5. ОПИСАНИЕ СЛОВАРЯ-ТЕЗАУРУСА
Полученный семантический словарь-тезаурус,
который приводится в третьей части книги, есть формальное представление
предметной области, основанное на корпусе научно-популярных текстов. Его
следует рассматривать как справочный материал для раскрытия семантики понятий,
приводимых в других энциклопедических или толковых словарях по этой же
предметной области. Словарь формально регистрирует факты наличия семантических
отношений между понятиями предметной области на заданном корпусе текстов.
Семантический словарь-тезаурус
представляет собой набор словарных статей, каждая из которых формально
характеризует какое-либо понятие предметной области.
Словарная статья состоит из
следующих полей:
·
ключевое
понятие,
·
категория
понятия,
·
абсолютная
частота понятия,
·
число
словоформ, связанных с этим понятием,
·
максимальный и
минимальный частотные индексы,
·
семантический
ареал: совокупность понятий предметной области, формально связанных с ключевым
понятием. Для каждого элемента семантического ареала указывается “сила” связи —
корреляционное отношение между частотными индексами данного элемента и
ключевого понятия.
На рис. 14 приведена структура
словарной статьи семантического словаря-тезауруса. Рассмотрим более подробно
каждый из элементов этой структуры.
1. Ключевое понятие
Ключевое понятие является заголовком
словарной статьи. Все словарные статьи расположены в алфавитном порядке
соответствующих ключевых понятий.
Ключевые понятия образуют
генеральный словник семантического словаря-тезауруса и получены фактически без
использования вычислительной техники. При этом использовалась следующая
методика:
·
Понятия
отбирались из частотных словников, построенных на корпусе текстов. Единственным
формальным показателем была абсолютная частота понятия в корпусе текстов. В
генеральный словник в основном включались предметные понятия, расположенные
вверху и в середине словника.
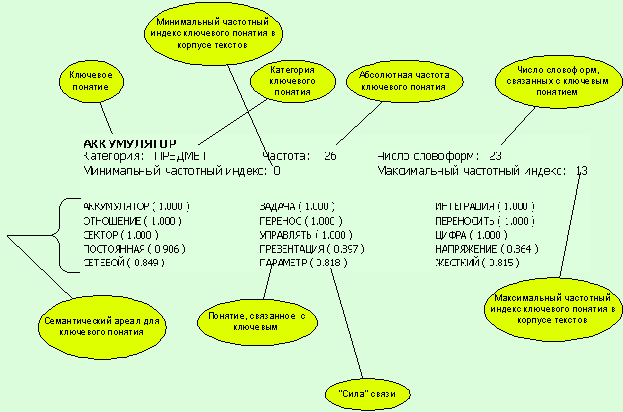
Рис. 14. Структура
словарной статьи
·
Часть понятий
была заимствована из других словарей по предметной области. В частности, одним
из источников был уже упоминавшейся ранее “англо-русский толковый словарь по
вычислительной технике, Интернету и программированию” Э. Пройдакова и Л.
Теплицкого [АРТСВТ, 2000].
·
В генеральный
словник вошли также понятия-стимулы, отобранные для проведения ассоциативного
эксперимента в предметной области “Информатика и вычислительная техника”15 .
·
Некоторые
понятия были включены методом экспертного отбора.
2. Категория ключевого понятия
Для каждого ключевого понятия,
вошедшего в генеральный словник семантического словаря-тезауруса, была
определена его категория. Под категорией здесь понимается условная
классификация понятий по четырем основным группам:
·
Предмет. Группа включает в себя понятия,
преимущественно обозначающие сущности, объекты или предметы. Например,
АККУМУЛЯТОР, ПРОЦЕССОР, КОМПЬЮТЕР и т.д.
·
Действие. В группу включены глагольные формы,
характеризующие операции, действия и процессы. Например, ОТКРЫТЬ, ПЕРЕДАТЬ,
КОПИРОВАТЬ, АНАЛИЗИРОВАТЬ и т.п.
·
Свойство. Данная группа представлена понятиями,
которыми обычно уточняют, описывают или характеризуют другие понятия. Например,
АСИНХРОННЫЙ <откат>, ВИДЕОГРАФИЧЕСКИЙ <контроллер>, ВИРТУАЛЬНЫЙ
<дисплей> и т.д.
·
Состояние. Последняя группа состоит в основном из понятий,
характеризующих некоторое событие, состояние или ситуацию. Например,
ВИЗУАЛИЗАЦИЯ (т.е. состояние визуализации чего-либо), ВОСПРОИЗВЕДЕНИЕ,
ВОССТАНОВЛЕНИЕ, ВЫДЕЛЕНИЕ и др.
3. Абсолютная частота ключевого
понятия
Каждому ключевому понятию поставлена
в соответствие числовая характеристика частоты его встречаемости в корпусе
текстов предметной области. В семантическом словаре-тезаурусе используется
интегральная характеристика, полученная на усреднении словоизменительных и
части словообразовательных форм ключевого понятия.
При построении частотных словников
частота непосредственно фиксируется только для словоформ, а не для их
канонических форм. Однако все ключевые понятия представлены в своих начальных
формах.
Методика построения семантического
словаря-тезауруса предусматривает механизм усреднения грамматических классов,
основанный на модифицированном методе квазиоснов, описанном в [Прохоров, 1999].
Таким образом, каждому ключевому понятию поставлены в соответствие конкретные
словоформы из частотных словников, построенных по корпусу текстов предметной
области.
Например,
|
ID |
ЛЕКСЕМА |
СЛОВОФОРМА |
АБС. ЧАСТОТА |
|
00003497 |
АВТОМАТ |
АВТОМАТ АВТОМАТА АВТОМАТЕ АВТОМАТЫ АВТОМНЫМ |
000010 000006 000002 000011 000001 |
|
00003251 |
АВТОМАТИЗАЦИЯ |
АВТОМАТИЗАЦИЕЙ АВТОМАТИЗАЦИИ АВТОМАТИЗАЦИЮ АВТОМАТИЗАЦИЯ |
000005 000562 000026 000049 |
|
00004149 |
АВТОМАТИЗИРОВАТЬ |
АВТОМАТИЗИРОВАЛ АВТОМАТИЗИРОВАЛА АВТОМАТИЗИРОВАЛО АВТОМАТИЗИРОВАН АВТОМАТИЗИРОВАНА АВТОМАТИЗИРОВАНО АВТОМАТИЗИРОВАНЫ АВТОМАТИЗИРОВАТЬ |
000002 000001 000001 000005 000007 000004 000014 000052 |
|
00003252 |
АДАПТАЦИЯ |
АДАПТАЦИЕЙ АДАПТАЦИИ АДАПТАЦИЮ АДАПТАЦИЯ |
000002 000025 000009 000006 |
|
00003499 |
АДАПТЕР |
АДАПТЕР АДАПТЕРА АДАПТЕРАМ АДАПТЕРАМИ АДАПТЕРАХ АДАПТЕРЕ АДАПТЕРНАЯ АДАПТЕРНОЙ АДАПТЕРНЫЕ АДАПТЕРНЫМ АДАПТЕРНЫХ АДАПТЕРОВ АДАПТЕРОМ АДАПТЕРУ АДАПТЕРЫ |
000163 000111 000008 000035 000011 000005 000001 000003 000015 000002 000010 000175 000041 000009 000157 |
Так, например, частота понятия “АВТОМАТ”
складывается из частот, связанных с ним словоформ: АВТОМАТ, АВТОМАТА и т.д.,
т.е. 10 + 6 + 2 + 11 + 1 = 30.
4. Число словоформ, связанных с
ключевым понятием
Как было упомянуто выше, каждому
ключевому понятию семантического словаря-тезауруса ставится в соответствие
словоформа из частотного словника. Однако частотные словники строятся для
каждого текста из корпуса текстов. Ключевое же понятие изначально никак не
соотносится с конкретным текстом — эта связь устанавливается косвенно через
словоформы, с которыми связаны ключевые понятия. Таким образом, в процессе
построения генерального словника образуется следующая структура (рис. 15):
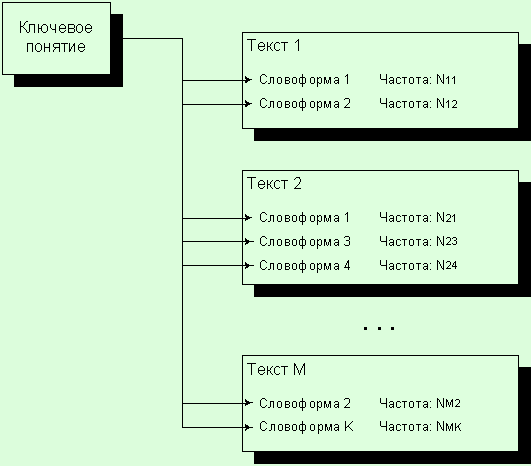
Рис. 15. Связь между
ключевым понятием, словоформой и текстом
Параметр “Число связанных с ключевым
понятием словоформ” характеризует общее число связей между ключевым понятием и
словоформами, т.е. может быть подсчитан по формуле
![]() ,
,
![]() где
где
Nforms (Kw)
— число словоформ для ключевого понятия Kw.
wti — i-я словоформа в
тексте t. i=1..Rt, где Rr — общее число словоформ
в тексте t.
L(k,w) — функция, имеющая значение
1, если k связана с w, 0 — в противном случае.
|
ЛЕКСЕМА |
СЛОВОФОРМА |
ТЕКСТ |
АБС. ЧАСТОТА |
|
АВТОМАТ |
АВТОМАТ АВТОМНЫМ АВТОМАТ АВТОМАТ АВТОМАТА АВТОМАТ АВТОМАТА АВТОМАТА АВТОМАТЫ АВТОМАТ АВТОМАТЫ АВТОМАТЕ АВТОМАТ АВТОМАТЫ АВТОМАТЕ АВТОМАТА АВТОМАТЫ АВТОМАТЫ АВТОМАТЫ АВТОМАТ АВТОМАТА АВТОМАТА |
ComputerWeek\01_95\DIC.TXT ComputerWeek\01_95\POWB.TXТ ComputerWeek\06_95\QU_DEL.TXT ComputerWeek\11_95\PL_DAT.TXT ComputerWeek\11_95\W95_RA.TXT ComputerWeek\12_95\HP_OP.TXT ComputerWeek\12_95\HP_OP.TXT ComputerWeek\14_95\KRZEM.TXT ComputerWeek\18_95\OLIVET.TXT ComputerWeek\24_95\SIEM.TXT ComputerWeek\25_95\JUK.TXT ComputerWeek\25_95\JUK.TXT ComputerWeek\25_95\JUK.TXT ComputerWeek\26_95\FICON.TXT ComputerWeek\33_95\GRAPH.TXT ComputerWeek\36_95\FPGA.TXT ComputerWeek\36_95\FPGA.TXT ComputerWeek\36_95\MNEWS2.TXT ComputerWeek\37_95\BUS.TXT ComputerWeek\37_95\COG.TXT ComputerWeek\41_95\WILD.TXT ComputerWeek\42_95\CRIME.TXT |
000002 000001 000001 000001 000001 000001 000001 000001 000001 000001 000006 000001 000003 000001 000001 000001 000001 000001 000001 000001 000001 000001 |
Значение параметра “число словоформ,
связанных с ключевым понятием” для понятия “АВТОМАТ” равно 22.
5.Частотные индексы
Формально, частотный индекс — это
номер частотного интервала, в который попадает абсолютная частота ключевого
понятия в определенном тексте. Однако необходимо определить назначение этой
характеристики и правила ее вычисления.
В качестве формальной меры связи
между ключевыми понятиями в словаре-тезаурусе используется корреляционное
отношение. Использование корреляционного отношения как меры семантической связи
обусловлено следующими допущениями:
·
Каждому слову
текста T можно поставить целочисленную величину, определяющую его количество
вхождений в текст T. Назовем эту величину абсолютной частотой слова в тексте T.
В формализованном виде это можно записать как fW(T).
·
Будем считать
величины fw(T) случайными. Данное допущение
небезосновательно. В действительности, употребление того или иного слова в
тексте определено большим числом факторов: синтаксисом, семантикой, контекстом,
стилем, жанром и т.д. Практически все эти факторы трудно формализуемы (или
вообще не формализуемы, если употребление слова связано с субъективными
предпочтениями автора или редактора текста, что, например, часто встречается в
переводных статьях) и трудно отделяемы друг от друга.
·
Если между
двумя естественно-языковыми единицами (в частности, словами) определено
синтагматическое, парадигматическое, ассоциативное или семантическое отношение,
то существует отличная от нуля вероятность, что на достаточно большом
количестве текстов можно построить функциональную зависимость между интервалами
частот этих слов в данных текстах. Формально, это допущение можно записать
следующим образом: ![]() ,
при
,
при ![]() , где P( ) —
вероятность события, заключенного в скобках, fWi(t) — частота слова Wi
в тексте t, D fi — допустимые отклонения
частот, L — функциональная зависимость между частотами слов и, наконец, {T1,
T2, …, TN} — область определения функции L.
, где P( ) —
вероятность события, заключенного в скобках, fWi(t) — частота слова Wi
в тексте t, D fi — допустимые отклонения
частот, L — функциональная зависимость между частотами слов и, наконец, {T1,
T2, …, TN} — область определения функции L.
·
Функцию L можно
рассматривать как формальную характеристику семантических отношений между
естественно-языковыми единицами. Для построения семантического
словаря-тезауруса нам необходимо знать только ее конкретные значения. Поэтому
более правильно было бы записать L в каноническом виде: ![]() , где S — некоторое числовое
значение функции L на множестве текстов
, где S — некоторое числовое
значение функции L на множестве текстов ![]() и множестве слов в этих текстах:
и множестве слов в этих текстах: ![]()
.
Фактически, значения корреляционного
отношения и рассматриваются как значения функции L.
Из математической статистики
известно, что для вычисления корреляционного отношения необходимо построить
корреляционную матрицу, каждый столбец и строка которой соответствуют некоторым
конкретным значениям характеристик, между которыми и вычисляется корреляционное
отношение. А сама матрица содержит число повторений этих значений в генеральной
совокупности.
Достаточно очевидно, как могла бы
выглядеть корреляционная матрица для вычисления корреляционного отношения между
частотами двух ключевых понятий:
|
|
Частоты для понятия 2 |
f1 |
… |
fN |
|
Частоты для понятия 1 |
— |
— |
— |
— |
|
f1 |
— |
K11 |
… |
K1N |
|
… |
— |
… |
… |
… |
|
fM |
— |
KM1 |
… |
KMN |
Рассмотрим, что представляют собой
частоты f1 ,..., fM и f1
и fN. Это не могут быть абсолютные частоты, так как
они напрямую зависят от размера текстов. Фактически, это означает, что
абсолютные частоты низкочастотного слова и высокочастотного могут совпасть,
если первая частота получена на тексте большего объема, чем текст, по которому
вычислялась частота второго слова. Очевидно, что использование абсолютных
частот для построения корреляционной матрицы некорректно.
Недостатки абсолютных частот можно
преодолеть, если использовать относительные частоты. Действительно,
относительные частоты уже не зависят от размера текста, более того, их значения
нормализованы (т.е. сумма относительных частот по всем словоформам текста равна
1). Тем не менее построить корреляционную матрицу все равно оказывается
невозможно, так как вероятность повторения значения относительной частоты у
некоторого слова в другом тексте близка к 0. Это приводит к тому, что
корреляционная матрица будет содержать только 0 и 1, да и перечислить все
частоты f1 ,..., fM и f1
и fN не представляется возможным, так как
относительная частота — действительное число от 0 до 1.
Таким образом, наиболее логичным в
данной ситуации представляется вычисление корреляционного отношения между
частотными интервалами, а строки и столбцы в корреляционной матрице сделать
соответствующими номерам этих частотных интервалов или, в нашем случае,
частотными индексами.
Поскольку распределение слов по
частоте подчинено закону Ципфа, то частотный интервал целесообразно определить
как
![]()
![]() , где
, где
max F — максимальная абсолютная
частота в тексте;
min F — минимальная абсолютная
частота в тексте;
NK — число частотных
интервалов;
k — частотный индекс.
Частотный индекс вычисляется для
каждого ключевого понятия по каждому тексту. В качестве max F и min F
используются максимальная и минимальная частоты, зафиксированные для ключевых
понятий на данном тексте.
Значение Nk
— это константа, которая устанавливается для всего семантического словаря и
эмпирически подбирается исходя из размеров текстов. Для статей еженедельника
“Computer Week” наиболее удобным оказалось значение Nk
= 20, т.е. для всех ключевых понятий теоретически возможные значения
минимального и максимального частотных индексов равны соответственно 0 и 19.
Ниже приведен фрагмент словника,
построенного по тексту “ComputerWeek\01_95\Aptalk.txt”:
|
ЛЕКСЕМА |
ЧАСТОТА |
Ч. И. |
|
ПРОТОКОЛ |
00041 |
00019 |
|
КОМПАНИЯ |
00015 |
00014 |
|
МАРШРУТИЗАТОР |
00013 |
00013 |
|
СРЕДСТВО |
00013 |
00013 |
|
МАРШРУТИЗАЦИЯ |
00012 |
00013 |
|
СЕРВЕР |
00009 |
00011 |
|
ТРАФИК |
00009 |
00011 |
|
ВРЕМЯ |
00005 |
00008 |
|
ДАННЫЕ |
00005 |
00008 |
|
ПОЛЬЗОВАТЕЛЬ |
00005 |
00008 |
|
РЕАЛИЗАЦИЯ |
00005 |
00008 |
|
СРЕДА |
00005 |
00008 |
|
КЛИЕНТ |
00004 |
00007 |
|
КОРПОРАЦИЯ |
00004 |
00007 |
|
МОДУЛЬ |
00004 |
00007 |
|
УСТРОЙСТВО |
00004 |
00007 |
|
СОВМЕСТИМОСТЬ |
00004 |
00007 |
|
ПРОГРАММНЫЙ |
00004 |
00007 |
|
ПРОГРАММА |
00004 |
00007 |
|
ДОСТУП |
00003 |
00005 |
|
КОНФИГУРАЦИЯ |
00003 |
00005 |
|
СВЯЗЬ |
00003 |
00005 |
|
РАБОТАТЬ |
00003 |
00005 |
|
РАБОТА |
00003 |
00005 |
|
ПЕРЕДАЧА |
00003 |
00005 |
|
ПЕРЕДАТЬ |
00003 |
00005 |
|
ОДНОВРЕМЕННЫЙ |
00003 |
00005 |
|
ЛИНИЯ |
00003 |
00005 |
|
КОРПОРАТИВНЫЙ |
00003 |
00005 |
|
АСИНХРОННЫЙ |
00002 |
00003 |
|
ИНФОРМАЦИЯ |
00002 |
00003 |
|
ПРОВЕРКА |
00002 |
00003 |
|
ЭФФЕКТИВНЫЙ |
00002 |
00003 |
|
УСТАНОВКА |
00002 |
00003 |
|
УДАЛЕННЫЙ |
00002 |
00003 |
|
ТЕХНОЛОГИЯ |
00002 |
00003 |
|
СТАНДАРТ |
00002 |
00003 |
|
СПЕЦИФИКАЦИЯ |
00002 |
00003 |
|
СОВМЕСТИМЫЙ |
00002 |
00003 |
|
СИСТЕМА |
00002 |
00003 |
|
ПРОЕКТ |
00002 |
00003 |
|
ПРИМЕР |
00002 |
00003 |
|
ОТКРЫТЫЙ |
00002 |
00003 |
|
ОБОРУДОВАНИЕ |
00002 |
00003 |
|
МЕТОД |
00002 |
00003 |
|
АДМИНИСТРАТОР |
00001 |
00000 |
|
АДРЕС |
00001 |
00000 |
|
ДИСТАНЦИОННЫЙ |
00001 |
00000 |
|
ИСКЛЮЧЕНИЕ |
00001 |
00000 |
|
ОПИСАНИЕ |
00001 |
00000 |
|
ОБСЛУЖИВАТЬ |
00001 |
00000 |
|
ОБЕСПЕЧЕНИЕ |
00001 |
00000 |
|
НИЗКОСКОРОСТНОЙ |
00001 |
00000 |
|
... |
|
|
|
ИНСТРУМЕНТАРИЙ |
00001 |
00000 |
|
ИНИЦИИРОВАТЬ |
00001 |
00000 |
|
ДОКУМЕНТ |
00001 |
00000 |
|
ВЫСОКОУРОВНЕВЫЙ |
00001 |
00000 |
|
ВЫПОЛНЕНИЕ |
00001 |
00000 |
|
ВКЛЮЧАТЬ |
00001 |
00000 |
|
АРХИТЕКТУРА |
00001 |
00000 |
Всего в словник попало 105 ключевых
понятий, максимальная абсолютная частота ключевого понятия в этом тексте = 41 (понятие
“ПРОТОКОЛ”), минимальная абсолютная частота = 1 (понятия, АДМИНИСТРАТОР, АДРЕС,
ДИСТАНЦИОННЫЙ, …, АРХИТЕКТУРА)
Функция L(k) для данного текста
имеет вид:
![]() .
.
В таблице ниже приведены абсолютные
частоты для некоторых частотных интервалов:
6. Семантический ареал
Под семантическим ареалом ключевого
понятия в семантическом словаре-тезаурусе понимается совокупность понятий и
терминов предметной области, для которых можно определить синтагматические,
ассоциативные, парадигматические или семантические отношения c ключевым
понятием. Вероятно, более точным, с точки зрения лингвистики, названием такой
единицы словаря было бы “предметный ареал” или “релевантные понятия”, так как
указанные типы отношений имеют различную природу и, как правило,
противопоставляются друг другу. Однако все эти типы отношений достаточно тесно
связаны друг с другом и, в конечном счете, влияют и определяют семантическую
составляющую.
|
Частотный индекс |
Частотный интервал |
Kомментарий |
|
0 |
[1, 1.2039] |
В данный частотный интервал попадают только слова с абсолютной частотой 1 |
|
1 |
[1.2039, 1.4494] |
Частотный интервал всегда пустой, так как допускает только частоты 1<f<2, что невозможно для абсолютных частот по определению |
|
2 |
[1.4494, 1.7550] |
|
|
3 |
[1.7450, 2.1009] |
В данный частотный интервал попадают только слова с абсолютной частотой 2 |
|
4 |
[2.1009, 2.5294] |
|
|
5 |
[2.5294, 3.0453] |
В данный частотный интервал попадают только слова с абсолютной частотой 3 |
|
… |
… |
|
|
13 |
[11.1651, 13.4422] |
В данный частотный интервал попадают только слова с абсолютными частотами: 12 и 13 |
|
14 |
[13.4422, 16.1836] |
В данный частотный интервал попадают только слова с абсолютными частотами: 14, 15 и 16 |
|
… |
… |
|
|
19 |
[34.0013, 41] |
В данный частотный интервал попадают только слова с абсолютными частотами: 35, 36, 37, …, 41 |
Как уже было упомянуто, формальной
мерой семантической связи между двумя ключевыми понятиями в семантическом
словаре-тезаурусе является корреляционное отношение, вычисленное между
частотными индексами этих двух понятий на всем корпусе текстов. В результате
вычисления корреляционного отношения между всеми определенными для данной
предметной области ключевыми понятиями строится простая семантическая сеть. В
узлах этой сети располагаются понятия предметной области, а дуги представляют
связи, “сила” которых формально определяется значением корреляционного
отношения. Семантическая сеть подвергается преобразованию с помощью методов
кластерного анализа, т.е. формируются семантические ареалы (кластеры) вокруг
ключевых понятий.
Рассмотрим более подробно процесс вычисления
корреляционного отношения. Для вычисления корреляционного отношения строится
корреляционная матрица Nk x Nk, строки и столбцы
которой соответствуют теоретически возможным частотным индексам (в нашем случае
частотные индексы могут принимать значения от 0 до 19). Строки соответствуют
частотным индексам первого понятия; столбцы — второго. Каждая ячейка
корреляционной матрицы с индексами f1 и f2,
где f1 — частотный индекс первого понятия, а f2
— второго, содержит число текстов из корпуса текстов, в которых частотные
индексы этих двух понятий равны f1 и f2 соответственно.
Ниже приведено формальное
представление корреляционной матрицы (табл. 1):
Таблица 1
Корреляционная матрица
|
W2 |
|
W1 |
|
|
|
|
|
... |
f1 = Nk –1 |
n(w2) |
|
f2 = 0 |
T0,0 |
… |
T0, Nk–1 |
|
|
… |
… |
… |
… |
… |
|
f2 = Nk–1 |
TNk–1, 0 |
… |
TNk–1, Nk–1 |
|
|
n (w1) |
|
… |
|
|
|
avg f2 (w1) |
|
… |
|
|
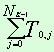
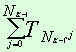
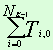

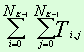
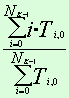
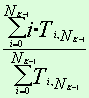
Обозначения:
W1 и W2
— ключевые понятия предметной области;
f1 — возможные значения
частотных индексов для понятия W1;
f2 — возможные значения
частотных индексов для понятия W2;
Nk — максимально возможное
значение частотного индекса, установленное для семантического
словаря-тезауруса;
n(w1) — число текстов, в
которых частотный индекс f1 понятия W1 принимает значения 0,
1, 2,…, Nk–1 соответственно;
n(w2) — число текстов, в
которых частотный индекс f2 понятия W2 принимает значения 0,
1, 2,…, Nk–1 соответственно;
avg f2 (w1)
— среднее значение частотного индекса для понятия W2
при условии, что частотный индекс f1 понятия W1 принимает значения
0,1,2, …, Nk-1 соответственно.
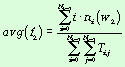 – среднее значение частотного индекса f2
– среднее значение частотного индекса f2
Корреляционное отношение между
частотными интервалами понятий W1 и W2 вычисляется по формуле
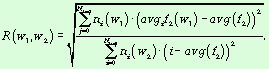
Для определения уровня доверия к
вычисляемому статистическому показателю предлагается определять степень
разреженности корреляционной матрицы по формуле
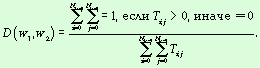
В семантический ареал входят только
те понятия, для которых:
R(k,w) >= 0.8, D(k,w) <= 0.8 и
абсолютная частота >= 20, где k — ключевое понятие, w — понятие, вошедшее в
семантический ареал.
Последние три условия и определяют
критерии для кластеризации семантической сети.
15 См. книгу данной
серии Ю.Филиппович, Г.Черкасова, Д.Дельфт. “Ассоциации информационных
технологий. Эксперимент на русском и французском языках”.