
CLAIM – научно-образовательный кластер
Автоматизированная система распознавания
древнерусских скорописных текстов
дипломный проект
Разработчик: Зеленцов И.А., руководитель Филиппович Ю.Н.
Содержание
Анализ изображенийАлгоритм распознавания
Проект «Автоматизированная система распознавания древнерусских скорописных текстов» посвящен разработке программного продукта, решающего задачу автоматизированного перевода древнерусских скорописных текстов в электронное текстовое представление.
Актуальность исследования обусловлена необходимостью перевода древнерусских скорописных документов в электронный вид с возможностью последующего автоматизированного анализа. Большую роль здесь играет специфика используемого в рукописях языка, круг пользователей которого ограничен в настоящий момент учёными-исследователями древнерусской письменности.
Целью исследования является разработка программного продукта, осуществляющего автоматизированный перевод текстов из растровых изображений в вид электронных документов. Назначением такого продукта является сокращение времени получения электронных текстовых документов за счёт замены этапа ручного ввода автоматизированным распознаванием. Продукт предназначается для научных сотрудников, исследующих древние документы данного вида. Также возможно использование продукта при подготовке мультимедийных электронных изданий рукописей.
Задачи исследования: изучение особенностей древнерусской скорописи; анализ существующих методов распознавания и выбор подходящего для решения задачи; определение возможной меры автоматизации процесса распознавания; проектирование и реализация программного продукта.
Предметная область
Древние рукописи являются памятником русской культуры, а также источником знаний о процессе формирования современного языка. Помимо сведений о событиях и укладе жизни людей прошлого, содержащихся непосредственно в тексте рукописей, в них также заложена информация о языке прошедших веков, способах письма и использования письменности как средства коммуникации. Поэтому они являются предметом исследований учёных-лингвистов.
Сложность решения задачи компьютерного распознавания находится в сильной зависимости от особенностей графического представления текста. В текстах, полученных типографским способом, буквы располагаются в ровных строках, имеют одинаковое начертание в пределах всего документа и, как правило, имеют достаточно четко различимые промежутки между собой. При решении задачи распознавания эта информация позволяет использовать допущения, снижающие сложность разрабатываемых алгоритмов и методов. Эти особенности присущи, хоть и в меньшей степени, рукопечатным текстам. Здесь в игру вступают вариативность начертания символов, а также всевозможные неточности, как, например, неровность строк, пересечение штрихов букв. Возможно также внесение декоративных элементов в начертание букв.
Скорописные тексты представляют собой наиболее сложный для распознавания вид текстовых изображений (см. рис.1). Назначением скорописи является быстрое нанесение текста на бумагу, при этом без внимания оказывается эстетическая сторона оформления документа. Поэтому в скорописных текстах ещё более велика вариативность начертания букв. Они, как правило, связываются соединительными линиями, что приводит к необходимости решения задачи определения границ букв в изображении. Строки не располагаются на ровных горизонталях, могут встречаться помарки и кляксы. Кроме того, процесс получения электронных изображений рукописей обычно включает в себя несколько этапов копирования (фотографирования и сканирования), каждый из которых вносит свою долю помех и дефектов в выходное изображение.

Рис.1. Пример изображения древнерусской скорописной страницы
Еще одной особенностью древних рукописей являются используемые в них язык и способы написания символов алфавита, которые отличаются от современных. Следовательно, для создания программы распознавания не достаточно знаний человека, владеющего современным русским языком, а требуются знания эксперта. В программу требуется заложить сведения о распознаваемом алфавите, способах написания различных символов, особенностях оформления древних документов.
В процессе распознавания возможны ситуации, когда программа не в состоянии произвести распознавание очередного символа. Это может быть связано с упомянутыми выше дефектами изображений, спецификой скорописи или обнаружением фрагментов, не поддающихся классификации с помощью заложенных в программу правил. При чтении человек пользуется сведениями, полученными из семантического и визуального контекста искажённого фрагмента текста для разрешения подобных неоднозначностей. Такой подход не может быть использован компьютерной программой, не осуществляющей грамматический разбор текста параллельно с распознаванием его изображения. Выходом из таких ситуаций может служить модель периодических обращений программы в неразрешимых ситуациях за помощью к эксперту, следящему за процессом распознавания. Эксперт может прямым указанием верного ответа позволить программе продолжить работу, а также дать команду запомнить ситуацию и её разрешение как новое правило.
Таким образом, для решения задачи автоматизации получения электронных текстов рукописей складывается необходимость в создании экспертной системы распознавания.
Технология распознавания
Общие принципы
Для решения задачи распознавания скорописи в проекте используется структурный метод. В его основе лежит представление об изображении буквы как о наборе структурных элементов, расположенных друг относительно друга определённым способом. Общий принцип работы метода заключается в следующем: выявление структурных компонентов изображения и анализ их состава и взаимоотношений с целью классификации изображения.
В качестве структурных элементов используются отдельные участки траектории движения пишущего инструмента, представляющие собой семантически выделяемые элементы букв. Так, можно сказать, что буква 'П' состоит из левой и правой вертикальных линий, соединённых сверху горизонтальной перемычкой, а буква 'О' построена одной замкнутой дуговой линией.
В процессе распознавания программа использует базу знаний о начертаниях букв. Она формируется экспертом на этапе обучения программы и содержит знания о процессе синтеза изображений букв, т.е. способе, которым буквы наносятся на бумагу. Обучение происходит следующим образом. Эксперт поочерёдно формирует на экране изображения всех букв с помощью мыши. Каждый элемент буквы формируется отдельно от остальных, т.е. левая клавиша мыши должна быть отпущена перед вводом очередного фрагмента. После ввода изображения эксперт указывает код представленного символа. Программа осуществляет онлайн-распознавание введённого изображения, т.е. классифицирует его элементы и определяет их взаимоотношения на плоскости рисунка. Каждый фрагмент буквы анализируется и характеризуется качественными показателями, такими как вертикальность или горизонтальность, положение относительно соседнего элемента (левее-правее и выше-ниже). Кроме того, фрагменту ставится в соответствие последовательность, кодирующая направления перемещения пишущего инструмента при его начертании. Полученная совокупность информации об элементах буквы и их отношениях заносится в базу знаний с указанием соответствующего кода буквы.
В рабочем режиме перед обученной программой стоит задача оффлайн-распознавания, т.к. изображение текста уже сформировано и информации о порядке его синтеза нет. В общем виде задача решается следующим образом. Графический анализатор (сканер) пытается выделить в изображении элементы букв всех типов, встречающихся в базе знаний. При нахождении очередного элемента определяется его отношения на рисунке к уже найденным элементам. Эта информация передаётся вышестоящему распознавателю букв. Последний производит поиск в базе знаний вхождений элементов найденных типов со схожими взаимоотношениями в одну из букв-эталонов. Как только подходящее вхождение обнаружено, распознаватель выдвигает гипотезу о наблюдаемой в текущей точке изображения букве. Далее он получает из буквы-эталона информацию об элементах, которые должны присутствовать в букве (если гипотеза верна), но ещё не обнаружены сканером. Эта информация служит для ориентирования сканера на поиск элемента определённого типа в определённой области изображения относительно одного из найденных элементов.
Если удаётся выделить все недостающие элементы, т.е. подтвердить гипотезу, то буква считается распознанной и её изображение исключается из дальнейшего рассмотрения. В противном случае, производится поиск в базе знаний другой гипотезы, не противоречащей полученной к данному моменту информации, и далее осуществляется проверка новой гипотезы.
В случае, если не остаётся ни одной правдоподобной гипотезы, ситуацию может разрешить эксперт. По запросу программы, он может выделить в проблемном фрагменте изображения области неопознанных букв и указать их. В таком случае программа, зафиксировав полученные сведения, может продолжить распознавание со следующей буквы.
Такой подход, основанный на выдвижении и проверке гипотез,
имеет следующие преимущества. Имея предположение о наблюдаемой букве,
распознаватель может с направить анализ изображения в нужную сторону и
выделить из общей картины лишь те элементы, которые необходимы для составления
буквы. Тем самым можно избежать паразитных пересечений элементов соседних
букв, а также отбросить декоративные росчерки, способные внести путаницу
в процесс распознавания.
Вариативность рукописного начертания символов устраняется за счёт описания
элементов качественными характеристиками, такими как вертикальность, горизонтальность,
относительные размеры. Вертикальная линия, выведенная рукой, не бывает
идеально вертикальной и ровной. Поэтому её точное описание не будет соответствовать
ожиданиям. Качественная же оценка способна выделить лишь наличие необходимого
признака объекта (вертикальности, т.е. протяженности вдоль вертикальной
оси), что может оказаться достаточным для его классификации.
Для облегчения процесса распознавания в программу также может быть включён распознаватель слов, опирающийся на словник. Он будет служить источником гипотез для распознавателя букв, помогая последнему скорее находить правильные гипотезы. Таким образом, получается многоуровневая система распознавания, в которой вышележащие уровни обеспечивают нижележащие гипотезами о наблюдаемой картине, а в ответ получают ответы о реальном положении вещей, что в свою очередь служит им для проверки гипотезы более высокого уровня. Развивая предложенную идею, можно говорить о надстройке над распознавателем букв грамматического и семантического анализаторов, способных выдвигать предположения о последующих словах и предложениях. Однако, это выходит за границы данной работы.
В следующих разделах приводится описание структуры программы и её компонентов.
Структура программы
Процесс функционирования разрабатываемой системы состоит
из двух этапов.
Первый этап — обучение системы — заключается в наполнении
базы знаний системы сведениями о символах алфавита, встречающихся в рукописях,
и способах их начертания. Эти знания могут быть получены от эксперта в
процессе его работы с системой в специальном обучающем режиме. Эксперт
с помощью мыши или графического планшета последовательно формирует в рабочем
окне программы изображения всех букв целевого алфавита и указывает соответствие
каждого изображения необходимому коду электронного представления. Начертания
символов должны соответствовать используемым в рукописях. Система производит
онлайн-распознавание вводимых изображений и заносит в базу знаний полученную
информацию о процессе синтеза изображений.
База знаний состоит из двух связанных частей:
- База фреймов букв;
- Словник.
Фреймы букв отражают знания эксперта об элементах, формирующих изображение символов и их пространственных взаимоотношениях. Словник состоит из слов, составляющих лексикон программы. Слова представлены в виде фреймовых структур, ссылающихся на фреймы букв из соответствующей части базы знаний и отражающих порядок следования букв в каждом конкретном слове. Заполнение словарной части базы знаний осуществляется автоматическим преобразованием текстового словника рукописей.
Второй этап функционирования системы является рабочим. На нём выполняется непосредственно распознавание изображений и формирование их текстовых представлений.
Блок распознавания системы состоит из следующих компонент:
- Сканер;
- Распознаватель букв (РБ);
- Распознаватель слов (РС).
Сканер является компонентом системы, отвечающим за графический анализ растра изображения и последовательное выделение в нём структурных элементов изображений по запросу распознавателя букв. Сканер может получать в запросе указание на вид ожидаемого элемента. Тогда, проводя трассировку черных линий изображения, он будет стремиться следовать таким путём, который приведёт к обнаружению элемента искомого типа. В случае же пустого запроса он выделяет произвольный элемент, встретившийся первым. Закончив выполнение задания, сканер возвращает распознавателю букв информацию об обнаруженном элементе и точках пересечения его другими элементами. В случае невозможности выполнить задание возвращается особый, отрицательный ответ.
Задачей распознавателя букв является получение с помощью сканера набора элементов изображения, определения взаимосвязей между ними и принятии решения на основе полученной информации о наблюдаемой букве. Получая от сканера очередную порцию информации, РБ производит в базе фреймов букв поиск фрейма или набора фреймов, которые могут быть инстанциированы имеющимися данными. Один из таких фреймов объявляется активным и используется в качестве гипотезы о наблюдаемой букве. На основании гипотезы РБ может делать предсказания о последующих считываемых элементах и специализировать запросы к сканеру.
РБ работает под управлением гипотезы, полученной от распознавателя слов. Этот компонент работает со словарной частью базы знаний. По аналогии с принципом работы РБ, РС выполняет задачу распознавания слов, оперируя получаемыми от РБ данными о найденных буквах. Проводя поиск по базе фреймов слов, РС выдвигает гипотезы о наблюдаемых словах и делает предсказания касательно ожидаемых букв. На рисунке 2 изображена описанная структурная схема проектируемой системы.
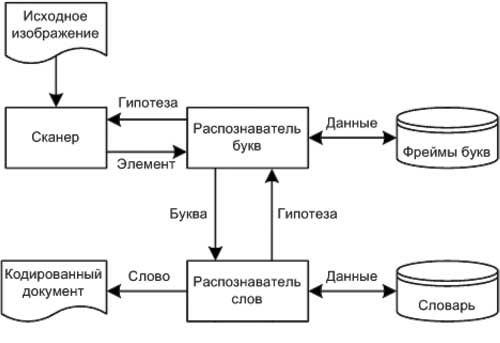
Рис. 2. Структурная схема проектируемой системы
Представление знаний
База знаний распознавателя содержит информацию о структуре букв и строится на основе фреймовой модели. Информация о структурных элементах изображения и их взаимосвязи представляется в виде фреймов — сетевых структур, узлы которых описывают объекты изображения, а именованные дуги — их взаимоотношения. В процессе распознавания в изображении также выделяются структурные элементы и определяются связи между ними. Процесс сегментации изображения управляется процессом проверки выбранного в текущий момент фрейма — гипотезы. Изображение признаётся как описываемое каким-либо фреймом, если удаётся связать его терминальные узлы с наблюдаемыми элементами изображения. Преимуществом такой модели является возможность описания изображений на разных концептуальных уровнях, от наиболее абстрактных понятий к конкретным фрагментам изображения. Это позволяет проводить распознавания на разных уровнях детализации, способствуя решению проблемы вариативности начертания рукописных символов. Другой полезной особенностью является возможность задания для некоторых терминалов фрейма значений по умолчанию, которые могут быть изменены при обнаружении противоречия, или признаются действительными в противном случае. Кроме того, использование фреймовых моделей букв позволяет сократить объём памяти, необходимой для хранения информации, а также время оперирования фреймами. Это достигается за счёт совместного использования узлов несколькими фреймами.
Фреймы букв строятся следующим образом. Узлы верхнего уровня обозначают буквы как таковые и хранят ссылки на числовые значения соответствующих кодировочных значений. Каждый узел-буква имеет набор связей с узлами более низкого уровня, соответствующих её структурным элементам. Эти узлы представляют в базе знаний части изображений букв на концептуальном уровне, т.е обозначают роль каждого элемента в начертании буквы. К примеру, такой узел может обозначать “левую вертикальную линию” в букве 'П'. Узлы-элементы ссылаются на ограниченный набор узлов, качественно представляющих типы линий (например, “вертикальная линия с закруглением в верхней части”).
На уровне элементов букв располагаются также узлы, обозначающие точки пересечения линий. Точка нечётким образом характеризуется её положением внутри области линии (например, “точка в правой части линии”) и указывает на место, в котором данный элемент пересекается другим.
Ещё одним видом узлов являются узлы-отношения. Они описывают различные виды связей между объектами и хранят ссылки на узлы-участники связей. Так, узлы-точки связываются с узлами-элементами с помощью специальных узлов, обозначающих, что данный элемент имеет пересечение с другим элементом в данной точке. Чтобы определить, с каким элементом в данной очке пересекается рассматриваемый элемент, вводится ещё один узел-отношение, связывающий две точки пересечения, т.е. указывающий, что эти две точки совпадают на изображении.
Помимо перечисленных в базе знаний также присутствуют отношения взаимного расположения элементов (справа, слева и т.д.) и относительных размеров (больше, меньше).
На рисунке 3 представлен упрощённый пример фреймов трёх букв. Здесь квадратами представлены узлы-элементы букв, кругами — точки пересечения, светлыми треугольниками — узлы-отношения принадлежности точек элементам, тёмными треугольниками — узлы-отношения соответствия точек пересечения. Линии между узлами обозначают их связи, т.е. ссылки друг на друга, имеющие различные семантические значения в зависимости от связываемых узлов. Узлы-буквы на данном рисунке явно не представлены. Вместо этого принадлежность узла тому или иному фрейму обозначена соответствующей буквой рядом с ним. Также для упрощения рисунка опущены узлы пространственных отношений.
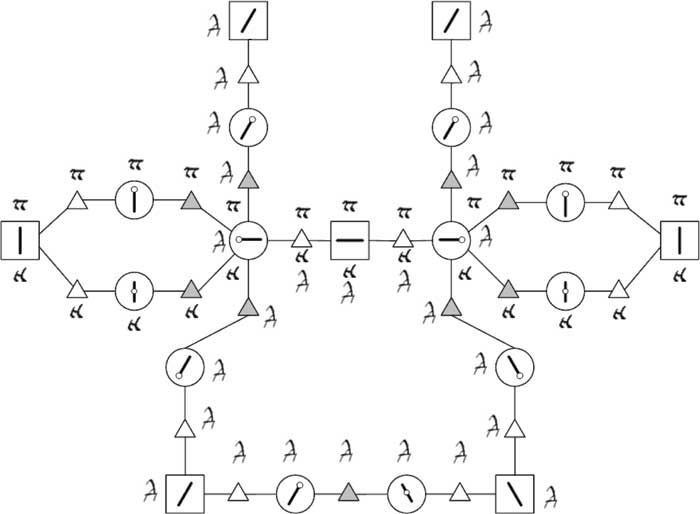
Рис.3. Представление знаний о структуре изображений символов
© НОК CLAIM, 2006-2012. Замечания, вопросы и сведения об ошибках просим сообщать в форуме или присылать администратору сайта.