
CLAIM – научно-образовательный кластер
Внимание! Некоторые математические знаки могут отображаться неправильно в браузерах, отличных от IE 5.0 и выше.
Филиппович Андрей
Принципы взаимных
функциональных зависимостей
Содержание
3. Взаимные функциональные зависимости.
1. Введение.
В настоящее время базы данных являются частью практически любой информационной системы. Современные БД характеризуются большой размерностью и сложной структурой, поэтому для их разработки используются специальные программные средства. Они позволяют не только упростить и ускорить процесс проектирования, но и выполнять некоторые функции по оптимизации БД. Наиболее популярным является подход, в котором осуществляется нормализация.
Теория нормализации (зависимостей) появилась одновременно с теорией реляционной алгебры. Коддом были предложены первые нормальные формы. Впоследствии, третья нормальная форма была уточнена и названа нормальной формой Бойса-Кодда (НФБК). Позже Фэйджином (Fagin) были предложены 4 и 5 нормальная формы, а также альтернативная доменно-ключевая нормальная форма [3, 23]. Существуют и другие нормальные формы, но наиболее популярными являются 3НФ и НФБК.
В основе теории нормализации лежат различные понятия зависимостей между атрибутами БД. В теории Кодда используется понятие функциональной зависимости (ФЗ), реляционный аналог математической функции. Рассмотрение основных вопросов статьи требует четкого определения понятия ФЗ, поэтом приведем формальное определение ФЗ из 6-ого издания книги Дейта [4]. Отметим сразу, что статья ориентирована на читателя, знакомого с основными понятиями реляционной алгебры и теории нормализации.
Пусть R — это отношение, а X и Y — произвольные подмножества множества атрибутов отношения R. Тогда Y функционально зависимо от X (X® Y), тогда и только тогда, когда каждое значение множества X отношения R связано в точности с одним значением множества Y отношения R. Иначе говоря, если два кортежа отношения совпадают по X [t1(X) = t2(X)], то они также совпадают и по Y [t1(Y) = t2(Y)].
X® Y у [t1(X) = t2(X)] => [t1(Y) = t2(Y)]
Проектирование схемы базы данных начинается с определения универсального отношения, в которое входят все атрибуты. Для предметной области задается множество ограничений с помощью функциональных, многозначных и других зависимостей. Для вывода новых ФЗ или сокращения их числа используются правила Армстронга. Однако, свободно применять правила Армстронга можно только для проектируемой БД, не имеющей данных [14].
Это замечание существенно для баз данных с динамически изменяемой структурой, к которым можно отнести современные объектно-реляционные разработки. Функциональные зависимости являются одними из простейших семантических ограничений, поэтому можно смело утверждать, что все рассматриваемые вопросы будут актуальны и для объектных СУБД.
Приведение отношений в 3НФ и НФБК направлено на избавление от транзитивных зависимостей (A® B, B® C => A® C). 3НФ позволяет удалить транзитивные зависимости с использованием неключевых атрибутов. В НФБК запрещаются транзитивные зависимости среди ключевых атрибутов.
Наиболее наглядное и простое определение 3НФ и НФБК дает Заниоло [26].
Пусть R – набор атрибутов, X Н R, A О R, F – множество функциональных зависимостей, К – ключ отношения. Отношение R находится в 3НФ, если для любой нетривиальной ФЗ (X® A)О F соблюдается одно из условий приведенных ниже. Отношение находится в НФБК если соблюдаются только первое условие.
1) K Н X , 2) A О K
Для проектирования отношений с использованием ФЗ наиболее часто используют алгоритмы декомпозиции и синтеза. Одним из самых простых алгоритмов синтеза предложен Ульманом [19]:
1. Получение неприводимого (нередуцируемого) справа покрытия ФЗ. Для этого используется правило декомпозиции Армстронга. В результате каждая ФЗ имеет в правой части только один атрибут.
" (X® A) (X Н R, A О R)
2. Получение неизбыточного покрытия. ФЗ исключается из покрытия, если для нее соблюдается следующее условие:
(F–{X® A})+=F+ => F= F–{X® A}
3. Получение неприводимого (нередуцируемого) слева покрытия ФЗ. Для этого каждая ФЗ проверяется на возможность удаления атрибутов из левой части без изменения замыкания покрытия.
" (X® A), " (B Н X) AО (X-B)+ => (X-B)® A
4. Декомпозиция отношения. Для обеспечения свойства сохранения зависимостей отношение декомпозируется на отношения, содержащие охват (все атрибуты) каждой из ФЗ. Количество отношений равняется количеству ФЗ.
Для обеспечения свойства соединения без потерь в схеме базы данных должно присутствовать отношение, содержащие ключ для всего отношения. Если оно отсутствует, то необходимо его добавить.
Первые три пункта алгоритма требуются для нахождения минимального покрытия (в терминологии Ульмана), т.е. набор ФЗ должен быть неизбыточным, неприводимым (слева и справа) и содержать в правой части каждой ФЗ только один атрибут.
Можно заметить, что алгоритм нахождения минимального покрытия Ульмана не работает в следующем случае:
F = { AB® C, A® B, C® B }
Если полностью выполнить первые 3 этапа алгоритма, то получим следующее покрытие:
F = { A® C, A® B, C® B }
Полученное покрытие является избыточным, т.к. из него можно исключить транзитивную ФЗ A® B. Чтобы преодолеть этот недостаток следует после выполнения третьего этапа еще раз выполнить второй этап или сначала выполнить 3-ий этап, а потом — 2-ой.
Еще одним недостатком алгоритма Ульмана является порождение схемы базы данных с избыточным количеством отношений. Например, для набора ФЗ (A® B, A® C, A® D) будет порождено три отношения (AB, AC, AD) с одинаковым ключом A. Причиной избыточности отношений является избыточность ФЗ в покрытии. Минимальное покрытие по терминологии Ульмана предпочтительней называть каноническим (по терминологии Мейера). Под минимальным набором ФЗ следует понимать эквивалентное каноническое покрытие, которое содержит наименьшее количество ФЗ.
Пример 1.1.
F=(A® B, A® C, A® D), G=(A® BCD), F=G
F — каноническое покрытие; G — минимальное покрытие.
2. Проблемы 3НФ и НФБК.
Рассмотрим пример приведения отношения в третью нормальную форму, предложенный Ульманом[19] и проблемы, которые при этом возникают. Пусть Задана схема отношения R и множество функциональных зависимостей F. Звездочкой (*) помечены функциональные зависимости, которые отсутствуют в указанном примере.
R = (A, B, C, D, E, T), где A – читаемый курс, B – преподаватель,
C – час начала занятий, D – аудитория, E – студент, T – оценка по курсу.
F = {CD® B, CD® A, AC® D, CE® A, A® B, CB® D, AE® T, CE® D}
A® B — каждый курс ведет один преподаватель;
CD® A — в аудитории в один и тот же момент времени может читаться только один курс;
CB® D — преподаватель в один и тот же момент времени может находиться только в одной аудитории;
CE® D — студент в один и тот же момент времени может находиться только в одной аудитории
AE® T — по каждому курсу каждый студент имеет только одну оценку;
AC® D* — каждый курс в один и тот же момент времени может читаться только в одной аудитории;
CD® B*— в аудитории в один и тот же момент времени может быть один преподаватель;
CE® A* — каждый студент в один и тот же момент времени может слушать только один курс;
Для приведения схемы отношения в 3НФ необходимо найти минимальное (по терминологии Ульмана) покрытие множества функциональных зависимостей. В описываемом примере оно будет представлено следующим образом:
F = {A® B, CD® A, CB® D, AE® T, CE® D}
Далее, осуществим декомпозицию схемы отношения:
r ={AB, CDA, CBD, AET, CED}, K=CE
Данная схема находится в НФБК и декомпозируется из исходной схемы с сохранением зависимостей. Недостатком этой декомпозиции является зависимость проекций (по терминологии Риссанена [4, 24]). Отсюда следует, что схема может обладать аномалиями. Проиллюстрируем это на примере:
| С* | D* | A |
| 10 | 12 | Базы Данных |
| 10 | 13 | Опер. сист. |
| A* | B |
| Базы Данных | Иванов |
| Опер. сист. | Петров |
| С* | B* | D |
| 10 | Иванов | 12 |
| 10 | Петров | 12 |
Рис.1. Противоречивость БД.
На рис.1. представлены три таблицы из полученной схемы отношений. Звездочками отмечены ключевые поля. Пусть в БД хранится информация, что в 10 часов в 12 и 13 аудиториях должны читаться курсы "Базы данных" и "Операционные системы" (CDA). Известно, что эти курсы читают соответственно преподаватели Иванов и Петров (AB). При этом оба преподавателя должны проводить занятия одновременно в одной аудитории (CBD). Данная информация является противоречивой, несмотря на то, что схема отношений находится в НФБК и все ФЗ соблюдены.
Представим теперь, что D — это номер посадочной полосы самолетов с номером рейса из B. По условиям, заданным набором ФЗ такая ситуация невозможна. И тем не менее, в БД, находящейся в НФБК с "сохранением" зависимостей содержится неутешительный приговор двум самолетам.
Рассмотрим другой случай. Пусть D — это сумма в размере 120000$ и ее нужно перечислить только на счет Иванова. Как видно из рис.1. эту сумму может также получить и Петров, а также десятки других сотрудников и это не будет противоречить структуре БД.
Из примера видно, что приведение отношения в 3НФ или даже в НФБК с помощью декомпозиции не решает все проблемы противоречивости хранимых данных. Если произвести естественное соединение всех отношений, то аномальные данные пропадут. Производить соединение всех таблиц базы данных после каждого изменения слишком трудоемко и неэффективно. Для обеспечения целостности связанных данных используют специальные средства: внешние ключи, представления, ограничения на целостность, триггеры и т.д. Существует необходимость выявления и устранения описанных недостатков.
3. Взаимные функциональные зависимости.
Этот параграф посвящен вопросу обнаружения и устранения ошибок, связанных с тем, что во множестве ФЗ имеются взаимные функциональные зависимости (ВФЗ).
3.1. Определения и способы задания ВФЗ.
Определение 1. Взаимной функциональной зависимостью атрибутов A и B называется пара функциональных зависимостей вида B® A, A® B и обозначается как A« B.
Рассмотрим основное свойство ВФЗ. Из функциональной зависимости A® B вытекает утверждение 1. Кроме того, в отношении может существовать множество кортежей с разными значениями в атрибуте А и одинаковыми значениями в атрибуте B (утверждение 2):
(1) A® B у [ti(A) = tj(A)] => [ti(B) = tj(B)]
(2) [" ti(B)] $ {t(A)} , |{t(A)}|і 1
Аналогично определим соотношения для ФЗ B® A:
(3) B® A у [ti(B) = tj(B)] => [ti(A) = tj(A)]
(4) [" ti(A)] $ {t(B)} , |{t(B)}|і 1
Соединяя условия (1), (4) и (2), (3) получаем следующие утверждения:
(5) [" ti(A)] $ {t(B)} , |{t(B)}|=1
(6) [" ti(B)] $ {t(A)} , |{t(A)}|=1
Основным свойством ВФЗ является взаимная однозначность значений для атрибутов левой и правой части, т.е. каждый кортеж должен иметь уникальные значения полей, входящих во ВФЗ.
Для задания ВФЗ в СУБД необходимо атрибуты A и B объединить в одном отношении (таблице) и задать уникальность каждого атрибута. Если части ВФЗ содержат более одного атрибута, то можно использовать первичный и альтернативный ключ (с обязательным заданием уникальности). Надо отметить, что алгоритмы нахождения минимального покрытия Мейера [11] и Бернштейна [21] учитывают ВФЗ, и используют их для сокращения размера покрытия.
Определение 2. Условной взаимной функциональной зависимостью атрибутов A и B называется пара функциональных зависимостей вида СB® A, СA® B, где С — набор атрибутов (условие) такой, что Сщ ® AB. Будем обозначать УВФЗ как С|A« B, при этом C будем называть условием, а A« B — основой УВФЗ.
Смысл УВФЗ заключается в том, что при определенных условиях атрибуты основы находятся во взаимной функциональной зависимости. Из функциональной зависимости CA® B вытекает утверждение 7 и 8:
(7) CA® B у [ti(C) = tj(C)]&[ti(A) = tj(A)] => [ti(B) = tj(B)]
(8) [" ti(B)] $ {t(СA)} , |{t(СA)}|і 1
Аналогично определим соотношения для ФЗ СB® A:
(9) СB® A у [ti(C) = tj(C)]&[ti(B) = tj(B)] => [ti(A) = tj(A)]
(10) [" ti(A)] $ {t(СB)} , |{t(СB)}|і 1
Соединяя условия (7-10) и фиксируя значение атрибута С, получаем следующие утверждения:
(11) [" ti(A)] $ {t(B)} , |{t(B)}|=1
(12) [" ti(B)] $ {t(A)} , |{t(A)}|=1
Основным свойством УВФЗ является взаимная однозначность значений для атрибутов основы при совпадении значений в атрибутах условия, т.е. для каждого значения атрибутов условия кортеж должен иметь уникальные значения атрибутов основы.
Существует несколько способов задать УВФЗ. Можно ввести понятие условного ключа или условной уникальности. Проиллюстрируем эти понятия. Пусть имеется условная взаимная зависимость (УВФЗ) такая, что условием является набор атрибутов C, атрибуты B и D входят во ВФЗ. Тогда при фиксированном значении атрибутов из С значения атрибутов B и D являются уникальными. Для пояснения приведем пример:
| С (Час начала занятий) | B (Преподаватель) | D (Аудитория)> |
| С1 | B (Преподаватель)* | D (Аудитория)* |
| С1 (10:00) | Петров | 1426 |
| С1 (10:00) | Иванов | 1427 |
| С1 (10:00) | Соколов | 1425 |
| С2 | B (Преподаватель)* | D (Аудитория)* |
| С2 (11:40) | Петров | 1426 |
| С2 (11:40) | Соколов | 1425 |
Ограничение можно реализовать либо программным способом, либо декомпозицией отношений и дополнительных изменений схемы.
К первому способу можно отнести возможность работы с представлениями (запросами на отображение). Если реализовать ввод данных только через представление, тогда оно должно содержать выборку по одному из значений условных атрибутов (например С1), а взаимозависимые атрибуты должны иметь уникальный ключ.
CREATE VIEW UslFD AS
SELECT Pse1.*
FROM table1 AS Pse1, table1 AS Pse2
WHERE (Pse1.C= Pse2.C) & (Pse1.A<> Pse2.A) & (Pse1.B<> Pse2.B)
При наборе условных атрибутов (C1,.. Cn) конструкция Where изменится:
WHERE (Pse1.C1= Pse2.C1) &(Pse1.C2= Pse2.C2) &…& (Pse1.Cn= Pse2.Cn)
& (Pse1.A<> Pse2.A) & (Pse1.B<> Pse2.B)
Альтернативой может послужить общее ограничения на целостность БД.
CREATE ASSERTION UslFD CHECK (
SELECT Pse1.*
FROM table1 AS Pse1, table1 AS Pse2
WHERE (Pse1.C= Pse2.C) & (Pse1.A<> Pse2.A) & (Pse1.B<> Pse2.B) )
Вторым способом задания ограничений является соответствующая организация структуры БД (схемы). Реализовать ограничение в одном отношении можно путем задания двух ключей (первичного и альтернативного) со свойством уникальности. Можно также осуществить декомпозицию с использованием внешних ключей.
3.2. Аксиомы и правила преобразования ВФЗ.
Утверждение 1. Любая УВФЗ может быть преобразована во ВФЗ по правилу (C| A « B у CA « CB). Таким образом, УВФЗ может рассматриваться как частный случай ВФЗ. С другой стороны ВФЗ можно считать частным случаем УВФЗ с пустым условием.
Утверждение позволяет рассматривать ВФЗ и УВФЗ как эквивалентные понятия и применять существующие подходы и алгоритмы для их поиска. В определении УВФЗ на атрибуты условия накладываются ограничение (Сщ ® AB). Если его ослабить, то можно получить вырожденные УВФЗ:
CA® B у CA| A« B
С® AB у C| A« B
Утверждение 2. Набору ВФЗ всегда соответствует множество ФЗ. Следовательно, на основании аксиом Армстронга для ФЗ можно сформулировать аксиомы для преобразования ВФЗ и УВФЗ.
А1. Рефлексивность и самоопределение. Аксиома рефлексивности для ВФЗ вырождается в аксиому самоопределения. Для УФВЗ может существовать рефлесивность условия и атрибутов основы. Сформулируем правила рефлексивности для атрибутов основы.
BН A, AН B => A=B => B« A
A« B, BМ M, A® M => M« A
C| A« B, BМ M, CA® M, Cщ ® M => C| M« B
Аксиому рефлексивности условия можно сформулировать следующим образом: более простые УВФЗ порождают более сложные. Если имеется две УВФЗ такие, что множество условных атрибутов одной зависимости входит во множество условных атрибутов другой зависимости, то такая УВФЗ является более простой:
C|A« B, CН D, Dщ ® AB => D|A« B
А2. Дополнение. Правило дополнения условия для УВФЗ аналогично правилу рефлексивности, поэтому рассмотрим только правила преобразования основы.
A« B => AC« BC
C|A« B, Cщ ® D => C|AD« BD
А3. Транзитивность.
A« B, B« C => A« C => A« B« C
C|A« B, E|B« D => CE|A« D => CE|A« B« D
А4. Декомпозиция.
A« BС, B® A, C® A => A« B, A« С
D|A« BС, DB® A, DC® A => D|A« B, D|A« С
A5. Объединение.
A« B, A« С => A« BС
D|A« B, E|A« С, DEщ ® AB => DE|A« BС
A6. Композиция.
A« B, C« D => AC« BD (AD« BC)
E| A« B, F| C« D, DEщ ® ABCD => EF|AC« BD (EF|AD« BC)
Далее сформулируем несколько дополнительных правил, которые могут быть использованы для преобразования УВФЗ.
R1. Перемещение атрибутов. Атрибуты условия в УВФЗ можно перемещать в основу. При этом они должны быть перемещены в обе части основы. Обратное утверждение также верно: если в обеих частях основы УВФЗ или ВФЗ имеются общие атрибуты, то их можно переместить в условие.
CD| A« B у C|DA« DB (Dщ ® AB)
R2. Удаление атрибутов. Если в основе имеется подмножество атрибутов, которое функционально зависит от условия, то его можно удалить.
C| AD« B, C® D => C| A« B
Доказательство: Преобразуем УВФЗ к множеству ФЗ:
C| AD« B у {CAD® B, CB® AD}у {CAD® B, CB® A, CB® D}
Добавим к полученному множеству ФЗ C® D и приведем к каноническому или минимальному покрытию (редуцированному и неизбыточному)
{CAD® B, CB® A, CB® D, C® D}= {CA® B, CB® A, C® D}
В минимальном покрытии выделим УВФЗ C| A« B.
R3. Замена атрибутов. Если в множестве ФЗ существует УВФЗ C| A« B, то во всех функциональных зависимостях, в которых присутствует набор условных атрибутов С можно заменить A на B или наоборот.
Рассмотрим преобразования для примера 2.1:
F = {CD® B, AC® D, CE® A, A® B, CD® A, CB® D, AE® T, CE® D}
CD® B & CB® D => B® D & D® B => C| D« B
Выберем все зависимости, в которых присутствует C
CD® B, AC® D, CE® A, CD® A, CB® D, CE® D
Заменим B на D и получим.
CD® D, AC® D, CE® A, CD® A, CD® D, CE® D
Сократим одинаковые зависимости (CD® D).
Полученная зависимость CD® D исключается как тривиальная.
AC® D, CE® A, CD® A, CE® D, C| D« B
Аналогично поступаем с AC® D и CD® A
CE® A, C| A« D« B
Итоговое множество функциональных зависимостей будет выглядеть следующим образом:
F = { A® B, AE® T, CE® A, C| A« D« B}
Аналогичное правило преобразования ВФЗ предложил в своей работе Мейер[11] для получения минимального покрытия.
Если в наборе ФЗ имеется ВФЗ X« Y и присутствует две зависимости X® U, Y® V, то их можно заменить на одну ФЗ X® VU или Y® VU. Для применения этого правила необходимо ввести дополнительное ограничение, не упомянутое автором. Если множества (X и V) или (Y и U) имеют общие атрибуты, то полученная зависимость X® VU (Y® VU) будет иметь посторонние (избыточные атрибуты). Изменим правило следующим образом:
{X« Y, X® U, Y® V} => { X« Y, X® (VU-X)} или { X« Y, Y® (VU-Y)}
Алгоритм приведения отношения в 3НФ Мейера обладает рядом недостатков, т.к. ограничивает использование вышеупомянутого правила и не учитывает УВФЗ. Алгоритм Бернштейна использует схожие принципы для построения отношений, но обладает почти теми же недостатками.
R5. Некоторые группы УВФЗ можно исключить или заменить на одну ВФЗ. Сокращение количества ВФЗ облегчает затраты на их задание с помощью ключей или программных ограничений. Приведем несколько примеров:
A|C« B, B|A« C, C® AB можно заменить на AB« C
BD|A« C, BC|A« D, AC|B« D, AD|B« C, AB® CD, CD® AB можно заменить на AB« CD.
3.3. Выявление ВФЗ.
Причиной возникновения ВФЗ является наличие циклической структуры в наборе ФЗ. Одним из способов обнаружения ВФЗ является графическое отображение ФЗ и поиск кольцевых структур.
На рис.2.а показаны функциональные зависимости в графической форме. Можно заметить, что функциональные зависимости пересекаются, и, кроме того, образуют циклическую структуру. Воспользовавшись правилом дополнения Армстронга, получаем схему, представленную на рис.2.б. Функциональная зависимость B® A представлена отдельно и атрибут B в ней не зависит от CA, т.к. зависимость была разделена на B® A при наличии C и на B® A при отсутствии C. На рис.2.в. представлено выделение взаимной зависимости A и B при условии С.
Пример 3.1. CA® B, B® A (C| B« A)
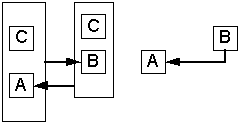
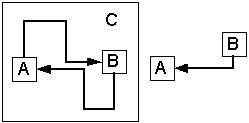
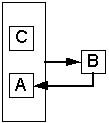
а) б) в)
Рисунок 2. Графическое выявление ВФЗ
Нахождение канонического (минимального) покрытия ФЗ не убирает и не изменяет ВФЗ, однако может усложнить их поиск. На рисунке 3 рассматривается процесс нахождения УВФЗ для минимального (канонического) покрытия ФЗ из примера 2.1. В результате нахождения минимального покрытия ВФЗ становятся менее очевидными из-за увеличения элементов в цикле. Взаимные зависимости становятся транзитивными.
Определение 3. ВФЗ (УВФЗ) называются n-местными (n >1), если существует ВФЗ между n множествами атрибутов (основы УВФЗ с общим условием).
Например, C| D« B« A — трехместная УВФЗ.
Мейер в своей работе [11] вводит понятие вырожденной составной ФЗ (CF-зависимости). Если использовать эту терминологию, то рассмотренная зависимость будет иметь следующий вид: (CD, СB, СA) ® Ж . В работе [25] рассматривается проблема двухместных УВФЗ и предлагается специальный способ их графического отображения. К сожалению, этот подход не эффективен для более сложных УВФЗ.
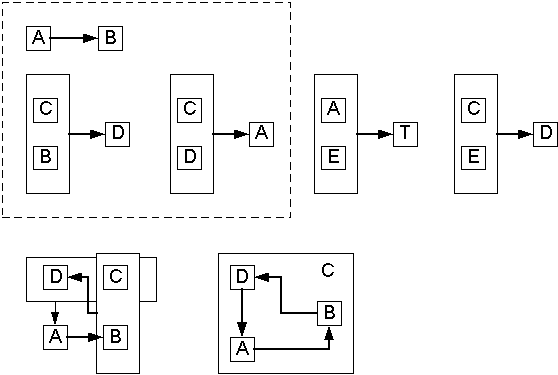
Рис.3. Поиск УВФЗ для минимального покрытия.
Нахождение минимального покрытия ФЗ в общем случае усложняет процесс нахождения ВФЗ за счет уменьшения числа зависимостей. Тем не менее, нахождение минимального покрытия необходимо для получения 3НФ, а некоторые ВФЗ могут быть исходно неочевидны и для их выявления требуется использовать специальные алгоритмы.
Сформулируем условия существования ВФЗ в аналитическом виде.
Теорема 1. Если в наборе нетривиальных ФЗ F={Xi® Yi} существует 2 ФЗ вида CA® B, DB® A и CDщ ® AB то существует УВФЗ вида CD| A« B.
Доказательство:
CA® B => CDA® B, DB® A=> CDB® A
{CDA® B, CDB® A, CDщ ® AB} => CD| A« B
Теорема 2.1. Пусть задано множество ФЗ F={Xi® Yi }. Если для двух ФЗ справедливо выражение Xi Н (Xj)+ и Xj Н (Xi)+, то существует ВФЗ Xi « Xj
Теорема 2.2. Пусть задано множество ФЗ F={Xi® Yi}. Если для двух ФЗ существует M Н Xi и N Н Xj и выполняется M Н (Xj)+ , N Н (Xi)+, XiXj-MNщ ® MN, то существует УВФЗ XiXj-MN| M « N
Доказательство:
1. Все атрибуты, входящие в замыкание множества атрибутов, функционально зависят от него:
M Н (Xj)+ => Xj ® M, N Н (Xi)+ => Xi ® N
2. Введем множества атрибутов C1 и C2
C1= Xi-M, C2= Xj-N => Xi = C1 M, Xj = C2N
3. Подставим (2) в (1) и получим:
C1 M® Nj , C2N® M
4. добавим ограничительное условие и согласно теореме 1 получим:
C1 M® Nj , C2N® M, C1C2щ ® MN => C1C2| M « N
Пример 3.2
F={CB® A, CA® K, K® M, LM® D, D® B}
(LM)+=LMDB; (CB)+=CBAKM; (CL)+=CL
BО (LM)+, MО (CB)+, CLщ ® BM => CL| M « B
К сожалению, теорема 2.2. не позволяет найти все УВФЗ.
Пример 3.3
F={CB® A, CA® K, K® M, LM® D, RD® B}
(LM)+=LMD; (CB)+=CBAKM; BП (LM)+, MО (CB)+
Однако, (LMR)+=LMRDB, (CLR)+=CLR
BП (LMR)+, MО (CB)+, CLRщ ® BM => CLR| M « B
Теорема 2.1. является частным случаем теоремы 2.2. и позволяет найти для минимального покрытия все ВФЗ, не имеющие одинаковых атрибутов в обеих частях зависимости. Из теоремы 2.2. вытекают следствия, которые могут быть использованы для поиска ВФЗ.
Следствие 1. Если два множества атрибутов имеют одинаковое замыкание, то между ними существует ВФЗ. Например, все минимальные ключи отношения находятся во ВФЗ и ни один из них нельзя исключать как эквивалентный.
Следствие 2. Для нахождения множеств M и N из теоремы 2.2. можно воспользоваться следующими правилами:
M= Xi З (Xj)+; N= Xj З (Xi)+
Следствие 3. УВФЗ между множествами атрибутов Xj и Xi существует тогда и только тогда, когда при пересечении их замыканий образуется множество, состоящее как минимум из двух атрибутов:
| (Xj)+ З(Xi)+ | і 2
Следствие 4. В качестве основы простых УВФЗ могут выступать только те атрибуты, которые встречаются одновременно в левой и правой частях множества ФЗ (LP). Атрибутами условия могут являться множества, которые встречаются только в качестве детерминанты (L) или принадлежат множеству LP.
![]()
Если количество атрибутов в множествах LP и L равно соответственно m и k, то максимальная размерность условия не превышает значения m+k-2. Согласно данным [22] соотношение (LP +L)/P обычно находится в диапазоне от 5 до 50. Это позволяет значительно сократить количество переборов в алгоритмах поиска УВФЗ.
Теорема 2.3. Пусть задано множество ФЗ F={Xi® Yi}. Если для двух наборов атрибутов Xi и Xj справедливы утверждения:
Xi З (Xj)+ =M № Ж , Xj З (Xi)+ =N№ Ж при условии XiXj-MNщ ® MN
то существует УВФЗ XiXj-MN| M « N
Алгоритм нахождения УВФЗ.
Ниже приводится алгоритм нахождения ВФЗ для канонического покрытия, имеющего в правой части каждой ФЗ один атрибут. Алгоритм можно также применять для произвольного множества ФЗ, но в случае канонического покрытия ВФЗ будут находится только один раз.
Пусть задана схема отношений R и множество ФЗ S такие что:
S ={ X[1]® Y[1]… X[i]® Y[i]… X[n]® Y[n]}, где n — количество ФЗ
Y[i]О R, X[i]Н R , т.е. Y является атрибутом, а X — набором атрибутов из R.
X[i]= {X[i][1]… X[i][j]… X[i][m]}, где m — Количество атрибутов в левой части ФЗ. Для разных ФЗ m может изменяться.
for i:=1 to n do // цикл по всем ФЗ
{ m:=m(X[i]); // подсчет количества атрибутов в левой части
for j:=1 to m do // цикл по всем атрибутам
{Left_Part:= X[i][j]; // выбор одного из атрибутов
for k:=1 to n do // цикл по всем ФЗ
// если условие выполняется, то возможно наличие кольцевой структуры
{if Left_Part == Y[k] then
//функция проверяет множество S на наличие ВФЗ
//между X[i][j] и Y[i] при условии X[i]- X[i][j]
call function_1(Left_Part, Y[i], X[i]- X[i][j]);
Restore S, n; //восстановление полного списка ФЗ
}
}
}
//функция проверяет множество S на наличие ВФЗ
//между Left_Part и Right_Part при условии Usl
function_1(Left_Part, Right_Part, Usl)
for i:=1 to n do // цикл по всем ФЗ
{ if (Right_Part Н X[i]) then //если правый атрибут входит
// в левую часть какой-либо ФЗ
{
Usl:=Usl+ X[i] - Right_Part; // то условие дополняется другими
//атрибутами из левой части
if (Left_Part == Y[i]) then //если произошло закольцевание
{ Add "Usl | Left_Part « Right_Part" //добавляется новая УВФЗ
delete X[i]® Y[i]; //данная ФЗ удаляется из S
n:=n-1; //количество ФЗ уменьшается
}
else
//иначе осуществляется рекурсивный вызов для дальнейшего поиска
{
Right_Part := Y[i];
delete X[i]® Y[i]; //данная ФЗ удаляется из S
n:=n-1; //количество ФЗ уменьшается
function_1(Left_Part, Right_Part, Usl);
}
}
}
После работы алгоритма необходимо исключить все вырожденные УВФЗ. Алгоритм является схематичным и неоптимизированным, т.к. при нахождении ВФЗ не осуществляется изменение (уменьшение) множества исходных ФЗ. Кроме того, алгоритм не позволяет построить УВФЗ, содержащие в основе двухэлементные ( и более размерные) множества атрибутов.
Согласно следствиям 1-4 можно предложить следующие усовершенствования алгоритма:
1. Заранее исключить зависимости, содержащие атрибуты множества P.
2. Исключить из рассмотрения в качестве основы УВФЗ атрибуты множества L.
3. При нахождении канонического покрытия сохранять в памяти замыкания множеств атрибутов.
4. Исключить варианты, когда условие содержит ключи отношения.
5. Проверять атрибуты основы на ФЗ от атрибутов условия.
6. Исключить из рассмотрения варианты, когда пересечение замыкания двух множеств имеют менее 2 атрибутов.
4. Заключение.
В заключении сформулируем основные выводы к статье и некоторые замечания.
1. Нахождение и задание ВФЗ позволяет избавиться от противоречивости хранимой информации в БД.
2. Одним из способов учета ВФЗ является наложение ограничений на целостность БД. Для этого введем понятие "целостности по взаимозависимости".
3. Вторым способ учета ВФЗ является нормализация отношений, т.е. приведение БД к соответствующей структуре (схеме). Введем понятие взаимно-независимой нормальной формы, если схема отношений не имеет ВФЗ. ВННФ можно рассматривать как синоним понятия ациклической БД.
4. Приведение отношения к ВННФ можно осуществлять независимо от приведения отношения в 3НФ, НФБК. Рекомендуется выявлять ВФЗ на этапе нахождения минимального покрытия.
5. Для многозначных зависимостей также существуют проблемы взаимности (взаимной независимости). Эти вопросы рассматриваются в работе [20].
6. Вероятность появления УВФЗ (циклической структуры ФЗ) достаточна велика. При проектировании схемы БД часто забывают определять УВФЗ. Это наглядно иллюстрирует пример 2.1. Причиной этого является особенности человеческого мышления и общения. Например, никогда не говорят, что "Петров сейчас один в аудитории, сейчас в аудитории только Петров", т.к. одно утверждение вытекает из другого.
7. Автор не считает, что вопросы, затронутые в этой работе являются научной новизной. Более того, автор уверен, что за такой продолжительный срок существования теории баз данных и теории нормализации, проблемы ВФЗ были затронуты, а может, и решены. К сожалению, из всех современных отечественных книг по БД, только в книге Мейера затрагивается этот вопрос, несмотря на его первостепенную важность. Автор осуществлял поиск и просмотрел большое количество литературы. На поиск аналогичных разработок было потрачено время, в во много раз превышающее теоретическую разработку проблемы ВФЗ. "Если теорему проще доказать, чем найти описание доказательства, то почему это не сделать?".
Автор пытается акцентировать внимание на вопросах ВФЗ. Если читатель имеет какую-либо информацию по данному вопросу, а также возражения, замечания или дополнения, просьба сообщить об этом через форум или по электронной почте.
Литература:
Арсеньев Б.П., Яковлев С.А. Интеграция распределенных БД, СПб, Лань, 2001, - 464 с. Теория нормализации (стр. 37-41). |
|
Вербовецкий А.А. Основы проектирования баз данных., Радио и связь, 2000, - 88 с. Теория нормализации (стр. 25-28). |
|
Голосов А.О. Аномалии в реляционных базах данных. Журнал СУБД, выпуск 1.06.1996. |
|
Дейт К.Дж. Введение в системы баз данных, 6-е издание. К., М., СПб.: Издательский дом "Вильямс", 2000. — 848 с. Теория нормализации (стр. 269-347). Одна из наиболее полных книг на русском языке. Затрагиваются вопросы атомарных отношений и ДКНФ. В 7-ом издании более подробно рассматриваются вопросы 4 и 5НФ. |
|
Дунаев С. Доступ к БД и техника работы в сети. М., Диалог-МИФИ, 2000, - 416 с. |
|
Калиниченко Л.А. Методы и средства интеграции неоднородных баз данных. М.: Наука, 1983 — 424 с. |
|
Карпова Т. Базы данных, модели, разработка, реализация, СПб., Питер, 2001, - 304 с. Теория нормализации (стр. 110-120). 1-5НФ, очень кратко. |
|
Коннолли Т., Бегг К., Страчан А. Базы данных. Проектирование, реализация и сопровождение. Теория и практика, 2-е изд., М.:"Вильямс", 2000, - 1120 с. Теория нормализации (стр. 222-258). 1-5НФ, очень кратко, в основном, примеры. |
|
Корнеев В.В., Гареев А.Ф., Васютин С.В., Райх В.В. Базы данных. Интеллектуальная обработка информации. М.: "Нолидж". – 352 с. |
|
10. Кульба В.В., Ковалевский С.С., Каяченко С.А., Сиротюк В.О. |
Кульба В.В., Ковалевский С.С., Каяченко С.А., Сиротюк В.О. Теоретические основы проектирования оптимальных структур распределенных БД., М., Синтег, 1999, 660 с. Теория нормализации (стр. 116-124). 1-3НФ, Формальное описание осуществлено в терминах книги. |
Мейер Д. Теория реляционных баз данных. М.: Мир, 1987. — 608 с. Теория нормализации раскрывается в этой книге наиболее полно. Очень много результатов, связанных с многозначными и соединительными зависимостями. Рассматриваются кольцевые и табличные зависимости, алгоритмы синтеза, декомпозиции и многие другие вопросы. Книга достаточна сложная, т.к. вводится множество дополнительных понятий, и переопределяются некоторые привычные определения. |
|
Мартин Дж. Организация баз данных в вычислительных системах. 2-е изд., М.: Мир, 1980. |
|
Ревунков Г.И., Четвериков В.Н., Самохвалов Э.Н. Базы и банки данных. М.: Высшая школа, 1987. — 248 с. |
|
Филиппович А.Ю. "Взаимные функциональные зависимости". Системный администратор. №1. Октябрь, 2002. — стр. 84-89. Рассмотрено большинство вопросов, затрагиваемых в этой статье. К сожалению, издателям не удалось сверстать формульный набор и большинство математических знаков "вылетели" при выводе пленок. |
|
Фролов. А., Фролов. Г. Базы данных в Интеренете: практическое руководство по созданию WEB-приложений с БД., изд. 2-е., "Русская Редакция", 2000, - 448 с. |
|
Хансен Г., Хансен Дж. Базы данных. Разработка и управление, М., Бином, 2000, - 704 с. Теория нормализации (стр. 200-210). 1-4НФ, очень кратко. |
|
Цаленко М.Ш. Моделирование семантики в БД. М.: Наука. Гл. ред. физ-мат.лит., 1989. - 288 с. - (Проблемы искусственного интеллекта). В книге рассматриваются многие вопросы теории нормализации, однако они формализованы в нетрадиционной для реляционной алгебры нотации. |
|
Ульман Дж., Уидом Дж. Введение в системы БД. М.: Лори, 2000, - 420 с. Теория нормализации (стр. 94-138). 1-5НФ, Переиздание книги 80 года с небольшими изменениями. |
|
Ульман Дж. Основы систем баз данных. — М.: Финансы и статистика, 1983. — 334 с. Теория нормализации (стр. 152-189). 1-4НФ, Одна из немногих книг, содержащая множество алгоритмов, теорем, аксиом для функциональных и многозначных зависимостей. |
|
Beeri Catriel, Kifer Michael. An Integrated Approach to Logical Design of Relational Database Schemes. .// ACM Trans. on Database Systems. - 1986. - V. 11. № 2. — Р 134-158. |
|
Bernstein P.A. Synthesising Third Normal Form Relations from Functional Dependencies // ACM Trans. on Database Systems. - 1976. V. 1, № 4. - Р. 277-298. |
|
Diederich Jim, Milton Jack. New Methods and Fast Algorithms for Database Normalization. ACM Trans. on Database Systems. - 1988. - V. 13, № 3. - Р.339-365 |
|
Fagin R. A Normal Form for Relational Databases That is Based on Domains and Keys// ACM Trans. on Database Systems. - 1981. - V. 6, № 3. - Р. 387-415. |
|
Rissanen J. Independent Components of Relations// ACM Trans. on Database Systems. - 1977. - V. 2, №4. - Р. 317-325. |
|
Zaniolo C., Melkanoff M.A. A Formal Approach to the Definition and the Design of Conceptual Schemata for Database Systems // ACM Trans. on Database Systems. - 1982. - V. 7, №.1, - P. 24-59. |
|
Zaniolo C. A New Normal Form for the Design of Relational Database Shemata // ACM Trans. on Database Systems. - 1982. - V. 7, №.3, - P. 489-499. |
© НОК CLAIM, 2006-2012. Замечания, вопросы и сведения об ошибках просим сообщать в форуме или присылать администратору сайта.