2. ОПИСАНИЕ ИНТЕРФЕЙСА СИСТЕМЫ
После запуска на экране появляется
главное окно системы (рис. 8). Можно выделить основные его логические элементы:
– панель подсказки (рис. 10);
– панель базовых терминов (рис. 11);
![]()
Рис. 10. Панель подсказки
|
Рис. 11. Панель базовых терминов |
Рис. 12. Панель
режимов |
– панели режимов (рис. 12).
Панель подсказки дает краткую справку о текущем режиме, в
котором находится система, и перечисляет основные функции выбранного режима.
При загрузке системы и смене режима эта панель становится желтой, а через
некоторое время “гаснет” и принимает цвет фона окна.
Панель базовых терминов служит для отображения списка всех базовых
слов словарных статей семантического словаря. Этот список отображается во всех
режимах, поскольку все действия над другими лингвистическими объектами в
системе прямо или косвенно с ним связаны.
Панель режимов дает возможность переключаться между
различными режимами, реализующими всю функциональность системы, с помощью
стандартного механизма закладок (Tabs). Всего в системе имеется 5 основных
режимов работы:
– режим “Словарь”;
– режим “Дерево”;
– режим “Словоформы”;
– режим “Сеть”;
– режим “Словник”.
Система построена на основе
стандартных интерфейсных элементов ОС Windows 95/NT4, логика работы которых
одинакова для всех режимов.
Для навигации в таблицах и списках,
выполнения операций добавления, модификации и удаления отдельных записей можно
воспользоваться панелями навигации. На рис. 13 приведен наиболее полный вид
такой панели:
![]()
Рис. 13. Панель
навигации
Ниже приводится описание назначения
кнопок в порядке их следования:
– перемещение на первую запись в
таблице (списке);
– перемещение на предыдущую запись в
таблице;
– перемещение на следующую запись в
таблице;
– перемещение на последнюю запись в
таблице;
– добавление новой записи в таблицу;
– удаление текущей записи из
таблицы;
– подтверждение внесенных в таблицу
изменений;
– отмена внесенных в таблицу
изменений.
Для выполнения всех операций в
системе предусмотрены кнопки с нанесенными на них графическими изображениями. В
табл. 1 приведен полный список назначений этих кнопок для каждого из режимов:
Таблица 1
Режимы системы и примеры их
использования
|
|
Системные функции |
|
|
Выбор рабочего шрифта системы. |
|
|
Настройка и инициализация рабочих таблиц. |
|
|
Вызов контекстной гипертекстовой справки. |
|
|
Завершение работы с системой. |
|
|
Функции режима “Словарь” |
|
|
Импорт словарных статей, автоматическое извлечение базовых слов и их толкований из текстов. |
|
|
Извлечение эксцерпций из текста и построение указателя. |
|
|
Получение выборки из генерального словника. |
|
|
Вычисление числовых характеристик словаря. |
|
|
Функции режима “Дерево” |
|
|
Построить понятийное дерево (тезаурус “определяющее-определяемое”). |
|
|
Добавить в ветвь элемент (слово). |
|
|
Удалить элемент (слово) из ветви. |
|
|
Удалить всю ветвь. |
|
|
Сделать выбранный термин в ветви текущим. |
|
|
Перейти к предыдущему термину. |
|
|
Построение графа дефиниций. |
|
|
Kластерный анализ тезауруса “определяющее-определяемое”. |
|
|
Расчет коэффициентов неопределенности для словарных статей. |
|
|
Функции режима “Словоформы” |
|
|
Привязать или отвязать словоформу от лексемы. |
|
|
Автоматическая привязка словоформ к лексемам. |
|
|
Перенести словоформу в генеральный словник. |
|
|
Построить частотный словник (по словам и словосочетаниям). |
|
|
Работа с исходными текстами. |
|
|
Функции режима “Сеть” |
|
|
Построение корреляционной семантической сети. |
|
|
Расчет (обновление) корреляционных отношений. |
|
|
Построение графа отношений. |
|
|
Kластерный анализ корреляционной сети. |
|
|
Функции режима “Словник” |
|
|
Построить частотный словник (по словам и словосочетаниям). |
|
|
Перенести словоформу в генеральный словник. |
|
|
Работа с исходными текстами. |
|
|
Проведение частотного анализа. |
|
|
Проведение динамического анализа. |
|
|
Построение группового словника. |
|
|
Сравнение текстов. |
|
|
Расчет параметров распределения в модели "ранг-частота". |
К системным функциям относятся:
|
|
Выбор рабочего шрифта системы. |
|
|
Настройка и инициализация рабочих таблиц. |
|
|
Вызов контекстной гипертекстовой справки. |
|
|
Завершение работы с системой |
Выбор рабочего шрифта системы ![]()
Система “Интерлекс” имеет
возможность отображать естественно-языковую информацию любым, доступным
операционной системе шрифтом. По умолчанию, используется шрифт с гарнитурой MS
Sans Serif и кеглем 8.
Чтобы изменить шрифт, необходимо
нажать на кнопку изменения шрифта в главном окне.
На экране появится стандартное окно
Windows (рис. 14):
После выбора гарнитуры шрифта, его
кегля, стиля и цвета необходимо нажать OK для активизации
изменений.
Возможность изменения шрифта
оказывается очень полезной при работе с текстами, в которых необходимо
обрабатывать специальные символы как элементы алфавита (например, старорусские
тексты и т.п.).
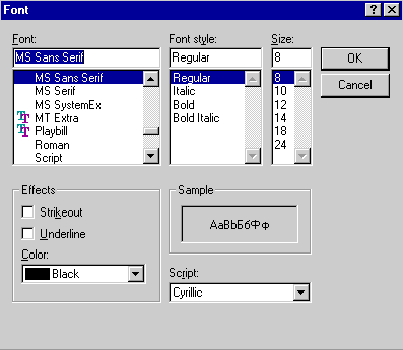
Рис. 14. Изменение
рабочего шрифта
Пример изменения стандартного шрифта
на гарнитуру FlowerC, Bold Italic, 12 c цветом “Navy” (рис. 15).
Рис. 15. Пример
изменения стандартного шрифта
Настройка и инициализация
рабочих таблиц ![]()
Система “Интерлекс” использует для
хранения промежуточной и выходной информации таблицы формата Paradox, которые
хранятся в подкаталоге \DATA\ основного каталога системы (раздел
“Файловая структура системы”, с. 127). Все таблицы образуют лингвистическую
базу данных. При необходимости часть этих таблиц можно очистить.
Для выполнения этой операции
необходимо нажать на кнопку “Настройка и инициализация рабочих таблиц”.
На экране появится окно настройки, как показано на рис. 16.
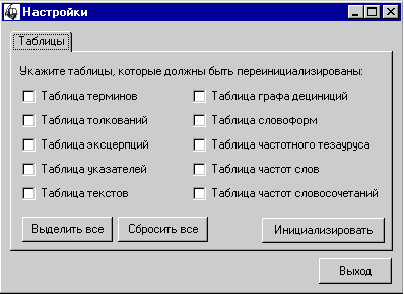
Рис. 16.
Инициализация рабочих таблиц
Для инициализации таблиц нужно
отметить необходимые поля и нажать кнопку “Инициализация”.
Следует отметить, что ряд таблиц являются зависимыми, поэтому в целях
сохранения целостности базы такие таблицы можно инициализировать только все
вместе (а не по отдельности).
ВНИМАНИЕ! Никогда не удаляйте файлы базы данных с помощью
средств операционной системы и файловых менеджеров. Это может привести к
нарушению целостности базы и сделает систему “Интерлекс” неработоспособной.
После завершения инициализации
необходимо нажать “Выход” для возврата в главное окно системы.
Пример инициализации таблицы базовых
терминов (рис. 17):
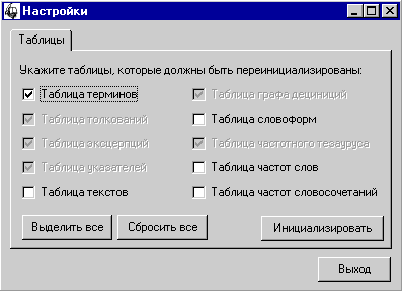
Рис. 17. Инициализация
таблицы базовых терминов
При инициализации таблицы базовых терминов
таблицы толкований, эксцерпций, указателей, графа дефиниций и частот слов
должны быть также проинициализированы.
Вызов контекстной
гипертекстовой справки ![]()
В версии “Интерлекс 2.0” не
реализовано.
Завершение работы с системой ![]()
Нажатие на эту кнопку приводит к закрытию
главного окна системы (с сохранением всех данных) и освобождению всех занятых
ресурсов (памяти, файлов и т.п.).
Для завершения работы рекомендуется
использовать эту функцию.
Режим служит для построения и
анализа частотных словников. Под частотным словником естественно-языкового
описания предметной области понимается совокупность естественно-языковых единиц
(слов, словосочетаний), которым поставлено в соответствие число,
характеризующее абсолютную или относительную частоту их встречаемости в
исходном корпусе текстов. Элементы частотных словников обычно упорядочены по
убыванию частотного признака.
Построение частотного словника
является одним из формальных методов для выделения базовых слов (понятий,
терминов) из естественно-языкового описания предметной области.
Для перехода в режим после запуска
системы щелкните на закладке “Словник”. Панель режимов в этом случае примет вид
(рис. 18):
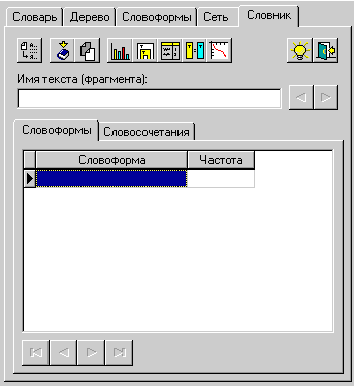
Рис. 18. Режим
“Словник”
В данном режиме доступны следующие
функции:
|
|
Построение частотного словника. |
|
|
Перенести словоформу в генеральный словник. |
|
|
Работа с исходными текстами. |
|
|
Проведение частотного анализа. |
|
|
Проведение динамического анализа. |
|
|
Построение группового словника. |
|
|
Сравнение текстов. |
|
|
Расчет параметров распределения. |
Кроме того, в этом режиме существуют
еще две закладки:
– словоформы;
– словосочетания.
Они позволяют переключаться между
двумя таблицами, содержащими частотные словники соответственно по словоформам и
словосочетаниям (в системе обрабатываются только парные словосочетания). В
обеих таблицах можно выделить два основных поля: естественно-языковая единица и
ее частота. Данные в таблицах сортируются в порядке убывания частоты.
В поле “Имя текста/фрагмента” отображается
название того исходного текста, на основании которого был построен частотный
словник (как по словоформам, так и по словосочетаниям).
При первом запуске системы таблицы
словников пусты. Таким образом, первым шагом при работе с данным режимом является
построение частотного словника.
Построение частотного словника
![]()
Для построения частотного словника
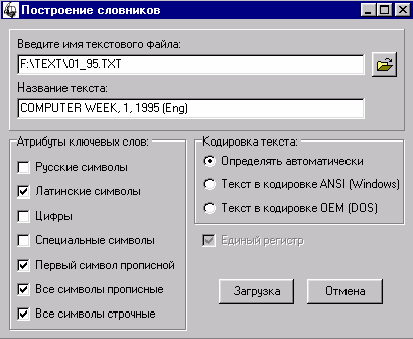
нажмите на кнопку “Построить словник”. На экране появится окно (рис. 19).
|
|
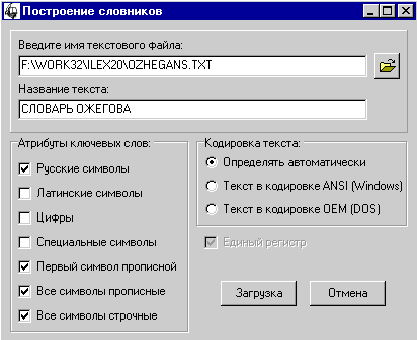
Рис. 19. Построение
словника
Для построения частотного словника
необходимо ввести (или выбрать) имя исходного текстового файла. Можно и
желательно также присвоить файлу некоторое текстовое обозначение (например,
заголовок или название). Оно будет использоваться в дальнейшем для
идентификации текста.
Выбор входного формата
Далее необходимо указать тип
кодировки, которой соответствует выбранный текстовый файл. Система “Интерлекс
2.0” поддерживает два формата текстовых файлов:
– MS Windows ANSI-1251;
– MS DOS OEM-866.
Если файл, подлежащий обработке,
имеет другой формат (например, DOC или RTF), то его следует пересохранить в
одном из указанных выше форматов. Как правило, все текстовые процессоры (MS
Word в том числе) имеют возможность сохранения документа как обычного
текстового файла.
Если вы знаете, что исходный текст
сохранен в одном из отмеченных форматов, но не знаете, в каком именно, можно
установить флажок в положение “Определять автоматически”. В этом случае перед
обработкой текста система попытается выяснить его формат на основе
статистических данных об используемых в нем символах. Этот метод безошибочно
работает на текстах объемом от 20–30 KB.
Перед началом построения словника
необходимо также задать фильтр для слов. Система имеет возможность строить
словники, включая в них только слова, обладающие рядом заданных свойств
(атрибутов). Всего для слов определено 7 атрибутов, которые можно разделить на
две группы в зависимости от достаточности присутствия у слова атрибута для его
включения в словник.
Атрибуты, отмеченное состояние
которых говорит о ВОЗМОЖНОСТИ включения слов:
– русские символы;
– латинские символы;
– цифры;
– специальные символы.
Атрибуты, отмеченное состояние
которых говорит, что слово ОБЯЗАНО иметь соответствующий атрибут для его
включения в словник:
– первый символ прописной;
– все символы прописные;
– все символы строчные.
Таким образом, отметив только
“Русские символы” и “Латинские символы”, вы получите словник, в котором будут
встречаться слова с символами русского или латинского алфавита и только. В этом
случае в словник может попасть слово, в котором часть символов принадлежит
русскому алфавиту, а часть — латинскому.
Аналогично и с атрибутами второй
группы. Отметив только “Первый символ прописной”, вы получите словник только по
словам, начинающимся с большой буквы. Однако если слово имеет все буквы
прописные, то оно включено в словник не будет, так как не выбран
соответствующий фильтр.
Принятие соглашения:
– все цифры имеют атрибут “Прописной
символ”;
– все числа имеют атрибут “Все
символы прописные”;
– специальные символы:
#, $, %, &, /, <, >, =, \,
^,_,*, ~,@.
Специальные символы не являются
разделителями слов, а принадлежат к основному алфавиту системы. Каждый
специальный символ имеет атрибут “Прописной символ”. Любая комбинация только из
специальных символов имеет атрибут “Все символы прописные”.
По умолчанию, система отмечает
фильтры:
– русские символы;
– первый символ прописной;
– все символы прописные;
– все символы строчные.
Это соответствует включению в
словник всех слов только с русскими символами (регистр не важен).
После установки фильтров нажмите
кнопку “ЗАГРУЗКА”.На экране появится окно (рис. 20):
Рис. 20. Ожидание
окончания операции
Процесс построения словника может
занять определенное время (в зависимости от размера исходного текста и
быстродействия компьютера).
После завершения процесса на экран
будет выведено сообщение (рис. 21):

Рис. 21. Подтверждение
окончания операции
Нажмите OK, система задаст следующий
вопрос (рис. 22):
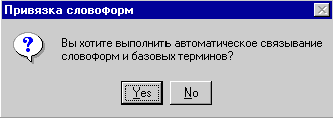
Рис. 22. Вы хотите
выполнить автоматическое связывание словоформ и базовых терминов?
Если вы строите словник и уже имеете
сформированный список базовых терминов (генеральный словник), то можно ответить
“Yes” — тогда каждой словоформе будет поставлена в соответствие некоторая каноническая
форма из генерального словника.
Если список базовых терминов пуст,
то следует ответить “No”.
Построенный словник будет отображен
на панели режимов. Щелкая на закладках “Словоформы” и “Словосочетания”, можно
просматривать частотный словник по словоформам и словосочетаниям
соответственно.
В поле “Имя текста (фрагмента)”
будет отображено введенное вами название текста, которому соответствует
полученный словник.
Пример 1
Исходные данные:
– файл с исходным текстом в формате
MS Windows DOS-866;
– установленная система “Интерлекс”.
Задача:
– построить частотный словник по
словам и словосочетаниям.
Исходный текст — электронная версия
компьютерного еженедельника “ComputerWeek”, №1, 1995 (рис. 23). Текст сохранен
под именем 01_95.TXT в формате DOS-866 в папке F:\TEXT. Объем файла ~420KB
(около 16 страниц).
Рис. 23. Фрагмент
номера еженедельника “ComputerWeek”, №1, 1995
Решение:
1. Запустить систему “Интерлекс”.
2. Перейти в режим “Словник”.
3. Нажать на кнопку “Построить
словник”.
4. В поле “Имя текстового файла”
набрать: F:\TEXT\01_95.TXT.
5. В поле “Название текста” набрать: Computer
Week, 1, 1995.
6. Указать кодировку текста: “Определять
автоматически”.
7. Указать фильтры: “Русские
символы”, “Первый символ прописной”, “Все символы прописные”, “Все символы
строчные”.
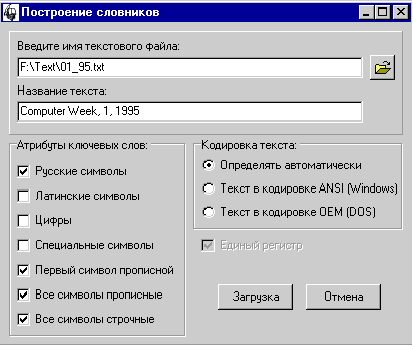
8. Нажать кнопку “Загрузка”.
9. Дождаться окончания операции.
10. Ответить “No” на вопрос “Вы
хотите выполнять автоматическое связывание словоформ и базовых терминов?”
Результат построения приведен на рис.
24. А в табл. 2 приведены фрагменты самих частотных словников.
|
|
|
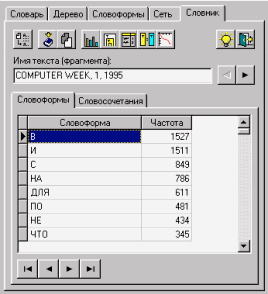
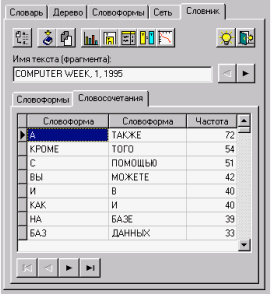
Рис. 24. Результат
построения частотных словников
Таблица 2
|
Частотный словник по словоформам |
Частотный словник по парным словосочетаниям |
|||
|
Словоформа |
Частота |
Словоформа |
Словоформа |
Частота |
|
В |
1527 |
А |
ТАKЖЕ |
72 |
|
И |
1511 |
КKРОМЕ |
ТОГО |
54 |
|
С |
849 |
С |
ПОМОЩЬЮ |
51 |
|
НА |
786 |
ВЫ |
МОЖЕТЕ |
42 |
|
ДЛЯ |
611 |
И |
В |
40 |
|
ПО |
481 |
КKАKК |
И |
40 |
|
НЕ |
434 |
НА |
БАЗЕ |
39 |
|
ЧТО |
345 |
БАЗ |
ДАННЫХ |
33 |
|
КK |
316 |
В |
KАЧЕСТВЕ |
31 |
|
КKАKК |
273 |
БАЗЫ |
ДАННЫХ |
29 |
|
ИЗ |
237 |
ТО |
ЧТО |
29 |
|
А |
219 |
В |
ТОМ |
29 |
|
ИЛИ |
219 |
В |
ОБЛАСТИ |
28 |
|
ДАННЫХ |
216 |
НАСТОЯЩЕЕ |
ВРЕМЯ |
28 |
|
ОТ |
189 |
В |
НАСТОЯЩЕЕ |
28 |
|
КKОМПАНИИ |
177 |
ДОСТУП |
КK |
26 |
|
ПРИ |
158 |
ИЗ |
НИХ |
26 |
|
СИСТЕМЫ |
157 |
ТАKИМ |
ОБРАЗОМ |
24 |
|
ТАKЖЕ |
155 |
ТАK |
И |
24 |
|
ЭТО |
143 |
НА |
РЫНKЕ |
23 |
|
СИСТЕМ |
134 |
ПО |
МНЕНИЮ |
22 |
|
ТО |
127 |
ПО |
СЛОВАМ |
22 |
|
ДОЛЛ |
127 |
ТАK |
КKАKК |
21 |
|
ВЫ |
125 |
НЕСМОТРЯ |
НА |
21 |
|
ИХ |
125 |
ПРИ |
ЭТОМ |
21 |
|
ВСЕ |
125 |
НЕ |
ТОЛЬKО |
20 |
|
БОЛЕЕ |
125 |
ПРОГРАММНЫХ СРЕДСТВ |
|
19 |
|
НО |
124 |
ЧТО |
В |
19 |
|
ЗА |
123 |
ДОСТУПА |
КK |
19 |
Табл. 2 получена с помощью утилиты
DBD32 и двух SQL- запросов:
SELECT Wordform, Frequency
FROM ‘freqtbl.db’, ‘wordform.db’
WHERE WordformID=RecordID
ORDER BY Frequency DESC
SELECT A.Wordform, B.Wordform,
Frequency
FROM ‘pairfreq.db’, ‘wordform.db’ A,
‘wordform.db’ B
WHERE FirstID=A.RecordID AND
SecondID=B.RecordID AND TextID=1
ORDER BY Frequency DESC
Пример 2
Исходные данные:
– файл с исходным текстом в формате
MS Windows DOS-866;
– установленная система “Интерлекс”.
Задача:
– построить частотный словник только
по англоязычной лексике.
Исходный текст — электронная версия
компьютерного еженедельника “ComputerWeek”, №1, 1995 (рис. 23). Текст сохранен
под именем 01_95.TXT в формате DOS-866 в папке F:\TEXT. Объем файла ~420KB
(около 16 страниц).
Решение:
1. Запустить систему “Интерлекс”.
2. Перейти в режим “Словник”.
3. Нажать на кнопку “Построить
словник”.
4. В поле “Имя текстового файла”
набрать: F:\TEXT\01_95.TXT.
5. В поле “Название текста” набрать: Computer
Week, 1, 1995 (Eng).
6. Указать кодировку текста: “Определять
автоматически”.
7. Указать фильтры: “Латинские
символы”, “Первый символ прописной”, “Все символы прописные”, “Все символы
строчные”.
|
|
8. Нажать кнопку “Загрузка”.
9. Дождаться окончания операции.
10. Ответить “No” на вопрос “Вы
хотите выполнять автоматическое формирование словоформ и базовых терминов?”.
11. С помощью клавиш панели навигации
выбрать текст с названием “Computer Week, 1, 1995 (Eng)”.
Результат построения приведен на
рис. 25. А в табл. 3 приведены фрагменты самих частотных словников.
|
|
|
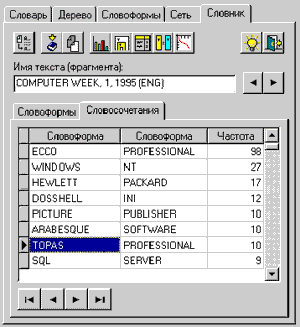
Рис. 25. Результат
построения частотных словников
Таблица 3
|
Частотный словник по словоформам |
Частотный словник по парным словосочетаниям |
|||
|
Словоформа |
Частота |
Словоформа |
Словоформа |
Частота |
|
WINDOWS |
165 |
ECCO |
PROFESSIONAL |
98 |
|
PROFESSIONAL |
108 |
WINDOWS |
NT |
27 |
|
ECCO |
108 |
HEWLETT |
PACKARD |
17 |
|
IBM |
107 |
DOSSHELL |
INI |
12 |
|
INTEL |
86 |
PICTURE |
PUBLISHER |
10 |
|
INFOCENTRAL |
74 |
TOPAS |
PROFESSIONAL |
10 |
|
MICROSOFT |
72 |
ARABESQUE |
SOFTWARE |
10 |
|
UNIX |
57 |
CD |
ROM |
9 |
|
PENTIUM |
50 |
FIRST |
AID |
9 |
|
NETWARE |
50 |
SQL |
SERVER |
9 |
|
DUO |
45 |
APPLE |
COMPUTER |
8 |
|
NOVELL |
40 |
MOBILE |
DATA |
8 |
|
SOFTWARE |
38 |
VISUAL |
REALITY |
8 |
|
COMPUTER |
37 |
IBM |
PC |
8 |
|
SQL |
35 |
COMPUTER |
ASSOCIATES |
7 |
|
APPLE |
34 |
BUSINESS |
OBJECTS |
7 |
|
ORACLE |
34 |
NOVELL |
NETWARE |
7 |
|
SYSTEM |
33 |
RAM |
MOBILE |
7 |
|
DOS |
32 |
BLUE |
LIGHTNING |
6 |
|
DCE |
32 |
POWERBOOK |
DUO |
6 |
|
NT |
31 |
FIRST |
UNION |
6 |
|
APPLETALK |
31 |
SOFTWARE |
AG |
5 |
|
VISUAL |
30 |
SILICON |
VIDEO |
5 |
|
SERVER |
30 |
NORTH |
AMERICA |
5 |
|
SYSTEMS |
25 |
MICRO |
EXPRESS |
5 |
|
SYBASE |
24 |
THIN |
CRT |
5 |
|
SYQUEST |
23 |
DIGITAL |
EQUIPMENT |
5 |
|
POWERBOOK |
22 |
AST |
RESEARCH |
5 |
|
ADVANCED |
22 |
BARCLAYS |
BANK |
5 |
|
INTERNET |
22 |
COMPAQ |
COMPUTER |
5 |
Табл. 3 получена с помощью утилиты
DBD32 и двух SQL- запросов:
SELECT Wordform, Frequency
FROM ‘freqtbl.db’, ‘wordform.db’
WHERE WordformID=RecordID AND
TextID=2
ORDER BY Frequency DESC
SELECT A.Wordform, B.Wordform,
Frequency
FROM ‘pairfreq.db’, ‘wordform.db’ A,
‘wordform.db’ B
WHERE FirstID=A.RecordID AND SecondID=B.RecordID
AND TextID=2
ORDER BY Frequency DESC
Перенос словоформ в
генеральный словник ![]()
В режиме “Словник” доступна функция
переноса словоформ в генеральный словник. С помощью этой функции постепенно
формируется список базовых терминов (т.е. основа генерального словника).
В генеральный словник могут попадать
как отдельные слова, так и словосочетания (не более чем из трех слов).
Чтобы перенести некоторое слово (или
словосочетание), в генеральный словник, необходимо установить курсор на нужном
слове (словосочетании) и нажать кнопку “Перенести в словарь”. На экране
появится окно (рис. 26):
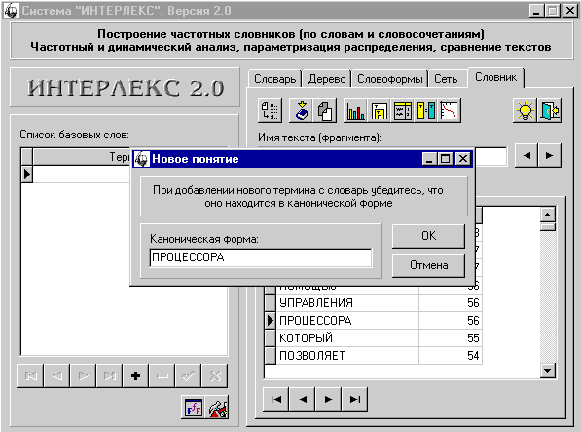
Рис. 26. Перенос
словоформы в список базовых терминов
Обратите внимание на предупреждение:
“При добавлении нового термина в словарь убедитесь, что он находится в
канонической форме”. Как правило, генеральный словник содержит слова в
своей начальной грамматической форме (например, для существительных это
именительный падеж единственного числа, для глаголов — инфинитив и т.д.).
Процесс нахождения канонической
формы слов носит название лемматизации. В данном случае имеет место
лемматизация отдельно взятых слов (или словосочетаний).
Таким образом, прежде чем нажать
“OK”, убедитесь, что слово находится в своей начальной форме (естественно, что
для этого вам потребуются определенные знания в области грамматики русского
языка).
На рис. 26 приведен пример переноса
слова “ПРОЦЕССОР” в список базовых слов. Обратите внимание, что в словнике оно
имеет вид “ПРОЦЕССОРА”. В этом случае необходимо внести необходимые
исправления.
Аналогично следует поступать и при
переносе словосочетаний.
Пример 3
Исходные данные:
– словники, построенные в примерах 1,
2.
Задача:
Перенести в генеральный словник
термины ПО “Информатика и вычислительная техника”:
“ПРОГРАММА”, “СЕТЬ”, “WINDOWS NT”.
Решение:
1. С помощью панели навигации
выберите текст с названием “Computer Week, 1, 1995”.
2. В таблице словоформ найдите слово
“ПРОГРАММА” в любой из форм (например, <ПРОГРАММЫ, 58>).
3. Нажмите кнопку “Перенести в
словарь”.
4. Измените слово “ПРОГРАММЫ” на
“ПРОГРАММА”.
5. Нажмите OK.
6. В таблице словоформ найдите слово
“СЕТЬ” в любой из форм (например, <СЕТИ, 89>).
7. Нажмите кнопку “Перенести в
словарь”.
8. Измените слово “СЕТИ” на “СЕТЬ”.
9. Нажмите OK.
10. С помощью панели навигации
выберите текст с названием “Computer Week, 1, 1995 (Eng)”.
11. В таблице словоформ найдите слово
“WINDOWS NT” (например, <WINDOWS, NT, 27>).
12. Нажмите кнопку “Перенести в
словарь”.
13. Термин уже находится в
канонической форме (ничего исправлять не требуется).
14. Нажмите OK.
В левой части главного окна
появляются три новых введенных термина (рис. 27):
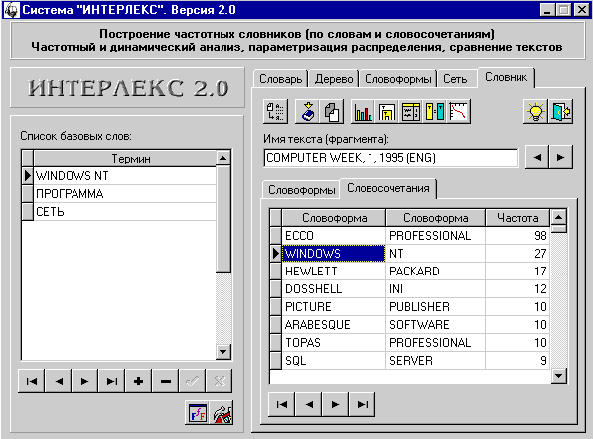
Рис. 27. Результат
переноса терминов из частотного
словника в список базовых терминов
Работа с исходными текстами ![]()
Система “Интерлекс” имеет
возможность работать одновременно с несколькими текстами. В лингвистической
базе данных системы каждому частотному словнику ставится в соответствие
идентификатор текста, на основе которого он был сформирован.
Данная функция позволяет
просматривать, переименовывать и удалять ссылки на тексты вместе с привязанными
к ним словниками. После нажатия на кнопку “Исходные тексты” на экране появится
окно (рис. 28):
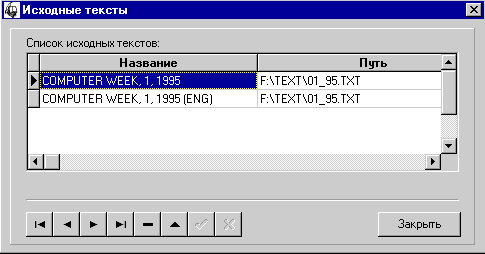
Рис. 28. Работа с
исходными текстами
Текущий текст всегда соответствует
тексту, отображаемому в панели режимов. Таким образом, чтобы просмотреть
словник по некоторому тексту, нужно выбрать его из таблицы и нажать “Закрыть”.
Для переименования названия текста
или пути нужно щелкнуть мышью на подсвеченной области, внести изменения, и на
панели навигации нажать кнопку “Сохранить изменения”.
Для удаления текста (точнее ссылки
на текст) и всех связанных с ним словников необходимо на панели навигации
нажать кнопку “Удалить текст”.
Проведение частотного анализа ![]()
Частотный анализ в системе
“Интерлекс” позволяет фиксировать заполняемость частотных интервалов на основе
имеющегося частотного словника.
Каждый частотный интервал
характеризуется следующими параметрами:
– общим количеством слов в тексте,
принадлежащих данному интервалу;
– количеством разных слов, попавших
в данный частотный интервал (т.е. количество слов в словнике, соответствующих
частотному интервалу).
Для интервала [0, 999999] имеют
смысл характеристики:
– математическое ожидание;
– дисперсия.
Частотный анализ проводится
автоматически по всем словникам, построенным в системе.
После нажатия на кнопку “Частотный
анализ” на экране появится окно (рис. 29):
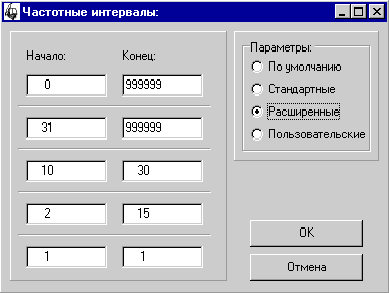
Рис. 29. Определение
частотных интервалов
В этом окне необходимо задать
частотные интервалы, за которыми будет проводится наблюдение. Всего можно
задать до 5 различных интервалов.
В системе “Интерлекс” имеется
возможность задать предопределенные параметры. Для этого существует
переключатель:
– По умолчанию. Устанавливает все
частотные интервалы в [0, 999999].
– Стандартные. Первые два интервала
[0, 999999], далее [6, 999999], [2, 5] и [1, 1].
– Расширенные. [0, 999999], [31,
999999], [10, 30], [2, 15], [1, 1].
– Пользовательские. Интервалы могут
принимать произвольные значения.
Задание конкретных значений зависит
от максимальной частоты слова в словнике.
Частотные интервалы позволяют
построить гистограмму распределения слов по частотным интервалам и на
определенном классе текстов провести исследования зависимости “высоты” столбца
гистограммы от его “ширины”, а также сопоставить полученные зависимости с
результатами, полученными на других текстах.
После задания частотных интервалов
нажмите “OK”. После окончания операции будет выведено (рис. 30):
Рис. 30. Окончание
частотного анализа
Результат частотного анализа
сводится в таблицу с именем _FRQTBL_.DB, которая расположена в
подкаталоге DATA системы “Интерлекс”. Чтобы просмотреть эту таблицу, запустите
утилиту DBD32, сделайте рабочим каталогом ссылку “INTERLEX”, через меню file
-> open -> table откройте таблицу _frqtbl_.db.
Формат таблицы _frqtbl_.db
Эта таблица имеет следующую
структуру:
– поле “ТеxtID”: идентификатор
(номер) исходного текста, для которого сделан анализ;
– поле “LowFreq”: нижняя граница
частотного интервала;
– поле “HighFreq”: верхняя граница
частотного интервала;
– поле “TotalForms”: общее число
слов в тексте, попавших в частотный интервал;
– поле “DifForms”: число разных
слов, попавших в частотный интервал;
– поле “ConstsForms”: здесь не
используется (всегда равно DifForms);
– поле “AVG”: математическое
ожидание (имеет смысл только для [0, 999999]);
– поле “DISP”: дисперсия (имеет
смысл только для [0, 999999]).
Чтобы получить окончательный
результат, рекомендуется выполнить следующий SQL-запрос:
select TextName, LowFreq, HighFreq,
TotalForms, DifForms
from “_frqtbl_.db”, “texttbl.db”
where textid=recordid;
Пример 4
Исходные данные:
– Частотные словники, построенные в
примерах 1, 2.
Задача:
Провести частотный анализ первого
словника, построить гистограмму распределения количества слов по частотным
интервалам. Выбрать значения частотных интервалов так, чтобы их ширина была
одинаковой и они покрывали весь частотный диапазон.
Решение:
1. С помощью панели навигации
выберите текст с названием “Computer Week, 1, 1995”.
2. Определите максимальную частоту
слова в частотном словнике: <В, 1527>.
3. Таким образом, весь частотный
диапазон для рассматриваемого словника = [1, 1527].
4. Разбиваем этот диапазон на 5
одинаковых интервалов
[0, 305], [305, 612], [612, 917], [917,1223], [1223, 999999] .
5. Нажимаем кнопку “Частотный
анализ”.
6. Вводим полученные значения (с
помощью утилиты DBD32 выполняем приведенный выше SQL-запрос) .
7. Результат приведен в табл. 4.
Таблица 4
|
№ |
Название текста (TextName) |
LowFreq |
HighFreq |
TotalForms |
DifForms |
|
1 |
COMPUTER WEEK, 1, 1995 |
0 |
305 |
40663 |
11267 |
|
2 |
COMPUTER WEEK, 1, 1995 |
305 |
612 |
2187 |
5 |
|
3 |
COMPUTER WEEK, 1, 1995 |
612 |
917 |
1635 |
2 |
|
4 |
COMPUTER WEEK, 1, 1995 |
917 |
1223 |
0 |
0 |
|
5 |
COMPUTER WEEK, 1, 1995 |
1223 |
999999 |
3038 |
2 |
|
6 |
COMPUTER WEEK, 1, 1995 (ENG) |
0 |
305 |
4905 |
1344 |
|
7 |
COMPUTER WEEK, 1, 1995 (ENG) |
305 |
612 |
0 |
0 |
|
8 |
COMPUTER WEEK, 1, 1995 (ENG) |
612 |
917 |
0 |
0 |
|
9 |
COMPUTER WEEK, 1, 1995 (ENG) |
917 |
1223 |
0 |
0 |
|
10 |
COMPUTER WEEK, 1, 1995 (ENG) |
1223 |
999999 |
0 |
0 |
В табл. 4:
LowFreq — нижняя граница частотного
интервала.
HighFreq — верхняя граница
частотного интервала.
TotalForms — общее число слов в
тексте в данном
частотном интервале.
DifForms — количество разных слов в
данном частотном
интервале.
Построим гистограммы распределения
числа слов в тексте и числа разных слов по частотным интервалам для текста
“Computer Week, 1, 1995”.
Для этого удобно воспользоваться
системой MS Excel, предварительно перенеся данные из таблицы “_FRQTBL_.DB”
(рис. 31, 32).
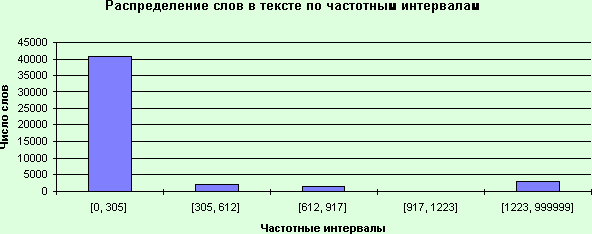
Рис. 31
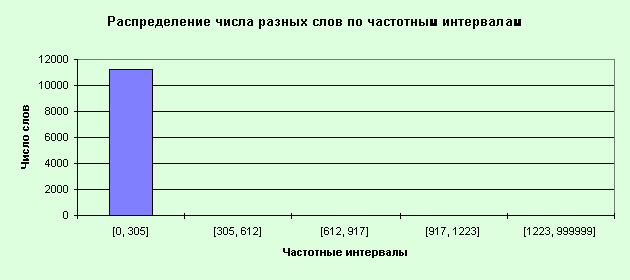
Рис.32
Проведение динамического
анализа ![]()
Целью анализа динамических
характеристик текстов является выявление закономерностей в частотных свойствах
естественно-языковых объектов, взятых из развернутого во времени корпуса
текстов по определенной предметной области, характеризующейся определенным
стилем и жанром.
Задачами динамического анализа
являются:
– исследование динамической
структуры текстов;
– исследование динамической
структуры словника;
– исследование динамики содержания
словника;
– исследования динамики наполнения
словника;
– определение “стоимости” слова.
На рис. 33 приведена схема
проведения динамического анализа.
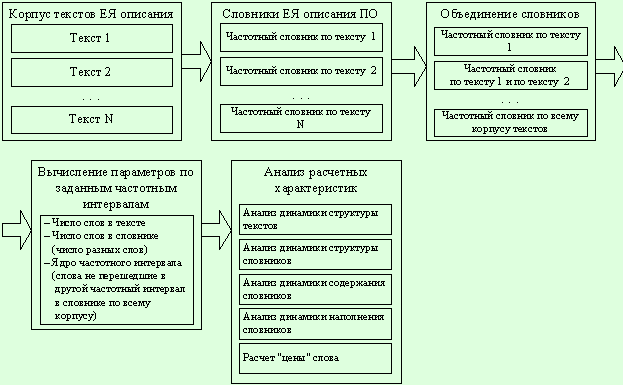
Рис. 33. Схема
проведения динамического анализа
Для проведения анализа динамических
характеристик необходимо сформировать развернутый во времени корпус текстов. Например,
это могут быть тексты разных номеров одного и того же периодического издания
(журнала, газеты и т.п.). Каждый из этих текстов должен быть представлен в
электронном виде в формате, доступном для обработки его в системе “Интерлекс”.
По каждому из текстов необходимо построить частотный словник.
Для проведения динамического анализа
нажмите кнопку “Динамический анализ”. На экране появится окно (рис. 34):
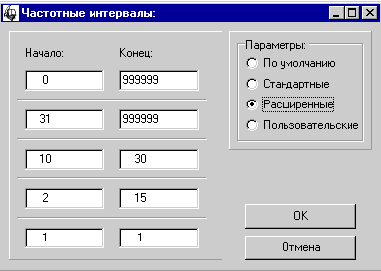
Рис. 34. Задание
частотных интервалов
В этом окне необходимо задать
частотные интервалы, за которыми будет проводится наблюдение. Всего можно
задать до 5 различных интервалов.
В системе “Интерлекс” имеется
возможность задать предопределенные параметры. Для этого существует
переключатель:
– По умолчанию. Устанавливает все
частотные интервалы в [0, 999999].
– Стандартные. Первые два интервала
[0, 999999], далее [6, 999999], [2, 5] и [1, 1].
– Расширенные [0, 999999], [31,
999999], [10, 30], [2, 15], [1, 1].
– Пользовательские. Интервалы могут
принимать произвольные значения.
Задание конкретных значений зависит
от максимальной частоты слова в построенных словниках.
После ввода частотных интервалов
нажмите “OK”. Процесс динамического анализа может занять некоторое время, о чем
будет сообщено в открывшемся окне.
Результат динамического анализа
сводится в таблицу с именем _DYNTBL_.DB, которая расположена в
подкаталоге DATA системы “Интерлекс”. Чтобы просмотреть эту таблицу, запустите
утилиту DBD32, сделайте рабочим каталогом ссылку “INTERLEX”, через меню file
-> open -> table откройте таблицу _dyntbl_.db.
Формат таблицы _dyntbl_.db
Эта таблица имеет следующую
структуру:
– поле “ТеxtID”: идентификатор
(номер) исходного текста, для которого сделан анализ;
– поле “LowFreq”: нижняя граница
частотного интервала;
– поле “HighFreq”: верхняя граница
частотного интервала;
– поле “TotalForms”: общее число
слов в тексте, попавших в частотный интервал;
– поле “DifForms”: число разных
слов, попавших в частотный интервал;
– поле “ConstsForms”: ядро
частотного интервала (число слов, оставшихся в данном частотном интервале в
словнике по всему корпусу текстов);
– поля “AVG” и “DISP” не
используются и равны 0.
Максимальное количество текстов,
которые могут участвовать в динамическом анализе, — 50. Система всегда включает
в файл “_dyntbl_.db” информацию о 50 текстах. Если текстов меньше, то в таблице
записи, для которых текстов не существует (TextID> максимального значения),
копируются значения параметров последнего построенного словника, т.е. словника
по всему корпусу текстов.
Использование значений таблицы
“_dyntbl_.db” для анализа динамики структуры текстов
Воспользуемся теперь полученными
значениями для анализа динамики структуры текстов. Для этого необходимо определить
долю слов (М) в каждом частотном интервале для каждого текста относительно
общего числа слов во всем корпусе текстов:
Пусть:
N (r1, r2, t) — число слов в тексте в частотном
интервале [r1, r2] для текста t.
M (r1, r2, t) — доля слов в частотном интервале [r1, r2] для текста t.
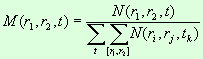
Результаты этого расчета можно
занести в MS Excel и представить их в виде таблицы (табл. 5):
Таблица 5
|
ЧИ |
Текст 1 |
Текст 2 |
Текст 3 |
... |
Текст N |
|
[r1, r2] |
M (r1, r2, 1) |
M (r1, r2, 2) |
M (r1, r2, 3) |
|
M (r1, r2, N) |
|
[r3, r4] |
M (r3, r4, 1) |
M (r3, r4, 2) |
M (r3, r4, 3) |
|
M (r3, r4, N) |
|
... |
|
|
|
|
|
|
[ri, rj] |
M (ri, rj, 1) |
M (ri, rj, 2) |
M (ri, rj, 3) |
|
M (ri, rj, N) |
|
|
|
|
|
|
|
По этой таблице можно построить
графики зависимости доли слов в частотном интервале от номера текста (или от
времени) для каждого частотного интервала.
Использование значений таблицы
“_dyntbl_.db” для анализа динамики структуры словников
Воспользуемся теперь полученными
значениями для анализа динамики структуры словников. Для этого необходимо
определить долю слов (М) в каждом частотном интервале для каждого текста
относительно общего числа слов в этом тексте:
Пусть:
N (r1, r2, t) — число слов в словнике в частотном
интервале [r1, r2] для текста t.
M (r1, r2, t) — доля слов в частотном интервале [r1, r2] для текста t.
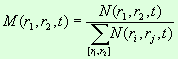
Результаты этого расчета можно
занести в MS Excel и представить их в виде таблицы (табл. 6):
Таблица 6
|
ЧИ |
Текст 1 |
Текст 2 |
Текст 3 |
... |
Текст N |
|
[r1, r2] |
M (r1, r2, 1) |
M (r1, r2, 2) |
M (r1, r2, 3) |
|
M (r1, r2, N) |
|
[r3, r4] |
M (r3, r4, 1) |
M (r3, r4, 2) |
M (r3, r4, 3) |
|
M (r3, r4, N) |
|
... |
|
|
|
|
|
|
[ri, rj] |
M (ri, rj, 1) |
M (ri, rj, 2) |
M (ri, rj, 3) |
|
M (ri, rj, N) |
|
|
|
|
|
... |
|
По этой таблице можно построить графики
зависимости доли слов в частотном интервале от номера текста (или от времени)
для каждого частотного интервала.
Использование значений таблицы
“_dyntbl_.db” для анализа динамики содержания словников
Воспользуемся теперь полученными
значениями для анализа динамики содержания словников. Для этого необходимо
определить долю слов (М) в каждом частотном интервале для каждого текста
относительно общего числа слов в этом частотном интервале во всем корпусе
текстов.
Пусть:
N (r1, r2, t) — число слов в словнике в частотном
интервале [r1, r2] для текста t.
M (r1, r2, t) — доля слов в частотном интервале [r1, r2] для текста t.
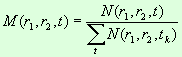
Результаты этого расчета можно
занести в MS Excel и представить их в виде таблицы (табл. 7):
Таблица 7
|
ЧИ |
Текст 1 |
Текст 2 |
Текст 3 |
... |
Текст N |
|
[r1, r2] |
M (r1, r2, 1) |
M (r1, r2, 2) |
M (r1, r2, 3) |
|
M (r1, r2, N) |
|
[r3, r4] |
M (r3, r4, 1) |
M (r3, r4, 2) |
M (r3, r4, 3) |
|
M (r3, r4, N) |
|
... |
|
|
|
|
|
|
[ri, rj] |
M (ri, rj, 1) |
M (ri, rj, 2) |
M (ri, rj, 3) |
|
M (ri, rj, N) |
По этой таблице можно построить
графики зависимости доли слов в частотном интервале от номера текста (или от
времени) для каждого частотного интервала.
Использование значений таблицы
“_dyntbl_.db” для анализа динамики наполнения словников
Воспользуемся теперь полученными
значениями для анализа динамики наполнения словников. Для этого необходимо
определить долю слов (М) в каждом частотном интервале для каждого текста относительно
общего числа слов в этом частотном интервале во всем корпусе текстов.
Пусть:
N (r1, r2, t) — ядро частотного интервала [r1, r2] для текста t.
M (r1, r2, t) — доля ядра частотного интервала [r1, r2] для текста t.
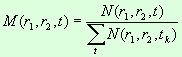
Результаты этого расчета можно
занести в MS Excel и представить их в виде таблицы (табл. 8):
Таблица 8
|
ЧИ |
Текст 1 |
Текст 2 |
Текст 3 |
... |
Текст N |
|
[r1, r2] |
M (r1, r2, 1) |
M (r1, r2, 2) |
M (r1, r2, 3) |
|
M (r1, r2, N) |
|
[r3, r4] |
M (r3, r4, 1) |
M (r3, r4, 2) |
M (r3, r4, 3) |
|
M (r3, r4, N) |
|
... |
|
|
|
|
|
|
[ri, rj] |
M (ri, rj, 1) |
M (ri, rj, 2) |
M (ri, rj, 3) |
|
M (ri, rj, N) |
По этой таблице можно построить
графики зависимости доли слов в частотном интервале от номера текста (или от
времени) для каждого частотного интервала.
Использование значений таблицы
“_dyntbl_.db” для расчета “цены” слова
Под “ценой” слова понимается
отношение изменения числа разных слов (числа слов в словнике) к изменению
общего числа слов.
Пусть:
N (r1, r2, t) — число разных слов (число слов в
словнике) для интервала [r1, r2] для текста t.
P (r1, r2, t) — общее число слов в тексте в частотном
интервале [r1, r2] для текста t.
C (r1, r2, t) — цена слова из частотного интервала [r1, r2] для текста t.
![]()
Результаты этого расчета можно
занести в MS Excel и представить их в виде таблицы (таблица 9):
Таблица 9
|
ЧИ |
Текст 1 |
Текст 2 |
Текст 3 |
... |
Текст N–1 |
|
[r1, r2] |
C (r1, r2, 1) |
C (r1, r2, 2) |
C (r1, r2, 3) |
|
C (r1, r2, N) |
|
[r3, r4] |
C (r3, r4, 1) |
C (r3, r4, 2) |
C (r3, r4, 3) |
|
C (r3, r4, N) |
|
... |
|
|
|
|
|
|
[ri, rj] |
C (ri, rj, 1) |
C (ri, rj, 2) |
C (ri, rj, 3) |
|
C (ri, rj, N) |
Пример 5
Исходные данные:
– Корпус текстов компьютерного
еженедельника “Computer Week”, 1995 (№1, 2, 3, 4, 5, 6, 7, 8, 9).
Задача:
Провести динамический анализ текстов
на примере первых 9 номеров еженедельника “Computer Week”, исследовать динамику
структуры текстов, динамику структуры словников, динамику содержания словников,
динамику наполнения словников, вычислить “цену” слов.
Построить необходимые графики.
Провести исследование для частотных
интервалов:
[1,1], [2,5], [6,inf].
Решение:
1. Постройте частотные словники для
каждого из текстов.
2. Нажмите кнопку “Динамический
анализ”.
3. Установите значения частотных
интервалов — стандартные.
4. Нажмите “OK”.
5. Дождитесь окончания процесса.
6. Запустите утилиту DBD32, входящую
в состав комплекса “Интерлекс”.
7. Откройте файл “_dyntbl_.db”,
расположенный в подкаталоге DATA (рис. 35).
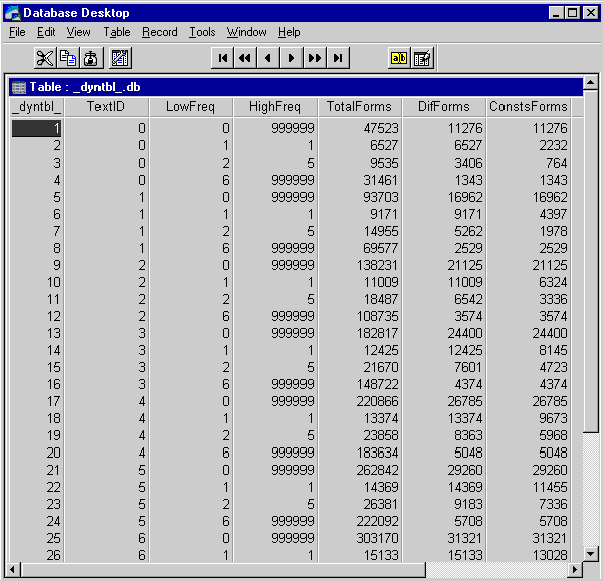
Рис. 35. Таблица
“_dyntbl_.db” после проведения динамического анализа первых 9 текстов
еженедельника “Computer Week”
Параметр TextID — индекс текста.
Необходимо помнить, что в динамическом анализе все параметры рассчитываются по
совокупности текстов. Например, параметры для TextID=0 соответствуют параметрам
по тексту 1, параметры для TextID=2 — параметрам, полученным по текстам 1 и 2,
как если бы это был один текст и, наконец, TextID=9 — параметры по всему
корпусу текстов, т.е. по всем 9 журналам еженедельника “Computer Week”.
Необходимо обратить внимание, что
каждому TextID соответствует 4 частотных интервала:
– [0, 999999]
– [1, 1]
– [2, 5]
– [6, 999999]
Здесь 999999 является эквивалентом
бесконечности (inf).
8.
Проведем анализ
динамики структуры текстов. Для этого запустим MS Excel и скопируем данные по
всем текстам и частотным интервалам по параметру “Общее число слов”
(TotalForms), сформируем таблицу (табл. 10) и построим графики (рис. 36).
Таблица 10
|
|
T1 |
T2 |
T3 |
T4 |
T5 |
T6 |
T7 |
T8 |
T9 |
|
[0,999999] |
47523 |
93703 |
138231 |
182817 |
220866 |
262842 |
303170 |
349144 |
393500 |
|
[1,1] |
6527 |
9171 |
11009 |
12425 |
13374 |
14369 |
15133 |
15943 |
16813 |
|
[2,5] |
9535 |
14955 |
18487 |
21670 |
23858 |
26381 |
28270 |
30482 |
32176 |
|
[6,999999] |
31461 |
69577 |
108735 |
148722 |
183634 |
222092 |
259767 |
302719 |
344511 |
|
|
47523 |
93703 |
138231 |
182817 |
220866 |
262842 |
303170 |
349144 |
393500 |
|
|
|
|
|
|
|
|
|
|
|
|
|
T1 |
T2 |
T3 |
T4 |
T5 |
T6 |
T7 |
T8 |
T9 |
|
[0,999999] |
0,12077 |
0,238127 |
0,351286 |
0,464592 |
0,561286 |
0,667959 |
0,770445 |
0,887278 |
1 |
|
[1,1] |
0,016587 |
0,023306 |
0,027977 |
0,031576 |
0,033987 |
0,036516 |
0,038457 |
0,040516 |
0,042727 |
|
[2,5] |
0,024231 |
0,038005 |
0,046981 |
0,05507 |
0,06063 |
0,067042 |
0,071842 |
0,077464 |
0,081769 |
|
[6,999999] |
0,079952 |
0,176816 |
0,276328 |
0,377947 |
0,466668 |
0,564402 |
0,660145 |
0,769299 |
0,875504 |
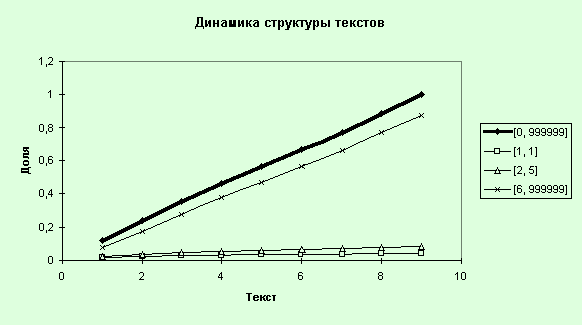
Рис. 36. Динамика
структуры текстов
9. Проведем анализ динамики
структуры словников. Для этого запустим MS Excel и скопируем данные по всем
текстам и частотным интервалам по параметру “Количество разных слов”
(DifForms), сформируем таблицу (табл. 11) и построим графики (рис. 37).
Таблица 11
|
|
T1 |
T2 |
T3 |
T4 |
T5 |
T6 |
T7 |
T8 |
T9 |
|
[0,999999] |
11276 |
16962 |
21125 |
24400 |
26785 |
29260 |
31321 |
33536 |
35648 |
|
[1,1] |
6527 |
9171 |
11009 |
12425 |
13374 |
14369 |
15133 |
15943 |
16813 |
|
[2,5] |
3406 |
5262 |
6542 |
7601 |
8363 |
9183 |
9847 |
10592 |
11172 |
|
[6,999999] |
1343 |
2529 |
3574 |
4374 |
5048 |
5708 |
6341 |
7001 |
7663 |
|
|
11276 |
16962 |
21125 |
24400 |
26785 |
29260 |
31321 |
33536 |
35648 |
|
|
T1 |
T2 |
T3 |
T4 |
T5 |
T6 |
T7 |
T8 |
T9 |
|
[0,999999] |
1 |
1 |
1 |
1 |
1 |
1 |
1 |
1 |
1 |
|
[1,1] |
0,57884 |
0,540679 |
0,521136 |
0,509221 |
0,499309 |
0,49108 |
0,483158 |
0,4754 |
0,471639 |
|
[2,5] |
0,302057 |
0,310223 |
0,30968 |
0,311516 |
0,312227 |
0,313841 |
0,31439 |
0,31584 |
0,313398 |
|
[6,999999] |
0,119103 |
0,149098 |
0,169183 |
0,179262 |
0,188464 |
0,195079 |
0,202452 |
0,208761 |
0,214963 |
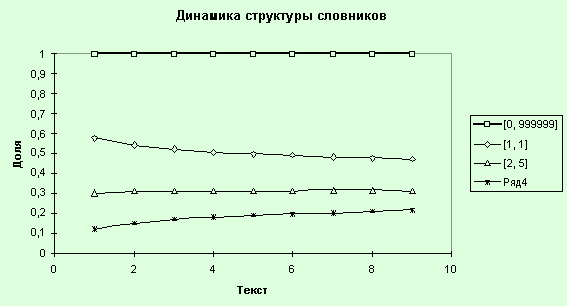
Рис. 37. Динамика
структуры словников
10. Проведем анализ динамики
содержания словников. Для этого запустим MS Excel и скопируем данные по всем
текстам и частотным интервалам по параметру “Количество разных слов”
(DifForms), сформируем таблицу (табл. 12) и построим графики (рис. 38).
Таблица 12
|
|
T1 |
T2 |
T3 |
T4 |
T5 |
T6 |
T7 |
T8 |
Т9 |
|
[0,999999] |
11276 |
16962 |
21125 |
24400 |
26785 |
29260 |
31321 |
33536 |
35648 |
|
[1,1] |
6527 |
9171 |
11009 |
12425 |
13374 |
14369 |
15133 |
15943 |
16813 |
|
[2,5] |
3506 |
5262 |
6542 |
7601 |
8363 |
9183 |
9847 |
10592 |
11172 |
|
[6,99999] |
1343 |
2529 |
3574 |
4374 |
5048 |
5708 |
6341 |
7001 |
7663 |
|
|
Т1 |
Т2 |
Т3 |
Т4 |
Т5 |
Т6 |
Т7 |
Т8 |
Т9 |
|
[0,99999] |
0,316315 |
0,475819 |
0,5926 |
0,68447 |
0,751375 |
0,820803 |
0,878619 |
0,940754 |
1 |
|
[1,1] |
0,388212 |
0,545471 |
0,654791 |
0,739011 |
0,795456 |
0,854636 |
0,900077 |
0,948254 |
1 |
|
[2,5] |
0,304869 |
0,470999 |
0,585571 |
0,680362 |
0,748568 |
0,821966 |
0,8814 |
0,948084 |
1 |
|
[6,99999] |
0,175258 |
0,330027 |
0,466397 |
0,570795 |
0,65875 |
0,744878 |
0,827483 |
0,913611 |
1 |
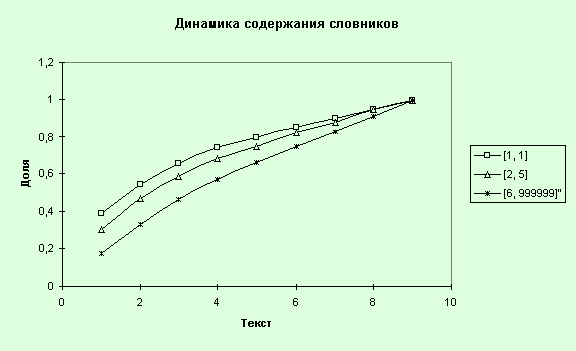
Рис. 38. Динамика
содержания словников
11. Проведем анализ динамики наполнения
словников. Для этого запустим MS Excel и скопируем данные по всем текстам и частотным
интервалам по параметру “Постоянное число слов в ЧИ” (ConstsfForms), сформируем
таблицу (табл. 13) и построим графики (рис. 39).
Таблица 13
|
|
Т1 |
Т2 |
Т3 |
Т4 |
Т5 |
Т6 |
Т7 |
Т8 |
Т9 |
|
[0,999999] |
11276 |
16962 |
21125 |
24400 |
26785 |
29260 |
31321 |
33536 |
35648 |
|
[1,1] |
6527 |
9171 |
11009 |
12425 |
13374 |
14369 |
15133 |
15943 |
16813 |
|
[2,5] |
3506 |
5262 |
6542 |
7601 |
8363 |
9183 |
9847 |
10592 |
11172 |
|
[6,99999] |
1343 |
2529 |
3574 |
4374 |
5048 |
5708 |
6341 |
7001 |
7663 |
|
|
Т1 |
Т2 |
Т3 |
Т4 |
Т5 |
Т6 |
Т7 |
Т8 |
Т9 |
|
[0,99999] |
0,316315 |
0,475819 |
0,5926 |
0,68447 |
0,751375 |
0,820803 |
0,878619 |
0,940754 |
1 |
|
[1,1] |
0,388212 |
0,545471 |
0,654791 |
0,739011 |
0,795456 |
0,854636 |
0,900077 |
0,948254 |
1 |
|
[2,5] |
0,304869 |
0,470999 |
0,585571 |
0,680362 |
0,748568 |
0,821966 |
0,8814 |
0,948084 |
1 |
|
[6,99999] |
0,175258 |
0,330027 |
0,466397 |
0,570795 |
0,65875 |
0,744878 |
0,827483 |
0,913611 |
1 |
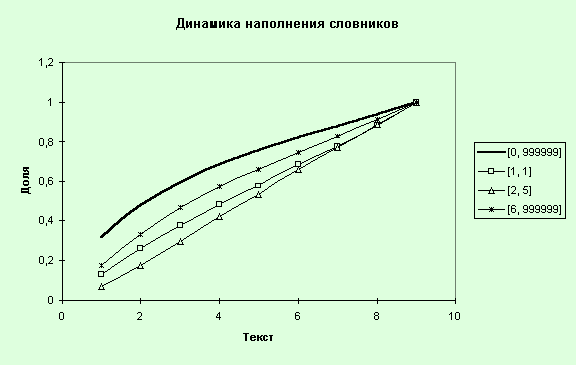
Рис. 39. Динамика
наполнения словников
12. Проведем анализ динамики
наполнения словников. Воспользуемся уже построенными таблицами (см. табл. 10,
11). Построим табл. 14, согласно формуле в разделе “Использование значений
таблицы “_dyntbl_.db” для расчета “цены” слова”, после чего построим график
“цены” слова (рис. 40).
Таблица 14
|
|
T1 |
T2 |
T3 |
T4 |
T5 |
T6 |
T7 |
T8 |
|
[0,999999] |
0,123127 |
0,093492 |
0,073454 |
0,062682 |
0,058962 |
0,051106 |
0,048179 |
0,047615 |
|
[1,1] |
1 |
1 |
1 |
1 |
1 |
1 |
1 |
1 |
|
[2,5] |
0,342435 |
0,362401 |
0,332705 |
0,348263 |
0,32501 |
0,351509 |
0,336799 |
0,342385 |
|
[6,999999] |
0,031116 |
0,026687 |
0,020007 |
0,019306 |
0,017162 |
0,016802 |
0,015366 |
0,01584 |
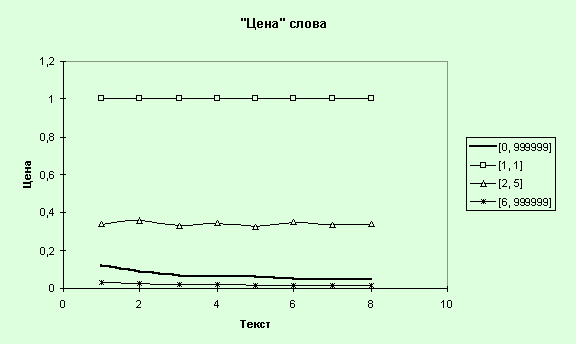
Рис. 40. “Цена”
слова
Построение группового словника
![]()
Под групповым словником понимается
частотный словник, который получается сложением двух и более уже построенных
словников. Так, если были построены частотные словники по текстам A, B и C, то
может быть построен групповой словник, который будет соответствовать частотному
словнику по тексту A+B+C (знак + означает конкатенацию текстов).
Групповые словники в неявном виде
строились при динамическом анализе, однако в системе имеется возможность
построить и в явном виде.
Для построения группового словника
нажмите кнопку “Построить групповой словник”. На экране появится окно (рис.
41).
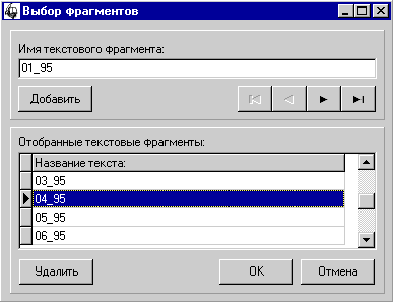
Рис. 41. Выбор
текстов (или фрагментов текста) для построения группового словника
В этом окне необходимо указать имена
тех текстов (точнее словников), по которым будет сформирован групповой словник.
Список уже отобранных текстов отображается в таблице. По умолчанию, в этот
список попадают все тексты, по которым строились частотные словники. С помощью
клавиши “Удалить” можно исключить ненужный текст из списка, а с помощью панели
навигации и кнопки “Добавить” новый текст может быть в него включен.
После того как список текстов, по
которым будет построен групповой словник, сформирован, нужно нажать клавишу
“OK”.
Процесс построения группового
словника может занять некоторое время. Следует отметить, что реальные тексты не
участвуют в построении группового словника. Групповой словник строится
исключительно на основе соответствующих частотных словников.
Результат помещается в специальную
таблицу с именем “_wftbl_.db”, которая размещается в подкаталоге DATA. Для ее
просмотра удобно воспользоваться утилитой DBD32, входящей в состав комплекса
“Интерлекс” (рис. 42).
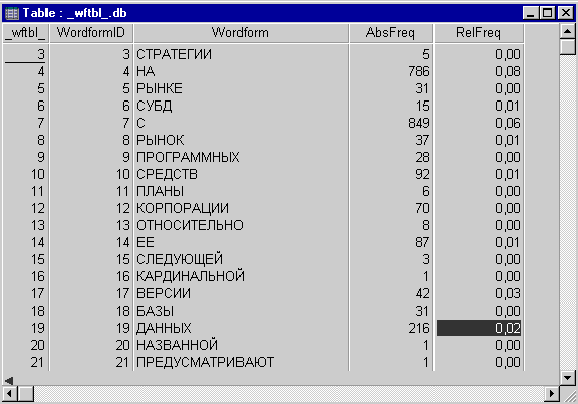
Рис. 42. Просмотр
группового словника с помощью утилиты DBD32
Формат таблицы “_wftbl_.db”
Эта таблица имеет следующую
структуру:
– WordformID — внутренний
идентификатор словоформы;
– Wordform — словоформа;
– AbsFreq — абсолютная частота
встречаемости словоформы в текстах, вошедших в группу;
– RelFreq — относительная частота
встречаемости словоформы в текстах, вошедших в группу.
Относительная частота определяется
через отношение абсолютной частоты встречаемости словоформы к общему числу слов
в группе текстов.
Пример 6
Исходные данные:
Построенные в примере 5 частотные
словники по 9 текстам журнала еженедельника “Сomputer Week”.
Задача:
Построить групповой словник по
журналам с номерами 1, 3, 5, 7, 9.
Решение:
1. Нажмите кнопку “Построить
групповой словник”.
2. С помощью клавиши “Удалить”
исключите из списка тексты, которые не войдут в групповой словник. Это тексты
02_95, 04_95, 06_95 и 08_95. Убедитесь, что в списке остались только те тексты
журналов, номера которых перечислены в задании.
3. Нажмите “OK” и дождитесь окончания
процесса.
4. Запустите утилиту DBD32, откройте
таблицу “_wftbl_.db”.
5. Данные в таблице — это групповой словник по текстам журналов с номерами
1, 3, 5, 7 и 9.
Сравнение текстов ![]()
Сравнение текстов (или проверка
гипотезы об “однородности” текстов) является одним из инструментов, позволяющих
выяснить, являются ли два текста представлением одной и той же предметной
области, жанра и стиля. В основу такого сравнения положены два правила.
Чтобы тексты были “однородными”,
необходимо:
1. Чтобы их словники были приблизительно
одинаковы. Речь идет о словарном составе словников. Иными словами, в текстах
должны использоваться “одинаковые” слова.
2. Расположение этих слов в
упорядоченном по убыванию частоты частотном словнике также должно быть
приблизительно одинаковым.
К сожалению, эти два критерия можно
назвать необходимыми, но они не являются достаточными. И причина в том, что
формальных методов, оперирующих только с частотной информацией о
естественно-языковых единицах недостаточно для выводов о семантической природе
текстов.
Таким образом, сравнение текстов
может служить лишь формальным инструментом, позволяющим сравнивать структурные
особенности текстов.
Для проверки “однородности” двух
текстов необходимо построить их частотные словники (см. раздел “Построение частотного
словника”), а затем нажать на кнопку “Проверка однородности текстов”. На экране
появится окно (рис. 43):
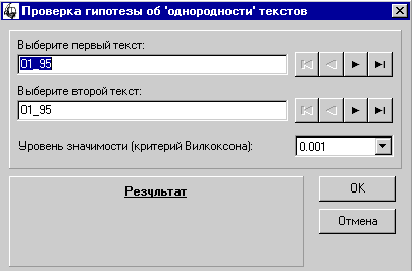
Рис. 43. Проверка гипотезы
об “однородности” текстов
Проверка гипотезы производится с
помощью статистического критерия Вилкоксона, позволяющего судить об
однородности двух выборок. Указанные выше критерии формируют числовые ряды,
которые можно использовать рассматривать как выборки в критерии Вилкоксона.
С помощью панелей навигации выберите
два текста, подлежащих сравнению, задайте уровень значимости и нажмите “OK”.
На панели c названием “Результат”
будет выведено:
“Гипотеза подтверждена...” или
“Гипотеза не подтверждена...”
Пример 7
Исходные данные:
Построенные в примере 5 частотные
словники по 9 текстам журнала еженедельника “Сomputer Week”.
Задача:
Проверить гипотезу об однородности
текстов журнала №1 и 9 при 5%-ном уровне доверия.
Решение:
1. Нажмите кнопку “Проверка гипотезы
об однородности текстов”.
2. С помощью панелей навигации
выберите тексты с именами 01_95 и 09_95.
3. Установите уровень доверия: 0.05.
4. Нажмите “OK”.
5. Результат: “Гипотеза подтверждена
с уровнем значимости 0.5000”.
Расчет параметров
распределения ![]()
С помощью этой функции системы
“Интерлекс” есть возможность получать реальные параметры и функциональные
зависимости распределения в модели “ранг-частота”.
Ранг и частота являются важнейшими
атрибутами элементов частотного словника:
– ранг — это порядковый номер слова
в упорядоченном по убыванию частоты словнике;
– частота — формальный параметр
слова (словоформы) в словнике, характеризующий частоту его (ее) появления в
исходном тексте.
Наиболее известны два закона,
связывающих эти две характеристики:
1. Закон Ципфа:
![]()
где k — число слов в тексте; r — ранг слова, i(k,r) - абсолютная частота.
2. Закон Ципфа в общем виде: ![]() , где k — число слов в тексте; r
— ранг слова; i(k,r) — абсолютная частота; p, b — параметры распределения.
, где k — число слов в тексте; r
— ранг слова; i(k,r) — абсолютная частота; p, b — параметры распределения.
3. Закон Мандельброта: i(k,
r) = pk(r + v) -b, где k — число
слов в тексте; p, v, b — параметры
распределения; r — ранг слова; i(k,r) — абсолютная частота.
С помощью системы “Интерлекс” можно
найти параметры распределения Ципфа и Мандельброта, а также получить свое
собственное распределение для текстов определенного класса.
Система “Интерлекс” позволяет
аппроксимировать реальное распределение “ранг-частота” с помощью полиномов первого,
второго, третьего, четвертого и пятого порядков (на основе метода наименьших
квадратов). Система рассчитывает коэффициенты этих полиномов, которые могут
быть преобразованы в соответствующие параметры распределения Ципфа и
Мандельброта.
Расчет параметров ведется по всем
текстам, частотные словники которых были построены в системе.
Для расчета параметров распределения
модели “ранг-частота” нажмите кнопку “Параметры распределения ранг-частота”. На
экране появится окно (рис. 44):
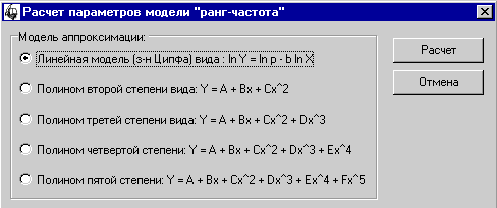
Рис. 44. Расчет
параметров модели “ранг-частота”
Выберите модель аппроксимации
(полином 1–5 порядка) и нажмите OK.
После окончания процесса расчета
параметров на экран будет выведено (рис. 45):
Рис. 45. Расчет
модели произведен
Результаты расчета всегда помещаются
в таблицу с именем “_rfprm_.db”, которая расположена в подкаталоге DATA.
Для ее просмотра можно
воспользоваться утилитой DBD32 (рис. 46):
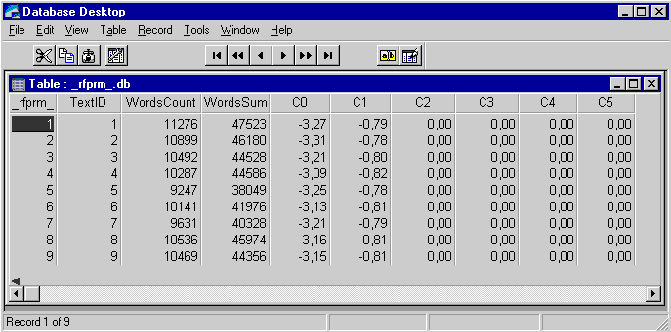
Рис. 46. Таблица параметров
распределения в модели “ранг-частота”
Формат таблицы “_rfprm_.db”
Таблица имеет следующую структуру:
– TextID — идентификатор текста, к
которому относятся рассчитанные параметры;
– WordsCount — число разных слов в
тексте (число слов в словнике);
– WordsSum — общее число слов в
тексте;
·
С0, С1, ..., C5 — коэффициенты
полинома:
![]()
где i(k, r) —
абсолютная частота; k — число слов в тексте (т.е. WordsSum); r —
ранг слова.
Для получения приближенных значений
параметров в законе Мандельброта можно воспользоваться формулами:
|
|
(1) |
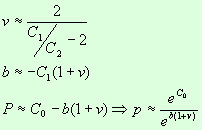
Значения C0, C1, C2 — коэффициенты
полинома второго порядка.
Для вычисления параметров
распределения з-на Ципфа можно воспользоваться точными формулами, которые можно
получить так:
|
|
|
|
|
|
|
|
(2) |
Здесь С0 и C1 — это коэффициенты полинома первого порядка
(т.е. линейной функции):
На рис. 47 приведены графики
распределения Ципфа и Мандельброта.
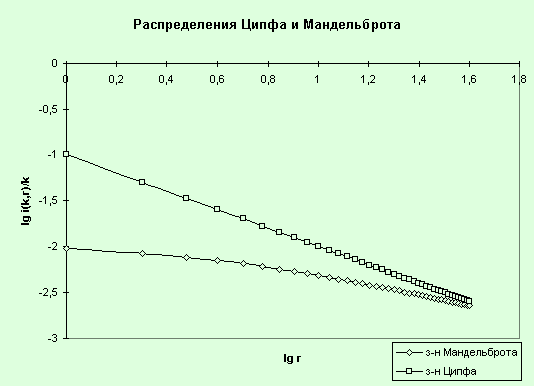
Рис. 47. Графики
распределения Ципфа (p=0.1, b=1) и Мандельброта (p=0.0271, b=0.66, v=4)
Пример 8
Исходные данные:
Построенные в примере 5 частотные
словники по 9 текстам журнала еженедельника “Сomputer Week”.
Задача:
Рассчитать параметры распределения
закона Ципфа (p и b) для всех 9 текстов журнала, построить теоретическую и
физическую кривые по первому тексту.
Решение:
1. Нажмите кнопку “Параметры
распределения ранг-частота”.
2. Выберите линейную модель
аппроксимации.
3. Дождитесь окончания процесса.
4. Запустите утилиту DBD32.
5. Откройте файл “_rfprm_.db”.
6. Перенесите данные в MS Excel и
постройте следующую таблицу (табл. 15). Параметры p и b можно рассчитать по
формулам (2).
Таблица 15
|
№ текста |
Разных слов |
Всего слов |
Kоэффициенты полинома первого порядка |
Параметры распределения в законе Ципфа |
||
|
|
|
|
С0 |
С1 |
р |
–b |
|
1 |
11276 |
47523 |
–3,27374 |
–0,7903 |
0,037865 |
–0,7903 |
|
2 |
10899 |
46180 |
–3,30789 |
–0,78295 |
0,036593 |
–0,78295 |
|
3 |
10492 |
44528 |
–3,20726 |
–0,79706 |
0,040467 |
–0,79706 |
|
4 |
10287 |
44586 |
–3,09058 |
–0,81634 |
0,045476 |
–0,81634 |
|
5 |
9247 |
38049 |
–3,24946 |
–0,78402 |
0,038795 |
–0,78402 |
|
6 |
10141 |
41976 |
–3,13149 |
–0,81254 |
0,043653 |
–0,81254 |
|
7 |
9631 |
40328 |
–3,2119 |
–0,79301 |
0,04028 |
–0,79301 |
|
8 |
10536 |
45974 |
–3,15722 |
–0,80717 |
0,042544 |
–0,80717 |
|
9 |
10469 |
44356 |
–3,15378 |
–0,80871 |
0,04269 |
–0,80871 |
7. Постройте групповой словник только
по первому тексту.
7.1. Нажмите кнопку “Построить
групповой словник”.
7.2. С помощью кнопки “Удалить”
оставьте в списке только текст с именем 01_95.
7.3. Нажмите кнопку “OK”.
7.4. Дождитесь окончания операции.
8. Запустите утилиту DBD32 и откройте
файл “_wftbl_.db”.
9. Перенесите частотный словник в MS
Excel.
10. Отсортируйте его по убыванию
частоты.
11. Вычислите значения ln r, ln
(RelFreq), ln p1 — b1ln r.
12. Постройте графики физического и
теоретического распределения (рис. 48).
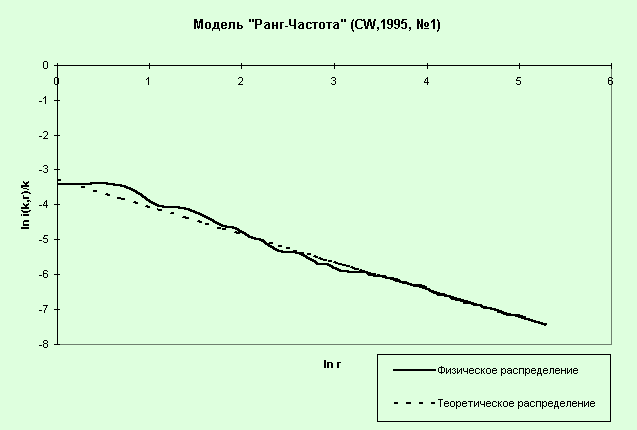
Рис. 48. Физическое
распределение и распределение Ципфа (p=0.037865, b=0.7903)
Режим “Словоформы” служит для
просмотра, добавления и редактирования словоформ. В отличие от режима “Словник”
режим “Словоформы” дает возможность работать со словником, в котором слова
упорядочены по алфавиту, а не по частотному признаку. Кроме того, в этом режиме
существует возможность просмотра всего списка слов, когда-либо введенных в
систему (без их привязки к конкретному тексту).
Режим “Словоформы” содержит важную
функцию — привязку словоформ к их леммам, т.е. словам в канонической форме.
Слова в канонической форме обычно являются элементами генерального словника и
являются заголовочными словами словарных статей семантического словаря.
Для перехода в режим после запуска
системы щелкните на закладке “Слоформы”. Главное окно системы примет вид (рис.
49):
Рис. 49. Режим
“Словоформы”
Таблица “Словоформ” (рис. 49)
состоит из двух полей:
– привязка;
– словоформа.
Поле “Привязка” может принимать
только два значения: “Не связано” и “Связано”. Если текущая словоформа является
словоизменением текущего слова из генерального словника (списка базовых слов),
то значение этого поля “Связано”, в противном случае “Не связано)”.
На панели режимов также имеется
независимый переключатель “Показывать все словоформы”. В активном состоянии в
таблице словоформ отображаются все имеющиеся в системе словоформы, в пассивном
— только словоформы, имеющие в поле “Привязка” значение “Связано”, т.е. все
словоизменения текущего слова из списка базовых слов.
Рис. 50 и 51 иллюстрируют типичные
состояния панели режима:
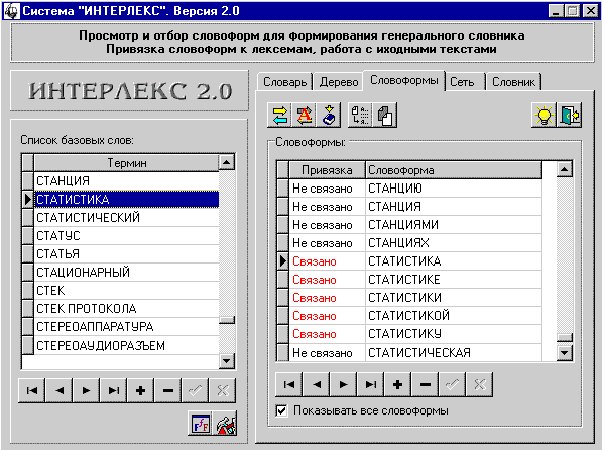
Рис. 50
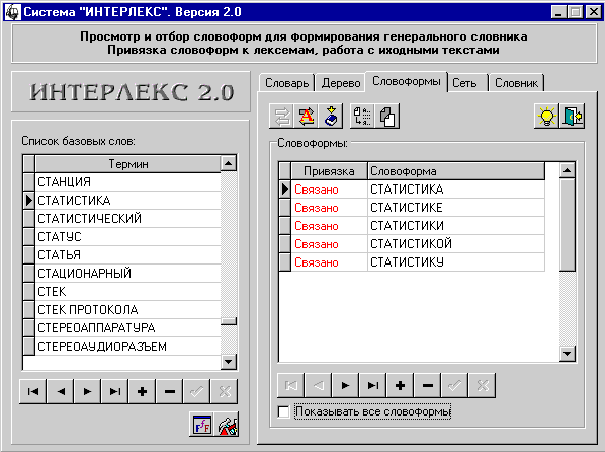
Рис. 51
На рис. 50 отображен весь список
словоформ (в алфавитном порядке), в котором словоформы “Статистика”,
“Статистике”, “Статистики”, “Статистикой”, “Статистику” привязаны к слову
“Статистика” из списка базовых слов.
На рис. 51 состояние панели режима,
когда отображаются только привязанные словоформы.
В данном режиме доступны следующие
функции:
|
|
Привязать или отвязать словоформу. |
|
|
Автоматическая привязка словоформ. |
|
|
Построение словника. |
|
|
Перенести словоформу в генеральный словник. |
|
|
Работа с исходными текстами. |
Доступна также панель навигации по
таблице словоформ, с помощью которой осуществляется ручное добавление новых
словоформ, их коррекция и удаление.
Добавление новых словоформ
При первом запуске системы таблица
словоформ не содержит записей. Чтобы добавить новые словоформы в таблицу, можно
воспользоваться:
– ручным вводом;
– автоматическим вводом.
Ручной ввод — это наиболее простой
способ добавления словоформ в систему. Для его использования нужно
воспользоваться панелью навигации. Нажмите на кнопку с изображением “![]() ” на панели навигации. В
таблице словоформ появится новая незаполненная строка, в которую необходимо
ввести новую словоформу. Если добавление производится при пассивном
переключателе “Показывать все словоформы”, то вводимая словоформа будет
автоматически привязана к текущему базовому слову. Для подтверждения окончания
ввода нажмите кнопку “
” на панели навигации. В
таблице словоформ появится новая незаполненная строка, в которую необходимо
ввести новую словоформу. Если добавление производится при пассивном
переключателе “Показывать все словоформы”, то вводимая словоформа будет
автоматически привязана к текущему базовому слову. Для подтверждения окончания
ввода нажмите кнопку “![]() ”. Если необходимо отказаться от введенного, то нужно нажать
на кнопку “
”. Если необходимо отказаться от введенного, то нужно нажать
на кнопку “![]() ” (рис
52).
” (рис
52).
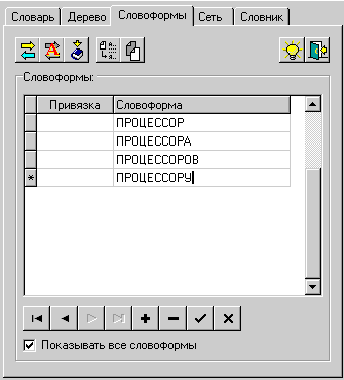
Рис. 52. Ручное
добавление словоформ
Ручной способ добавления новых
словоформ удобен для ввода отдельных словоформ, не связанных с каким-либо
конкретным текстом.
Если же необходимо ввести все или
часть словоформ из определенного текста, то следует использовать автоматический
способ.
Построение словника
(автоматический ввод словоформ) ![]()
Автоматический ввод словоформ
полностью совпадает с функцией построения частотных словников. Использование
этой функции одновременно выполняет и построение частотного словника и
добавляет новые записи в таблицу словоформ. Вызов этой функции можно осуществлять
как из режима “Словник” для добавления новых словоформ, так и из режима
“Словоформы” для построения частотных словников. Различаются только
представление данных в этих режимах.
Работа с исходными текстами ![]()
Система “Интерлекс” имеет
возможность работать одновременно с несколькими текстами. В лингвистической
базе данных системы каждому частотному словнику ставится в соответствие идентификатор
текста, на основе которого он был сформирован.
Перенос словоформ в
генеральный словник ![]()
Эта функция также совпадает с
одноименной в режиме “Словник”. Ее использование в режиме “Словоформы” служит
для аналогичных целей — для ручного переноса словоформ в список базовых
терминов, т.е. для формирования генерального словника.
Ручная привязка словоформ к
базовым словам ![]()
Функция ручной привязки словоформ
является инструментом, позволяющим поставить в соответствие некоторому базовому
слову (элементу генерального словника) его возможные формы, встречающиеся в
тексте или которые в принципе могут быть. Система не накладывает никаких
ограничений на связываемые естественно-языковые единицы. Наиболее типичным
является связывание канонической формы слова с его грамматическими формами. В
версии системы “Интерлекс 2.0” имеется возможность связывания словоформы только
с одним каноническим представлением, тогда как в языке можно привести примеры
омонимии, когда словоформа в зависимости от контекста может иметь различные
канонические формы. Например, словоформа “банка” может быть словоизменением
базового слова “банк” (родительный падеж, ед. ч.) либо быть самостоятельной
канонической формой; словоформа “засыпал” — либо словоизменение глагола
“заснуть”, либо глагола “засыпать (сыпать)” и т.п. Поэтому в подобных случаях
необходимо выбрать наиболее типичный вариант для исследуемого корпуса текстов.
Чтобы выполнить ручную привязку
словоформы к базовому слову, необходимо:
– выбрать в списке базовых слов
слово, к которому будет привязана словоформа;
– выбрать в списке словоформ
словоформу, которая будет привязана к базовому слову;
– нажать кнопку “Привязать/отвязать
словоформу”.
Если выбранные базовое слово и
словоформа уже были связаны, то применение этой функции выполнит обратную
операцию.
Пример 9
Исходные данные:
В списке базовых слов находится слово
“ПРОЦЕССОР”.
В списке словоформ — слова
“ПРОЦЕССОР”, “ПРОЦЕССОРА”, “ПРОЦЕССОРУ”, “ПРОЦЕССОРОВ”.
Задача:
Используя функцию ручной привязки
словоформ к базовым словам, привяжите указанные словоформы к базовому слову.
Решение:
1. Запустите систему и, если в
системе уже были данные, проинициализируйте системные таблицы.
2. Используя панель навигации,
введите в систему исходные данные.
3. Установите курсор на слово
“ПРОЦЕССОР” в списке базовых слов.
4. Установите курсор на слово
“ПРОЦЕССОР” в списке словоформ.
5. Нажмите кнопку “Привязать/отвязать
словоформу”.
6. Повторите операции 4 и 5 для
остальных словоформ, которые нужно привязать.
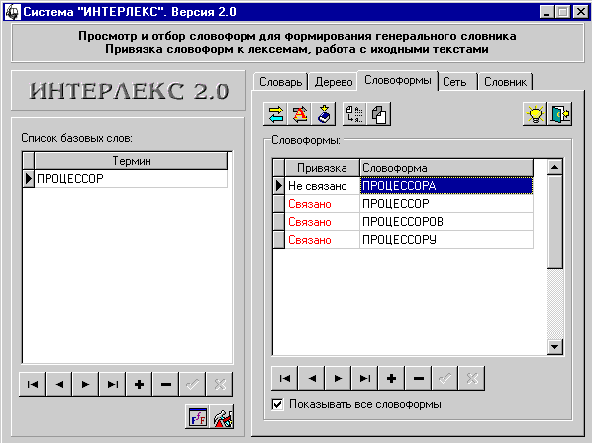
Рис. 52. Ручное
связывание словоформ и базовых слов
Автоматическая привязка
словоформ к базовым словам ![]()
Если число словоформ и базовых слов
достаточно велико, использование функции ручного связывания может оказаться
затруднительным или невозможным. В этом случае можно воспользоваться функцией
автоматической привязки всех словоформ к базовым словам.
Автоматическое связывание с помощью
эвристического алгоритма позволяет определить, что некоторая словоформа
является словоизменением некоторого базового слова. Этот алгоритм основан на
известном в лингвистике методе “квазиоснов”, который был доработан и
адаптирован для решения этой задачи.
Идея метода состоит в том, что в
каждом слове выделяется наибольшая его часть, которая остается неизменной в
словоизменительных и части словообразовательных форм.
Необходимо отметить, что реализованный
в системе метод не дает 100%-ной гарантии правильной привязки словоформ к
базовым словам, которые находятся в канонической форме. При использовании
автоматической привязки существует опасность возникновения ошибок I и II рода.
Ошибка I рода — произошла связка
словоформы и базового слова, в которой словоформа не является словоизменением
данного базового слова. Ошибка II рода — система не выполнила связки между
словоформой и базовым словом, где словоформа является словоизменением базового
слова.
Предполагается, что указанные ошибки
должны исправляться пользователем системы.
Необходимо также отметить, что метод
хорошо работает на словах длиной от 6–7 символов; на словах меньшей длины
возможно возникновение большого числа ошибок.
Для выполнения автоматической
привязки словоформ к базовым словам необходимо нажать кнопку “Автоматическая
привязка”.
Пример 10
Исходные данные:
В списке базовых слов находится слово
“ПРОЦЕССОР”.
В списке словоформ — слова
“ПРОЦЕССОР”, “ПРОЦЕССОРА”, “ПРОЦЕССОРУ”, “ПРОЦЕССОРОВ”.
Задача:
Используя функцию автоматической
привязки словоформ к базовым словам, привяжите указанные словоформы к базовому
слову.
Решение:
1. Запустите систему и, если в
системе уже были данные, проинициализируйте системные таблицы.
2. Используя панель навигации,
введите в систему исходные данные.
3. Нажмите кнопку “Автоматическая
привязка”.
Пример 11
Исходные данные:
Фрагмент словаря Ожегова (около 150
словарных статей) в текстовом файле формата ANSI-1521 (поставляется с
системой).
Задача:
Загрузить словарь в систему,
построить словник и выполнить автоматическое связывание словоформ и базовых
слов.
Решение:
1. Запустите систему и, если в
системе уже были данные, проинициализируйте системные таблицы.
2. Загрузите словарь Ожегова: войдите
в режим “Словарь”, нажмите на кнопку “Импорт словаря” (![]() ), выберите файл с именем OZHEGANS.TXT и
нажмите кнопку “Импорт”.
), выберите файл с именем OZHEGANS.TXT и
нажмите кнопку “Импорт”.
3. Перейдите в режим “Словоформы”. Постройте
словник по этому же файлу.
4. После окончания построения
словника система выдаст запрос (рис. 53):
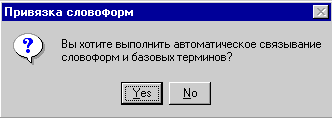
Рис. 53. Вы хотите
выполнить автоматическое связывание словоформ и базовых терминов?
5. Необходимо ответить “Да” либо,
ответив “Нет”, нажать на кнопку “Автоматическая привязка”.
6. Результат выполнения операции
приведен на рис. 54.
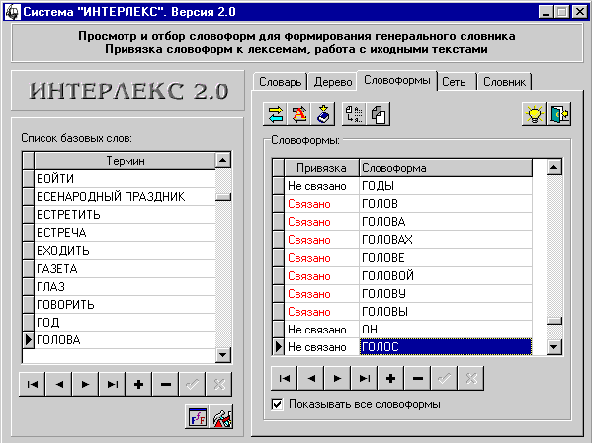
Рис. 54. Результат
автоматического связывания словоформ и базовых слов словаря Ожегова
Режим “Словарь” позволяет
сформировать словарные статьи семантического словаря по естественно-языковому
описанию предметной области. Семантический словарь, который формируется в
системе “Интерлекс 2.0”, имеет следующую структуру:
– базовое (или заголовочное) слово;
– семантическое поле, т.е.
совокупность всех возможных дефиниций (определений) заголовочного слова;
– эксцерпции, т.е. примеры
употребления заголовочного слова в исходном тексте или корпусе текстов;
– словоуказатель, т.е. сквозной
указатель строки, номер страницы и номер строки на странице эксцерпции.
Совокупность заголовочных слов
составляет генеральный словник семантического словаря ЕЯ описания ПО.
Для перехода в режим “Словарь”
необходимо щелкнуть на одноименной закладке. Главное окно системы примет вид
(рис. 55).
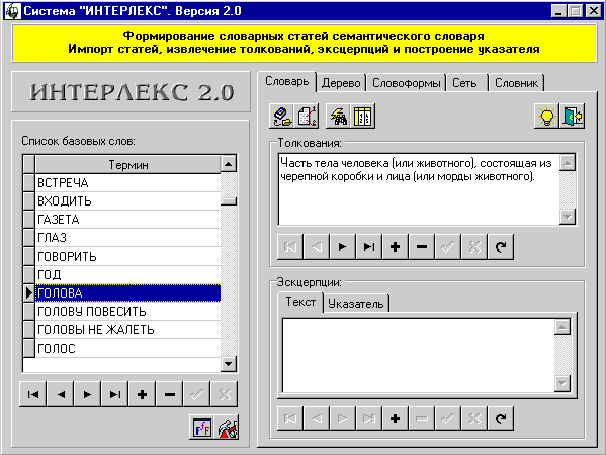
Рис. 55. Режим
“Словарь”
Каждое из четырех вышеперечисленных
полей семантического словаря может быть сформировано независимо от другого.
Единственное ограничение — это существование генерального словника. В системе
реализовано два разных подхода к формированию генерального словника:
– импорт словаря из текстового
файла, оформленного по определенным правилам;
– постепенное построение на основе
данных частотного, динамического и семантического анализа.
Первый способ построения
генерального словника и семантического поля наиболее прост. Для его
использования требуется наличие текста словарных статей какого-либо
семантического или толкового словаря или текст, содержащий дефиниции каких-либо
терминов. Второй способ значительно сложнее, требует от пользователя
определенных знаний в области лексикологии и лексикографии, но позволяет
сформировать генеральный словник (и словарь) в соответствии с намеченной целью.
В режиме “Словарь” доступны следующие
функции:
|
|
Импорт словарных статей, автоматическое извлечение базовых слов и их толкований из текстов. |
|
|
Извлечение эксцерпций из текста и построение указателя. |
|
|
Получение выборки из генерального словника. |
|
|
Вычисление числовых характеристик словаря. |
Импорт словарных статей ![]()
Функция импорта словарных статей
позволяет быстро сформировать генеральный словник семантического словаря на
основе словарных статей другого семантического или толкового словаря, а также
на основе текста, содержащего дефиниции терминов ЕЯ описания ПО. Система
“Интерлекс” имеет возможность анализировать структуру текстов и “узнавать”
синтаксические конструкции, используемые для оформления словарных статей и
определений в тексте. Использование этой функции особенно полезно, если
исходный текст содержит большое число определений и новых понятий, которые
разъясняются в тексте.
Для импорта словарных статей нажмите
кнопку “Импорт словаря”. На экране появится окно (рис. 56):
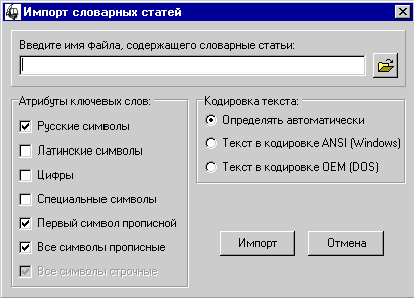
Рис. 56. Импорт
словарных статей
Введите имя файла, содержащего текст
словарных статей или дефиниции терминов. Допускаются только текстовые форматы
файлов либо в ANSI-1251 кодировке (для среды Windows), либо в кодировке DOS-866
(для среды MS DOS).
Выбор входного формата
Далее необходимо указать тип
кодировки, которой соответствует выбранный текстовый файл. Система “Интерлекс
2.0” поддерживает два формата текстовых файлов:
– MS Windows ANSI-1251.
– MS DOS OEM-866.
Если файл, подлежащий обработке,
имеет другой формат (например, DOC или RTF), то его следует пересохранить в
одном из указанных выше форматов. Как правило, все текстовые процессоры (MS
Word в том числе) имеют возможность сохранения документа как обычного
текстового файла.
Если вы знаете, что исходный текст
сохранен в одном из отмеченных форматов, но не знаете, в каком именно, можно
установить флажок в положение “Определять автоматически”. В этом случае перед
обработкой текста система попытается выяснить его формат на основе
статистических данных об используемых в нем символах. Этот метод безошибочно
работает на текстах объемом от 20–30 KB.
Задание фильтров
Перед началом импорта необходимо
также задать фильтр для слов. Система имеет возможность выбирать слова для
списка базовых слов, обладающих рядом заданных свойств (атрибутов). Всего для
слов определено 6 атрибутов.
Атрибуты, отмеченное состояние
которых говорит о ВОЗМОЖНОСТИ включения слов:
– Русские символы.
– Латинские символы.
– Цифры.
– Специальные символы.
– Первый символ прописной.
– Все символы прописные.
– Все символы строчные (всегда
отмечен).
Таким образом, отметив только
“Русские символы” и “Латинские символы”, вы получите список базовых слов, в
котором будут встречаться слова с символами русского или латинского алфавита, и
только. В этом случае в него может попасть слово, в котором часть символов
принадлежит русскому алфавиту, а часть — латинскому.
Принятие соглашения:
– Все цифры имеют атрибут “Прописной
символ”.
– Все числа имеют атрибут “Все
символы прописные”.
– Специальные символы:
#, $, %, &, /, <, >, =, \,
^,_,*, ~,@.
Специальные символы не являются
разделителями слов, а принадлежат к основному алфавиту системы.
– Каждый специальный символ имеет
атрибут “Прописной символ”.
– Любая комбинация только из
специальных символов имеет атрибут ““Все символы прописные”.
По умолчанию, система отмечает
фильтры:
– Русские символы.
– Первый символ прописной.
– Все символы прописные.
– Все символы строчные.
Это соответствует включению всех
слов только с русскими символами (регистр не важен).
После установки фильтров нажмите
кнопку “ИМПОРТ”.
После окончания процесса главное
окно системы примет вид (рис. 57):
Рис. 57. Результат
импорта словарных статей
Формат файла для импорта
словаря
Чтобы система могла успешно
импортировать словарные статьи и дефиниции терминов из исходного текста,
необходимо оформить их соответствующим образом. В дистрибутив системы включен
пример оформления словарных статей, которые могут быть автоматически введены в
систему (файл OZHEGANS.TXT). Этот файл содержит фрагмент словаря Ожегова (около
150 словарных статей):
БАБУШКА — 1. Мать отца или матери. 2.
Обращение к старой женщине (разг.). Бабушка надвое сказала (разг.) —
неизвестно, произойдет что-нибудь или нет.
БЕЖАТЬ — 1. Двигаться быстрым, резко
отталкивающимся от земли шагом.
Бежать рысью. 2. Быстро двигаться,
проходить, течь, миновать. Облака бегут. Дни бегут. Вода бежит ручьями. Кровь
бежит из раны. 3. Спасаться (спастись) бегством. Бежать из плена.
БЕЛЫЙ — 1. Цвета снега или мела;
противоп. черный. Белый флаг. 2. Светлый. Белый хлеб 3. Контрреволюционный.
Поражение белых (сущ.). 4. Со светлой кожей (как признак расы). Белая горячка —
тяжелая психическая болезнь на почве алкоголизма. Белая кость (ирон.) — о
дворянах. Белое мясо — о телячьем и курином мясе. Белый билет (устар.) —
свидетельство об освобождении от военной службы. Белый гриб — сорт съедобных
грибов. Белый уголь — о движущей силе воды. Средь бела дня (разг.) — днем,
когда совсем светло.
БИЛЕТ — 1. Документ, удостоверяющий
право пользоваться чем-нибудь за плату. Театральный билет. Железнодорожный
билет. Проездной билет. 2. Документ, удостоверяющий принадлежность к
какой-нибудь организации, партии, отношение к каким-нибудь обязанностям.
Партийный билет. Профсоюзный билет. Членский билет. Ученический билет.
Отпускной билет. Военный билет. 3. Бумажный денежный знак, документ. Кредитный
билет. Государственный казначейский билет. 4. Листок, карточка. Пригласительный
билет. Экзаменационный билет. Билетная касса.
БОЛЬШОЙ — 1. Значительный по размерам,
по величине, силе. Большой дом. Большая радость. Большая буква (прописная). 2.
Значительный, выдающийся (означает высшую степень признака, положительную или
отрицательную в зависимости от определяемого существительного). Большая победа.
Большой вопрос. Большой поэт. Большой плут. 3. Взрослый. Большой сын. Слушаться
больших (сущ.; взрослых). 4. Многочисленный. Большое знакомство. Большей частью
или по большей части — преимущественно. Самое большее — наиболее возможное, не
больше.
БУМАГА, 1 — 1. Материал для письма,
изготовляемый из древесной или тряпичной массы. Остаться на бумаге (перен.: о
решении, которое не выполняется). 2. Официальное письменное сообщение,
документ. Рыться в бумагах. Ценные бумаги (денежные документы).
БУМАГА, 2 — 1. Хлопок или изделия из
него.
ВЕРНУТЬСЯ — 1. Прийти обратно,
возвратиться. Вернуться домой. Вернуться к прежней мысли.
Оформление заголовочных слов
Заголовочные слова в словарных
статьях должны начинаться с прописной буквы. Рекомендуется все символы
заголовочных слов делать также прописными. Заголовочное слово может быть также
словосочетанием (не более трех слов), в котором разделителем между словами
является только пробел (или несколько пробелов). Если после заголовочного слова
(словосочетания) встречается любой другой знак препинания (кроме тире), то он и
все символы после него игнорируются.
Разделитель заголовочных слов
и их дефиниций
Основной меткой, что слово или
словосочетание есть заголовочное, является знак “тире”. Если предложение
содержит “тире” — это значит, что в нем, возможно, есть дефиниция.
Оформление дефиниций
Если слово имеет только одну
дефиницию, то оно должно следовать сразу же после “тире”. Рекомендуется
дефиницию начинать с прописной буквы. Дефиницией может быть только одно
предложение, содержащее любые знаки препинания (включая точку, если она служит
для оформления сокращения). Кроме того, возможно использование скобок, внутри
которых допускаются любые синтаксические конструкции. Загрузчик словарных
статей системы “Интерлекс” не является формальным “компилятором” или
“интерпретатором”, поэтому сообщение о синтаксической ошибке вы не получите.
Однако неправильно оформленные статьи могут быть введены не полностью или
неправильно. В связи с этим, особое внимание следует уделить количеству
открывающихся и закрывающихся скобок в дефинициях (круглых и квадратных).
Если слово имеет несколько
дефиниций, то их необходимо пронумеровать. Имеет значение только сам факт
нумерации, а не конкретное числовое значение перед дефиницией. После числового
номера дефиниции необходимо поставить точку, а новую дефиницию рекомендуется
начинать с большой буквы. Количество дефиниций у одного слова не ограничено.
Необходимо помнить, что дефиницией считается только одно предложение (первое
после “тире” или номера).
Оформление словарных статей
Если требуется импортировать в
систему несколько словарных статей, то жестким требованием является разделение
их хотя бы одной пустой строкой. В противном случае система может пропускать
некоторые словарные статьи или вводить их неправильно.
Ввод дефиниций из
произвольного текста
Отмеченных требований к оформлению
словарных статей оказывается достаточным для ввода в систему дефиниций
практически из любого текста. В этом случае работает одно-единственное правило:
если в тексте есть “тире”, значит, в нем, возможно, есть дефиниция.
Необходимо отметить, что в системе
не предусмотрено никаких переключателей для указания способа оформления
дефиниций (как словарных статей или как дефиниций в произвольном тексте). Это
значит, что любой анализируемый текст обрабатывается таким образом, что если в
нем обнаруживаются правильно оформленные словарные статьи, то они загружаются в
систему, если нет — тогда из текста извлекаются только отдельные дефиниции.
Пример 12
Исходные данные:
Текстовый файл, содержащий 150
словарных статей словаря Ожегова (файл OZHEGANS.TXT поставляется с системой).
Задача:
Импортировать в систему все
дефиниции.
Решение:
1. Запустите систему “Интерлекс”.
2. Перейдите в режим “Словарь”.
3. Нажмите кнопку “Импорт словаря”.
4. Выберите файл OZHEGANS.TXT.
5. Оставьте фильтры и кодировку
текста установленными по умолчанию.
6. Нажмите кнопку “Импорт”.
7. Дождитесь окончания выполнения
операции.
8. Внимательно изучите полученный
результат (рис. 58, рис. 59, табл. 16).
Рис. 58
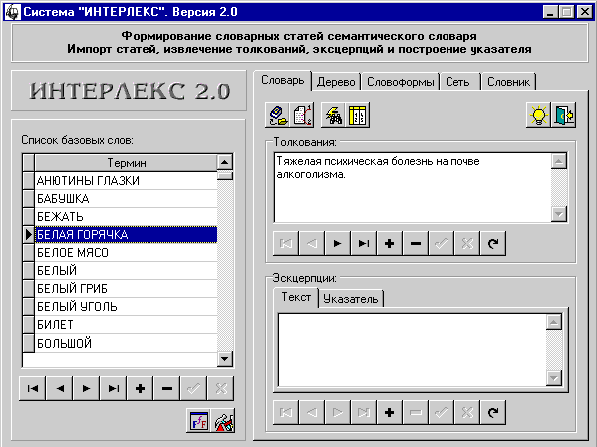
Рис. 59
Таблица 16
|
Заголовочное слово |
Дефиниции |
|
АНЮТИНЫ ГЛАЗKИ |
Трехцветные садовые фиалки. |
|
БАБУШKА |
Мать отца или матери. Обращение к старой женщине (разг.). |
|
БЕЖАТЬ |
Двигаться быстрым, резко отталкивающимся от земли шагом. Быстро двигаться, проходить, течь, миновать. Спасаться (спастись) бегством. |
|
БЕЛАЯ ГОРЯЧKА |
Тяжелая психическая болезнь на почве алкоголизма. |
|
БЕЛОЕ МЯСО |
О телячьем и курином мясе. |
|
БЕЛЫЙ |
Цвета снега или мела; противоп. черный. Светлый. Kонтрреволюционный. Со светлой кожей (как признак расы). |
|
БЕЛЫЙ ГРИБ |
Сорт съедобных грибов. |
|
БЕЛЫЙ УГОЛЬ |
О движущей силе воды. |
|
БИЛЕТ |
Документ, удостоверяющий право пользоваться чем-нибудь за плату. Документ, удостоверяющий принадлежность к какой-нибудь организации, партии, отношение к каким-нибудь обязанностям. Бумажный денежный знак, документ. Листок, карточка. |
|
БОЛЬШОЙ |
Значительный по размерам, по величине, силе. Значительный, выдающийся (означает высшую степень признака, положительную или отрицательную, в зависимости от определяемого существительного). Взрослый. Многочисленный. |
|
БУМАГА |
Материал для письма, изготовляемый из древесной или тряпичной массы. Официальное письменное сообщение, документ. Хлопок или изделия из него. |
|
В ГЛАЗА ГОВОРИТЬ |
Говорить в лицо, открыто. |
|
В ДОБРЫЙ ЧАС |
Пожелание счастливого пути, начинания. |
|
В ПЕРВУЮ ГОЛОВУ |
В первую очередь. |
|
В СТОРОНУ СKАЗАТЬ |
Немного отвернувшись, сказать тихо с тем, чтобы собеседник не услышал. |
|
. . . |
. . . . . . . . . |
Из примера хорошо видно, как система
импортирует словарные статьи и отдельные дефиниции из текста. Обратите внимание,
что именно взято в качестве дефиниций. Поскольку заголовочные слова в списке
базовых слов отображаются по алфавиту, в таблице 16 присутствуют слова и
словосочетания, которые были распознаны как заголовочные, но которых нет в
приведенном выше фрагменте файла OZHEGANS.TXT.
Извлечение эксцерпций и
построение словоуказателя ![]()
Под эксцерпциями в системе
“Интерлекс” понимаются примеры употребления базовых слов в тексте.
Словоуказатель — это указатель точного места в тексте, откуда была взята
соответствующая эксцерпция.
И эксцерпции и словоуказатель
объединены в одну функцию и отображаются на панели режимов (рис. 60, рис. 61):
|
Рис. 60. Текст эксцерпции |
Рис. 61. Словоуказатель |
Эксцерпции и словоуказатель являются
важными составляющими семантического словаря, поскольку обеспечивают
непосредственную связь базовых слов с конкретными текстами.
Система “Интерлекс” позволяет
извлекать эксцерпции из любого текста, при этом она использует механизм
“привязки словоформ с базовыми словами”, чтобы определить эксцерпции,
содержащие их словоизменения.
Система “Интерлекс” считает
эксцерпцией одно полное предложение. Каждому базовому слову может
соответствовать несколько эксцерпций. В системе нет ограничений на количество
эксцерпций для одного слова: из анализируемого текста выбираются все возможные
предложения, содержащие базовые слова.
Если эксцерпции вводятся
автоматически (а не посредством панели навигации), то для каждой из них
строится словоуказатель. Словоуказатель состоит из трех компонент:
– сквозной номер строки;
– номер страницы;
– номер строки на странице.
Поскольку система на вход получает
текстовый файл, то для поиска эксцерпций в нем удобно использовать сквозной
номер строки — номер строки, начиная от начала текста. Этот параметр не зависит
от разметки текста и разбиения его на страницы. По умолчанию, текст нумеруется
с первой строки.
Номер страницы и номер строки на
странице имеют смысл, если текст был предварительно размечен. Система
“Интерлекс” имеет возможность обрабатывать размеченные тексты и вести учет
номерам страниц. Разметку текста можно производить в любом текстовом редакторе,
а затем необходимо указать системе характеристики разметки.
Разметка исходных текстов
Все параметры, относящиеся к
разметке текста, хранятся в файле настроек SRCTEXT.INI (расположен в корневом
каталоге системы). После инсталляции системы этот файл имеет вид (рис. 62):
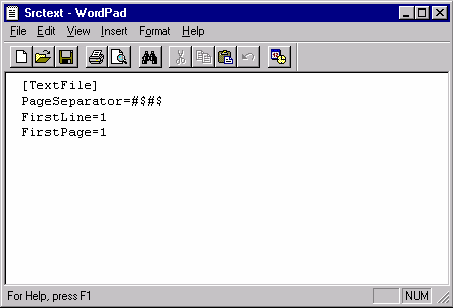
Рис. 62. Содержимое
файла настройки разметки текста SRCTEXT.INI
Файл настроек имеет одну секцию
[TextFile] и три параметра.
Параметр PageSeparator
Значением этого параметра является символьная
последовательность, используемая в системе “Интерлекс” для разделения текста на
страницы. Разметку текста можно выполнить в любом доступном текстовом
редакторе, а в файле настроек нужно указать соответствующую символьную
последовательность. По умолчанию, используется разделитель страниц #$#$.
Параметр FirstLine
Указывает номер первой строки на
странице. По умолчанию, имеет значение 1.
Параметр FirstPage
Указывает начало нумерации страниц в
тексте. По умолчанию, имеет значение 1.
Извлечение эксцерпций
Для извлечения эксцерпций нажмите
кнопку “Загрузка эксцерпций”. На экране появится окно (рис. 63):
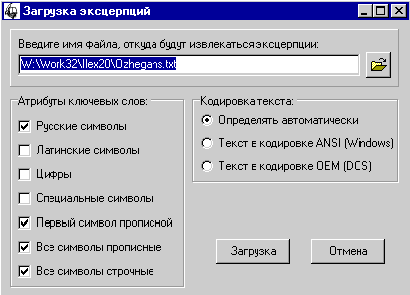
Рис. 63. Окно
загрузки эксцерпций
Введите имя файла, содержащего
текст, откуда будут извлекаться эксцерпции. Допускаются только текстовые
форматы файлов либо в ANSI-1251 кодировке (для среды Windows), либо в кодировке
DOS-866 (для среды MS DOS).
Выбор входного формата
Далее необходимо указать тип
кодировки, которой соответствует выбранный текстовый файл. Система “Интерлекс
2.0” поддерживает два формата текстовых файлов:
– MS Windows ANSI-1251.
– MS DOS OEM-866.
Если файл, подлежащий обработке,
имеет другой формат (например, DOC или RTF), то его следует пересохранить в
одном из указанных выше форматов. Как правило, все текстовые процессоры (MS
Word в том числе) имеют возможность сохранения документа как обычного
текстового файла.
Если Вы знаете, что исходный текст
сохранен в одном из отмеченных форматов, но не знаете, в каком именно, можно
установить флажок в положение “Определять автоматически”. В этом случае перед
обработкой текста система попытается выяснить его формат на основе
статистических данных об используемых в нем символах. Этот метод безошибочно
работает на текстах объемом от 20–30 KB.
Задание фильтров
Перед началом извлечения эксцерпций
необходимо также задать фильтр для слов. Система имеет возможность выбирать
эксцерпции, в которых базовые слова обладают рядом заданных свойств
(атрибутов). Всего для слов определено 6 атрибутов.
Атрибуты, отмеченное состояние
которых говорит о ВОЗМОЖНОСТИ включения слов:
– Русские символы.
– Латинские символы.
– Цифры.
– Специальные символы.
– Первый символ прописной.
– Все символы прописные.
– Все символы строчные.
Таким образом, отметив только
“Русские символы” и “Латинские символы”, вы получите эксцерпции, где в базовых
словах встретяться символы русского или латинского алфавита, и только.
Принятие соглашения:
– Все цифры имеют атрибут “Прописной
символ”.
– Все числа имеют атрибут “Все
символы прописные”.
– Специальные символы:
#, $, %, &, /, <, >, =, \,
^,_,*, ~,@.
Специальные символы не являются
разделителями слов, а принадлежат к основному алфавиту системы.
– Каждый специальный символ имеет
атрибут “Прописной символ”.
– Любая комбинация только из
специальных символов имеет атрибут “Все символы прописные”.
По умолчанию, система отмечает
фильтры:
– Русские символы.
– Первый символ прописной.
– Все символы прописные.
– Все символы строчные.
Это соответствует включению всех
слов только с русскими символами (регистр не важен).
После установки фильтров нажмите
кнопку “ЗАГРУЗКА”.
После окончания процесса главное
окно системы примет вид (рис. 64):
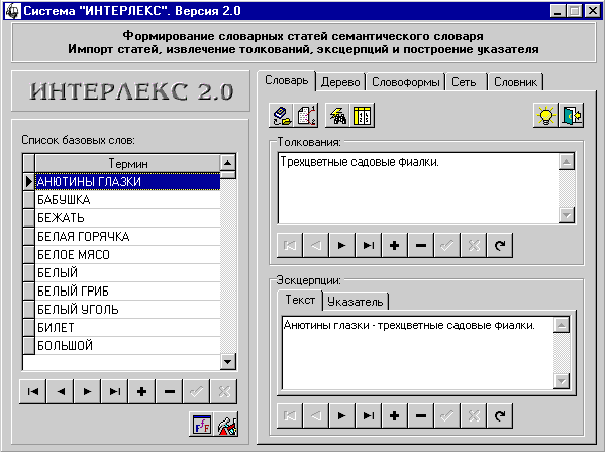
Рис. 64. Результат
извлечения эксцерпций
Пример 13
Исходные данные:
Текстовый файл, содержащий 150
словарных статей словаря Ожегова (файл OZHEGANS.TXT поставляется с системой).
Задача:
Импортировать словарные статьи,
извлечь из этого же текста эксцерпции и построить словоуказатель
Решение:
1. Запустите систему “Интерлекс”.
2. Очистите системные таблицы (см.
раздел “Настройка и инициализация рабочих таблиц”, стр. 22).
3. Выполните импорт словарных статей
из файла OZHEGANS.TXT (см. “Пример 12”, стр. 79).
4. Загрузите файл OZHEGANS.TXT в
текстовый редактор (например, в MS Word) и выполните разбиение на страницы. В
MS Word необходимо проставить жесткие границы, а затем заменить их на символьную
последовательность #$#$. После разметки файл необходимо сохранить как обычный
текст под именем OZHEGPG.TXT.
5. Нажмите кнопку “Загрузка
эксцерпций”.
6. Выберите файл OZHEGPG.TXT.
7. Кодировку текста и фильтры
оставьте установленными по умолчанию.
8. Нажмите кнопку “Загрузка” и
дождитесь окончания операции.
9. Результат будет отображен на
панели режимов.
Получение выборки из
генерального словника ![]()
Эта функция позволяет отобрать из
всего списка базовых слов те, которые удовлетворяют заданному пользователем
шаблону. Под шаблоном слова понимается регулярное выражение (или маска),
которое описывает некоторую совокупность естественно-языковых единиц.
В регулярное выражение могут входить
следующие символы:
– буквы русского и/или латинского
алфавита;
– цифры;
– символ “_”;
– символ “%”.
Символ “_” обозначает любой символ
алфавита, а символ “%” — любую последовательность символов алфавита. Например,
последовательность “___” (три символа “_”) обозначает все трехбуквенные слова,
а последовательность “%ЫЙ” — все слова, которые оканчиваются на “ЫЙ”.
Чтобы задать шаблон для получения
выборки из списка базовых слов, нажмите кнопку “Выборка терминов”. На экране
появится окно (рис. 65).
Рис. 65. Выборка из
списка базовых слов
Независимый переключатель “Включить
в режим выборки” позволяет включать или отключать режим выборки при отображении
списка базовых слов. Если необходимо отобразить только выборку (а не все
слова), то его необходимо перевести в активное состояние.
После чего в поле “Шаблон слова”
можно задать шаблон или выбрать уже готовый из списка.
Нажмите “OK”, чтобы слова,
удовлетворяющие шаблону, появились в списке базовых слов.
Обновление статистики.
В режиме “Словарь” имеется функция
для получения статистических характеристик словаря:
– числа толкований (дефиниций) для каждого
слова;
– числа эксцерпций для каждого
слова;
– числа связанных со словом
словоформ.
Чтобы получить эту информацию,
необходимо нажать на кнопку “Статистика словаря”. После сбора необходимых
данных на экране появится окно (рис. 66):
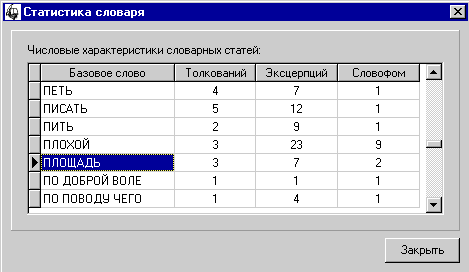
Рис. 66. Статистика
словаря
Режим “Дерево” служит для анализа
семантического словаря. Система “Интерлекс” позволяет построить сетевую
(древовидную) модель словаря на основе заголовочных слов, их дефиниций и
эксцерпций. Такая древовидная структура устанавливает отношения между
естественно-языковыми единицами словаря, а именно между базовыми словами.
Другими словами, древовидная структура отношений представляет собой тезаурус.
Система “Интерлекс” позволяет
построить тезаурус, который устанавливает отношения типа
“определяющее-определяемое”.
“Определяемое” — это
естественно-языковая единица (слово или словосочетание), которая является элементом
генерального словника (т.е. базовым словом или словосочетанием).
“Определяющее” — это
естественно-языковая единица (слово или словосочетание), которая входит в
генеральный словник (т.е. является базовым словом или словосочетанием) и
содержится хотя бы один раз в любой из дефиниций “определяемого”.
На рис. 67 приведена схема
построения тезауруса “определяющее-определяемое” по семантическому словарю.
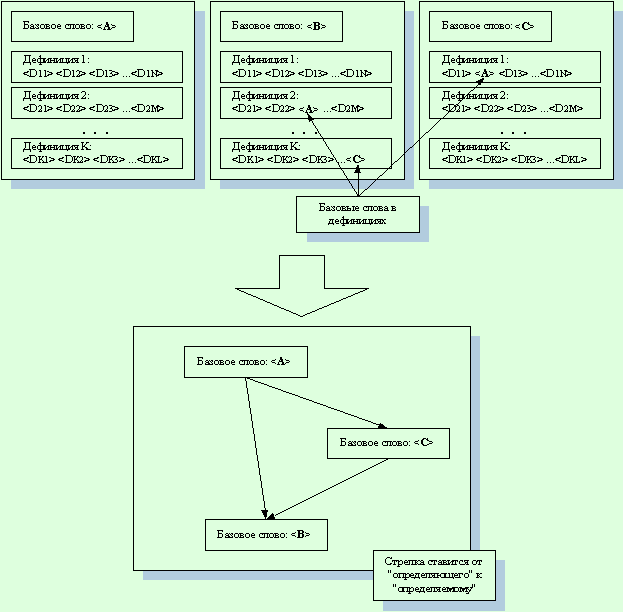
Рис. 67. Схема
получения тезауруса “определяющее-определяемое”
Рассмотрим следующий пример. Пусть
даны следующие варианты дефиниций слов:
ЧИСТЫЙ
1. Освобожденный от грязи, не имеющий
грязи; противоп. грязный.
2. Нравственно безупречный, честный,
правдивый, беспорочный.
3. С открытой, не занятой
поверхностью.
4. ...
ВОДА
1. Прозрачная бесцветная жидкость,
представляющая собой в чистом виде химическое соединение
водорода и кислорода.
2. Водная поверхность — река, озеро,
море и т.п., а также ее уровень.
3. Потоки, струи, волны.
4. Минеральные источники, курорт с
такими источниками. лечиться на водах.
СИДЕТЬ
1. Находиться в положении, при
котором туловище опирается на что-нибудь нижней своей частью.
2. Находиться в каком-нибудь месте,
состоянии.
3. Иметь какую-нибудь осадку,
углубляться в воду.
Тогда имеют место следующие
отношения “определяющие-определяемое”:
ЧИСТЫЙ ® ВОДА ® СИДЕТЬ (см.
выделенные слова).
Для перехода в режим щелкните на
закладку “Дерево”. Главное окно системы в этом случае примет вид (рис. 68):
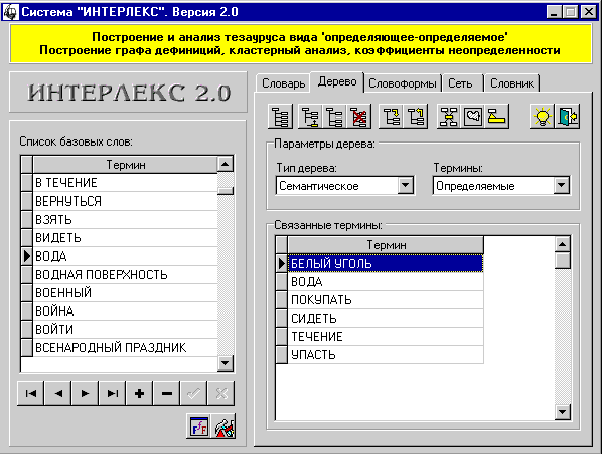
Рис. 68. Вид окна
системы в режиме “Дерево”
В данном режиме доступны следующие
функции:
|
|
Построить понятийное дерево (тезаурус). |
|
|
Добавить в ветвь элемент (слово). |
|
|
Удалить элемент (слово) из ветви. |
|
|
Удалить всю ветвь. |
|
|
Сделать выбранный термин в ветви текущим. |
|
|
Перейти к предыдущему термину. |
|
|
Построение графа дефиниций. |
|
|
Анализ тезауруса. |
|
|
Расчет коэффициентов неопределенности. |
В списке на панели режимов
отображаются связанные с текущим базовым словом слова и словосочетания. Этот
список меняется в зависимости от значений двух фильтров, расположенных на той
же панели режимов:
– тип дерева;
– термины.
Тип дерева имеет два значения:
семантическое и ассоциативное. В первом случае “определяемые” слова берутся из
семантического поля (дефиниций); во втором — из экземплярно-иллюстративного
(эксцерпций).
Управляющий элемент “термины”
позволяет выбрать направление “развертывания дерева”: “определяемые” слова
относительно текущего базового или “определяющие” слова относительно текущего
базового.
Оба этих фильтра служат только для
ограничения выводимых в списке значений.
Построение понятийного дерева
(тезауруса) ![]()
Чтобы построить понятийное дерево
(тезаурус), необходимо иметь сформированный список базовых слов (генеральный
словник) и их дефиниций и/или эксцерпции (см. “Режим “Словарь”).
Если семантический словарь готов, то
нажмите на кнопку “Построить понятийное дерево”. На экране будет отображено
(рис. 69):
Рис. 69. Построение
понятийного дерева
Укажите, по каким полям
семантического словаря нужно построить тезаурус. Если отмечено “По толкованиям
базовых терминов”, то “определяемые” слова будут браться из семантического поля
(дефиниций), если “По эксцерпциям базовых слов”, то из
экземплярно-иллюстративного поля.
Нажмите “OK” и дождитесь окончания
операции.
Пример 14
Исходные данные:
Текстовый файл, содержащий 150
словарных статей словаря Ожегова (файл OZHEGANS.TXT поставляется с системой).
Задача:
Построить понятийное дерево (тезаурус
“определяющее-определяемое”) на основе дефиниций.
Решение:
1. Импортируйте словарные статьи из
файла OZHEGANS.TXT в систему (см. раздел “Импорт словарных статей”).
2. Перейдите в режим “Дерево” и
нажмите кнопку “Построить понятийное дерево”.
3. Укажите только “ По толкованиям
базовых терминов” (рис. 69).
4. Нажмите “OK”.
5. Дождитесь окончания операции.
6. Результат будет отображен в списке
“связанные термины” на панели режимов. Необходимо отметить, что не все слова из
генерального словника будут иметь “определяющие” и “определяемые” слова. Для
этих слов список “связанных терминов” будет пуст.
7. Сопоставьте полученный результат,
например, для слов “БОЛЬШОЙ”, “ВЗЯТЬ” и “ВИДЕТЬ”.
Добавить в ветвь элемент
(базовое слово) ![]()
Несмотря на то что система
“Интерлекс” имеет возможность автоматического построения понятийного дерева,
иногда бывает необходимым подкорректировать результат “вручную”.
В системе “Интерлекс” предусмотрена
возможность добавления новых слов (из списка базовых) в ветвь.
Чтобы воспользоваться этой функцией,
необходимо выбрать текущее базовое слово (в списке базовых слов) и нажать на
кнопку “Добавить термин в ветвь”. На экране появится окно (рис. 70):
Рис. 70. Добавление
нового слова в ветвь для термина “ВОЕННЫЙ”
В окне “Добавить слово в ветвь”
необходимо выполнить следующие действия:
– Выбрать добавляемое слово
(словосочетание) из списка базовых слов. Для удобства поиска можно воспользоваться
фильтром. Символ “%” означает любую последовательность символов. Символ “_”
означает любой одиночный символ. Комбинация символов алфавита и этих знаков
дает возможность легко ограничивать список выводимых слов. Например, шаблон
“%ЫЙ” обеспечит отображение всех слов, оканчивающихся на “ЫЙ”, а шаблон “А__” —
список всех трехбуквенных слов, начинающихся с буквы “А”.
– Указать тип слова (т.е. тип
отношения). Необходимо указать, является ли добавляемое слово “определяющим”
или “определяемым” по отношению к текущему.
– Указать тип дерева. Система
“Интерлекс” позволяет работать с деревьями, построенными как по дефинициям
(семантические деревья), так и по экземплярно-иллюстративным полям
(ассоциативные деревья).
– Сила связи. В настоящей версии
системы этот параметр не используется. Допускается произвольное значение.
После выполнения указанных установок
нажмите “OK” и выбранное слово будет добавлено в выбранную ветвь. В зависимости
от установок фильтров “Тип дерева” и “Термины” результат может быть уведен
сразу, либо только после переустановки фильтров.
Удалить элемент (слово) из
ветви. ![]()
Чтобы удалить некоторое слово из
ветви, необходимо выбрать его и нажать кнопку “Удалить термин из ветви”. С
помощью этой функции может быть удалено слово только из отображаемой ветви.
Перед удалением пользователь должен
подтвердить выполнение операции (рис. 71):
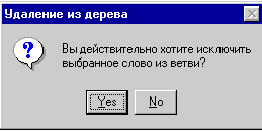
Рис. 71. Удаление
слова из ветви
Удалить всю ветвь ![]()
Если требуется удалить всю ветвь,
необходимо отобразить ее (с помощью фильтров “Тип дерева” и “Термины”, а затем
нажать кнопку “Удалить ветвь”.
Пользователь должен подтвердить
выполнение операции (рис. 72):
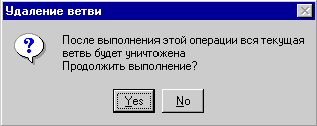
Рис. 72. Удаление
ветви
Навигация по дереву ![]()
![]()
Для удобства навигации по
семантическому и ассоциативному дереву в системе “Интерлекс” предусмотрены две
функции:
– ![]() сделать выбранный термин (слово в ветви)
текущим;
сделать выбранный термин (слово в ветви)
текущим;
– ![]() вернуться к слову, от которого был совершен
переход предыдущей функцией.
вернуться к слову, от которого был совершен
переход предыдущей функцией.
Эти две функции работают по принципу
FIFO. После применения первой функции слово, которое было текущим в списке
“связанных слов”, становится текущим в списке базовых слов, а предыдущее слово
из генерального словника запоминается. При следующем применении первой функции
система будет уже помнить два слова и т.д. Вторая функция выполняет обратный
переход (рис. 73).
Рис. 73. Навигация
по дереву
Граф дефиниций ![]()
Важным функциональным свойством
системы “Интерлекс” является возможность визуального представления
семантических структур. Так, система может графически представить семантическое
или ассоциативное деревья.
Для графического представления
данных о семантическом или ассоциативном дереве нажмите кнопку “Граф
дефиниций”. На экране появится окно (рис. 74):
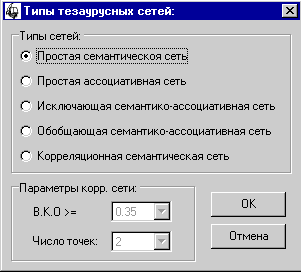
Рис. 74. Способы
визуализации
Система “Интерлекс” имеет возможность
отображать в графическом виде разные виды деревьев и сетей, которые могут быть
построены с помощью ее средств. Всего в системе различается 5 сетей:
– Простая семантическая сеть.
Фактически это граф отношений “определяющее-определяемое” по дефинициям
элементов генерального словника. Обычно в научной литературе этот термин имеет
другое толкование.
– Простая ассоциативная сеть. Граф
отношений “определяющее-определяющее” по экземплярно-иллюстративным полям.
Обычно в научной литературе этот термин имеет другое толкование.
– Исключающая
семантико-ассоциативная сеть. Наложение простой семантической и ассоциативной
сетей друг на друга с использованием логической операции “И” (рис. 75):
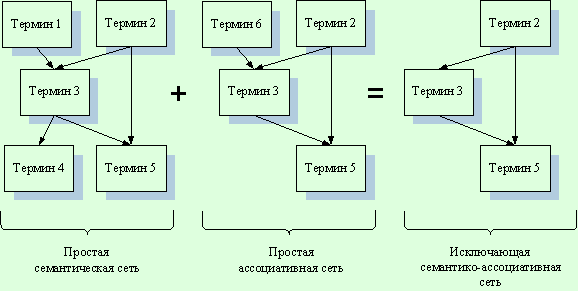
Рис. 75. Способ
формирования исключающей семантико-ассоциативной сети
– Обобщающая семантико-ассоциативная
сеть. Наложение простой семантической и ассоциативной сетей друг на друга с
использованием логической операции “ИЛИ” (рис. 76).
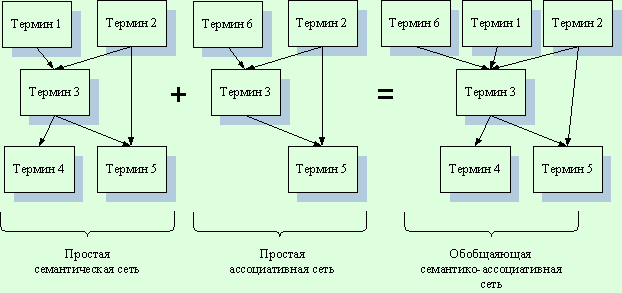
Рис. 76. Способ
формирования обобщающей семантико-ассоциативной сети
– Корреляционная сеть. Вид семантической
сети, построенной на основе статистических характеристик естественно-языковых
единиц (подробнее см. “Режим “Сеть””).
После выбора необходимого типа сети
нажмите “OK”. На экране появится окно (рис. 77):
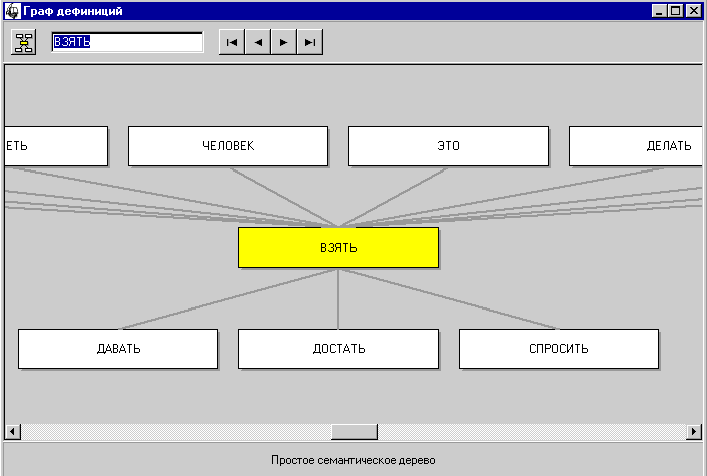
Рис. 77. Визуальное
представление семантической сети
В центре в желтом прямоугольнике
отображается текущее базовое слово. В верхнем ряду отображаются в зависимости
от типа тезауруса “определяющие” слова по отношению к базовому, а в нижнем ряду
— “определяемые”. Использование функции визуализации упрощает навигацию по
семантическому дереву (или сети). Достаточно щелкнуть мышью на белом
прямоугольнике и это слово сделается базовым.
Кроме того, всегда есть возможность
изменить тип отображаемой сети (кнопка “Тип тезаурусной сети” в левом верхнем
углу окна).
Анализ тезауруса ![]()
Система “Интерлекс” имеет средства
для анализа сформированных семантического или ассоциативного деревьев. В
частности, интерес может представлять следующая информация:
– Является ли полученное
семантическое (ассоциативное) дерево цельным (т.е. охватывающим все элементы
генерального словника), или оно состоит из отдельных, не связанных поддеревьев,
и сколько их?
– Является ли полученная структура
действительно древовидной либо в ней присутствуют циклы? Какова средняя длина
цикла?
На эти вопросы можно получить ответ,
воспользовавшись средствами анализа тезаурусов системы “Интерлекс”. Система
позволяет для указанного базового слова строить ареал, т.е. выделять всю
совокупность слов, которые имеют связи с базовым. На рис. 78 схематично
показана процедура построения ареала:
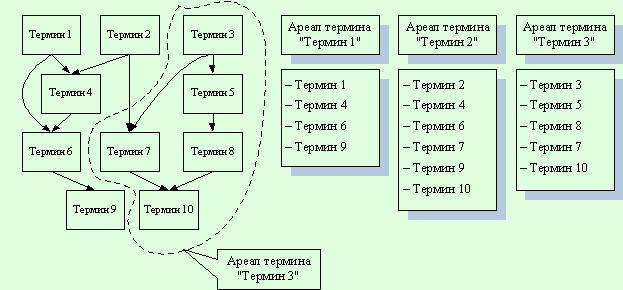
Рис. 78. Схема
получения ареалов
Для построения ареала нажмите кнопку
“Анализ тезауруса”. На экране появится окно (рис. 79).
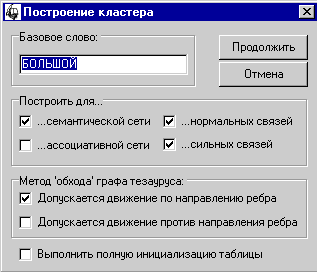
Рис. 79. Построение
ареала
В этом окне необходимо задать
параметры построения ареала:
– вид сети (семантическая или ассоциативная)
– способ ориентации ребер графа
дефиниций (т.е. графа отношений “определяющее-определяемое”)
– способ сохранения новых данных
(объединять с уже существующими или удалить все перед началом операции)
Установку этих параметров можно
выполнить с помощью независимых переключателей.
· Построить для семантической
сети. Строится ареал для выбранного базового слова по семантической
сети (дереву дефиниций).
· Построить для ассоциативной
сети. Строится ареал для выбранного базового слова по ассоциативной
сети (дереву по экземплярно-иллюстративным полям).
Если выбраны оба параметра, то
строится ареал по обобщающей семантико-ассоциативной сети.
· Метод “обхода” графа
тезауруса. По направлению ребра. Ареал строится на основе графа, в
котором ребра направлены от “определяющих” слов к “определяемым” (например, см.
рис. 77).
· Метод “обхода” графа
тезауруса. Против направления ребра. Ареал строится на основе графа, в
котором ребра направлены от “определяемых” слов к “определяющим”. Ориентация
ребер графа меняется на противоположную.
Если выбраны оба способа, то
считается, что граф не является ориентированным, и ареал строится без учета
направления ребер. Учитывается только наличие какой-либо связи.
· Выполнить полную
инициализацию таблицу. Если данный переключатель установлен, то перед
началом операции все данные из таблицы, содержащей информацию об ареалах, будут
удалены. В противном случае, новая информация будет добавлена к уже имеющейся.
Переключатели “Построить для
нормальных связей” и “Построить для сильных связей” в настоящей версии системы
не используются и должны быть всегда включены.
После выполнения всех установок
нажмите кнопку “Продолжить”, дождитесь окончания операции, на экране появится
окно (рис. 80):
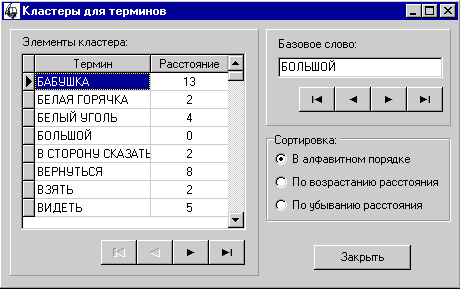
Рис. 80. Ареал
термина
В этом окне отображается весь ареал
выбранного базового слова в соответствии с установленными параметрами.
В таблице “элементы кластера”
отображаются все естественно-языковые единицы генерального словника, которые
вошли в ареал. Пользователь может выбрать способ сортировки этих слов с помощью
переключателей:
– в алфавитном порядке;
– по возрастанию расстояния;
– по убыванию расстояния.
Под расстоянием понимается
минимальное число шагов по графу дефиниций, которое необходимо совершить, чтобы
добраться от базового слова к слову из ареала этого базового слова. Считается,
что расстояние базового слова до самого себя равно 0, до всех слов, которые
являются непосредственно “определяющими” или “определяемыми” = 1, и т.д.
Используя панель навигации, можно
просмотреть ареалы для других базовых слов, которые были построены ранее (это
имеет смысл, если при построении ареала не был установлен переключатель
“выполнить полную инициализацию таблицы”, в противном случае для всех других
базовых слов ареалы будут пусты).
Таблица, в которой сохраняются
данные об ареалах базовых терминов, называется “DICTCLST.DB”, расположенной в
каталоге “DATA” относительно установочного каталога системы “Интерлекс”.
Формат таблицы “dictclst.db”
Таблица “dictclst.db” имеет
следующую структуру:
– BaseKey.
Идентификатор базового слова, для которого строится ареал. Ссылка на таблицу
“dictkey.db”.
– RecordID. Порядковый
номер записи внутри ареала. Уникален внутри ареала.
– KeywordID.
Идентификатор слова из генерального словника, которое является элементом ареала
базового слова (BaseKey). Ссылка на таблицу “dictkey.db”.
– MinLen. Минимальное
расстояние от базового слова до элемента ареала.
Для получения копии этой таблицы в
виде, удобном для чтения, выполните c помощью утилиты DBD32 следующий
SQL-запроc:
select A.Keyword, C.Keyword, B.MinLen
from ‘dictclst.db’ B, ‘dictkey.db’ A,
‘dictkey.db’ C
where A.RecordID=B.BaseKey AND
C.RecordID=B.KeywordID
order by B.MinLen;
Результат выполнения этого запроса
представлен на рис. 81:
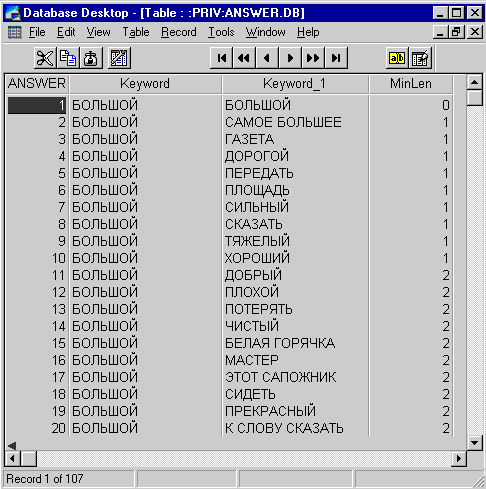
Рис. 81. Таблица
ареалов для базовых слов
Расчет “коэффициентов
определенности” ![]()
Еще одним способом анализа тезауруса
отношений “определяющее-определяемое” является вычисление “коэффициентов определенности”.
Сначала рассмотрим фрагмент
семантического дерева (рис. 82):
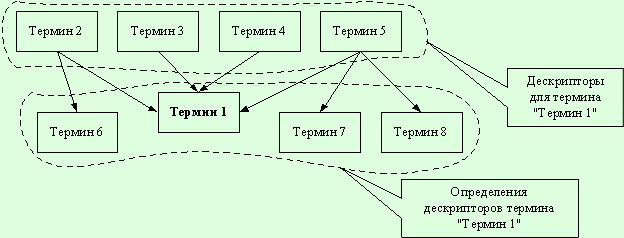
Рис. 82. Фрагмент
семантического дерева
На приведенном выше фрагменте
семантического дерева выведены два термина:
– дескрипторы;
– определения.
Дескрипторами в данном контексте
будем называть совокупность всех “определяющих” слова для некоторого базового.
Определениями в данном контексте
будем называть совокупность всех слов, для которых дескрипторы некоторого
базового слова являются “определяющими”.
Система “Интерлекс” позволяет
определять число дескрипторов и число определений для всех естественно-языковых
единиц генерального словника на основе уже сформированного тезауруса
“определяющее-определяемое”.
“Коэффициентом определенности” будем
называть числовую величину, равную отношению числа определений к числу
дескрипторов. Физический смысл этой величины заключается в следующем:
Примем гипотезу о том, что
семантическое значение некоторого термина (базового слова) тем точнее
определено, чем меньше существует других терминов, которые имеют те же
дескрипторы. Другими словами, термин “абсолютно определен”, если его
дескрипторы не являются дескрипторами ни для какого другого термина.
Значение “коэффициента
определенности” тем больше, чем “менее точно” определен термин, т.е. число
определений больше числа дескрипторов. Минимальное значение “коэффициента
определенности” равно 1. Это значит, что для каждого дескриптора базового слова
существует одно и только одно “определяемое” — само базовое слово.
Чтобы вычислить значения
“коэффициента определенности” для всех базовых слов, нажмите кнопку “Расчет
коэффициентов определенности”. На экране появится окно (рис. 83):
Рис. 83. Фрагмент
семантического дерева
Система “Интерлекс” имеет
возможность вычислять “коэффициент определенности” как по семантической сети (тезаурусу
“определяющее-определяемое”), так и по ассоциативной (сети по
экземплярно-иллюстративным полям). В окне (рис. 83) необходимо отметить сеть,
по которой будет рассчитан коэффициент. Если отметить обе позиции, то
коэффициент будет рассчитан по обобщающей семантико-ассоциативной сети.
Нажмите “Продолжить” и дождитесь
окончания операции. На экране появится окно (рис. 84):
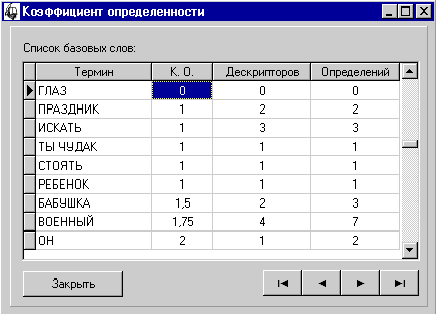
Рис. 84. “Коэффициент
определенности”
Информация о “коэффициентах
определенности” сохраняется в таблице с именем “DICTDEF.DB”, расположенной в
каталоге DATA.
Формат таблицы “dictdef.db”
Таблица “dictdef.db” имеет следующий
формат:
– KeywordID. Идентификатор базового
слова из генерального словника (ссылка на таблицу “dictkey.db”).
– Masters. Число дескрипторов.
– ChildSum. Число определений.
– AveFactor. Значение “коэффициента
определенности”.
Для представления таблицы в виде,
удобном для чтения с помощью утилиты DBD32, выполните следующий SQL-запрос:
select Keyword, Masters, ChildSum,
AveFactor
from ‘dictkey.db’, ‘dictdef.db’
where KeywordId=RecordID order by
Keyword
Пример выполнения этого запроса
приведен на рис. 85:
Рис. 85. Пример
выполнения запроса по таблице “коэффициентов определенности”
Система “Интерлекс” включает в себя
инструментарий для статистического анализа естественно-языкового описания
предметной области. В частности, пользователь имеет возможность воспользоваться
одним из вариантов дистрибутивно-статистического метода для установления
семантических отношений между естественно-языковыми единицами в тексте.
Под дистрибутивно-статистическими
методами понимается совокупность формальных преобразований статистической
(частотной) информации о естественно-языковых единицах, на основании
результатов которых можно установить факт наличия связи между ЕЯ единицами.
Прямого перехода от чисто количественной характеристики к интерпретации
отношений на семантическом уровне конечно нет, однако для ряда предметных
областей наличие формальной связи характеризуется, как правило, наличием не
только синтаксического, но и семантического отношения между ЕЯ единицами.
В системе “Интерлекс” использован
метод, основанный на расчете корреляционного отношения и коэффициента
корреляции. Другими словами, формальной мерой “связанности” (не обязательно
семантической) ЕЯ единиц являются статистические параметры корреляционного
отношения и коэффициента корреляции.
Использование корреляционного (ВКО)
отношения дает следующие преимущества, вытекающие из его свойств:
– 0 ВКО 1
– ВКО не зависит от вида связи между
двумя исследуемыми статистическими характеристиками ЕЯ единиц.
– Не ассоциативен, т.е. ВКО (A, B)
ВКО (B, A) в общем случае.
В дополнение к этой характеристике
система “Интерлекс” рассчитывает коэффициент корреляции (ВКК),
характеризующийся следующим:
– -1 ВКК 1
– Позволяет фиксировать только
линейные отношения между статистическими характеристиками ЕЯ единиц.
– Обладает свойством
ассоциативности, т.е. ВКК(A, B) = =BКК (B, A).
Если принять гипотезу о том, что
указанные формальные характеристики так или иначе характеризуют семантические
отношения между естественно-языковыми единицами, то можно говорить о
корреляционной семантической сети (или просто семантической сети). Эта
структура (в отличие от рассмотренной в предыдущем разделе) не является
древовидной. Основные отличия семантической сети от cемантического дерева
(тезауруса “определяющее-определяющее”) следующие:
– семантическая сеть троится на
основе исходного текста по частотным характеристикам ЕЯ единиц, а не на их
дефиниций или эксцерпций.
– Связь между любыми двумя ЕЯ
единицами в семантической сети характеризуется двумя формальными значениями
(ВКО и ВКК)
– Связь может интерпретироваться как
синтаксическое, так и как семантическое отношение (не только как
“определяющее-определяемое”)
– Фактическое лингвистическое или
экстралингвистическое отношение не устанавливается, а фиксируется только
возможность наличия такой связи.
На рис. 86 приведена схема
формирования семантической сети:
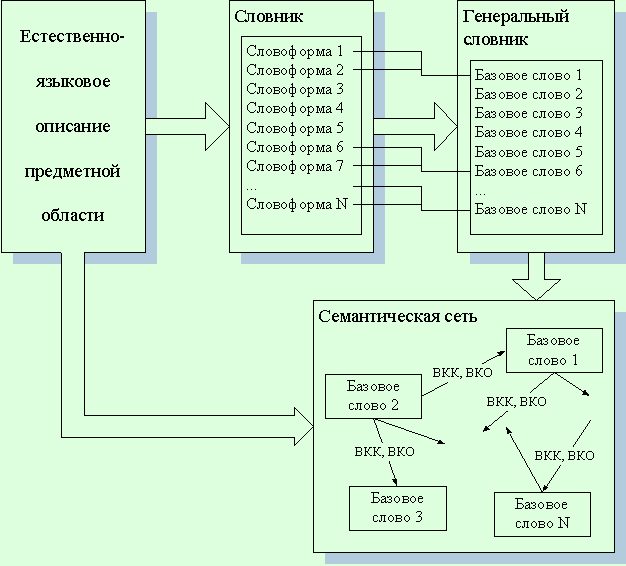
Рис. 86. Схема
формирования семантической сети
Для перехода в режим “Сеть” щелкните
на одноименной закладке в главном окне. При этом главное окно примет вид (рис.
87):
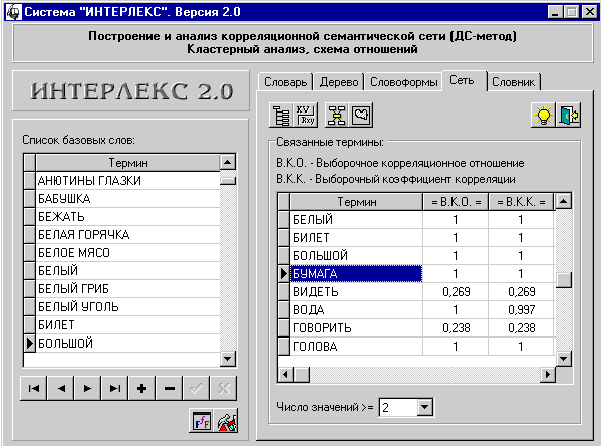
Рис. 87. Режим
“Сеть”
В данном режиме доступны следующие
функции:
Построить корреляционную сеть.
Вычислить корреляционное отношение.
Графическое представление
семантической сети.
Построение семантических ареалов.
Построение корреляционной
семантической сети
Чтобы построить корреляционную
семантическую сеть по исходному тексту, необходимо:
– сформировать по исходному тексту
генеральный словник (см. разделы “Режим “Словоформы””, “Режим “Словарь”);
– перейти в режим “Сеть” и нажать
кнопку “Построить корреляционную сеть”.
На экране появится окно (рис. 88):
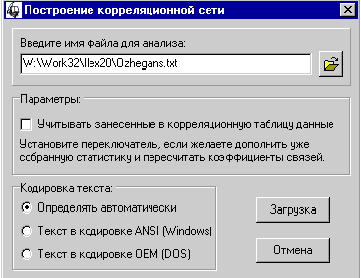
Рис. 88. Построение
корреляционной сети
Укажите имя исходного текста, по
которому будет строиться корреляционная семантическая сеть.
Если данная операция уже ранее
выполнялась и требуется объединить данные, уже хранящиеся в базе данных с
новыми, то необходимо установить переключатель “Учитывать занесенные в
корреляционную таблицу данные”.
Необходимо также задать кодировку
исходного текста или позволить системе сделать это автоматически.
После выполненных установок нажмите
кнопку “Загрузка” и дождитесь окончания операции.
Если операция завершилась успешно,
то на экран будет выведено сообщение (рис. 89):

Рис. 89. Завершение
операции построения корреляционной сети
Это сообщение означает, что система
собрала всю необходимую статистику о частотах естественно-языковых единиц
исходного текста и готова к расчету основных характеристик корреляционной сети:
корреляционного отношения (ВКО) и коэффициента корреляции (ВКК). Нажмите “OK”,
и на экран будет выведено следующее сообщение (рис. 90):
Рис. 90. Пересчет
характеристик корреляционной сети
Если необходимо провести расчет
характеристик корреляционной сети немедленно, то следует ответить “Yes” (см.
“Расчет корреляционного отношения”, стр. 110). Если эту операции Вы планируете
выполнить позднее, то выберите ответ “No”.
Расчет корреляционного
отношения ![]()
Функция вычисления корреляционных
отношений и коэффициентов корреляции непосредственно связана с предыдущей и
должна выполняться после выполнения построения корреляционной семантической
сети.
Система “Интерлекс” вычисляет
искомые корреляционные отношения и коэффициенты корреляции по корреляционным
матрицам, т.е. статистике, собранной по естественно-языковым единицам исходного
текста.
Чтобы выполнить расчет (или
обновить) корреляционные отношения и коэффициенты корреляции, нажмите на кнопку
“Расчет корреляционных отношений” и дождитесь окончания операции.
Экран примет вид (рис. 91):
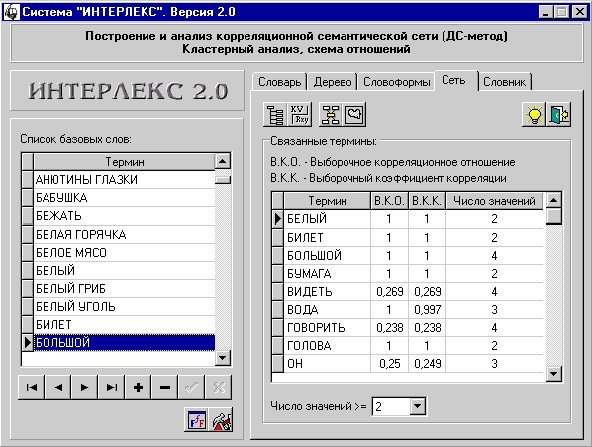
Рис. 91. Расчет ВКО
и ВКК
Система “Интерлекс” представляет
результат в следующем виде:
– в таблице на панели режимов
отображаются элементы генерального словника, непосредственно связанные с
текущим базовым словом. Другими словами, для базового слова и любого слова из
списка можно определить ненулевое ВКО;
– таблица непосредственно связанных
слов состоит из следующих столбцов: ВКО (корреляционное отношение), ВКК
(коэффициент корреляции) и “Число значений”.
– Параметр “Число значений”
позволяет оценить точность вычисления ВКО и ВКК. Он показывает число ненулевых
значений в корреляционной матрице, образовавшейся при сборе статистики для
текущего базового слова и соответствующего слова из списка связанных слов.
Естественно, что чем больше значение параметра “Число значений”, тем больше
вероятность, что полученные значения ВКО и ВКК не являются смещенными.
Для удобства просмотра результатов
система “Интерлекс” имеет фильтр по “Числу значений”. Изменяя этот фильтр,
можно отбрасывать связи, для которых число значений, т.е. объем собранной
статистики, слишком мало.
Графическое представление
семантической сети ![]()
Система “Интерлекс” имеет функцию
визуального представления семантической сети, а также навигации по ней.
Нажмите кнопку “Граф дефиниций” и на
экране появится окно (рис. 92):
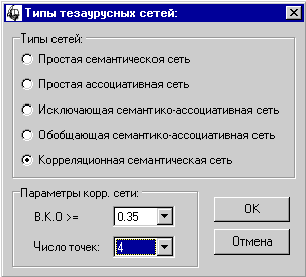
Рис. 92.
Визуализация корреляционной семантической сети
Для визуализации корреляционной
семантической сети необходимо установить в соответствующее положение и указать
минимальные параметры “Число точек” (т.е. число значений в корреляционной
матрице) и ВКО. Все связи, для которых хотя бы один из параметров окажется
меньше, будут проигнорированы.
Нажмите “OK”, и на экране появится
окно (рис. 93).
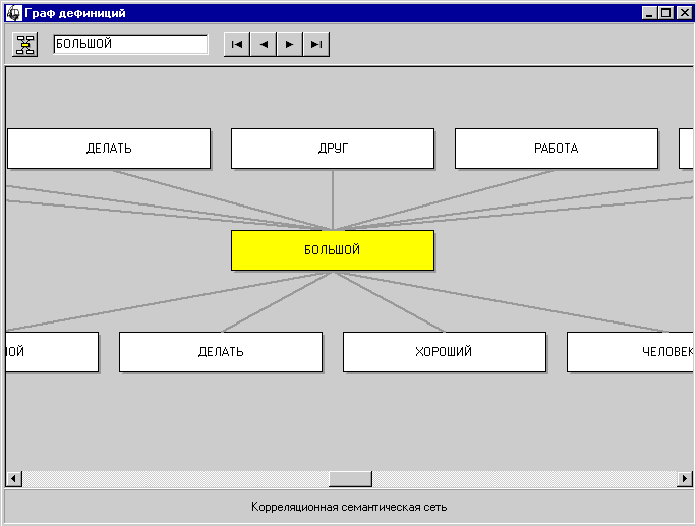
Рис. 93. Вид
корреляционной семантической сети
В центре, в желтом прямоугольнике,
отображается текущее базовое слово. В верхнем ряду отображаются слова, которые
связаны с базовым, а в нижнем ряду — слова, с которыми связано базовое слово
(свойство неассоциативности ВКО в общем случае). Использование функции
визуализации упрощает навигацию по семантической сети. Достаточно щелкнуть
мышью на белом прямоугольнике и это слово сделается базовым.
Необходимо отметить, что на связях
не отображаются значения ВКО, ВКК и “Числа значений”. Считается, что если связь
отображена, то значения ВКО и “Числа значений” не меньше заданных в окне
параметров (рис. 91).
Все данные о корреляционной
семантической сети хранятся в таблице “DICTCORR.DB” в каталоге DATA.
Формат таблицы “dictcorr.db”
Таблица “dictcorr.db” имеет
следующую структуру:
– MasterID — идентификатор слова, от
которого устанавливается связь (ссылка на таблицу “dictkey.db”);
– SlaveID — идентификатор слова к
которому устанавливается связь (ссылка на таблицу “dictkey.db”);
– Rxy — величина корреляционного
отношения;
– Kv — величина коэффициента
корреляции;
– ValCount — число значений в
корреляционной матрице.
Для представления таблицы в виде,
удобном для чтения, можно выполнить следующий SQL-запрос:
select A.Keyword, B.Keyword, Rxy, Kv,
ValCount
from ‘dictkey.db’ A, ‘dictkey.db’ B,
‘dictcorr.db’
where A.RecordID=MasterID AND
B.RecordID=SlaveID
order
by ValCount DESC,Rxy DESC
Для его выполнения можно
воспользоваться утилитой DBD32. На рис. 94 приведен результат выполнения этого
запроса:
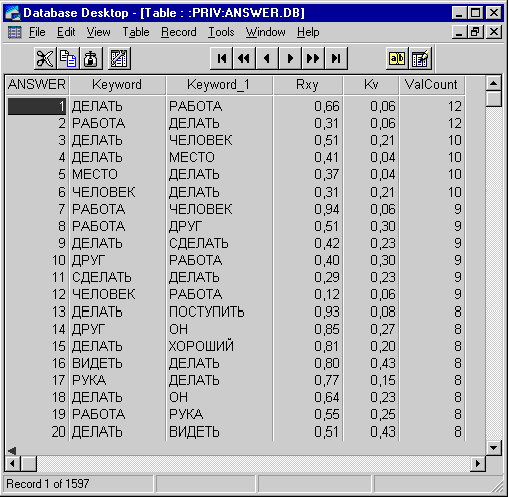
Рис. 94. Результат
выполнения SQL-запроса по таблице “dictcorr.db”
Пример 15
Исходные данные:
Текстовый файл, содержащий 150
словарных статей словаря Ожегова (файл OZHEGANS.TXT поставляется с системой).
Задача:
Построить корреляционную
семантическую сеть.
Решение:
8. Импортируйте словарные статьи из
файла OZHEGANS.TXT в систему (см. раздел “Импорт словарных статей”, стр. 74).
9. Перейдите в режим “Сеть” и нажмите
кнопку “Построение корреляционной семантической сети”.
10. Укажите файл “OZEGANS.TXT”.
Переключатели “Учитывать занесенные в корреляционную таблицу данные” и
“Кодировка текста” оставить установленными по умолчанию.
11. Нажмите “OK”.
12. Дождитесь окончания операции. На
вопрос “Вы хотите пересчитать коэффициенты?” следует ответить положительно.
13. Результат будет отображен в
списке слов на панели режимов. Возможно, не все слова из генерального словника
будут иметь связи. Это значит, что корреляционное отношение между этим словом и
любыми другими из этого же генерального словника равно 0 (исходя из их
частотных характеристик анализируемого текста).
14. Запустите утилиту DBD32 и
выполните в ней SQL-запрос (см. “Формат таблицы “dictcorr.db””).
15. Перенесите полученный результат в
MS Word или в MS Excel для оформления. Фрагмент семантической сети (в табличном
виде) представлен в табл. 17. Данные в таблице представлены по убыванию числа
значений (V) в соответствующих корреляционных матрицах.
16. Обратите внимание на термины,
частоты которых сильно коррелируют между собой (например, “ГОВОРИТЬ-ДЕЛАТЬ”,
“РУКА-ДЕЛАТЬ”, “НАЧАТЬ-ДЕЛАТЬ”, “РАБОТА-ТРУД” и т.п.).
Таблица 17
|
№ |
Термин 1 |
Термин 2 |
ВKО |
ВK |
V |
|
1 |
ДЕЛАТЬ |
РАБОТА |
0,663 |
0,058 |
12 |
|
2 |
РАБОТА |
ДЕЛАТЬ |
0,306 |
0,058 |
12 |
|
3 |
ДЕЛАТЬ |
ЧЕЛОВЕK |
0,511 |
0,21 |
10 |
|
4 |
ДЕЛАТЬ |
МЕСТО |
0,414 |
0,04 |
10 |
|
5 |
МЕСТО |
ДЕЛАТЬ |
0,371 |
0,04 |
10 |
|
6 |
ЧЕЛОВЕKК |
ДЕЛАТЬ |
0,31 |
0,21 |
10 |
|
7 |
РАБОТА |
ЧЕЛОВЕKК |
0,937 |
0,056 |
9 |
|
8 |
РАБОТА |
ДРУГ |
0,509 |
0,299 |
9 |
|
9 |
ДЕЛАТЬ |
СДЕЛАТЬ |
0,423 |
0,234 |
9 |
|
10 |
ДРУГ |
РАБОТА |
0,404 |
0,299 |
9 |
|
11 |
СДЕЛАТЬ |
ДЕЛАТЬ |
0,29 |
0,234 |
9 |
|
12 |
ЧЕЛОВЕK |
РАБОТА |
0,12 |
0,056 |
9 |
|
13 |
ДЕЛАТЬ |
ПОСТУПИТЬ |
0,93 |
0,078 |
8 |
|
14 |
ДРУГ |
ОН |
0,849 |
0,272 |
8 |
|
15 |
ДЕЛАТЬ |
ХОРОШИЙ |
0,809 |
0,197 |
8 |
|
16 |
ВИДЕТЬ |
ДЕЛАТЬ |
0,795 |
0,433 |
8 |
|
17 |
РУKА |
ДЕЛАТЬ |
0,77 |
0,145 |
8 |
|
18 |
ДЕЛАТЬ |
ОН |
0,636 |
0,227 |
8 |
|
19 |
РАБОТА |
РУKА |
0,551 |
0,249 |
8 |
|
20 |
ДЕЛАТЬ |
ВИДЕТЬ |
0,505 |
0,433 |
8 |
|
21 |
ЧЕЛОВЕK |
ДРУГ |
0,426 |
0,277 |
8 |
|
22 |
РУKА |
РАБОТА |
0,40 |
0,249 |
8 |
|
23 |
ИДТИ |
ДЕЛАТЬ |
0,381 |
0,201 |
8 |
|
24 |
ДЕЛАТЬ |
ИДТИ |
0,353 |
0,201 |
8 |
|
25 |
ОН |
ДРУГ |
0,298 |
0,272 |
8 |
|
26 |
ДРУГ |
ЧЕЛОВЕKК |
0,297 |
0,277 |
8 |
|
27 |
ОН |
ДЕЛАТЬ |
0,271 |
0,227 |
8 |
|
28 |
ДЕЛАТЬ |
РУKА |
0,262 |
0,145 |
8 |
|
29 |
ХОРОШИЙ |
ДЕЛАТЬ |
0,223 |
0,197 |
8 |
|
30 |
ПОСТУПИТЬ |
ДЕЛАТЬ |
0,208 |
0,078 |
8 |
|
31 |
РУKА |
РУKА |
1,00 |
1,00 |
7 |
|
32 |
ГОВОРИТЬ |
ГОВОРИТЬ |
1,00 |
1,00 |
7 |
|
33 |
ДЕЛАТЬ |
ДАТЬ |
0,997 |
0,688 |
7 |
|
34 |
ГОВОРИТЬ |
ДЕЛАТЬ |
0,931 |
0,187 |
7 |
|
35 |
ДАТЬ |
ДЕЛАТЬ |
0,74 |
0,688 |
7 |
|
36 |
НОВЫЙ |
ДЕЛАТЬ |
0,729 |
0,407 |
7 |
|
37 |
ДЕЛАТЬ |
НОВЫЙ |
0,58 |
0,407 |
7 |
|
38 |
ДРУГ |
ИДТИ |
0,563 |
0,426 |
7 |
|
39 |
ИДТИ |
ДРУГ |
0,563 |
0,426 |
7 |
|
40 |
ОН |
ЧЕЛОВЕK |
0,516 |
0,286 |
7 |
|
41 |
ДЕЛАТЬ |
ГОВОРИТЬ |
0,484 |
0,187 |
7 |
|
42 |
ДЕЛАТЬ |
ГОРОД |
0,456 |
0,16 |
7 |
|
43 |
ПРОСТОЙ |
ДЕЛАТЬ |
0,432 |
0,304 |
7 |
|
44 |
ВОДА |
ДЕЛАТЬ |
0,418 |
0,055 |
7 |
|
45 |
ДЕЛАТЬ |
ЖИЗНЬ |
0,326 |
0,043 |
7 |
|
46 |
ДЕЛАТЬ |
ВОДА |
0,321 |
0,055 |
7 |
|
47 |
ЖИЗНЬ |
ДЕЛАТЬ |
0,319 |
0,043 |
7 |
|
48 |
ДЕЛАТЬ |
ПРОСТОЙ |
0,314 |
0,304 |
7 |
|
49 |
ЧЕЛОВЕK |
ОН |
0,313 |
0,286 |
7 |
|
50 |
ГОРОД |
ДЕЛАТЬ |
0,16 |
0,16 |
7 |
|
51 |
ДРУГ |
ДРУГ |
1,00 |
1,00 |
6 |
|
52 |
РАБОТА |
РАБОТА |
1,00 |
1,00 |
6 |
|
53 |
ДЕЛАТЬ |
ДЕЛАТЬ |
1,00 |
1,00 |
6 |
|
54 |
РАБОТА |
ТРУД |
0,997 |
0,129 |
6 |
|
55 |
ТРУД |
РАБОТА |
0,989 |
0,129 |
6 |
|
56 |
ТРУД |
РУKА |
0,949 |
0,465 |
6 |
|
57 |
НАЧАТЬ |
ДЕЛАТЬ |
0,88 |
0,698 |
6 |
|
58 |
РУKА |
ТРУД |
0,801 |
0,465 |
6 |
|
59 |
РАБОТА |
ПОСТУПИТЬ |
0,80 |
0,274 |
6 |
|
60 |
ЧЕЛОВЕKК |
ХОРОШИЙ |
0,799 |
0,138 |
6 |
|
61 |
ДЕЛАТЬ |
НАЧАТЬ |
0,791 |
0,698 |
6 |
|
62 |
РАБОТА |
ХОРОШИЙ |
0,731 |
0,493 |
6 |
|
63 |
ИДТИ |
РАБОТА |
0,692 |
0,121 |
6 |
|
64 |
ПРОСТОЙ |
ЖИЗНЬ |
0,674 |
0,125 |
6 |
|
65 |
ДЕЛАТЬ |
ТРУД |
0,647 |
0,573 |
6 |
|
66 |
РУKА |
ПРОСТОЙ |
0,632 |
0,383 |
6 |
|
67 |
ХОРОШИЙ |
РАБОТА |
0,626 |
0,493 |
6 |
|
68 |
ДЕЛАТЬ |
ЧАС |
0,62 |
0,308 |
6 |
|
69 |
ТРУД |
ДЕЛАТЬ |
0,591 |
0,573 |
6 |
|
70 |
СТОРОНА |
ДЕЛАТЬ |
0,586 |
0,172 |
6 |
|
71 |
ЧЕЛОВЕKК |
ВОДА |
0,572 |
0,386 |
6 |
|
72 |
ДРУГ |
ПРОСТОЙ |
0,569 |
0,305 |
6 |
|
73 |
ДЕЛАТЬ |
ЭТО |
0,535 |
0,417 |
6 |
|
74 |
ДЕЛАТЬ |
ДРУГ |
0,514 |
0,079 |
6 |
|
75 |
ДЕЛАТЬ |
СТОРОНА |
0,485 |
0,172 |
6 |
|
76 |
ВОДА |
ЧЕЛОВЕK |
0,471 |
0,386 |
6 |
|
77 |
МЕСТО |
ЧЕЛОВЕKК |
0,423 |
0,147 |
6 |
|
78 |
ЭТО |
ДЕЛАТЬ |
0,417 |
0,417 |
6 |
|
79 |
ДЕЛАТЬ |
ПЕРЕДАТЬ |
0,404 |
0,228 |
6 |
|
80 |
ЧАС |
ДЕЛАТЬ |
0,39 |
0,308 |
6 |
|
81 |
ПРОСТОЙ |
РУKА |
0,383 |
0,383 |
6 |
|
82 |
ПРОСТОЙ |
ДРУГ |
0,379 |
0,305 |
6 |
|
83 |
ПЕРЕДАТЬ |
ДЕЛАТЬ |
0,367 |
0,228 |
6 |
|
84 |
ПОСТУПИТЬ |
РАБОТА |
0,353 |
0,274 |
6 |
|
85 |
ЖИЗНЬ |
ПРОСТОЙ |
0,31 |
0,125 |
6 |
|
86 |
РАБОТА |
СОВЕТСKИЙ |
0,304 |
0,139 |
6 |
|
87 |
ЧЕЛОВЕK |
СОВЕТСKИЙ |
0,279 |
0,194 |
6 |
|
88 |
НОВЫЙ |
ИДТИ |
0,278 |
0,201 |
6 |
|
89 |
СОВЕТСKИЙ |
ЧЕЛОВЕKК |
0,262 |
0,194 |
6 |
|
90 |
ХОРОШИЙ |
ЧЕЛОВЕKК |
0,239 |
0,138 |
6 |
|
91 |
ИДТИ |
НОВЫЙ |
0,227 |
0,201 |
6 |
|
92 |
СОВЕТСKИЙ |
РАБОТА |
0,187 |
0,139 |
6 |
|
93 |
ЧЕЛОВЕKК |
МЕСТО |
0,184 |
0,147 |
6 |
|
94 |
РАБОТА |
ИДТИ |
0,121 |
0,121 |
6 |
|
95 |
ДРУГ |
ДЕЛАТЬ |
0,087 |
0,079 |
6 |
|
96 |
ГОВОРИТЬ |
ЧЕЛОВЕKК |
1,00 |
0,772 |
5 |
|
97 |
ГОВОРИТЬ |
ИДТИ |
1,00 |
0,86 |
5 |
|
98 |
ХОРОШИЙ |
ХОРОШИЙ |
1,00 |
0,999 |
5 |
|
99 |
РУKА |
СДЕЛАТЬ |
1,00 |
0,766 |
5 |
|
100 |
ЖИЗНЬ |
ЖИЗНЬ |
1,00 |
1,00 |
5 |
|
101 |
ВИДЕТЬ |
ВИДЕТЬ |
1,00 |
1,00 |
5 |
|
102 |
ДАТЬ |
ДАТЬ |
1,00 |
1,00 |
5 |
|
103 |
РАБОТА |
РАБОЧИЙ |
1,00 |
0,316 |
5 |
|
104 |
ИДТИ |
ИДТИ |
1,00 |
1,00 |
5 |
|
105 |
ЧАС |
ХОРОШИЙ |
0,998 |
0,203 |
5 |
|
106 |
РАБОЧИЙ |
РАБОТА |
0,996 |
0,316 |
5 |
|
107 |
СЕСТЬ |
ДЕЛАТЬ |
0,995 |
0,23 |
5 |
|
108 |
ПЕРЕДАТЬ |
ДАТЬ |
0,986 |
0,65 |
5 |
|
109 |
ЧЕЛОВЕKК |
ПРОСТОЙ |
0,972 |
0,202 |
5 |
|
110 |
РАБОТА |
БОЛЬШОЙ |
0,95 |
0,217 |
5 |
|
111 |
ЧЕЛОВЕK |
РУKА |
0,93 |
0,875 |
5 |
|
112 |
ЖИЗНЬ |
ЧЕЛОВЕKК |
0,899 |
0,33 |
5 |
|
113 |
НОВЫЙ |
ЧЕЛОВЕKК |
0,895 |
0,323 |
5 |
|
114 |
РУKА |
ЧЕЛОВЕKК |
0,893 |
0,875 |
5 |
|
115 |
ИДТИ |
ГОВОРИТЬ |
0,86 |
0,86 |
5 |
|
116 |
ТОЧKА |
ДЕЛАТЬ |
0,84 |
0,546 |
5 |
|
117 |
ВИДЕТЬ |
ПРОСТОЙ |
0,802 |
0,136 |
5 |
|
118 |
ДРУГ |
НОВЫЙ |
0,801 |
0,071 |
5 |
|
119 |
ДРУГ |
ХОРОШИЙ |
0,79 |
0,223 |
5 |
|
120 |
ГОЛОВА |
ДЕЛАТЬ |
0,784 |
0,165 |
5 |
|
121 |
ЧЕЛОВЕKК |
ГОВОРИТЬ |
0,772 |
0,772 |
5 |
|
122 |
СДЕЛАТЬ |
РУKА |
0,766 |
0,766 |
5 |
|
123 |
ДАТЬ |
ПЕРЕДАТЬ |
0,751 |
0,65 |
5 |
|
124 |
СТОРОНА |
ЧЕЛОВЕKК |
0,749 |
0,456 |
5 |
|
125 |
СЕСТЬ |
РАБОТА |
0,707 |
0,421 |
5 |
|
126 |
ХОРОШИЙ |
ВИДЕТЬ |
0,706 |
0,218 |
5 |
|
127 |
ДЕЛАТЬ |
СЕСТЬ |
0,676 |
0,23 |
5 |
|
128 |
ЧЕЛОВЕKК |
ЭТО |
0,661 |
0,065 |
5 |
|
129 |
ДРУГ |
СТАРЫЙ |
0,654 |
0,266 |
5 |
|
130 |
ДЕЛАТЬ |
ТОЧKА |
0,65 |
0,546 |
5 |
|
131 |
ЧЕЛОВЕKК |
НОВЫЙ |
0,622 |
0,323 |
5 |
|
132 |
ОН |
ИДТИ |
0,618 |
0,197 |
5 |
|
133 |
ВИДЕТЬ |
ПЛОХОЙ |
0,612 |
0,509 |
5 |
|
134 |
ДАТЬ |
ОН |
0,612 |
0,283 |
5 |
|
135 |
ХОРОШИЙ |
ПРОСТОЙ |
0,612 |
0,269 |
5 |
|
136 |
ДЕЛАТЬ |
ПРИЙТИ |
0,612 |
0,345 |
5 |
|
137 |
ДЕЛАТЬ |
ГОЛОВА |
0,602 |
0,165 |
5 |
|
138 |
ДРУГ |
ЗЕМЛЯ |
0,581 |
0,531 |
5 |
|
139 |
ЗЕМЛЯ |
ДРУГ |
0,534 |
0,531 |
5 |
|
140 |
ЧЕЛОВЕK |
РАБОЧИЙ |
0,527 |
0,203 |
5 |
|
141 |
БОЛЬШОЙ |
ЧЕЛОВЕKК |
0,522 |
0,452 |
5 |
|
142 |
ПЛОХОЙ |
ВИДЕТЬ |
0,509 |
0,509 |
5 |
|
143 |
ЧЕЛОВЕKК |
БОЛЬШОЙ |
0,50 |
0,452 |
5 |
|
144 |
ПРОСТОЙ |
ЧЕЛОВЕKК |
0,487 |
0,202 |
5 |
|
145 |
ДЕЛАТЬ |
БОЛЬШОЙ |
0,487 |
0,297 |
5 |
|
146 |
БОЛЬШОЙ |
ДЕЛАТЬ |
0,474 |
0,297 |
5 |
|
147 |
ЧЕЛОВЕKК |
ИДТИ |
0,469 |
0,05 |
5 |
|
148 |
ВИДЕТЬ |
НОВЫЙ |
0,462 |
0,394 |
5 |
|
149 |
ГОРОД |
НОВЫЙ |
0,462 |
0,428 |
5 |
|
150 |
НОВЫЙ |
ГОРОД |
0,462 |
0,428 |
5 |
|
151 |
ЧЕЛОВЕKК |
СТОРОНА |
0,456 |
0,456 |
5 |
|
152 |
НОВЫЙ |
ВИДЕТЬ |
0,426 |
0,394 |
5 |
|
153 |
РАБОТА |
СЕСТЬ |
0,421 |
0,421 |
5 |
|
154 |
ПРОСТОЙ |
ПОМОЩЬ |
0,416 |
0,277 |
5 |
|
155 |
ЧЕЛОВЕK |
ЖИЗНЬ |
0,412 |
0,33 |
5 |
|
156 |
СТАРЫЙ |
ДРУГ |
0,406 |
0,266 |
5 |
|
157 |
ХОРОШИЙ |
ЧАС |
0,397 |
0,203 |
5 |
|
158 |
РАБОТА |
ЭТО |
0,377 |
0,283 |
5 |
|
159 |
ИДТИ |
ОН |
0,372 |
0,197 |
5 |
|
160 |
ИДТИ |
ЧЕЛОВЕK |
0,354 |
0,05 |
5 |
|
161 |
НОВЫЙ |
МЕСТО |
0,353 |
0,245 |
5 |
|
162 |
ПРИЙТИ |
ДЕЛАТЬ |
0,345 |
0,345 |
5 |
|
163 |
НОВЫЙ |
ДРУГ |
0,327 |
0,071 |
5 |
|
164 |
ТРУД |
ЧЕЛОВЕK |
0,318 |
0,248 |
5 |
|
165 |
ВИДЕТЬ |
ХОРОШИЙ |
0,309 |
0,218 |
5 |
|
166 |
РАБОЧИЙ |
ЧЕЛОВЕKК |
0,304 |
0,203 |
5 |
|
167 |
ЧЕЛОВЕK |
ТРУД |
0,294 |
0,248 |
5 |
|
168 |
ОН |
РАБОТА |
0,288 |
0,128 |
5 |
|
169 |
ОН |
ДАТЬ |
0,283 |
0,283 |
5 |
|
170 |
ЭТО |
РАБОТА |
0,283 |
0,283 |
5 |
|
171 |
ПОМОЩЬ |
ПРОСТОЙ |
0,277 |
0,277 |
5 |
|
172 |
ПРОСТОЙ |
ХОРОШИЙ |
0,269 |
0,269 |
5 |
|
173 |
БОЛЬШОЙ |
РАБОТА |
0,266 |
0,217 |
5 |
|
174 |
МЕСТО |
НОВЫЙ |
0,253 |
0,245 |
5 |
|
175 |
ХОРОШИЙ |
ДРУГ |
0,25 |
0,223 |
5 |
|
176 |
ВИДЕТЬ |
ЧЕЛОВЕK |
0,249 |
0,175 |
5 |
|
177 |
ПРОСТОЙ |
ВИДЕТЬ |
0,204 |
0,136 |
5 |
|
178 |
ЧЕЛОВЕKК |
ВИДЕТЬ |
0,175 |
0,175 |
5 |
|
179 |
РАБОТА |
МЕСТО |
0,145 |
0,118 |
5 |
|
180 |
МЕСТО |
РАБОТА |
0,131 |
0,118 |
5 |
|
181 |
РАБОТА |
ОН |
0,128 |
0,128 |
5 |
|
182 |
ЭТО |
ЧЕЛОВЕKК |
0,065 |
0,065 |
5 |
|
183 |
НОВЫЙ |
НОВЫЙ |
1,00 |
1,00 |
4 |
|
184 |
НОВЫЙ |
НАЧАТЬ |
1,00 |
0,93 |
4 |
|
185 |
ДАТЬ |
ИДТИ |
1,00 |
0,332 |
4 |
|
186 |
ЗДОРОВЬЕ |
ЗДОРОВЬЕ |
1,00 |
1,00 |
4 |
|
187 |
ГОВОРИТЬ |
НОВЫЙ |
1,00 |
0,801 |
4 |
|
188 |
ДЕЛАТЬ |
ДОБРЫЙ |
1,00 |
0,451 |
4 |
|
189 |
ДЕЛАТЬ |
KОМНАТА |
1,00 |
0,036 |
4 |
|
190 |
ЧЕЛОВЕKК |
ЧЕЛОВЕKК |
1,00 |
1,00 |
4 |
|
191 |
РУKА |
ВЗЯТЬ |
1,00 |
0,966 |
4 |
|
192 |
ВЗЯТЬ |
ВЗЯТЬ |
1,00 |
0,999 |
4 |
|
193 |
ДРУГ |
СТОРОНА |
1,00 |
0,726 |
4 |
|
194 |
ДАТЬ |
МЕСТО |
1,00 |
0,131 |
4 |
|
195 |
ПРОСТОЙ |
ПРОСТОЙ |
1,00 |
1,00 |
4 |
|
196 |
ГОЛОВА |
ГОЛОВА |
1,00 |
1,00 |
4 |
|
197 |
ХОРОШИЙ |
БОЛЬШОЙ |
1,00 |
0,715 |
4 |
|
198 |
ГОВОРИТЬ |
БОЛЬШОЙ |
1,00 |
0,238 |
4 |
|
199 |
СЕСТЬ |
СЕСТЬ |
1,00 |
1,00 |
4 |
|
200 |
ДРУГ |
МЕСТО |
1,00 |
0,894 |
4 |
|
201 |
ТРУД |
ТРУД |
1,00 |
1,00 |
4 |
|
202 |
БОЛЬШОЙ |
БОЛЬШОЙ |
1,00 |
1,00 |
4 |
|
203 |
СТОРОНА |
ДРУГ |
1,00 |
0,726 |
4 |
|
204 |
ДРУГ |
ДОРОГОЙ |
1,00 |
0,992 |
4 |
|
205 |
ЧИСТЫЙ |
ЧИСТЫЙ |
1,00 |
1,00 |
4 |
|
206 |
НАЧАТЬ |
НАЧАТЬ |
1,00 |
1,00 |
4 |
|
207 |
СТОРОНА |
СТОРОНА |
1,00 |
1,00 |
4 |
|
208 |
ДАТЬ |
ПИТЬ |
1,00 |
0,938 |
4 |
|
209 |
ЗДОРОВЬЕ |
ЧЕЛОВЕK |
1,00 |
0,169 |
4 |
|
210 |
НОВЫЙ |
ОН |
1,00 |
0,697 |
4 |
|
211 |
МЕСТО |
МЕСТО |
1,00 |
1,00 |
4 |
|
212 |
ВОДА |
ВОДА |
1,00 |
1,00 |
4 |
|
213 |
ХОРОШИЙ |
ОН |
1,00 |
0,09 |
4 |
|
214 |
РАБОТА |
ПРОВЕСТИ |
1,00 |
0,266 |
4 |
|
215 |
ЧАС |
ЧАС |
1,00 |
1,00 |
4 |
|
216 |
РУKА |
ГОВОРИТЬ |
1,00 |
0,031 |
4 |
|
217 |
ПРОСТОЙ |
ГЛАЗ |
1,00 |
0,242 |
4 |
|
218 |
РУKА |
ЭТО |
1,00 |
0,903 |
4 |
|
219 |
ГОРОД |
ИДТИ |
0,999 |
0,794 |
4 |
|
220 |
ДОРОГОЙ |
ДРУГ |
0,998 |
0,992 |
4 |
|
221 |
РАБОТА |
ЧАС |
0,998 |
0,154 |
4 |
|
222 |
ВЗЯТЬ |
РУКА |
0,997 |
0,966 |
4 |
|
223 |
РАБОТА |
ПРОСТОЙ |
0,996 |
0,935 |
4 |
|
224 |
ДРУГ |
ЛЮДИ |
0,996 |
0,786 |
4 |
|
225 |
РАБОТА |
РАЗГОВОР |
0,99 |
0,97 |
4 |
|
226 |
ГОВОРИТЬ |
РУКА |
0,989 |
0,031 |
4 |
|
227 |
ИДТИ |
ГОЛОВА |
0,989 |
0,385 |
4 |
|
228 |
РАЗГОВОР |
РАБОТА |
0,986 |
0,97 |
4 |
|
229 |
НАЧАТЬ |
НОВЫЙ |
0,986 |
0,93 |
4 |
|
230 |
ПИТЬ |
ДАТЬ |
0,984 |
0,938 |
4 |
|
231 |
РАБОТА |
СТОРОНА |
0,983 |
0,148 |
4 |
|
232 |
СКАЗАТЬ |
ГОВОРИТЬ |
0,962 |
0,785 |
4 |
|
233 |
РУКА |
ВИДЕТЬ |
0,959 |
0,268 |
4 |
|
234 |
НОВЫЙ |
СТОРОНА |
0,949 |
0,176 |
4 |
|
235 |
ПРОСТОЙ |
РАБОТА |
0,946 |
0,935 |
4 |
|
236 |
ДЕЛАТЬ |
ПЛОХОЙ |
0,942 |
0,368 |
4 |
|
237 |
ИДТИ |
ЖИЗНЬ |
0,925 |
0,318 |
4 |
|
238 |
ВОДА |
МЕСТО |
0,904 |
0,465 |
4 |
|
239 |
ЧЕЛОВЕК |
СДЕЛАТЬ |
0,904 |
0,09 |
4 |
|
240 |
ПОЛНЫЙ |
ДЕЛАТЬ |
0,904 |
0,476 |
4 |
|
241 |
ГОВОРИТЬ |
НАЧАТЬ |
0,904 |
0,246 |
4 |
|
242 |
ЭТО |
РУКА |
0,903 |
0,903 |
4 |
|
243 |
МЕСТО |
ДРУГ |
0,894 |
0,894 |
4 |
|
244 |
ВИДЕТЬ |
ЖИЗНЬ |
0,892 |
0,76 |
4 |
|
245 |
ДОБРЫЙ |
РАБОТА |
0,872 |
0,571 |
4 |
|
246 |
ЛЮДИ |
ДРУГ |
0,866 |
0,786 |
4 |
|
247 |
ИДТИ |
ГОРОД |
0,836 |
0,794 |
4 |
|
248 |
ГОВОРИТЬ |
СКАЗАТЬ |
0,816 |
0,785 |
4 |
|
249 |
НОВЫЙ |
ГОВОРИТЬ |
0,801 |
0,801 |
4 |
|
250 |
ЖИЗНЬ |
ВИДЕТЬ |
0,76 |
0,76 |
4 |
|
251 |
ОН |
НОВЫЙ |
0,73 |
0,697 |
4 |
|
252 |
БОЛЬШОЙ |
ХОРОШИЙ |
0,715 |
0,715 |
4 |
|
253 |
ЖИЗНЬ |
ВОДА |
0,707 |
0,301 |
4 |
|
254 |
ГОЛОВА |
РАБОТА |
0,707 |
0,457 |
4 |
|
255 |
ДРУГ |
СKАЗАТЬ |
0,707 |
0,14 |
4 |
|
256 |
ДОБРЫЙ |
ПОСТУПИТЬ |
0,707 |
0,554 |
4 |
|
257 |
ДОБРЫЙ |
ЧЕЛОВЕKК |
0,672 |
0,417 |
4 |
|
258 |
СТОРОНА |
ОН |
0,666 |
0,298 |
4 |
|
259 |
ЛЮДИ |
ЧЕЛОВЕKК |
0,666 |
0,453 |
4 |
|
260 |
СОВЕТСKИЙ |
ОН |
0,666 |
0,347 |
4 |
|
261 |
ИДТИ |
ХОРОШИЙ |
0,666 |
0,606 |
4 |
|
262 |
ГОРОД |
ХОРОШИЙ |
0,661 |
0,00 |
4 |
|
263 |
РАЗГОВОР |
ЧЕЛОВЕK |
0,661 |
0,598 |
4 |
|
264 |
МЕСТО |
ИДТИ |
0,654 |
0,113 |
4 |
|
265 |
РАБОТА |
ДОБРЫЙ |
0,654 |
0,571 |
4 |
|
266 |
ГОРОД |
РАБОТА |
0,654 |
0,267 |
4 |
|
267 |
РАБОТА |
СТОЯТЬ |
0,637 |
0,358 |
4 |
|
268 |
ДЕЛАТЬ |
СТОЛ |
0,632 |
0,547 |
4 |
|
269 |
ЧЕЛОВЕK |
ДОБРЫЙ |
0,62 |
0,417 |
4 |
|
270 |
ВИДЕТЬ |
ЭТО |
0,612 |
0,313 |
4 |
|
271 |
ДЕЛАТЬ |
ОПРЕДЕЛЕННЫЙ |
0,612 |
0,559 |
4 |
|
272 |
ОН |
ЖИТЬ |
0,612 |
0,559 |
4 |
|
273 |
ХОРОШИЙ |
ИДТИ |
0,606 |
0,606 |
4 |
|
274 |
ЧЕЛОВЕKК |
РАЗГОВОР |
0,598 |
0,598 |
4 |
|
275 |
ПЛОХОЙ |
ДЕЛАТЬ |
0,589 |
0,368 |
4 |
|
276 |
ОН |
ГОРОД |
0,577 |
0,522 |
4 |
|
277 |
РУKА |
ДОРОГОЙ |
0,577 |
0,555 |
4 |
|
278 |
ТРУД |
ДРУГ |
0,577 |
0,44 |
4 |
|
279 |
ДЕЛАТЬ |
ТОЧKА ЗРЕНИЯ |
0,577 |
0,522 |
4 |
|
280 |
ДЕЛАТЬ |
ПОЛОЖИТЬ |
0,577 |
0,00 |
4 |
|
281 |
ЧЕЛОВЕKК |
ВОЙНА |
0,577 |
0,44 |
4 |
|
282 |
ДЕЛАТЬ |
KНИЖKА |
0,577 |
0,522 |
4 |
|
283 |
ГОВОРИТЬ |
ХОРОШИЙ |
0,577 |
0,555 |
4 |
|
284 |
ТРУД |
ВИДЕТЬ |
0,577 |
0,446 |
4 |
|
285 |
ГОЛОС |
ДЕЛАТЬ |
0,577 |
0,362 |
4 |
|
286 |
ЖИТЬ |
ВИДЕТЬ |
0,577 |
0,357 |
4 |
|
287 |
СЛЕДОВАТЬ |
ДЕЛАТЬ |
0,577 |
0,471 |
4 |
|
288 |
ДАТЬ |
НОВЫЙ |
0,577 |
0,522 |
4 |
|
289 |
ГОВОРИТЬ |
СДЕЛАТЬ |
0,577 |
0,406 |
4 |
|
290 |
ДЕЛАТЬ |
НАСТОЯЩИЙ |
0,577 |
0,367 |
4 |
|
291 |
СЛЕДОВАТЬ |
РАБОТА |
0,577 |
0,471 |
4 |
|
292 |
ДРУГ |
ПЕРЕДАТЬ |
0,577 |
0,44 |
4 |
|
293 |
ДЕЛАТЬ |
ВОЙНА |
0,577 |
0,132 |
4 |
|
294 |
ЧЕЛОВЕKК |
МОЛОДОЙ |
0,577 |
0,44 |
4 |
|
295 |
ТОЧKА |
МЕСТО |
0,577 |
0,355 |
4 |
|
296 |
ДЕЛАТЬ |
ЗЕМЛЯ |
0,577 |
0,471 |
4 |
|
297 |
МЕСТО |
ХОРОШИЙ |
0,577 |
0,424 |
4 |
|
298 |
ГОЛОВА |
ИДТИ |
0,568 |
0,385 |
4 |
|
299 |
ОПРЕДЕЛЕННЫЙ |
ДЕЛАТЬ |
0,559 |
0,559 |
4 |
Построение семантических
ареалов ![]()
Корреляционная семантическая сеть
может быть представлена в виде ориентированного графа, где вершинами являются
элементы генерального словника, а связи могут интерпретироваться как
семантические отношения.
Каждому ребру графа ставится в
соответствие действительное число из интервала [0,1], называемое ВКО, которое
характеризует “силу” связи между вершинами графа, т.е. “силу” отношения между
соответствующими естественно-языковыми единицами.
Представляет интерес не только вся корреляционная
семантическая сеть целиком, а ее часть, характеризующаяся заданными
минимальными значениями “ВКО” и “Числом значений”. Такую семантическую сеть
будем называть приведенной. Главным достоинством приведенной семантической сети
является то, что она не содержит заведомо ложной информации относительно связей
между естественно-языковыми единицами, а имеющиеся связи сопоставимы, поскольку
соответствуют одному критерию (т.е. ВКО>=const, “Число значений”>=const).
На рис. 96 приведена схема
формирования приведенной семантической сети:
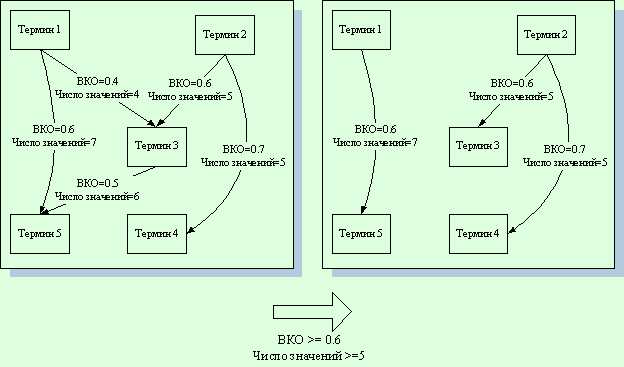
Рис. 95. Схема
формирования приведенной семантической сети
Достаточно очевидно, что приведенная
семантическая сеть скорее всего не будет являться полносвязной, т.е. в ней
возможно выделить отдельные, не связанные друг с другом фрагменты. Эти
фрагменты и являются семантическими ареалами.
Система “Интерлекс” позволяет
строить семантические ареалы для каждого элемента генерального словника. Для
этого нажмите кнопку “Построение семантических ареалов”. На экране появится
окно (рис. 96):
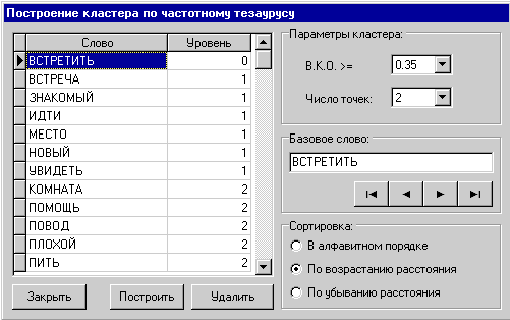
Рис. 96. Построение
семантических ареалов
В этом окне можно строить и
просматривать семантические ареалы. Семантические ареалы строятся для базового
слова, которое является центром ареала.
Просмотр семантических ареалов
осуществляется с помощью панели навигации.
Построение семантического ареала
выполняется по нажатию на кнопку “Построить” с использованием заданных в этом
же окне параметров ВКО и “Числа точек”.
Каждому слову в семантическом ареале
соответствует число в столбце “Уровень”. Оно показывает расстояние от базового
слова до соответствующего слова в семантическом ареале. Физический смысл
расстояния — это минимальное число шагов по приведенной семантической сети,
которые связывают базовое слово со словом семантического ареала. Считается, что
до самого базового слова требуется 0 шагов.
Для удобства отображения информации
можно воспользоваться переключателем “Сортировка”.
Если требуется обновить содержимое
семантического ареала или построить его с другими значениями “ВКО” и “Числа
точек” (т.е. число значений в корреляционной матрице), то рекомендуется удалить
его с помощью кнопки “Удалить”, выбрать новые минимальные значения ВКО и “Числа
точек” и построить ареал заново (нажать кнопку “Построить”).
Вся информация о семантических
ареалах сохраняется в таблице “NETCLUST.DB”.
Формат таблицы “netclust.db”
Таблица “netclust.db” имеет
следующую структуру:
– BaseKey.
Идентификатор базового слова, для которого строится ареал. Ссылка на таблицу
“dictkey.db”.
– RecordID. Порядковый
номер записи внутри ареала. Уникален внутри ареала.
– KeywordID.
Идентификатор слова из генерального словника, которое является элементом ареала
базового слова (BaseKey). Ссылка на таблицу “dictkey.db”.
– MinLen. Минимальное
расстояние от базового слова до элемента ареала.
Для получения копии этой таблицы в
виде, удобном для чтения, выполните c помощью утилиты DBD32 следующий
SQL-запроc:
select A.Keyword, C.Keyword, B.MinLen
from ‘netclust.db’ B, ‘dictkey.db’ A,
‘dictkey.db’ C
where A.RecordID=B.BaseKey AND
C.RecordID=B.KeywordID
order by B.MinLen;
Результат выполнения этого запроса
представлен на рис. 97:
Рис. 97. Таблица “netclust.db”
— семантический ареал термина “ВСТРЕТИТЬ”