) сравнение проверяемого символа или слова;
2) исправление ошибки.
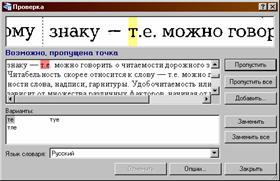
Рис. 3. Окно проверки ошибок.
После проверки текста
осуществляется его сохранение. При этом в FineReader предлагается передать текст в текстовый редактор (Microsoft Word) или
другую программу. Данная процедура может только включать в себя операции по
выбору параметром сохранения или передачи.
Оценка
эффективности
Определяющим параметром
эффективности работы системы оптического распознавания является время,
затрачиваемое на ввод текста – T. Чтобы оценить временные затраты проанализируем этапы
технологического процесса ввода информации, подробно рассмотренного в предыдущем
параграфе. Временные затраты на различные этапы, процедуры и операции на
порядок отличаются друг от друга, поэтому при оценке их эффективности
технологическая схема упрощена. Некоторые операции подробно не
рассматриваются.
Технология ввода текста
включает два этапа: предварительный и основной. Тогда:
Т = Тпред. этапа + Тосн. этапа
Предварительный этап
технологического процесса зависит от текущих настроек системы. Поэтому временные
затраты на его выполнение в зависимости
от процедур выполняемых на этом этапе могут быть различными. Так, если на
предварительном этапе необходимо установить все аппаратное и программное обеспечение,
необходимое для ввода текста, то этот временные затраты на это могут составить
от нескольких часов до суток. В другом случае, если на предварительном этапе необходимо
только запустить систему оптического распознавания, и настроить опции
распознавания и проверки, которые заранее определены, то на это потребуется
несколько минут. Кроме этого, непосредственный ввод текста осуществляется в основном
этапе, поэтому он является показательным. Исходя из этого, предварительный этап
технологического процесса ввода текста исключается из рассмотрения.
Т = Тосн. этапа.
На основном этапе при вводе
текста выполняются: сканирование, распознавание, корректура и сохранение
текста.
Тосн. этапа = Тскан. + Tрасп. +Tкор. + Tсохр.
Данные операции
выполняются для всех страниц текста.
![]()