1. ОБЩАЯ ХАРАКТЕРИСТИКА СИСТЕМЫ
Технические требования
Для функционирования системы
“Интерлекс” требуется следующий состав аппаратно-программных средств (знаком
“!” отмечена желательная конфигурация):
- Платформа/процессор: IBM совместимый компьютер на базе процессора
Intel 486, Pentium (!) или совместимый с ними.
- Оперативная память: 16 MB (для Windows 95/98) и 32 MB (для Windows
NT 4.0)
- Жесткий диск: Для установки и работы системы требуется не менее
200 MB свободного пространства.
- Видеосистема: Система “Интерлекс” рассчитана на эксплуатацию в
режиме не менее 800x600 точек при глубине цвета не менее 8 бит (256
цветов).
Другие аппаратные
средства: Для установки и работы с системой необходимы клавиатура, манипулятор
“мышь”, дисковод 3,5’.
- Операционная система: Windows 95/98 или Windows NT 4.0 SP3 (!).
- Дополнительное программное обеспечение. Для подготовки входных и
оформления выходных данных рекомендуется использование следующих
программных продуктов:
– MS Word 7.0 или выше (для
подготовки текстов);
– MS Excel 7.0 или выше (для
построения графиков и представления данных в табличной форме).
Состав системы
Программный комплекс
инструментальных средств автоматизации анализа естественно-языкового описания
предметной области “Интерлекс” оформлен в виде независимого 32-разрядного
приложения и предназначен для функционирования в среде Windows.
Система “Интерлекс” реализована на
языке “С/C++” и “Assembler”, использует интегрированный интерфейс прикладных
программ доступа к базам данных (IDAPI). Версия 2.0 системы поддерживает два
формата входных файлов: OEM-866 (для текстов, подготовленных в среде MS-DOS) и
ANSI-1251 (для текстов, подготовленных в среде Windows), для хранения
промежуточных и выходных данных используют файлы системы управления базами
данных (СУБД) “Paradox 5.0”.
Система построена на основе 5
фактически независимых блоков, каждый из которых предназначен для проведения
исследования определенного рода (рис.1):
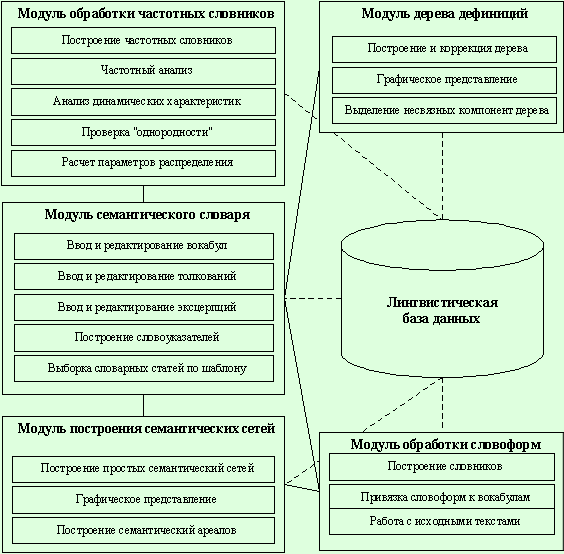
Рис. 1. Архитектура системы “Интерлекс”
Лингвистическая база данных
Лингвистическая база данных (ЛБД) является низкоуровневым объектом в
архитектуре системы (на рис.1 связи с другими модулями отмечены пунктиром) и
служит для хранения априорной, текущей и выходной информации об
естественно-языковых единицах, объектах и их связях. ЛБД логически связана со
всеми модулями системы.
Физически ЛБД реализована в виде
таблиц СУБД “Paradox 5.0” и доступна для администрирования утилитами этой
системы. Кроме того, в поставку системы “Интерлекс” включены две утилиты для
администрирования и настройки ЛБД: BDE Administrator и DataBase
Desktop.
Модуль обработки частотных
словников
Модуль служит для выполнения
следующих функций: построения и работы с частотными словниками, проведения
частотного и динамического анализа. Включает в себя средства проверки
“однородности” текстов на основе статистического критерия, а также включает
функции для расчета параметров распределения в модели “ранг-частота”.
Под частотным словником
понимается упорядоченная совокупность естественно-языковых единиц (словоформ и
парных словосочетаний), которым ставится в соответствие абсолютная или
относительная частота их встречаемости в исходном корпусе текстов. Частотные
словники обычно упорядочены по убыванию частоты.
Под моделью “ранг-частота”
понимается зависимость абсолютной или относительной частоты
естественно-языковой единицы от ее порядкового номера в упорядоченном по
убыванию частоты словнике. Наиболее известен закон Ципфа:
![]()
где k — общее число слов
(словоформ), r — ранг слова (словоформы), i(k,r) — абсолютная частота слова с
рангом r. Этот закон позднее был существенно дополнен и представлен в более
общем виде (закон Мандельброта):
![]()
где k — общее число слов
(словоформ), r — ранг слова (словоформы), p, v, b — параметры распределения,
i(k,r) — абсолютная частота слова с рангом r.
Модуль семантического словаря
Центральный модуль системы.
Реализует работу с семантическим словарем. Обеспечивает ввод и коррекцию
словарных статей (семантических и экземплярно-иллюстративных полей), а также
построение словоуказателей.
Под словарной статьей
понимается структурная единица словаря, упорядоченная последовательность
которых формирует текст словаря. Структура словарной статьи обычно остается
постоянной для всего словаря.
Основными элементами словарной
статьи (для семантического словаря) являются заголовочное слово
(словосочетание), семантическое поле, экземплярно-иллюстративное поле.
Под заголовочным словом
семантического словаря понимается словоформа (или словосочетание) в
каноническом (лемматизированном) виде.
Под семантическим полем
понимается вся совокупность дефиниций (определений) заголовочного слова
словарной статьи.
Под экземплярно-иллюстративным
полем понимается вся совокупность эксцерпций (примеров употребления
заголовочного слова в исходном корпусе текстов).
Под словоуказателем понимается
формальная конструкция <p1, p2, p3>, которая ставится в соответствие каждому
элементу экземплярно-иллюстративного поля и указывает его местоположение в
исходном корпусе текстов, где p1 — номер страницы,
p2 — номер строки, p3 — сквозной номер строки.
Модуль дерева дефиниций
Модуль служит для построения иерархической
структуры на основе имеющихся семантических полей для заголовочных слов
семантического словаря. Модуль содержит интерфейс для просмотра и
редактирования полученной структуры, а также средства для ее анализа (выделение
полносвязных поддеревьев). Имеет возможность визуального графического
представления информации.
Дерево дефиниций представляет собой структуру, показывающую
связность словарных статей семантического словаря между собой. Представляет
тезаурус экстралингвистических отношений “определяющее-определяемое”. Пусть
имеются две словарные статьи, где Ti — заголовочное
слово, Si — семантическое поле. Будем считать, что T1 и T2 находятся в отношении
“определяющее-определяемое”, R1 = =<T1, S1,...>, R2 = <T2, S2,...>, если: T1 хотя бы один раз встречается в S2. Обозначение: T1 > T2.
Модуль обеспечивает механизм
выделения неразрывных поддеревьев, т.е. деревьев, в которых от любого элемента
существует путь к другому элементу и только один. Семантический словарь может
состоять из нескольких поддеревьев.
Модуль обработки словоформ
Модуль служит для построения
генерального словника семантического словаря, имеет интерфейс для формирования
заголовочных слов семантического словаря и обеспечивает их автоматическую
привязку к словоформам, встретившихся в исходном корпусе текстов. Реализует
интерфейс для работы с исходным корпусом текстов.
Под генеральным словником
словаря понимается совокупность всех заголовочных слов словаря. Генеральный
словник является одним из наиболее важных компонентов словаря, поскольку
определяет вид, структуру, направленность и область его использования.
Модуль построения
семантических сетей
Модуль служит для построения и
анализа простых семантических сетей, построенных на основе статистического
анализа исходного корпуса текстов. Имеет возможность визуального графического
представления полученной сети в виде ориентированного графа. Позволяет выделять
из полученных семантических сетей полносвязные подграфы (семантические ареалы).
Под простой семантической сетью
понимается совокупность сущностей (заголовочных слов словаря), связанных между
собой дугами, интерпретируемыми как лингвистические или экстралингвистические
отношения. Простые семантические сети не имеют внутренней структуры.
Дистрибутив системы “Интерлекс”
распространяется на дискетах емкостью 1.44 MB. Для его создания было
использовано стандартное средство — InstallShield.
Перед началом установки убедитесь,
что аппаратно-программные характеристики вашего компьютера соответствуют
требованиям пакета “Интерлекс” (см. “Технические требования”), а также в
наличии 6 дискет с дистрибутивом системы. Все дискеты пронумерованы и имеют
наклейку вида (рис. 2):
|
|

Рис. 2. Вид первой
дискеты дистрибутива “Интерлекс”
Начало установки
Загрузите вашу операционную систему,
установите в дисковод первую инсталляционную дискету с системой “Интерлекс”,
нажмите на кнопку, выберите пункт меню “Settings” / “Control
Panel” и в появившемся окне щелкните на пиктограмме “Add/Remove
Programs” (см. рис. 3):
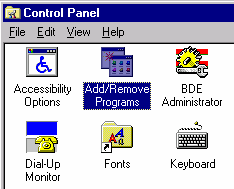
Рис. 3. Вид окна
“Control Panel”
В открывшемся окне диалога нажмите
кнопку “Install”, следуйте указаниям системного Wizard и, когда
будет предложено, найдите на диске “A” файл setup.exe, а затем
нажмите кнопку “Finish” (см. рис. 4):
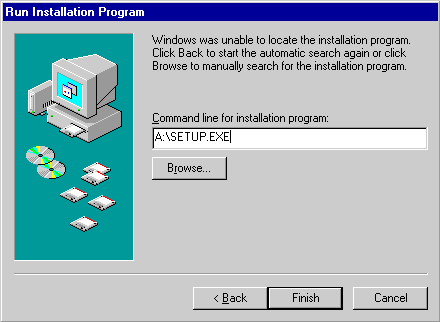
Рис. 4. Начало
установки системы “Интерлекс”
После того как InstallShield
завершит подготовку к установке, на экране появится Wizard, который поможет
установить систему “Интерлекс”.
Выбор рабочего каталога
Программа установки предложит
выбрать каталог, куда будут установлены системные и рабочие файлы комплекса “Интерлекс”
(рис. 5). По умолчанию, они будут установлены в каталог:
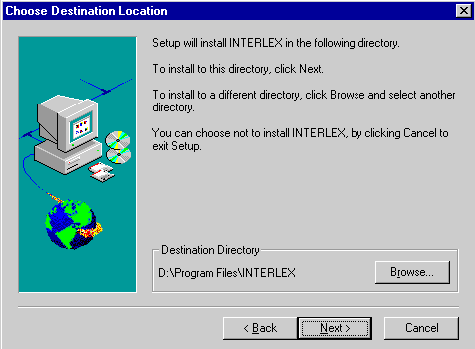
Рис. 5. Выбор
установочного каталога
[Системный диск]\Program Files\INTERLEX
Необходимо помнить, что для работы
системы требуется не менее 200 MB свободного места, поэтому следует выбрать
диск, удовлетворяющий этому требованию.
Далее программа установки будет
требовать вставить новый диск, а после завершения инсталляции выполнит все
необходимые системные настройки и создаст ярлык, доступный через меню
“Programs” (рис. 6):
Рис. 6. Вид меню
установленной системы “Интерлекс”
Запускаемые файлы
Программа установки помещает в меню
программ три ссылки на выполняемые файлы (см. рис. 6).
Утилита BDE Administrator
служит для настройки интерфейса доступа к базам данных (IDAPI). Необходимо
отметить, что система “Интерлекс” использует свое уникальное имя для
обозначения расположения файлов базы данных, что обеспечивает совместимость с
другими системами, использующими такой же интерфейс доступа к данным.
Утилита DataBase Desktop
позволяет быстро просматривать содержимое таблиц БД системы “Интерлекс”,
выполнять простые SQL-запросы, переносить данные из БД в MS Word или MS Excel.
Interlex 2.0 — непосредственно сама система “Интерлекс”.
Первый запуск
Сразу после
установки система готова к запуску. Для этого необходимо выбрать
соответствующий пункт системного меню (рис. 6). На экране появится заставка
(рис. 7), а затем главное окно системы (рис. 8).

Рис. 7. Заставка
системы “Интерлекс”
При первом запуске главное окно
системы не будет содержать никаких данных. Система автоматически создаст все
необходимые для работы файлы и проинициализирует их.
Файловая структура системы
После инициализации системы на диске
формируется следующая файловая структура (рис. 9).
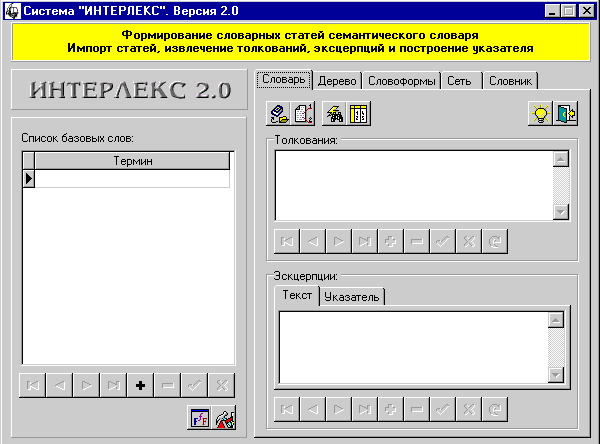
Рис. 8. Главное окно
системы
Для просмотра содержимого файлов
базы данных можно воспользоваться утилитой DBD32, входящей в состав комплекса
“Интерлекс”.
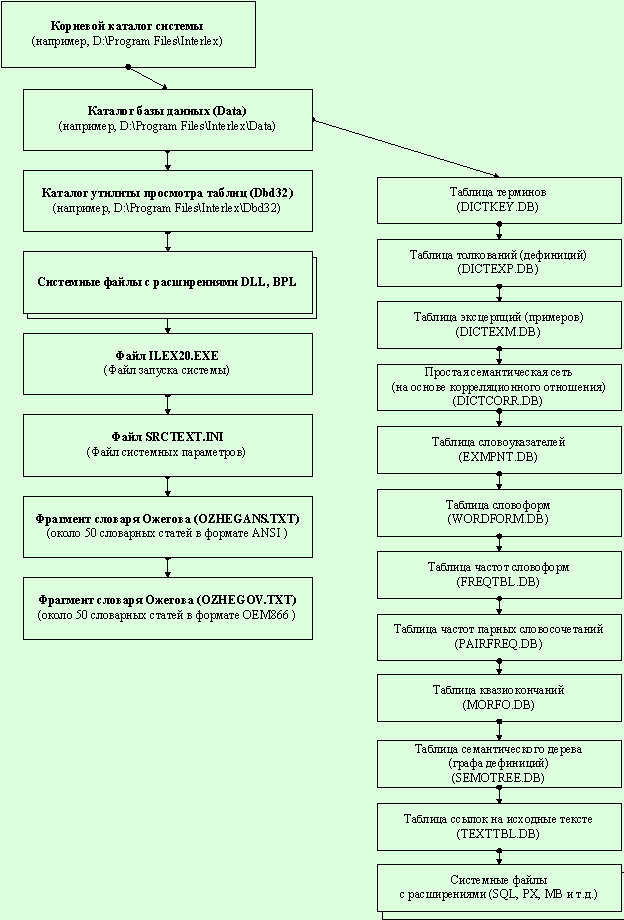
Рис. 9. Файловая
структура системы “Интерлекс”