3. ТЕХНОЛОГИЯ
АВТОМАТИЗИРОВАННОГО ПОСТРОЕНИЯ
СЛОВАРЯ-ТЕЗАУРУСА
Задачей данной главы является разработка
технологии создания системы организации знаний на базе семантического
словаря-тезауруса. Под термином “технология” в научной литературе часто
понимают совокупность (последовательность) приемов, нацеленных на создание
чего-либо [Шемакин, 1995]. В данном случае речь идет о создании системы
организации знаний. Как уже неоднократно отмечалось, единой автоматизированной
технологии создания систем подобного класса нет. Это связано с трудностями и
неоднозначностями представления ЕЯ описания ПО.
Так, в литературе [Шрейдер, 1972]
можно встретить точку зрения, что технология построения тезауруса целиком и
полностью зависит от человека. Ю.А.Шрейдер отмечает, что “более перспективным
методом является тот, где человек отбирает слова и значимые пары, указывая смысловые
сходства слов и пар, а последующее разбиение материала на рубрики и сам выбор
рубрик можно автоматизировать”. Легко заметить, что подобная технология имеет
узкое место, связанное с отбором терминов и определения связей между ними.
Понятно, что ввиду исключительной сложности задачи сегодняшние
автоматизированные средства не позволяют полностью заменить человека, но это не
значит, что невозможно получение максимально полезной для составления тезауруса
информации из анализа “сырых текстов” [Шрейдер, 1972].
Рассмотреть частную технологию,
которая может приниматься или не приниматься при решении других аналогичных
задач, но в которой наибольшее внимание уделено формальным преобразованиям ЕЯ
описания ПО.
В любом технологическом процессе
необходимо, прежде всего, четко представлять исходное и конечное состояние
этого процесса. В рамках проблемы организации знаний на базе семантического
словаря-тезауруса эти состояния могут быть представлены следующим образом (рис.
8):
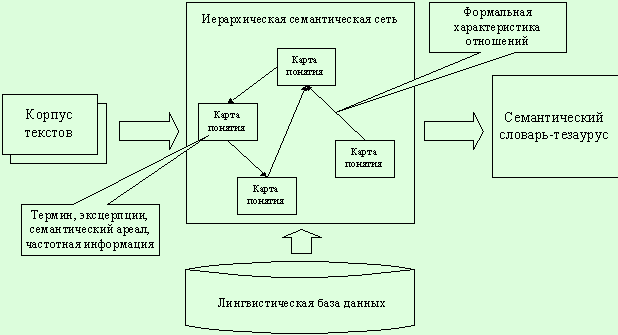
Рис. 8. Иерархическая
семантическая сеть
Основная часть работы посвящается
разработке автоматизированной технологии построения семантической сети и карт
понятий, которые уже при активном участии человека могут быть представлены в
принятой в лексикографии форме словаря-тезауруса. На рис. 8 показана
иерархическая семантическая сеть, основное отличие от простой семантической
сети, заключается в том, что каждая вершина имеет свою собственную структуру.
Эта структура подразумевается под термином “карта понятия”. Карта понятия
— это совокупность формальных дескрипторов понятия или термина предметной
области. Так, например, в карту понятия может входить частота слова, указатели
источников, классификационные признаки, семантическое поле и т.п.
Для хранения иерархической
семантической сети используется лингвистическая база данных. Это понятие уже
было использовано ранее, когда рассматривались отдельные формальные методы
обработки ЕЯ информации.
Для построения автоматизированной
технологии необходимо определить точную структуру объектов “карта понятия” и
лингвистическая база данных. Таким образом, правильнее начать рассматривать
автоматизированную технологию с описания структуры этих объектов.
3.1. Лингвистическая база
данных
Лингвистическая база данных (ЛБД) —
это специальная структура данных, которая служит для хранения и эффективного
использования исходной, промежуточной и конечной информации о ЕЯ объектах и их
отношениях. ЛБД представляет собой реляционную структуру, для которой
существует эффективный алгоритм оптимизации, что позволяет достаточно легко
решать задачи добавления, изменения и поиска информации. Основные положения
теории реляционной алгебры и баз данных были рассмотрены в первой главе. Сейчас
же необходимо сделать акцент на содержательной стороне ЛБД и разработать ее
оптимальную структуру.
Выделим основные сущности, которые
должны быть представлены в ЛБД без указания каких-либо отношений между ними:
Вокабулы9 — это отбираемые по определенным критериям лексемы, которые могут
являться терминами в рассматриваемой предметной области. Поскольку вокабулы
есть подмножество лексем, которые связаны с некоторыми конкретными словоформами
в исходном корпусе текстов, то для них можно определить частотный параметр.
Толкование (дефиниция). Под толкованием будем понимать выраженное в
ЕЯ форме одно из возможных значений вокабулы. Совокупность всех толкований для
некоторой вокабулы будет представлять собой семантическое поле.
Эксцерпция — конкретный пример употребления вокабулы в
тексте. Для определенности будем считать, что единичной эксцерпцией является
предложение. Совокупность всех эксцерпций вокабулы образуют
экземплярно-иллюстративное поле.
Текст — имя, название и/или указатель на конкретное
ЕЯ представление ПО, носителем которого является двоичный файл в определенном
формате.
Указатель источника — точное указание места в тексте, где
встречается та или иная эксцерпция. Более точно указатель можно представить в
виде: “Имя текста”, “Сквозной номер строки”, “Номер страницы”, “Номер строки на
странице”. Поскольку текст любого объема в виде компьютерного файла
представляет собой одну сплошную страницу, то для него естественным образом
определяется понятие сквозного номера строки — порядкового номера строки от
начала текста. Однако для реальных тестов такое представление часто
неприемлемо, поэтому текст может (и должен) содержать разметку страниц, которая
в общем случае может быть сделана произвольным образом. Атрибуты “номер
страницы” и “номер строки на странице” являются традиционными компонентами
указателя.
Словоформа — выбранноя из текста (или корпуса текстов)
слово в некоторой своей грамматической форме. Для словоформы определяются
только частотный параметр и ее связь с вокабулой.
Словосочетание. Аналогично словоформе существует
необходимость хранить частотную информацию о всех представленных в тексте (или
корпусе текстов) словосочетаниях. Здесь под словосочетанием понимается
неразрывная связка двух словоформ, между которыми нет синтаксических признаков
конца предложения.
Отношение
“определяющее-определяемое” — вспомогательная
характеристика, которая позволяет связывать вокабулы в общем случае
родовидовыми отношениями (или отношениями, сводимыми к родовидовым10 ). Такая возможность появляется только после формирования семантических
полей.
Морфема. Название сущности подчеркивает лишь уровень
системных языковых единиц, который она представляет. В данном случае речь идет
о квазиокончаниях.
Кластер отношений
“определяющее-определяемое”.
Отношения “определяющее-определяемое” позволяют строить граф дефиниций. Более
подробную информацию можно найти в литературе [Шемакин, 1995]. Для построения
так называемого кластера отношений используется метод, аналогичный тому,
который используется для построения семантического ареала, что позволяет
формировать всю возможную иерархию вокабул на основе их дефиниций.
Корреляционная матрица. Сущность, которая определяет статистические
данные для корреляционного анализа.
Семантическая сеть. Сущность, определяющая отношения между
вокабулами на основе статистического корреляционного отношения, вычисляемого по
корреляционной матрице для каждой пары вокабул.
Семантический ареал. Совокупность устойчивых и достоверных отношений
между вокабулами, задаваемая определенными пороговыми значениями.
В ЛБД также следует выделить
сущности, которые являются комбинациями вышеописанных. Основываясь на
приведенном выше списке, выделим все атрибуты ЛБД и сведем их в таблицу:
|
Атрибут |
Шифр |
Обозначение |
|
Номер вокабулы |
RecordID |
A1 |
|
Вокабула |
KeywordID |
A2 |
|
Число толкований вокабулы |
ExplainCount |
A3 |
|
Число эксцерпций вокабулы |
ExampleCount |
A4 |
|
Число словоформ вокабулы |
FormCount |
A5 |
|
Номер толкования |
RecordID |
A6 |
|
Текст толкования |
Explain |
A7 |
|
Номер эксцерпции |
RecordID |
A8 |
|
Текст эксцерпции |
Example |
A9 |
|
Номер текста |
RecordID |
A10 |
|
Имя текста |
TextName |
A11 |
|
Путь к тексту |
TextPath |
A12 |
|
Отметка о выделении текста |
TextCheck |
A13 |
|
Номер указателя |
RecordID |
A14 |
|
Имя текста |
TextName |
A15 |
|
Сквозной номер строки |
LineNo |
A16 |
|
Номер страницы |
PageNo |
A17 |
|
Номер строки на странице |
PageLineNo |
A18 |
|
Частота словоформы |
Frequency |
A19 |
|
Частота парного словосочетания |
Frequency |
A20 |
|
Номер словоформы |
RecordID |
A21 |
|
Словоформа |
Wordform |
A22 |
|
Номер отношения “определяющее-определяемое” |
RecordID |
A23 |
|
Параметр отношения “определяющее-определяемое” |
TreeType |
A24 |
|
“Сила” связи отношения “определяющее-определяемое” |
Strenth |
A25 |
|
Номер слова в кластере “определяющее-определяемое” |
RecordID |
A26 |
|
Минимальное расстояние в кластере “...” |
MinLen |
A27 |
|
Число контекстов для вокабулы 1 |
M_COUNT |
A28 |
|
Число контекстов для вокабулы 2 |
S_COUNT |
A29 |
|
Kорреляционная матрица для вокабул 1 и 2 |
Value |
A30 |
|
Kорреляционное отношение для вокабул 1 и 2 |
Rxy |
A31 |
|
Число значений в корр. матрице |
ValCount |
A32 |
|
Kоэффициент корреляции |
KV |
A33 |
|
Номер морфемы |
RecordID |
A34 |
|
Kод морфемы |
MorfCode |
A35 |
|
Значение морфемы |
MorfData |
A36 |
|
Номер вокабулы в семантическом ареале |
RecordID |
A37 |
|
Минимальное расстояние в семантическом ареале |
MinLen |
A38 |
Под картой понятия понимается
совокупность необходимых характеристик слова ЕЯ описания ПО для его
представления в семантическом словаре-тезаурусе. В карту понятия входит: Вокабула,
Семантическое поле, Частотная информация, Экземплярно-иллюстративное поле,
Указатели источника, Семантический ареал понятия.
Карты понятий могут в свою очередь
быть объединены в семантическую сеть, где связи будут определяться либо
корреляционным отношением между вокабулами, либо связями отношения
“определяющее-определяемое”. И в том и в другом случае будет иметь место
иерархическая семантическая сеть.
Условно, графически, карту понятия
можно изобразить в виде (рис. 9):
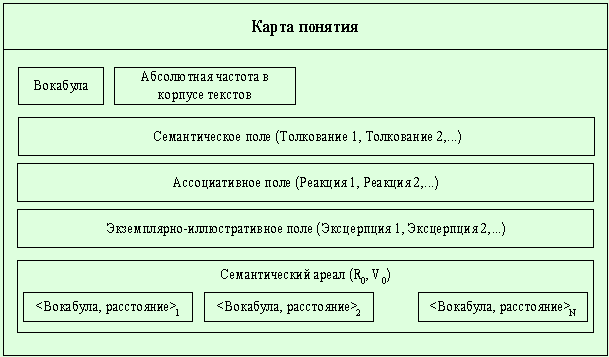
Рис. 9. Структура
карты понятия
Необходимо отметить несколько
особенностей заполнения выделенных полей;
Вокабулы будут отбираться с помощью комбинации
ручного и формального метода и должны представлять лексемы, характерные для
исследуемой предметной области.
Абсолютная частота в корпусе текстов — совокупная частотная
характеристика лексемы, вычисленная по всему объему генеральной совокупности
(корпуса текстов).
Семантическое поле формируется человеком-экспертом на основе
информации, представленной в семантическом ареале или на основе простейшего
синтаксического анализа текста.
Ассоциативное поле — не заполняется. Предполагается, что
ассоциативное поле будет заполнено в будущем после проведения и анализа
результатов ассоциативного эксперимента.
Экземплярно-иллюстративное поле автоматически заполняется предложениями из
корпуса текстов, где есть употребление соответствующей лексемы.
Семантический ареал строится на основе дистрибутивно-статистического
метода и метода выделения компонент графа, где критерием связанности служит
корреляционное отношение между частотами вокабул. Вокабулы семантического
ареала расположены в порядке возрастания длины минимального маршрута в
семантической сети от данной вокабулы.
3.3. Технология построения
иерархической семантической сети и карт понятий
Технологию построения иерархической
семантической сети и карт понятий можно условно разделить на три основных
этапа:
·
Этап
формирования ядра естественно-языкового описания предметной области.
·
Этап построения
генерального словника по сформированному корпусу текстов.
·
Этап построения
семантической сети и семантических ареалов.
Каждый этап состоит из ряда шагов.
Рассмотрим детально каждый из них последовательно для каждого этапа.
Этап 1. Этап формирования ядра
ЕЯ описания ПО
Шаг 1. Первый шаг этого этапа начинается с
подготовки текстовых материалов для проведения анализа. На этом шаге
выполняется ручной ввод или автоматизированный ввод текстов в компьютер и формирования
отдельных файлов. Это наиболее трудоемкая (по времени) работа и далеко не
наименее важная. Вне зависимости от того, какой способ ввода используется,
обязательно необходима процедура коррекции. Задачей этой процедуры является
устранение грамматических и синтаксических ошибок, исправление неверно
распознанных символов (при сканировании и распознавании) в особенности тех,
которые имеют одинаковые начертания для русского и латинского алфавитов.
Подготовка текстов может вестись в любом доступном текстовом процессоре
(например, MS Word 6.0/7.0/98, Lexicon, WordPad и т.п.), но с обязательным
окончательным сохранением их в формате ANSI-1251 (при подготовке текстов в
среде Windows) или OEM-866 (при подготовке текстов в среде MS DOS).
Шаг 2. Будем считать, что на шаге 1 были
сформированы N текстов ЕЯ описания ПО. На этом шаге строятся частотные словники
по всем N текстам. При этом необходимо разделить иностранную11 лексику и русскоязычную лексику.
Шаг 3. Будем считать, что на шаге 1 были
сформированы N текстов ЕЯ описания ПО. Если все сформированные тексты в равной
степени представляют предметную область (или нет возможности выделить эталонный
текст), то целесообразно применить полносвязную схему формирования ядра ЕЯ
описания ПО. Для этого необходимо построить N частотных словников и выполнить
проверку гипотезы по однородности всех пар текстов при пятипроцентом уровне
доверия. Учитывая полносвязную схему, необходимо проверить N(N-1)/2 гипотезы.
Текст исключается из корпуса текстов, если хотя бы одна гипотеза об
однородности не подтверждается.
Шаг 4. Построение частотных словников для парных
словосочетаний для каждого из N отобранных текстов ЕЯ описания ПО.
Шаг 5. Получение параметрического профиля. Расчет
основных статистических характеристик текста, а также определение параметров
модели “ранг-частота”. Полученные по заведомо однородной генеральной
совокупности, эти характеристики могут выступать как определители конкретной
предметной области, представленной определенной совокупностью текстов. Эти
параметры могут быть включены в словарь, как дополнительная информация, а также
могут быть использованы в целях формирования значений хеш-функций при
организации поиска данной совокупности.
Шаг 6. Если отобранные тексты являются отображением
некоторой предметной области в динамике, то можно провести комплекс
исследований динамических характеристик корпуса текстов. В частности,
исследование динамики структуры текста, исследование динамики структуры
словника, исследование динамики содержания словника и исследования динамики
наполнения словника.
Шаг 7. Распечатка частотных словников по
словоформам и словосочетаниям по русскоязычной и иноязычной лексике.
Этап 2. Этап построения
генерального словника ЕЯ описания ПО
Шаг 1. Выделение лексем ЕЯ описания ПО из частотных
словников. Формируемый список лексем должен определенным образом отражать
содержание исследуемой предметной области. Поэтому можно предложить следующую
формальную процедуру извлечения. В список лексем отбираются слова и
словосочетания, относительная частота употребления которых в корпусе текстов
больше, чем в текстах с общеупотребительной лексикой. Математически это правило
можно выразить так: A — предметная лексика, B — общеупотребительная лексика, С
— неклассифицированная лексика, D = A U B — словник ЕЯ описания ПО. Тогда A = D
\ (B U C). Другими словами, чтобы выделить предметную лексику из словника,
нужно вычесть из него словник, в котором предметная лексика не содержится. К
сожалению, четкой границы между предметной и непредметной лексикой не существует,
поэтому дополнительно учитывается еще и относительная частота встречаемости
слова (или словосочетания) в предметном и непредметном словнике. Эта операция
эквивалента разности словников: S(T*) = S(T1) — S(T2),
где T1 — текст с предметной и непредметной
лексикой, T2 — текст с непредметной лексикой. Выбор
текста, не содержащего данную предметную лексику, сделать не так уж сложно.
Кроме того, для подтверждения неоднородности найденного “непредметного” текста
и исследуемого корпуса текстов можно проверить гипотезу об однородности (см.
этап 1). В любом случае, после формального отбора лексем необходима ручная
коррекция и их приведение к каноническому виду.
Шаг 2. Привязка словоформ ЕЯ описания ПО к
выделенным лексемам. Привязка осуществляется на основе метода квазиокончаний.
После привязки необходима ручная коррекция: устранение ошибок первого рода
(связывание лексемы со словоформой, которая на самом деле не является
словоизменением первой).
Шаг 3. Автоматическое формирование семантических
полей для отобранных лексем на основе простейшего синтаксического анализа
текстов. На этом шаге для некоторых лексем формируются отдельные дефиниции,
имеющие место в корпусе текстов.
Шаг 4. Формирование экземплярно-иллюстративного
поля на основе извлечения эксцерпций из ЕЯ описания ПО (корпуса текстов) для
каждой выбранной лексемы.
Шаг 5. Построение указателя источника для всех
отобранных эксцерпций. В указатель, как уже отмечалось, помещается имя текста,
сквозной номер строки, номер страницы и номер строки на странице. Указатель
строится для каждой эксцерпции.
Шаг 6. Вычисление основных числовых характеристик
лексем: число эксцерпций, число словоформ, абсолютная и относительная частота.
Вычисление математического ожидания и среднеквадратического отклонения для
относительных частот каждой лексемы.
Шаг 7. Распечатка генерального словника и его
основных числовых характеристик.
Этап 3. Этап построения
семантической сети и карт понятий
Шаг 1. Применение дистрибутивно-статистического
метода для получения статистической информации о связанности лексем
генерального словника.
Шаг 2. Построение простой семантической сети на
основе применения корреляционного отношения как меры семантической связи между
словами (лексемами).
Шаг 3. Получение формальных характеристик
семантической сети методами теории графов. В частности, интерес представляет
число несвязанных компонент.
Шаг 4. Построения семантических ареалов для
заданных пороговых значений (R0, V0): (0.7,8), (0.5,8) и
(0.3,8). Исследование характера изменения формы семантических ареалов.
Нахождение оптимальных пороговых значений.
Шаг 5. Построение семантических ареалов для лексем,
имеющих наименьшее среднеквадратическое отклонение относительной частоты. Такие
лексемы будем называть понятиями ЕЯ описания ПО.
Шаг 6. Формирование карт понятий и построение
иерархической семантической сети, в которой мерой связи между картами понятий
выступает корреляционное отношение.
Графически технологический процесс
построения карт понятий и иерархической семантической сети можно представить в
таком виде (рис. 10):
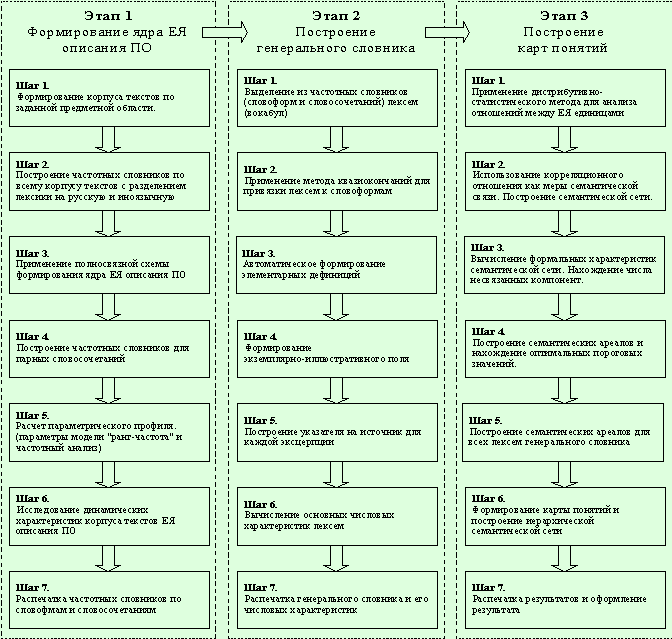
Рис. 10. Технология
построения карт понятий
9 Вокабула – заглавное слово (или
словосочетание), термин ЕЯ описания ПО [Мельчук, 1997].
10 В принципе нет значительной
разницы в отношениях “элемент-система”, “часть-целое”, “один-ко-многим” и т.п.
Все они могут быть определены в рамках родо-видовых отношений.
11 Под иностранной лексикой
понимаются слова, набранные символами нерусского алфавита.