4. РЕЗУЛЬТАТЫ
ИССЛЕДОВАНИЯ ЕЯ ОПИСАНИЯ ПО
Для анализа была выбрана предметная
область “Информатика и вычислительная техника”, которая представлена корпусом
текстов еженедельного журнала “Computer Week” за 1995 г. Приведем общие характеристики
этого корпуса текстов:
N = 2631 – общее количество статей в
журнале.
S = 18 312 906 – общий размер (в
байтах) всего корпуса текстов.
T = 31 – количество представленных
тем и рубрик.
Ni — количество статей на
i-ю рубрику.
Y = 48 – количество журналов,
выпущенных за год.
Si — объем (в байтах) i-й
рубрики.
В приведенной ниже таблице приведены
все тематические рубрики, представленные в журнале:
|
№ |
Рубрика |
Ni |
Si |
|
1 |
Рынок программных средств |
540 |
4 188 466 |
|
2 |
Сети |
385 |
2 986 221 |
|
3 |
Рынок аппаратных средств |
372 |
2 589 282 |
|
4 |
Kиты индустрии |
144 |
1 002 302 |
|
5 |
Передовая технология |
105 |
730 845 |
|
6 |
Базы данных |
103 |
716 924 |
|
7 |
Программный продукт крупным планом |
101 |
703 003 |
|
8 |
Размышление и прогнозы |
79 |
549 874 |
|
9 |
Рынок ПK |
77 |
535 953 |
|
10 |
Системы и средства связи |
76 |
528 993 |
|
11 |
Менеджеру информационных систем |
60 |
417 626 |
|
12 |
Выставки, ярмарки, конференции |
56 |
389 784 |
|
13 |
Kомпьютеры и люди |
52 |
361 942 |
|
14 |
Защита данных |
48 |
334 100 |
|
15 |
Экономика информатики |
47 |
327 140 |
|
16 |
Мультимедиа |
45 |
313 219 |
|
17 |
Портативные ПK |
44 |
306 259 |
|
18 |
Графические средства и системы |
43 |
299 298 |
|
19 |
32-разрядные платформы |
38 |
264 496 |
|
20 |
Открытые системы. Стандарты |
35 |
243 615 |
|
21 |
Банковские системы |
32 |
222 733 |
|
22 |
Распределенные объектно-ориентированные БД |
28 |
194 892 |
|
23 |
Информатика и право |
18 |
125 287 |
|
24 |
Настольные издательские системы |
17 |
118 327 |
|
25 |
Имидж-реклама |
15 |
104 406 |
|
26 |
Информатика и госаппарат |
15 |
104 406 |
|
27 |
Kомпьютерный бизнес и право |
15 |
104 406 |
|
28 |
История в лицах |
13 |
90 485 |
|
29 |
Бизнес-клуб “CW-Moscow” |
12 |
83 525 |
|
30 |
Гуманитарная информатика |
10 |
69 604 |
|
31 |
Рынок программ и программистов |
6 |
41 762 |
|
|
Всего: 31 тема |
2631 |
18 312 906 |
Таблица составлена на основе материалов
электронной версии годовой подборки журналов, распространяемой издательством
“Computer Week”. Из приведенной таблицы явно следует, что представление
предметной области “Информатика и вычислительная техника” имеет выраженный
научно-популярный характер. Большая доля статей уделяется вопросам рынка,
рекламы, экономики, права, обсуждению конференций, персоналий и т.п. Эту
особенность необходимо учитывать при интерпретации результатов исследования
этого корпуса текстов.
Приведенная ниже таблица иллюстрирует
характеристики каждого текстового файла журнала:
|
Размер |
Имя |
|
431 766 |
01_95.txt |
|
416 848 |
02_95.txt |
|
414 424 |
03_95.txt |
|
411 252 |
04_95.txt |
|
351 366 |
05_95.txt |
|
376 165 |
06_95.txt |
|
364 570 |
07_95.txt |
|
413 196 |
08_95.txt |
|
398 684 |
09_95.txt |
|
414 916 |
10_95.txt |
|
418 969 |
11_95.txt |
|
383 208 |
12_95.txt |
|
410 905 |
13_95.txt |
|
386 396 |
14_95.txt |
|
484 842 |
15_95.txt |
|
370 416 |
16_95.txt |
|
408 131 |
17_95.txt |
|
390 900 |
18_95.txt |
|
424 130 |
19_95.txt |
|
370 634 |
20_95.txt |
|
331 807 |
21_95.txt |
|
428 050 |
22_95.txt |
|
418 550 |
23_95.txt |
|
372 145 |
24_95.txt |
|
351 246 |
25_95.txt |
|
330 754 |
26_95.txt |
|
317 124 |
27_95.txt |
|
336 462 |
28_95.txt |
|
371 020 |
29_95.txt |
|
356 101 |
30_95.txt |
|
352 243 |
31_95.txt |
|
425 170 |
32_95.txt |
|
357 842 |
33_95.txt |
|
329 764 |
34_95.txt |
|
414 170 |
35_95.txt |
|
469 162 |
36_95.txt |
|
428 525 |
37_95.txt |
|
391 909 |
38_95.txt |
|
418 711 |
39_95.txt |
|
475 967 |
40_95.txt |
|
495 330 |
41_95.txt |
|
390 622 |
42_95.txt |
|
311 879 |
43_95.txt |
|
291 732 |
44_95.txt |
|
283 885 |
45_95.txt |
|
291 953 |
46_95.txt |
|
264 998 |
47_95.txt |
|
264 116 |
48_95.txt |
Средний объем журнала (текста): s
=381 518 байт.
Тексты журналов подготовлены в виде
обычных текстовых файлов без разметки в формате DOS-866.
На основе этого корпуса текстов
необходимо выявить закономерности в отношениях естественно-языковых единиц и
сформировать иерархическую семантическую сеть и карты понятий. Согласно
предложенной в третьей главе технологии проведем исследование имеющегося
корпуса текстов.
Будем считать, что первый шаг
первого этапа выполнен, т.е. сформированы тексты ЕЯ описания ПО. Тогда
сформируем частотные словники по всему корпусу текстов, разделяя русскоязычную
и англоязычную лексику. Для этого воспользуемся пакетом “Интерлекс”12.
Построение русскоязычных словников
по всему корпусу текстов достаточно трудоемкий (по времени) процесс. В среднем
обработка одного текста составляет около 12 мин, а суммарное время, затраченное
на построение частотных словников по всему корпусу текстов (чистое время
построения) — около 10.5 ч. Основные характеристики частотных словников
приведены в таблице (табл. 20):
Nобщ — общее число
словоформ,
Nраз — число разных
словоформ,
Nmax — максимальная
частота.
|
Текст |
Nобщ |
Nраз |
Nmax |
|
“Сomputer Week”, №1 |
47525 |
11277 |
1527 |
|
“Сomputer Week”, №2 |
46188 |
10900 |
1504 |
|
“Сomputer Week”, №3 |
44540 |
10503 |
1568 |
|
“Сomputer Week”, №4 |
44587 |
10288 |
1487 |
|
“Сomputer Week”, №5 |
38052 |
9249 |
1451 |
|
“Сomputer Week”, №6 |
41976 |
10141 |
1417 |
|
“Сomputer Week”, №7 |
40328 |
9631 |
1362 |
|
“Сomputer Week”, №8 |
45977 |
10539 |
1497 |
|
“Сomputer Week”, №9 |
44356 |
10469 |
1551 |
|
“Сomputer Week”, №10 |
46327 |
10507 |
1608 |
|
“Сomputer Week”, №11 |
47017 |
11248 |
1579 |
|
“Сomputer Week”, №12 |
41769 |
9774 |
1357 |
|
“Сomputer Week”, №13 |
44788 |
10480 |
1456 |
|
“Сomputer Week”, №14 |
42117 |
9855 |
1369 |
|
“Сomputer Week”, №15 |
52847 |
12366 |
1718 |
|
“Сomputer Week”, №16 |
40375 |
9448 |
1312 |
|
“Сomputer Week”, №17 |
44486 |
10410 |
1446 |
|
“Сomputer Week”, №18 |
42608 |
9970 |
1385 |
|
“Сomputer Week”, №19 |
46230 |
10818 |
1502 |
|
“Сomputer Week”, №20 |
40399 |
9453 |
1313 |
|
“Сomputer Week”, №21 |
36167 |
8463 |
1175 |
|
“Сomputer Week”, №22 |
46657 |
10918 |
1516 |
|
“Сomputer Week”, №23 |
45622 |
10676 |
1483 |
|
“Сomputer Week”, №24 |
40564 |
9492 |
1318 |
|
“Сomputer Week”, №25 |
38286 |
8959 |
1244 |
|
“Сomputer Week”, №26 |
36052 |
8436 |
1172 |
|
“Сomputer Week”, №27 |
34567 |
8089 |
1123 |
|
“Сomputer Week”, №28 |
36674 |
8582 |
1192 |
|
“Сomputer Week”, №29 |
40441 |
9463 |
1314 |
|
“Сomputer Week”, №30 |
38815 |
9083 |
1261 |
|
“Сomputer Week”, №31 |
38394 |
8984 |
1248 |
|
“Сomputer Week”, №32 |
46344 |
10844 |
1506 |
|
“Сomputer Week”, №33 |
39005 |
9127 |
1268 |
|
“Сomputer Week”, №34 |
35944 |
8411 |
1168 |
|
“Сomputer Week”, №35 |
45145 |
10564 |
1467 |
|
“Сomputer Week”, №36 |
51139 |
11967 |
1662 |
|
“Сomputer Week”, №37 |
46709 |
10930 |
1518 |
|
“Сomputer Week”, №38 |
42718 |
9996 |
1388 |
|
“Сomputer Week”, №39 |
45639 |
10680 |
1483 |
|
“Сomputer Week”, №40 |
51880 |
12140 |
1686 |
|
“Сomputer Week”, №41 |
53976 |
11275 |
1878 |
|
“Сomputer Week”, №42 |
43423 |
10973 |
1655 |
|
“Сomputer Week”, №43 |
33324 |
8305 |
1250 |
|
“Сomputer Week”, №44 |
32108 |
8497 |
1134 |
|
“Сomputer Week”, №45 |
30707 |
8483 |
1078 |
|
“Сomputer Week”, №46 |
32437 |
8726 |
1141 |
|
“Сomputer Week”, №47 |
28572 |
8365 |
1077 |
|
“Сomputer Week”, №48 |
29289 |
8576 |
1002 |
Исследование выбранного корпуса
текстов по иноязычной (англоязычной) лексике в данной работе не проводится, однако
эта лексика выделяется из всего корпуса текстов и сохраняется как отдельный
словник.
Очередной шаг исследования ЕЯ
описания ПО связан с формированием ядра. Для формирования ядра выберем
полносвязную схему и проверим гипотезу об однородности текстов для каждой пары.
Всего, следовательно, нужно выполнить 1128 проверок. Воспользуемся системой
Интерлекс и проверим с помощью этого программного средства гипотезы, задавшись
пятипроцентным уровнем доверия.
Применение статистического критерия согласия
при пятипроцентном уровне доверия показало, что все отобранные тексты ЕЯ
описания ПО электронные версии выпусков журнала “Computer Week” могут быть
включены в ядро. Учитывая выбранную схему построения ядра, можно сделать вывод
о достаточной обоснованности этого включения. Таким образом,
естественно-языковое описание предметной области, представленное корпусом
текстов журнала “Computer Week”, является однородным.
Построим частотный словник для
парных русскоязычных словосочетаний. Эта процедура также может быть выполнена в
системе “Интерлекс”. К парным словосочетаниям относятся непосредственно рядом
стоящие слова, между которыми отсутствуют знаки препинания, обозначающие конец
предложения.
Проведем расчет параметрического
профиля, т.е. совокупности статистических параметров корпуса текстов, которые
определяют его структуру. Рассмотрим текст в модели “ранг-частота” и построим
эмпирическую кривую зависимости количества слов от их ранга.
Например, для текста “Сomputer
Week”, №1 эта кривая будет иметь такой вид (рис. 11):
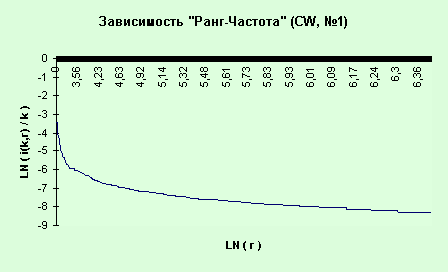
Рис. 11. Модель
“Ранг-Частота” для ЕЖ “Computer Week”, №1
Из лингвистической статистики известна
функциональная зависимость, описывающая это распределение:
![]() – з-н Мандельброта.
– з-н Мандельброта.
График этого распределения показан
на рис. 12:
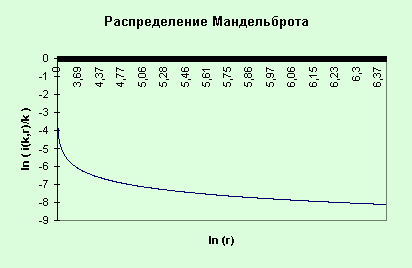
Рис. 12. Распределение
Мандельброта
Рассчитаем приближенные значения
параметров этого распределения. Результаты поместим в таблицу:
|
Текст |
С0 |
С1 |
С2 |
p |
v |
b |
|
“Computer Week”, №1 |
–3,326 |
-0,768 |
-0,002 |
0,0358 |
0,006 |
0,7722 |
|
“Computer Week”, №2 |
–3,344 |
-0,768 |
-0,002 |
0,0352 |
0,004 |
0,7707 |
|
“Computer Week”, №3 |
–3,558 |
-0,646 |
-0,015 |
0,0276 |
0,0491 |
0,6777 |
|
“Computer Week”, №4 |
–3,538 |
-0,623 |
-0,019 |
0,0279 |
0,066 |
0,6646 |
|
“Computer Week”, №5 |
–3,500 |
-0,676 |
-0,011 |
0,0295 |
0,0331 |
0,6982 |
|
“Computer Week”, №6 |
–3,447 |
-0,677 |
-0,014 |
0,0309 |
0,0419 |
0,7049 |
|
“Computer Week”, №7 |
–3,500 |
-0,669 |
-0,012 |
0,0294 |
0,0386 |
0,6946 |
|
“Computer Week”, №8 |
–3,404 |
-0,701 |
-0,011 |
0,0325 |
0,0313 |
0,7229 |
|
“Computer Week”, №9 |
–3,464 |
-0,675 |
-0,013 |
0,0304 |
0,0413 |
0,7029 |
|
“Computer Week”, №10 |
–3,423 |
-0,687 |
-0,012 |
0,0318 |
0,0363 |
0,7119 |
|
“Computer Week”, №11 |
–3,476 |
-0,703 |
-0,009 |
0,0304 |
0,0248 |
0,7201 |
|
“Computer Week”, №12 |
–3,443 |
-0,702 |
-0,011 |
0,0312 |
0,0324 |
0,7247 |
|
“Computer Week”, №13 |
–3,327 |
-0,692 |
-0,007 |
0,0354 |
0,0206 |
0,7063 |
|
“Computer Week”, №14 |
–3,501 |
-0,672 |
-0,012 |
0,0293 |
0,0389 |
0,6988 |
|
“Computer Week”, №15 |
–3,470 |
-0,7 |
-0,008 |
0,0306 |
0,0243 |
0,7176 |
|
“Computer Week”, №16 |
–3,425 |
-0,718 |
-0,007 |
0,032 |
0,0223 |
0,7349 |
|
“Computer Week”, №17 |
–3,341 |
-0,76 |
-0,002 |
0,0352 |
0,0064 |
0,7656 |
|
“Computer Week”, №18 |
–3,524 |
-0,67 |
-0,012 |
0,0287 |
0,0382 |
0,6964 |
|
“Computer Week”, №19 |
–3,466 |
-0,708 |
-0,007 |
0,0307 |
0,0229 |
0,7246 |
|
“Computer Week”, №20 |
–3,377 |
-0,752 |
-0,003 |
0,0339 |
0,0097 |
0,7601 |
|
“Computer Week”, №21 |
-3,501 |
-0,674 |
-0,012 |
0,0294 |
0,0377 |
0,7 |
|
“Computer Week”, №22 |
-3,429 |
-0,688 |
-0,011 |
0,0316 |
0,0343 |
0,7125 |
|
“Computer Week”, №23 |
-3,499 |
-0,677 |
-0,011 |
0,0295 |
0,0348 |
0,7013 |
|
“Computer Week”, №24 |
-3,485 |
-0,702 |
-0,008 |
0,0301 |
0,0232 |
0,7191 |
|
“Computer Week”, №25 |
-3,406 |
-0,738 |
-0,005 |
0,0328 |
0,0139 |
0,7488 |
|
“Computer Week”, №26 |
-3,344 |
-0,763 |
-0,002 |
0,0351 |
0,0071 |
0,7684 |
|
“Computer Week”, №27 |
-3,43 |
-0,731 |
-0,005 |
0,032 |
0,0149 |
0,7428 |
|
“Computer Week”, №28 |
-3,483 |
-0,72 |
-0,004 |
0,0304 |
0,0132 |
0,7294 |
|
“Computer Week”, №29 |
-3,452 |
-0,695 |
-0,01 |
0,0309 |
0,0324 |
0,7175 |
|
“Computer Week”, №30 |
-3,278 |
-0,984 |
0,02 |
0,0392 |
-0,0403 |
0,9451 |
|
“Computer Week”, №31 |
-3,515 |
-0,673 |
-0,011 |
0,029 |
0,036 |
0,6975 |
|
“Computer Week”, №32 |
-3,439 |
-0,721 |
-0,005 |
0,0317 |
0,0162 |
0,7327 |
|
“Computer Week”, №33 |
-3,449 |
-0,714 |
-0,007 |
0,0313 |
0,0208 |
0,7291 |
|
“Computer Week”, №34 |
-3,501 |
-0,689 |
-0,009 |
0,0296 |
0,0273 |
0,7083 |
|
“Computer Week”, №35 |
-3,508 |
-0,688 |
-0,01 |
0,0293 |
0,0312 |
0,7096 |
|
“Computer Week”, №36 |
-3,302 |
-0,794 |
0 |
0,0368 |
-0,0022 |
0,7927 |
|
“Computer Week”, №37 |
-3,493 |
-0,689 |
-0,009 |
0,0298 |
0,0297 |
0,7098 |
|
“Computer Week”, №38 |
-3,421 |
-0,718 |
-0,007 |
0,0322 |
0,021 |
0,7335 |
|
“Computer Week”, №39 |
-3,41 |
-0,746 |
-0,003 |
0,0328 |
0,0101 |
0,7535 |
|
“Computer Week”, №40 |
-3,477 |
-0,712 |
-0,006 |
0,0305 |
0,0181 |
0,7249 |
|
“Computer Week”, №41 |
-3,457 |
-0,694 |
-0,01 |
0,0309 |
0,0299 |
0,715 |
|
“Computer Week”, №42 |
-3,337 |
-0,784 |
0 |
0,0355 |
-0,0004 |
0,7839 |
|
“Computer Week”, №43 |
-3,471 |
-0,72 |
-0,004 |
0,0308 |
0,0126 |
0,7295 |
|
“Computer Week”, №44 |
-3,473 |
-0,68 |
-0,011 |
0,0303 |
0,0342 |
0,7041 |
|
“Computer Week”, №45 |
-3,529 |
-0,669 |
-0,011 |
0,0286 |
0,0365 |
0,6935 |
|
“Computer Week”, №46 |
-3,267 |
-0,799 |
0,001 |
0,0383 |
-0,0048 |
0,7954 |
|
“Computer Week”, №47 |
-3,354 |
-0,787 |
0,002 |
0,0351 |
-0,0054 |
0,783 |
|
“Computer Week”, №48 |
-3,532 |
-0,694 |
-0,007 |
0,0288 |
0,0229 |
0,7101 |
Найдем среднее значение и
среднеквадратичное отклонение каждого параметра:
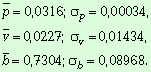
Таким образом, естественно-языковое описание
предметной области “Computer Week” имеет закон распределения в модели
“ранг-частота” следующего вида:
![]() – относительная частота слова с рангом r.
– относительная частота слова с рангом r.
Проведем исследование динамических
характеристик корпуса текстов “Computer Week”. Каждый текст является
представлением ЕЯ описания ПО в определенный момент времени. Всего весь корпус
текстов охватывает временной интервал в 12 месяцев. Будем исследовать следующие
динамические характеристики:
·
Динамика
структуры текстов.
·
Динамика
структуры словников.
·
Динамика
содержания словников.
·
Динамика
наполнения словников.
Построим соответствующие таблицы и
графики:
Динамика структуры текста:
|
F1 |
f2 |
F1 |
F2 |
F3 |
F4 |
F5 |
F6 |
F7 |
F8 |
F9 |
F10 |
F11 |
|
|
1 |
1 |
0,013406 |
0,018835 |
0,022632 |
0,02554 |
0,027491 |
0,029534 |
0,031103 |
0,032764 |
0,034551 |
0,035972 |
0,038028 |
Ряд 1 |
|
2 |
50 |
0,054031 |
0,096958 |
0,132602 |
0,160651 |
0,182823 |
0,207127 |
0,228357 |
0,250627 |
0,272381 |
0,29246 |
0,313552 |
Ряд 2 |
|
51 |
100 |
0,006904 |
0,017864 |
0,029425 |
0,039492 |
0,050433 |
0,059031 |
0,067695 |
0,078345 |
0,081201 |
0,089221 |
0,100698 |
Ряд 3 |
|
101 |
999999 |
0,023252 |
0,058785 |
0,099248 |
0,149786 |
0,192863 |
0,244118 |
0,295471 |
0,355305 |
0,419996 |
0,485611 |
0,547722 |
Ряд 4 |
|
|
|
0,097593 |
0,192442 |
0,283907 |
0,375469 |
0,45361 |
0,53981 |
0,622626 |
0,717042 |
0,808129 |
0,903263 |
1 |
|
Динамика структуры словника:
|
f1 |
f2 |
F1 |
F2 |
F3 |
F4 |
F5 |
F6 |
F7 |
F8 |
F9 |
F10 |
F11 |
|
|
1 |
1 |
0,163695 |
0,229996 |
0,276361 |
0,311868 |
0,33569 |
0,360641 |
0,379799 |
0,400085 |
0,421901 |
0,439254 |
0,464355 |
Ряд 1 |
|
2 |
50 |
0,116853 |
0,18995 |
0,244916 |
0,287871 |
0,32077 |
0,354949 |
0,384488 |
0,416385 |
0,444595 |
0,472554 |
0,501342 |
Ряд 2 |
|
51 |
100 |
0,001229 |
0,00321 |
0,005216 |
0,007046 |
0,008877 |
0,010256 |
0,011685 |
0,013441 |
0,014168 |
0,015622 |
0,017503 |
Ряд 3 |
|
101 |
999999 |
0,001003 |
0,002232 |
0,003561 |
0,005391 |
0,006695 |
0,00825 |
0,009805 |
0,01141 |
0,013616 |
0,015397 |
0,016801 |
Ряд 4 |
|
|
|
0,28278 |
0,425387 |
0,530053 |
0,612177 |
0,672033 |
0,734096 |
0,785777 |
0,84132 |
0,89428 |
0,942827 |
1 |
|
Динамика содержания словника:
|
f1 |
f2 |
F1 |
F2 |
F3 |
F4 |
F5 |
F6 |
F7 |
F8 |
F9 |
F10 |
F11 |
|
|
1 |
1 |
0,578877 |
0,540674 |
0,521383 |
0,509442 |
0,499515 |
0,491272 |
0,483342 |
0,475545 |
0,471777 |
0,46589 |
0,464355 |
Ряд 1 |
|
2 |
50 |
0,41323 |
0,446534 |
0,462059 |
0,470241 |
0,477313 |
0,483518 |
0,489309 |
0,494918 |
0,497154 |
0,50121 |
0,501342 |
Ряд 2 |
|
51 |
100 |
0,004345 |
0,007545 |
0,00984 |
0,01151 |
0,013209 |
0,013971 |
0,014871 |
0,015976 |
0,015843 |
0,01657 |
0,017503 |
Ряд 3 |
|
101 |
999999 |
0,003547 |
0,005246 |
0,006718 |
0,008807 |
0,009963 |
0,011238 |
0,012478 |
0,013561 |
0,015226 |
0,01633 |
0,016801 |
Ряд 4 |
|
|
|
1 |
1 |
1 |
1 |
1 |
1 |
1 |
1 |
1 |
1 |
1 |
|
Динамика наполнения словника:
|
f1 |
f2 |
F1 |
F2 |
F3 |
F4 |
F5 |
F6 |
F7 |
F8 |
F9 |
F10 |
F11 |
|
|
1 |
1 |
0,105087 |
0,208284 |
0,299654 |
0,385733 |
0,458635 |
0,544767 |
0,617021 |
0,706232 |
0,79906 |
0,888541 |
1 |
Ряд 1 |
|
2 |
50 |
0,17061 |
0,321412 |
0,437653 |
0,530586 |
0,602461 |
0,676487 |
0,741359 |
0,811684 |
0,873806 |
0,936028 |
1 |
Ряд 2 |
|
51 |
100 |
0 |
0,002865 |
0,004298 |
0,012894 |
0,032951 |
0,120344 |
0,270774 |
0,459885 |
0,627507 |
0,812321 |
1 |
Ряд 3 |
|
101 |
999999 |
0,059701 |
0,132836 |
0,21194 |
0,320896 |
0,398507 |
0,491045 |
0,583582 |
0,679104 |
0,810448 |
0,916418 |
1 |
Ряд 4 |
|
|
|
0,135334 |
0,260137 |
0,362196 |
0,450738 |
0,52228 |
0,602472 |
0,672735 |
0,754332 |
0,833722 |
0,911482 |
1 |
|
В таблицах использованы следующие
обозначения:
f1 — нижняя граница исследуемого
частотного интервала,
f2 — верхняя граница
исследуемого частотного интервала,
![]() .
.
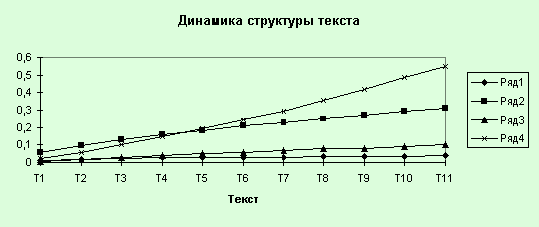
Динамика структуры текстов
показывает относительный объем каждого частотного интервала относительно общего
числа слов во всех текстах. Из графика “Динамика структуры текста” хорошо
видно, что объем всех частотных групп нарастает линейно от текста к тексту. Это
означает, что одинаковые частотные интервалы в разных текстах содержат
одинаковое количество слов. Это дает возможность говорить не только о
лексической однородности, но и частотной однородности текстов. Это, в
частности, подтверждается относительно небольшими значениями среднеквадратичных
отклонений параметров распределения Мандельброта, которые были получены выше.
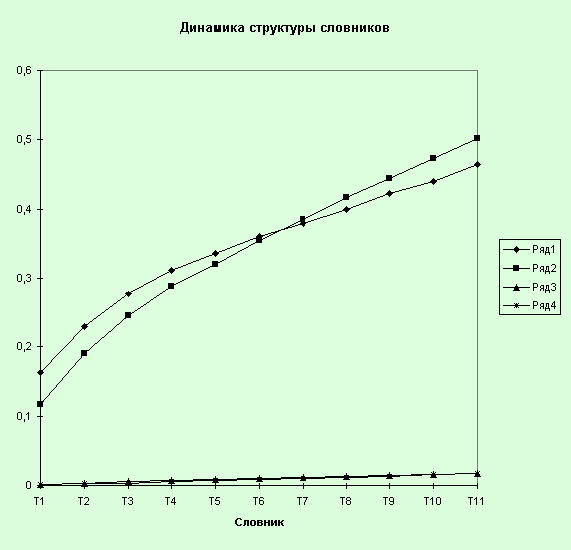
Напротив, динамика структуры
словников показывает наличие неоднородности для частотных интервалов ниже 50.
Из графика “Динамика структуры словников” видно, что кривые, соответствующие
частотным интервалам (1,1) и (2,50), имеют нелинейный характер. Вогнутость
говорит о том, что доля малочастотной лексики становится меньше при переходе от
текста к тексту, хотя доля слов, образующих высокочастотные интервалы, остается
незначительной (около 2–2,5% для частотных интервалов, больших 50). Таким
образом, из всей лексики, содержащейся в корпусе текстов, анализу с помощью
статистических методов может быть подвергнуто только 2% слов, поскольку частоты
остальных не позволят получить надлежащую статистику. Сложим объемы всех
текстов, входящих в корпус, и получим 2003090 слов, тогда “эффективный” объем
будет составлять около 40000 слов. Необходимо помнить, что здесь речь идет о
словоформах, тогда как при лемматизации это число сильно сократится.
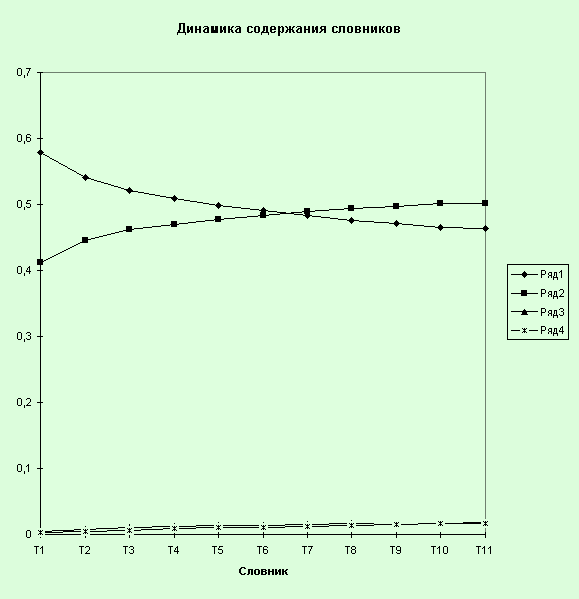
Рассмотрим теперь внутренние пропорции
каждого частотного интервала (см. график “Динамика содержания словника”).
Отчетливо просматривается изменение соотношений среди малочастотной лексики.
Доля лексики в частотном интервале (2, 50) увеличивается и становится
наибольшей. Вместе с тем происходит снижение доли лексики с частотой 1. Это
результат “насыщения”, когда в каждом новом тексте встречается все меньше и
меньше новых слов. Поэтому в общем корпусе текстов основную долю представляют
“средние частоты”.
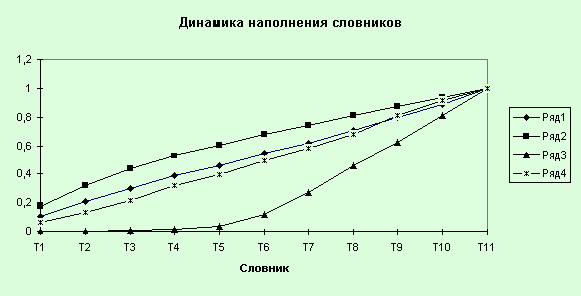
Четвертая динамическая характеристика:
“Динамика наполнения словника”. Ее смысл в том, что она показывает соотношение
долей “заполненности” частотной группы на некотором этапе. Здесь интерес
представляет частотный интервал (51, 100). Активное заполнение этого частотного
интервала начинается только с пятого текста за счет перетекания слов в этот
частотный интервал из других частотных групп.
4.2. Генеральный словник ЕЯ
описания ПО
Для получения списка тех словоформ и
парных словосочетаний, которые могут быть внесены в генеральный словник,
воспользуемся правилом, которое было сформулировано п. 3.3. Для его применения
необходимо построить частотный словник по некоторому тексту, в котором не
содержится предметной лексики14. Приведем еще раз методику отсечения
непредметной лексики:
Пусть:
S(T1) — частотный словник
для всей исследуемой генеральной совокупности (корпуса текстов).
S(T2) — частотный словник
для текста с непредметной лексикой.
Тогда искомый словник S(T*)
= S(T1) — S(T2). Операция вычитания словников
была введена во второй главе. Необходимо сделать только одно замечание. На
практике необходимо выравнивание частот в словниках S(T1)
и S(T2), поскольку тексты T1
и T2 имеют, как правило, разные размеры. По этой
причине от абсолютных частот имеет смысл перейти к относительным.
Фрагмент частотного словника (по
словоформам и словосочетаниям) по тексту с непредметной лексикой приведен в
Приложении 4 материалов электронного издания на CD ROM, которые сопровождают
книгу.
Теперь, для того чтобы получить
словник S(T*), можно воспользоваться SQL-запросом:
DELETE FROM ‘_wftbl_.db’ A
WHERE A.WordformID IN (SELECT
B.WordformID FROM ‘sbor.db’
WHERE A.RelFreq <= B.RelFreq)
Из полученного словника отбираются
лексемы. Список этих лексем представлен в Приложении 5 на CD ROM. При отборе
все лексемы необходимо преобразовать к каноническому виду. Однако в этом случае
теряется связь с текстом (например, для лексемы нельзя указать частоту ее
появления). Чтобы устранить это, необходимо провести привязку лексем к словоформам.
Эта процедура может быть выполнена автоматически в системе “Интерлекс” с
помощью метода квазиокончаний. В приложении 5 на CD ROM приводятся результаты
такой привязки. Аналогичные конструкции можно построить и по словосочетаниям.
Сформируем элементарные
семантические и экземплярно-иллюстративные поля на основе корпуса текстов. Для
этого воспользуемся системой Интерлекс и извлечем из текста элементарные
дефиниции и эксцерпции для каждой отобранной лексемы. Параллельно будет
построен и указатель источника. Поскольку отбор примеров делается из корпуса
текстов, в которых нет разметки на страницы, то будет формироваться только
сквозной номер строки (Приложение 6 на CD ROM).
При извлечении элементарных
дефиниций из текста система “Интерлекс” дополняет генеральный словник словами,
которых там не было, но имеющих дефиницию в тексте. Это относится как к
отдельным словам, так и к словосочетаниям. Понятно, что для некоторых ЕЯ
конструкций частота встречаемости во всем корпусе текстов может быть равна 1,
что не дает возможности их исследования статистическими методами. Однако на
этапе построения генерального словника все слова и словосочетания, каким-либо
образом выделенные в процессе анализа, должны быть включены в него.
Итак, на основании вышесказанного, в
генеральный словник войдут слова и словосочетания, которые:
·
отобраны из
списка, полученного в результате операции вычитания словников с предметной и
непредметной лексикой (слова и парные словосочетания);
·
автоматически
внесены в генеральный словник при формировании элементарных дефиниций;
·
англоязычная
лексика (из словника, сформированного на первом этапе).
Выполнение очередного этапа
завершилось формированием генерального словника ЕЯ описания ПО и определением
основных характеристик лексем, вошедших в него. В частности, были сформированы
элементарные дефиниции на основе синтаксического анализа корпуса текстов, было
построено экземплярно-иллюстративное поле для каждой лексемы на основе
эксцерпций, а также были рассчитаны частотные характеристики лексем на основе связей
с соответствующими словоформами. Все указанные параметры были получены и
сохранены в лингвистической базе данных, а в приложениях были отражены только
ее отдельные фрагменты. Это связано в первую очередь со сложностью структуры и
неоднородностью заполнения внутренних полей ЛБД. Все полученные характеристики
будут на следующем этапе помещены в соответствующие поля карты понятий.
4.3. Семантическая сеть и
карты понятий
Построение семантической сети
основано на применении дистрибутивно-статистического метода и корреляционного
отношения для получения числовой характеристики связанности слов в тексте.
Семантический анализ будем проводить на всем корпусе текстов. Воспользуемся
возможностями системы “Интерлекс” (рис. 13):
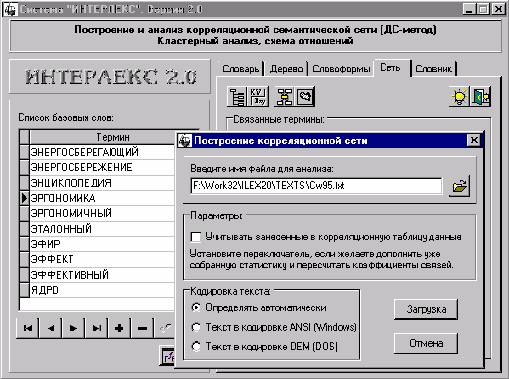
Рис. 13. Построение
корреляционной (семантической) сети в системе “Интерлекс”
Полученная семантическая сеть
сохраняется в лингвистической базе данных в таблице со следующей струкурой:
|
№ |
MasterID |
SlaveID |
Rxy |
KV |
ValCount |
MasterID — идентификатор лексемы, из
которой выходит связь;
SlaveID — идентификатор лексемы, на
которую связь направлена;
Rxy — корреляционное отношение;
KV — коэффициент корреляции;
ValCount — число точек в
корреляционной матрице для пары (MasterID, SlaveID).
Определим основные характеристики
семантической сети:
|
Число записей в таблице: |
108598 |
|
Максимальное значение Rxy: |
1 |
|
Минимальное значение Rxy: |
0.001 |
|
Максимальное значение ValCount: |
65 |
|
Минимальное значение ValCount: |
2 |
|
Число вершин сети (N): |
1156 |
|
Число связей (M): |
108598 |
|
Число нелинейных связей (Rxy0 KV=0): |
914 |
|
Число выраженных линейных связей (RV=1): |
9915 |
|
|
|
|
Число выраженных нелинейных связей (Rxy=1): |
14533 |
Из формул (3.21) получим число
несвязанных компонент сети (k):
![]() ,
,
![]() ,
,
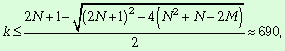
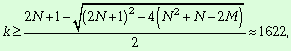
![]()
Поскольку число компонент сети не
может превышать число вершин, то делаем вывод, что число несвязанных компонент
семантической сети лежит в пределах:
![]()
Построим приведенную семантическую
сеть, приняв в качестве пороговых значений R0 (пороговое значение
корреляционного отношения) и V0 (пороговое значение числа точек в
корреляционной матрице) значения: R0 = 0.5, V0 = 8.
Такая сеть может быть построена с помощью
следующего SQL-запроса:
SELECT * FROM ‘dictcorr.db’ WHERE
Rxy >= 0.5 AND ValCount >= 8.
В приведенной семантической сети
присутствуют только те связи, которые удовлетворяют требованию:
Для любых ![]() .
.
Определим параметры приведенной
семантической сети:
|
Число записей в таблице: |
2211 |
|
Максимальное значение Rxy: |
1 |
|
Минимальное значение Rxy: |
0.5 |
|
Максимальное значение ValCount: |
65 |
|
Минимальное значение ValCount: |
8 |
|
Число вершин сети (N): |
1156 |
|
Число связей (M): |
2211 |
Определим число несвязанных
компонент приведенной семантической сети:
![]() ,
,
![]() ,
,
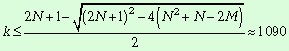 ,
,
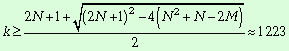 ,
,
![]()
Видно число несвязанных компонент
возросло примерно в 1,5 раза. Это позволяет сделать вывод о наличии
семантических ареалов.
На заключительном этапе исследования
ЕЯ описания ПО строится простая и иерархическая семантические сети и
формируются карты понятий.
12 Пакет “Интерлекс”
— система автоматизированного анализа естественно-языкового описания предметных
областей, разработанная в рамках НИОКР по исследованию семантико-статистических
характеристик текстов и представленная в качестве дипломной работы Прохоровым
А.В. в 1998 г.
14 В качестве такого
текста были взяты материалы для хрестоматии “Отечественные лексикографы”
[Богатова, 1998]. Текст содержит в основном общеупотребительную и специальную
филологическую лексику, и поэтому его словник может служить для отсечения
непредметной лексики в корпусе текстов журнала “Computer Week”.