3. ИНФОРМАЦИОННО-ПОИСКОВАЯ
СИСТЕМА
“УКАЗАТЕЛЬ ИСТОЧНИКОВ”
Функциональным прототипом ИПС “Указатель источников” является информационная система на основе базы данных, реализованная в среде СУБД Paradox 5.0.
Основное отличие ИПС “Указатель источников” от ее прототипа заключается в независимости новой системы от конкретной СУБД. Программа также имеет более удобный (эргономичный) интерфейс с большими функциональными возможностями. В ИПС разработан язык запросов, который позволяет выполнить большинство необходимых операций для поиска и создания выборок.
Существует достаточно много программ, аналогичных Указателю источников. Среди них можно выделить, прежде всего, классы электронных словарей и энциклопедий, например: “Энциклопедия Кирилла и Мефодия”, “Словарь Брокгауза и Ефрона”, “Иллюстрированный энциклопедический словарь”. Эти программные продукты являются мультимедийными и имеют оригинальный интерфейс. В отличие от них ИПС “Указатель источников” обладает большей функциональностью, т.е. позволяет работать с ним долгое время, изменять размеры рабочих областей и при этом имеет стандартный интерфейс, используемый в среде Windows 9x.
Мультимедийные издания не используют для хранения информации базы данных, так как это упрощает взлом информации и затрудняет воссоздание качественного отображения текста. По этой причине программы обладают меньшим быстродействием и не позволяют создавать произвольные запросы. Для стандартных выборок и поисковых операций используются специально созданные индексы, которые значительно увеличивают необходимое дисковое пространство.
База данных ИПС “Указатель
источников”
Описание полей БД. База данных ИПС получена из соответствующей базы информационной системы Указателя источников (см. табл. 1) путем ее преобразования. Она состоит из одной таблицы, содержащей 15 основных полей (Шифр источника, Полное описание, Синоним, Название источника, Автор, Исследователь-издатель, Дата источника, Уточненная дата, Язык оригинала, Издание рукописи, Датировка состава, Переиздание, Место хранения) и 3 служебных (SortIndex, IssledInex, NazvIstIndex). База данных имеет формат Paradox 5.0., но содержит в некоторых полях (Formatted Memo) данные, которые не поддерживаются СУБД Paradox. Ниже приведены краткие описания основных полей базы данных.
Шифр источника — поле содержит сокращенное обозначение древнего источника, используемое в Словаре русского языка XI_XVII вв.
Полное описание — поле содержит библиографическое описание источника и некоторую дополнительную информацию о нем. Другие поля базы данных получены путем расписывания полного описания.
Синоним — поле содержит ссылку на основное сокращение, используемое в Словаре русского языка XI-XVII вв. Общее количество шифров, имеющих синонимы, равно 1042. Значение этого поля можно просмотреть только с помощью запроса.
Название источника — поле содержит полное название источника. В случае составных источников, таких, как Великие Минеи Четьи, указывается часть источника (часть, список, страница и т.д.).
Автор — поле содержит информацию об авторе или группе авторов источника. Имена и отчества авторов обычно приведены в сокращенном виде. Часто используются псевдонимы, титулы, должности и т.д.
Исследователь-издатель — поле содержит информацию об исследователе источника или об издателе источника, который его восстанавливал, комментировал, исследовал, переиздавал и т.д.
Дата источника — поле содержит точную дату создания источника или предполагаемый период создания. Информация представляется в вербальном виде с помощью римских и арабских цифр. Около трети записей не имеют указания на дату создания.
Уточненная дата — поле содержит уточненную дату создания источника. При появлении новых данных об источнике, авторе или описываемых событиях информация о дате источника корректируется.
Язык оригинала — поле содержит информацию о языке, который использовался при создании источника. Некоторые источники написаны на нескольких языках. В этих случаях в поле указываются два языка. Если язык оригинала русский, то поле не содержит никакой информации. Обычно используются сокращенные обозначения языков. Это необходимо учитывать при поиске или формировании запросов.
Издание рукописи — поле содержит информацию об издании источника. В поле может указываться библиографическое описание издания, обозначение сборника или другая информация. Датировка состава — поле содержит информацию о датировке состава источника. Обычно указывается время создания частей источников.
Переиздание — поле содержит дополнительную информацию о дальнейших переизданиях источника.
Место хранения — поле содержит информацию о месте хранения источника. При этом используются общепринятые сокращения для библиотек, музеев и т.д.
Поля Полное описание, Название источника и Исследователь -издатель могут содержать информацию на различных языках.
Необходимость создания служебных полей описывается во второй части данной главы. В описании эти поля часто называются индексными.
SortIndex — поле содержит ключи поля Шифр источника, которые получены с помощью программы Andrew Sort. По этому полю была осуществлена сортировка. Оно не является ключевым, так как может содержать одинаковые значения.
IssledIndex — поле содержит копию поля Исследователь-издатель без шрифтового форматирования (выделения). Оно необходимо для выполнения поиска и сортировки, а также для отображения значений в табличном виде.
NazvIstIndex — поле содержит копию поля Название источника без шрифтового форматирования (выделения). Оно необходимо для выполнения поиска и сортировки, а также для отображения значений в табличном виде.
Анализ значений полей позволил выявить необходимые типы полей и их размерность. Перед заполнением базы данных длины полей были завышены, но впоследствии были оптимизированы и уменьшены. Даталогическая модель БД приведена в табл. 6.
Таблица 6
Даталогическая модель БД Указателя
источников
|
№ |
Название |
Тип данных |
Размерность |
|
1 |
Шифр источника |
Текстовое |
64 |
|
2 |
Полное описание |
DBRichEdit |
— |
|
3 |
Синоним |
Текстовое |
128 |
|
4 |
Название источника |
DBRichEdit |
— |
|
5 |
Автор |
Текстовое |
64 |
|
6 |
Исследователь-издатель |
DBRichEdit |
— |
|
7 |
Дата источника |
Текстовое |
32 |
|
8 |
Уточненная дата |
Текстовое |
32 |
|
9 |
Язык оригинала |
Текстовое |
16 |
|
10 |
Издание рукописи |
Текстовое |
240 |
|
11 |
Датировка состава |
Текстовое |
240 |
|
12 |
Переиздание |
Текстовое |
240 |
|
13 |
Место хранения |
Текстовое |
128 |
|
14 |
SortIndex |
Текстовое |
64 |
|
15 |
IssledInex |
Текстовое |
255 |
|
16 |
NazvIstIndex |
Текстовое |
255 |
Создание БД ИПС. В гл. 1 была описана технология создания базы данных информационной системы Указателя источников на основе многошрифтового форматированного текста. Подчеркнем еще один раз, что практически единственной СУБД, которая поддерживает текстовый тип данных со шрифтовой разметкой, является Paradox4. Она не имеет возможности импорта таких текстов, но позволяет работать с буфером обмена. Последовательно было заполнено поле Полное описание, после чего оно было расписано по всем остальным полям. Для этого была разработана специальная форма в среде СУБД, которая ускорила процесс работы.
Поле, способное хранить многошрифтовую информацию, является MEMO-полем (Formatted MEMO) и его нельзя сделать ключевым, а также осуществлять по нему поиск или запросы. Поля Название источника и Исследователь-издатель могут содержать текст, представленный различными шрифтами, которые не смешиваются в пределах одной записи. В СУБД Paradox и Access можно установить произвольный шрифт только для всей таблицы целиком, т.е. нельзя задать разные шрифты каждому полю или набору записей.
Ввод данных, заполнение базы данных, вычитывание, дополнение и корректировка выполнялись в течение нескольких лет. За это время СУБД Paradox версии 5.0 в значительной степени устарела, т.е. с ее помощью нельзя создать современную и независимую информационную систему5. Кроме того, прекратился выпуск ее русских версий. Фирма Borland выпустила серию систем программи рования, которые позволяют быстро и эффективно создавать приложения баз данных в среде Windows. Кроме того, Delphi и C++Builder имеют внутреннюю поддержку таблиц Paradox и мощные средства для работы с ними на основе механизма BDE6.
Первые версии этих продуктов не позволяли хранить тексты с разметкой в базе данных. Эта возможность появилась только в третьей версии, но в другом формате, отличном от FMEMO СУБД Paradox. Возникла необходимость написать программы на PalObject и на C++Builder, которые помогли осуществить преобразование из одного формата в другой. Для работы с форматированными текстами в Delphi (VCL) существует класс TRichEdit и его “родствен ник” TDBRichEdit. Принципиально новых возможностей не появилось: все так же нельзя вставлять тексты из файлов (только через буфер) и выполнять запросы.
После преобразования базы данных для работы в
новой среде встал вопрос сортировки Указателя источников. Необходимо было
упорядочить все записи по полю Шифр источника.
Поля Название источника и Исследователь-издатель имеют формат FMEMO, но каждая запись содержит менее 255 символов7. Фактически нужно не MEMO-поле, а текстовое с разметкой. Так как каждая запись этих полей содержит только один шрифт, то для хранения в базе данных можно воспользоваться следующей простой моделью: поместить в одно поле информацию о языке (шрифте), а в другое — сам текст без форматирования. В этом варианте можно выделить следующие недостатки:
1. Размер таблицы возрастает . Для двух полей это примерно 5_10 %, но для базы данных Указателя источников это не существен но. Можно сократить эту цифру, используя вместо названия шрифта некий числовой кодификатор. Например:
Andrew Greek — 1;
Arial Cyr — 2;
Arial CE — 3.
Для применения такой структуры необходимо разработать новые механизмы работы с данными.
2. Разработка механизма отображения информации . В некоторых случаях способ хранения информации в FMEMO более рационален, так как каждая запись пишется последовательно в BLOB-поле, заполняя все свободное пространство. При использовании простого текстового поля в таблицу записывается одинаковое количество символов, соответствующее размеру поля, независимо от содержимого.
3. Ограниченность использования . Этот вариант хорош для хранения отдельной информации о шрифте, но для полного описания нужны еще поля размера, начертания, цвета и др. Более того, при появлении полиязычности в одной записи такое хранение может оказаться совсем неэффективным.
Среди достоинств модели следует выделить следующие возможности:
1. Поиск и сортировка . Появление дополнительных полей позволяет не только осуществить поиск вообще, но и значительно его ускорить. Например, при поиске в таблице с 10000 записей, содержащих информацию на 10 языках (шрифтах), средняя скорость увеличивается в 5 раз.
2. Экспорт и хранение в других форматах . Такой способ хранения позволяет использовать любые СУБД, а также осуществлять экспорт.
При реализации Указателя источников не возникло необходимости экспорта в формат другой системы управления базами данных. Количество записей, содержащих русский язык, значительно превосходит все остальные вместе взятые.
Поэтому для решения использовалось еще более простое решение. В базе данных было создано два служебных поля, в которые было занесено содержимое полей Название источника и Исследователь-издатель без разметки. В операциях поиска или запросов используются новые поля, а в интерфейсе отображаются исходные поля с разметкой.
На рис.3 показан механизм корреляции FMEMO и простых текстовых полей. Пунктирная стрелка указывает на возможную неоднозначность. Такая схема появилась не случайно и не в угоду простоте системы. Был проведен ряд экспериментов и анализ используемых языков, в результате которых выяснилось следующее:
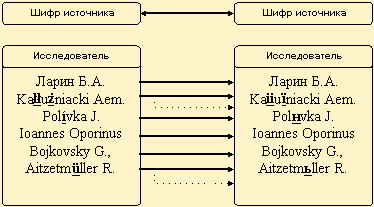
Рис.3. Корреляция полиязычных полей
1. В базе данных используется 5 языков и 3 шрифта для их отображения. Каждый шрифт содержит в себе две раскладки, одна из которых всегда является латинской.
2. Для набора латинского текста можно использовать два из трех шрифтов (Arial Cyr или Arial CE). Очевидно, что русские буквы шрифта не пересекаются с латинскими, так как располагаются на другой раскладке8.
3. Греческие буквы шрифта Andrew Greek располагаются на латинской клавиатуре. Многие из них совпадают по расположению с буквами латыни (примерно на 70%), но корни слов и их конструкции отличаются. Помимо букв греческий язык содержит около 15 надстрочных знаков, которые располагаются на служебных символах шрифта. На практике греческие названия используют из-за невозможности передачи их латинскими или русскими варианта ми. Можно сделать выводы, что вероятность совпадения греческих и латинских слов (шрифтовая корреляция) очень мала.
4. Сложнее обстоит дело с польским языком. Его алфавит почти полностью совпадает с латинским (по расположению на раскладке клавиатуре), но в польском языке часто используются надстрочные знаки. Для их набора используется родная (не латинская) раскладка. Из этого следует, что польский язык не пересекается с русским по раскладке, а с латинским и немецким — по корреляции слов, так как польский язык принадлежит славянской группе.
5. Остается немецкий язык, который является историческим потомком латыни. В нем присутствуют дополнительно буква b и три умляута. Некоторые особенности в написании и многовековая история развития языка формируют существенные отличия от латинских слов.
6. Все предыдущие рассуждения основаны на том, что поиск осуществляется по слову целиком. Если выполнять запросы с использованием шаблонов, то вероятность совпадения уменьшается с количеством используемых символов.
7. Для набора немецкого, польского и латыни использую тся один шрифт и одна (латинская) раскладка. Отличить один язык от другого можно либо по уникальным буквам, либо по словарной принадлежно сти. Большинство пользователей не знают, как отображаются символы на экране монитора и что при этом происходит в компьютере. Поэтому для них играет роль лишь графический вид буквы или знака.
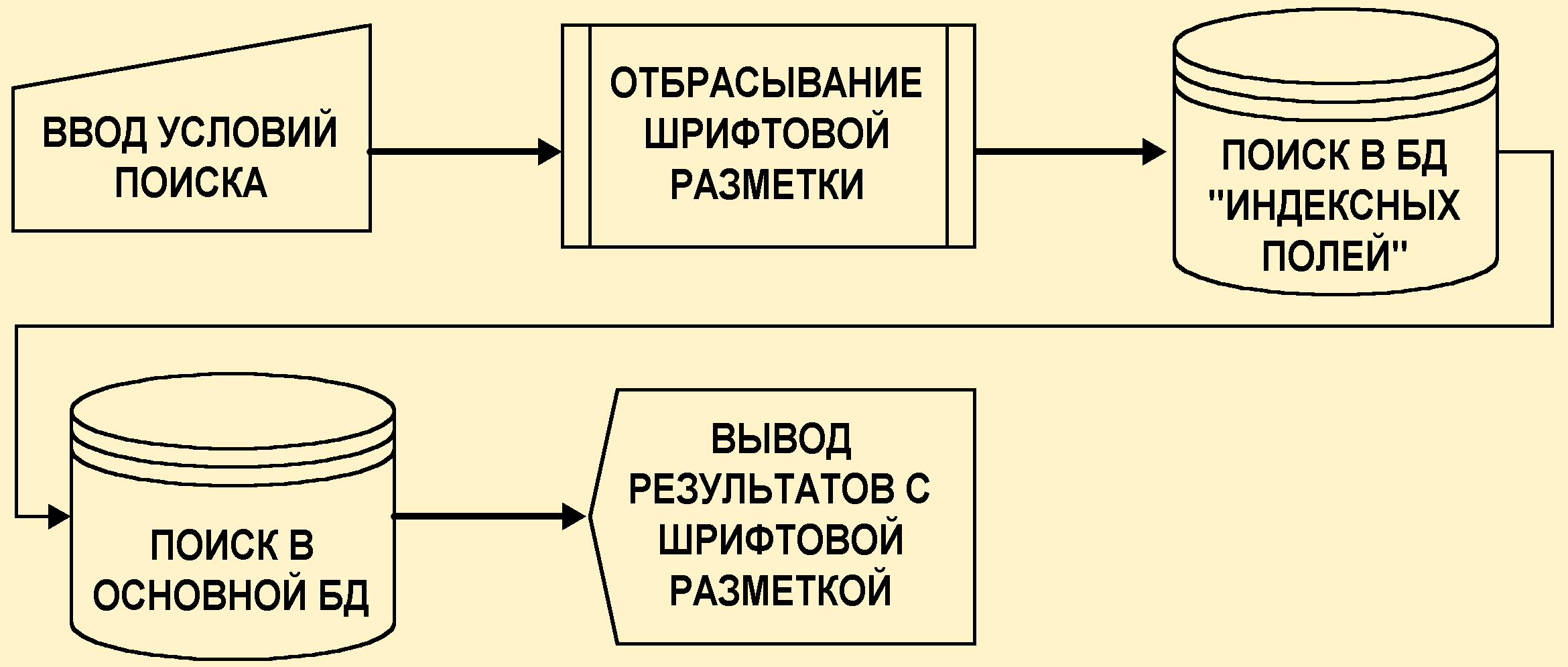
Рис.4. Механизм поиска в Указателе источников
Предложенная модель является отнюдь не совершенной. Если бы база данных Указателя источников содержала большое количество записей на других языках, то система имела бы существенный недостаток. Структурно механизм поиска представлен на рис.4. Тем не менее, данная модель хорошо показала себя на экспериментах. В общем случае вероятность совпадения не превышает 10% порога.
Математическая модель обработки
информации
Определения. Для того чтобы формализовать процессы обработки текстовой информации , необходимо выделить объекты, над которыми производятся преобразования. Введем следующие понятия:
1. Символ C — совокупность графических линий, характеризу ющих букву L, цифру N или служебный знак P.
C = L | N | P
2. Алфавит ALF — множество всех букв, цифр и служебных знаков, используемых в конкретном тексте, языке и других знаковых образованиях.
ALF = {L, N, P} = {C}
Обычно алфавит имеет порядок следования, называемый также порядком сортировки. В этом случае можно говорить об упорядоченном множестве символов.
ALF = <L, N, P>
3. Слово W — сочетание символов, отделяемое на письме и имеющее семантику. Будем подразумевать под словом набор букв, надстрочных, подстрочных, выносных знаков, влияющих на семантику слова.
W = {C1, … Cn}, где n — длина слова.
Ci = {L} — для современного языка без использования жаргонов и сокращений символы слова могут быть только буквами. В общем случае это недействительно. Например, древнегреческий, старославянский языки могут содержать служебные знаки. Современные жаргонные слова могут содержать также цифры.
4. Словосочетание (конкорданс) K — упорядоченная совокупность нескольких слов внутри предложения.
K = <W1, …, Wn>
5. Текст Т — совокупность символов, объединенных общей семантикой, визуальным расположением, правилами пунктуации и др.
При вводе данных в ЭВМ происходит преобразование текстовой информации. Это связано с тем, что в компьютере имеются другие понятия.
6. Компьютерный символ Ch — это пара, состоящая из графического образа (символа) С и кодовой комбинации M. Кодовая комбинация представляет собой число.
Ch = (C, M)
7. В вычислительной технике часто используются понятия шрифта и шрифтовой разметки. Будем под шрифтом F понимать совокупность гарнитуры G, стиля S, размера Z и цвета R.
F = (G, S, Z, R)
В настоящее время существуют и другие параметры шрифта, но в данной работе они не учитываются. Будем также использовать комбинированное понятие компьютерного символа в сочетании со шрифтовыми характеристиками.
Ch = (C, M, G, S, Z, R)
Ввод текстовой информации есть преобразование F1 одного текста в другой. Для этого характеристики каждого символа Ch изменяются, добавляется шрифтовая разметка.
![]()
Формально этот процесс можно описать матричным преобразованием.
![]()
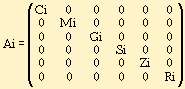
где
Ci = C2i/C1i; Mi = M2i/M1i; Gi = G2i/G1i;
Si = S2i/S1i; Zi = Z2i/Z1i;
Ri = R2i/R1i;
Можно каждой комбинации (всему пространству векторов Ch) сопоставить целое число. Размерность этого представления следующая:
256 символов * 256 шрифтов (CharSet) * 256 размеров шрифта * 256 стилей * 256 цветов = 240.
Если ограничить число используемых шрифтов, стилей и цветов, то можно уменьшить это число до 220.
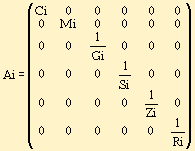
Чтобы получить числовой аналог, необходимо умножить матрицу символа на следующую матрицу Ai1.
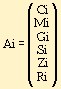
Некоторые преобразования удобно делать над группами символов. Можно разделить преобразования AFi, связанные со шрифтовой разметкой, и преобразования AMi, связанные с изменением кода символа.
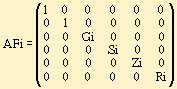
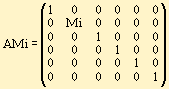
Если символ Ch не имеет шрифтовой разметки, то значения принимаем равными 1. Таким образом, символ в тексте.
С Ю Ch = (C,1,1,1,1,1)
Исправление ошибок. Особый интерес представляет матрица ошибок Ei, связанная с неправильным вводом текста.
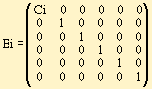
В общем случае ошибки могут быть связаны со всеми элементами символа Ch.
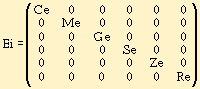
Чтобы удалить ошибки, необходимо найти обратную матрицу преобразования Ei-1. За выполнение этой операции отвечает преобразование F4.
Расписывание текста в базу данных. Расписывание текста T1 в базу данных DB1 есть преобразование F2. При этом происходит фрагментация текста, его структурирование. Эта операция зависит от представления исходных и выходных данных, а именно от количества элементов N, на которые надо сегментировать информацию.
Если представить текст T1 как некую абстрактную функцию в N-мерном пространстве элементов, тогда можно продифференци ровать по направлениям. При этом фрагменты текста (участки функции), которые нельзя четко фрагментировать, должны относиться к немонотонным участкам.
Такое представление является очень абстрактным, поэтому для выполнения этих операций воспользуемся теорией формальных языков. Необходимо сформировать грамматику и автоматы разбора (структурирования) текста:
Mп = (K, E, Gr, d, q0, Z0, F),
где Мп — магазинный автомат (разбора); K — непустое множество неструктурированных состояний; E — непустое конечное множество входных символов; Gr — непустое конечное множество магазинных символов; d — функция, называемая функцией перехода; q0 — начальное состояние; Z0 — начальный символ магазина; F — непустое множество заключительных состояний.
Для структурирования текста можно построить несколько автоматов разбора: автомат разбора записей Mпз и автомат(ы) разбора статьи (отдельной записи) Mпс.
Вторая группа нуждается в грамматике, которая делает синтаксический разбор, разбор по форматированию, логический разбор (по порядку) и семантический разбор. Построение таких автоматов очень сложно, так как оперирует с естественно-языковыми грамматиками, которые не поддаются формальному описанию.
Автомат разбора записей Мпз построить несложно. Он был реализован при переводе БД Указателя источников из формата СУБД Paradox в формат, используемый C++Builder. При этом символом, свидетельствующим о конце разбора записи, служил знак возврата каретки.
Сортировка базы данных. Сортировка базы данных есть ее преобразование F5 в новую базу данных. Под новой БД нужно понимать упорядоченную старую (исходную) БД. Для этого необходимо ввести понятие порядка:
Z1 > Z2 > . . . > Zn
Для сортировки необходимо задать алфавит сортировки ALF и механизм (алгоритм) перестановки элементов сравнения. Существует большое множество методов сортировки. Каждый алгоритм показывает различное быстродействие в зависимости от типа информации, с которой он работает. Если каждой записи поставить в соответствие уникальный ключ Ke, то операцию сортировки формально можно определить следующим образом:
сортировка есть перестановка
P = p(1)p(2) … p(n)
такая, что
Kp(1)< Kp(2)< … Kp(n),
где p(i) — соответствующая запись; Kp(i) — уникальный ключ; N — количество записей.
Создание запросов. Рассмотрим процесс создания запросов и их реализацию в терминах реляционной алгебры. База данных Указателя источников имеет 16 полей, каждому из которых соответствует свой идентификатор (см. табл. 8).
ИПС позволяет делать выборки из БД по отдельным полям.
R1= p1 — выборка 1-го поля (Шифр источников) из БД.
Ri = pi — выборка i-го поля из БД.
Особенностью запросной системы БД является включение индексных полей (16 и 15) для полей 4 и 6.
Если Ri = p4 => Ri= p4,16
Если Ri = p6 => Ri= p6,15
Запросно-поисковая система позволяет также делать выборки по нескольким полям. Запишем общий вид такого запроса:
Ri= p1,...n — выбор нескольких полей. При этом максимальное значение n может изменяться следующим образом:
n = 11 , если поля 4 и 6 не включены в запрос;
n = 13 , если поля 4 или 6 включены в запрос;
n = 15 , если поля 4 и 6 включены в запрос.
ИПС позволяет также делать выборки с заданием условий.
R2= s1=T1 — задание условий для поля Шифр источников.
Rj= sj=Tj — задание условий для j-го поля.
Важно отметить, что условие Тj является простым и не может быть составным. Кроме того, для поля 2 (Полное описание) условия задаваться не могут, так как оно имеет формат DBRichEdit.
Для полей 4 и 6 условия запросов перенаправляются для полей 16 и 15 соответственно.
Если Rj= s4=T1 => Rj= s16=T1 & s4=0
Если Rj= s6=T1 => Rj= s15=T1
В запросной системе Указателя источников имеется также возможность объединения U результатов запроса.
U = A + B,
где A, B — результирующие выборки (множества) записей.
Если выборки пересекаются по каким-то элементам, то лишние отбрасываются и в объединение не входят.
(A _ AЧB) + (B _ BЧA) = A + B _ 2ЧAЧB — объединение выборки без общих элементов.
(A + B _ 2ЧAЧB) + AЧB = A + B _ AЧB — объединение без повторения общих элементов.
Запишем теперь объединение в общем виде
![]()
Отбрасывание шрифтовой разметки. Для поиска в БД необходимо формировать запросы только для текстовых полей. Поля 4 и 6 таковыми не являются, поэтому нужно сделать преобразование. Для этого каждый символ Ch текста условия запроса умножим на следующую матрицу:
Работа с ИПС “Указатель
источников”
Запуск программы
Для запуска программы необходимо выбрать на рабочем столе Windows Пуск | Программа | Указатель источников | Указатель.
После запуска Указатель источников откроется в режиме Книга. Каждому режиму соответствует экранная форма. В программе имеется четыре основных режима (формы):
Режим Книга является компьютерным аналогом печатного издания, т.е. форма позволяет просматривать все шифры источников и их описание.
Режим База данных является экранной формой для отображения полей базы данных указателя источников.
Режим Просмотр результатов запроса позволяет просматривать результаты запроса (выборки) в табличном виде.
Режим Отчет предназначен для создания и печати отчетов, а также для подготовки текстовых документов и передачи их в другие текстовые редакторы.
Работа с режимом Книга
Данная форма состоит из главного меню, панели управления и двух полей (Шифр источника и Полное описание ). Размер поля Полное описание может изменяться вместе с размером окна программы. Размеры меню, панели управления и поля Шифр источника не изменяются, поэтому при уменьшении размера окна некоторые фрагменты интерфейса могут быть недоступны.
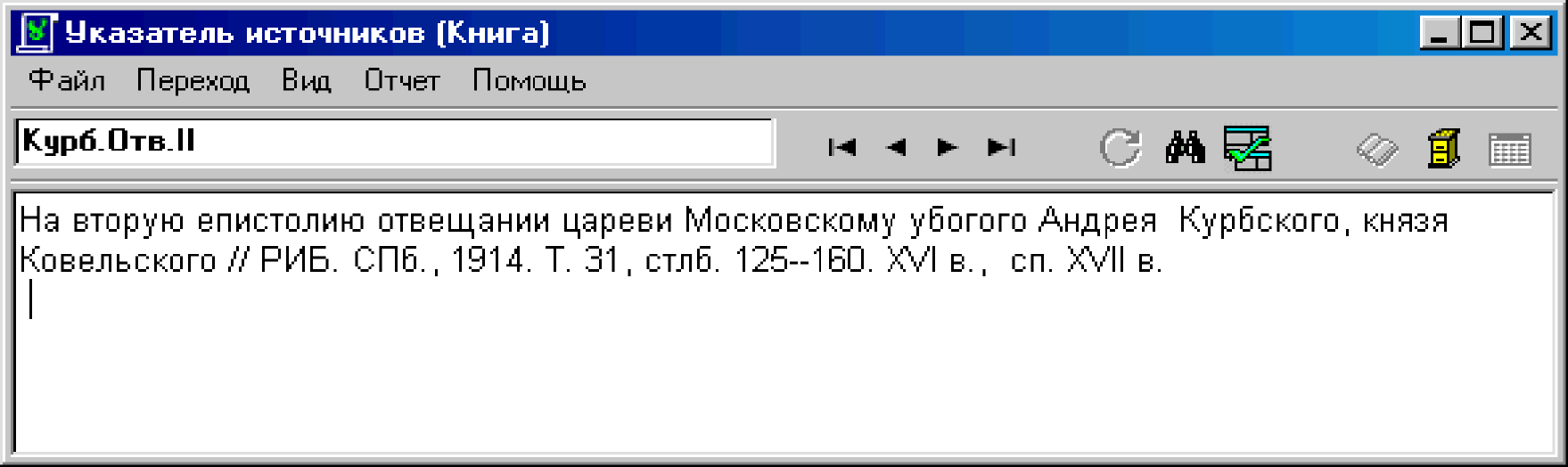
Для каждого шифра источника в базе данных имеется отдельная запись. В режиме Книга в каждый момент времени можно просматривать только одну запись, поэтому для отображения нужной записи необходимо переместить текущий указатель с помощью кнопок навигатора.
![]() — переход на первую запись,
— переход на первую запись,
![]() — переход на одну запись назад,
— переход на одну запись назад,
![]() — переход на одну запись вперед,
— переход на одну запись вперед,
![]() — переход на последнюю запись.
— переход на последнюю запись.
Чтобы ускорить поиск шифра источника, в программе имеется возможность просмотра всех шифров источников в виде списка. Количество элементов в списке определяется размером окна программы. Для их просмотра необходимо в режиме Книга установить курсор на поле Полное описание , нажать правую кнопку мыши и выбрать соответствующий пункт меню.
Для перемещения по списку можно использовать полосу прокрутки. После щелчка мыши на выбранном шифре источника происходит автоматический переход к соответствующей записи.
Для закрытия списка необходимо поместить указатель мыши в область списка, нажать правую кнопку мыши и выбрать пункт меню Закрыть.
На панели управления располагаются еще две группы кнопок, предназначенные для поисково-запросных операций и для переключения между различными режимами.
![]() — Кнопка Синоним позволяет осуществить автоматический
переход к основному шифру источника. Кнопка может принимать два состояния:
активное, если шифр-синоним существует, и пассивное, если отсутствует. Для
некоторых шифров существует несколько синонимов. В этих случаях переход
осуществляется к основному синониму9. Чтобы найти все шифры-синонимы, необходимо
воспользоваться запросной системой, введя в поле Синоним название
основного шифра источника.
— Кнопка Синоним позволяет осуществить автоматический
переход к основному шифру источника. Кнопка может принимать два состояния:
активное, если шифр-синоним существует, и пассивное, если отсутствует. Для
некоторых шифров существует несколько синонимов. В этих случаях переход
осуществляется к основному синониму9. Чтобы найти все шифры-синонимы, необходимо
воспользоваться запросной системой, введя в поле Синоним название
основного шифра источника.
![]() — Кнопка Поиск открывает диалоговое окно, которое
позволяет осуществить поиск необходимого источника. Поиск источника выполняется
в соответствии с введенными условиями.
— Кнопка Поиск открывает диалоговое окно, которое
позволяет осуществить поиск необходимого источника. Поиск источника выполняется
в соответствии с введенными условиями.
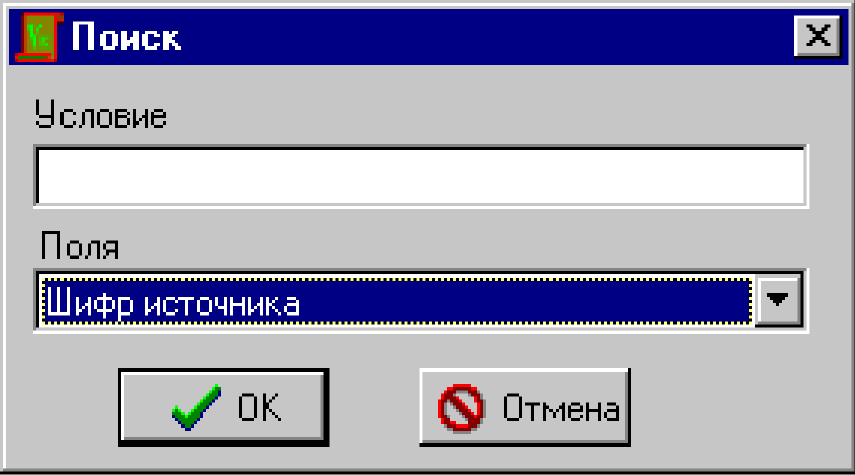
При задании условий поиска можно использовать шаблон “звездочка” (*), который означает любое количество символов10 (например, шаблон ВМЧ* позволяет отобразить все шифры, начинающиеся на буквы “ВМЧ”).
Система находит все значения, удовлетворяющее условиям поиска. Для их просмотра необходимо пользоваться кнопками навигатора. Чтобы отменить результаты поиска, нужно нажать кнопку Отмена поиска, которая появится вместо кнопки Поиск.
Внимание! В режиме просмотра результатов поиска переход к синониму может не работать, так как доступны лишь выбранные источники.
![]() — Кнопка Переход в режим запроса позволяет перейти в форму
создания запроса. Запросная система позволяет осуществлять более сложные
процедуры поиска и выборки данных11.
— Кнопка Переход в режим запроса позволяет перейти в форму
создания запроса. Запросная система позволяет осуществлять более сложные
процедуры поиска и выборки данных11.
![]() — Кнопка Переход в режим Базы данных позволяет перейти в
соответствующую форму. Форма режима Книги закрывается, но указатель на
текущую запись остается неизменным. Таким образом, можно переключаться между
двумя режимами и отсутствует необходимость снова осуществлять поиск
нужного шифра.
— Кнопка Переход в режим Базы данных позволяет перейти в
соответствующую форму. Форма режима Книги закрывается, но указатель на
текущую запись остается неизменным. Таким образом, можно переключаться между
двумя режимами и отсутствует необходимость снова осуществлять поиск
нужного шифра.
![]() — Кнопка Просмотр результатов запроса позволяет
просмотреть результаты последнего запроса. Кнопка становится активной только
после выполнения хотя бы одного запроса.
— Кнопка Просмотр результатов запроса позволяет
просмотреть результаты последнего запроса. Кнопка становится активной только
после выполнения хотя бы одного запроса.
Работа с режимом Базы данных
Экранная форма состоит из главного меню, панели управления и 12 полей (Шифр источника, Название источника, Автор, язык оригинала и др.). Размер окна в этом режиме не изменяется, поэтому некоторые поля имеют полосы прокрутки.
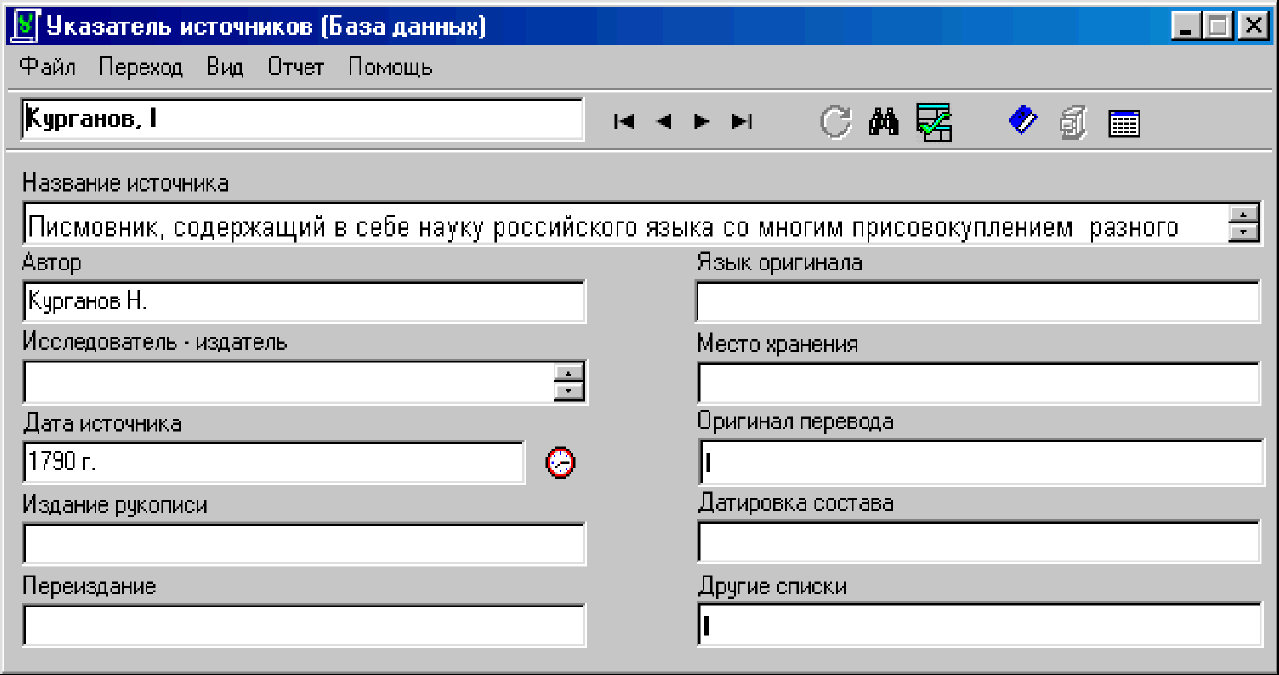
Большинство кнопок на панели инструментов выполняют те же функции, что и в режиме Книга.
![]() — Кнопка Переход в режим Книги позволяет перейти в
соответствующую форму. Форма режима Базы данных закрывается, но
указатель на текущую запись остается неизменным. Таким образом, можно переключаться
между двумя режимами и отсутствует необходимость снова осуществлять
поиск нужного шифра.
— Кнопка Переход в режим Книги позволяет перейти в
соответствующую форму. Форма режима Базы данных закрывается, но
указатель на текущую запись остается неизменным. Таким образом, можно переключаться
между двумя режимами и отсутствует необходимость снова осуществлять
поиск нужного шифра.
![]() — Кнопка Дата источника расположена на форме. Она
позволяет переключаться между полями Дата источника и Уточненная дата
источника , т.е. можно просматривать в каждый момент времени только
одно из этих полей.
— Кнопка Дата источника расположена на форме. Она
позволяет переключаться между полями Дата источника и Уточненная дата
источника , т.е. можно просматривать в каждый момент времени только
одно из этих полей.
Работа с запросной системой
Для создания запроса необходимо нажать кнопку перехода в режим запроса на панели управления в режиме Книги или Базы данных. На экране появится форма, состоящая из панели управления, списка полей БД и полей для ввода условий запроса.
![]() — Кнопка Выделить все позволяет включить все поля в
запрос, при этом она устанавливает галочки для всех полей.
— Кнопка Выделить все позволяет включить все поля в
запрос, при этом она устанавливает галочки для всех полей.
![]() — Кнопка Очистить все позволяет очистить список полей,
входящих в запрос, при этом она удаляет галочки для всех полей.
— Кнопка Очистить все позволяет очистить список полей,
входящих в запрос, при этом она удаляет галочки для всех полей.
![]() — Кнопка Выполнить запрос позволяет выполнить запрос. Если
хотя бы одно поле выбрано и нет ошибок при наборе условий, то после ее нажатия
выполняется запрос и его результаты отображаются в режиме Просмотра
результатов запроса.
— Кнопка Выполнить запрос позволяет выполнить запрос. Если
хотя бы одно поле выбрано и нет ошибок при наборе условий, то после ее нажатия
выполняется запрос и его результаты отображаются в режиме Просмотра
результатов запроса.
По умолчанию поле Шифр источника всегда отмечено галочкой. Если сделать его неактивным, то некоторые пункты меню в форме Просмотр результатов запроса станут недоступными. Если сделать активным поле Полное описание , то появится возможность добавления записей в отчет.
Справа от названий полей располагаются поля для ввода условий запроса. Запросная система позволяет сделать выборку (запрос), удовлетворяющую условиям, введенным в соответствующие поля. Одно из отличий от поисковой системы заключается в возможности задания критериев выбора для нескольких полей одновременно.
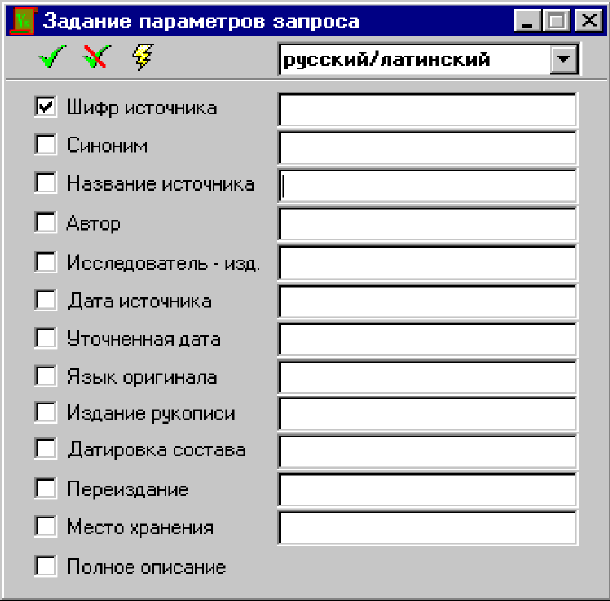
Внимание! Условия запроса учитываются только для тех полей, которые отмечены галочками. Остальные поля пропускаются и в формировании запроса не участвуют.
Ввод условий осуществляется путем набора на клавиатуре ключевого слова или фразы в соответствующем поле. Имеется возможность вставки текста из буфера. Это осуществляется с помощью стандартных комбинаций двух клавиш:
Shift + Ins или Ctrl + V — вставка из буфера обмена Windows.
Ctrl + Ins или Ctrl + C — копирование в буфер обмена Windows
Перед копированием необходимо выделить текстовой фрагмент подсветкой с помощью мыши или клавиатуры.
При выполнении запроса учитывается регистр букв, поэтому выборка по строчным и по прописным буквам осуществляется отдельно.
Текстовые шаблоны запросной системы
Запросная система поддерживает текстовые шаблоны SQL (Structured Query Language). Шаблоны предназначены для замены неизвестных символов или их комбинаций. В программе используется два типа шаблонов: одиночный символ и любое количество символов .
Одиночный символ используется для замены одного неизвестного символа и обозначается как нижнее подчеркивание (“_”). В результате запроса выбираются все существующие комбинации, удовлетворяющие условиям. Обычно шаблоны используются вместе с клю чевыми фрагментами слов или фраз. Шаблон может размещаться в любой части слова, а также перед ним и после него. Разрешается использование нескольких шаблонов.
Любое количество символов используется для замены нескольких неизвестных символов и обозначается как “%”. Этот шаблон удобен для поиска слова в больших фрагментах текста.
Примеры запросов
1. Поиск произведений автора
Необходимо ввести в поле Автор фамилию автора, шаблон “Любое количество символов” (“Курбский%”) и выполнить запрос.
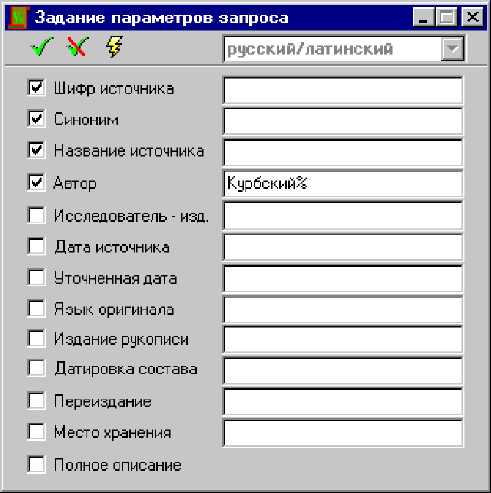
Запросная система выберет 6 источников: “История о великом князе Московском”, “История о осьмом соборе”, “Краткое отвещание князя Андрея Курбского на зело широкую епистолию великого князя Московского”, “На вторую епистолию отвещании цареви Московскому убогого Андрея Курбского, князя Ковельского”, “Письма князя Курбского к разным лицам”, “Эпистолиа первая князя А. Курбского к царю и великому князю Московскому”.
Иногда поле Автор содержит несколько авторов, поэтому лучше использовать более сложный запрос (“%Курбский%”). После выполнения этого запроса в результирующую выборку добавится еще одно произведение — “Переписка Ивана Грозного с Андреем Курбским”.
2. Выбор непустых значений полей
Для того чтобы выбрать все источники, для которых указан исследователь, необходимо задать комбинированный шаблон для поиска непустых значений (“_%”). После выполнения запроса на экране отобразится 1494 источника.
3. Выбор шифров источников фиксированной длины
Для того чтобы выбрать все шифры источников, имеющих определенную длину, необходимо ввести заданное число раз шаблон одиночный символ. Например, в Указателе содержится 7 двухсимвольных шифров (“__”), 18 трехсимвольных (“___”), 62 четырехсимвольных (“____”).
4. Выбор значений полей, состоящих из более чем одного слова
Выделение слова в запросе осуществляется путем набора знака пробел. Чтобы найти все названия из двух слов и более, нужно задать комбинированный шаблон “%<пробел>%”. Если нужно найти названия из трех слов и более, то шаблон будет следующий: “%<пробел>%<пробел>%”.
5. Выбор шифров источников без учета регистра
Запросная система Указателя не позволяет осуществлять выборки без учета регистра. Это вызвано, во-первых, спецификой кодовых таблиц используемых шрифтов, во-вторых, сложностью формирования таких запросов. Чтобы выбрать, например, все источники, имеющие в своем названии слово Акт, необходимо осуществить два запроса (“%Акт%” и “%акт%”). Но сумма количества шифров двух выборок не будет точной, так как есть названия, содержащие слово как со строчной, так и с прописной буквой “А”.
Объединение выборок можно осуществить с помощью опции “Добавить все” в режиме просмотра результатов запроса. При этом одинаковые шифры источников будут встречаться только один раз. Возможность просмотра результатов объединения имеется только в режиме Книга.
Многоязыковая поддержка
Для полей Название источника и Исследователь можно задавать различные языки (греческий, польский, русский, латынь). При реализации этой функции используются шрифты Andrew Greek, Arial CE, Arial Cyr.
Чтобы изменить язык, необходимо установить мигающий курсор в одно из двух полей. При этом список на панели управления становится активным. После этого нужно раскрыть список и выбрать соответствующий язык. Древнегреческие буквы набираются на латинской (английской) раскладке клавиатуры.
Режим Просмотра результатов запроса
Данный режим предназначен для просмотра результатов запросов. Можно также использовать его для просмотра в табличном виде всего Указателя источников. Для этого при создании запроса надо выбрать все поля и не задавать условия отбора.
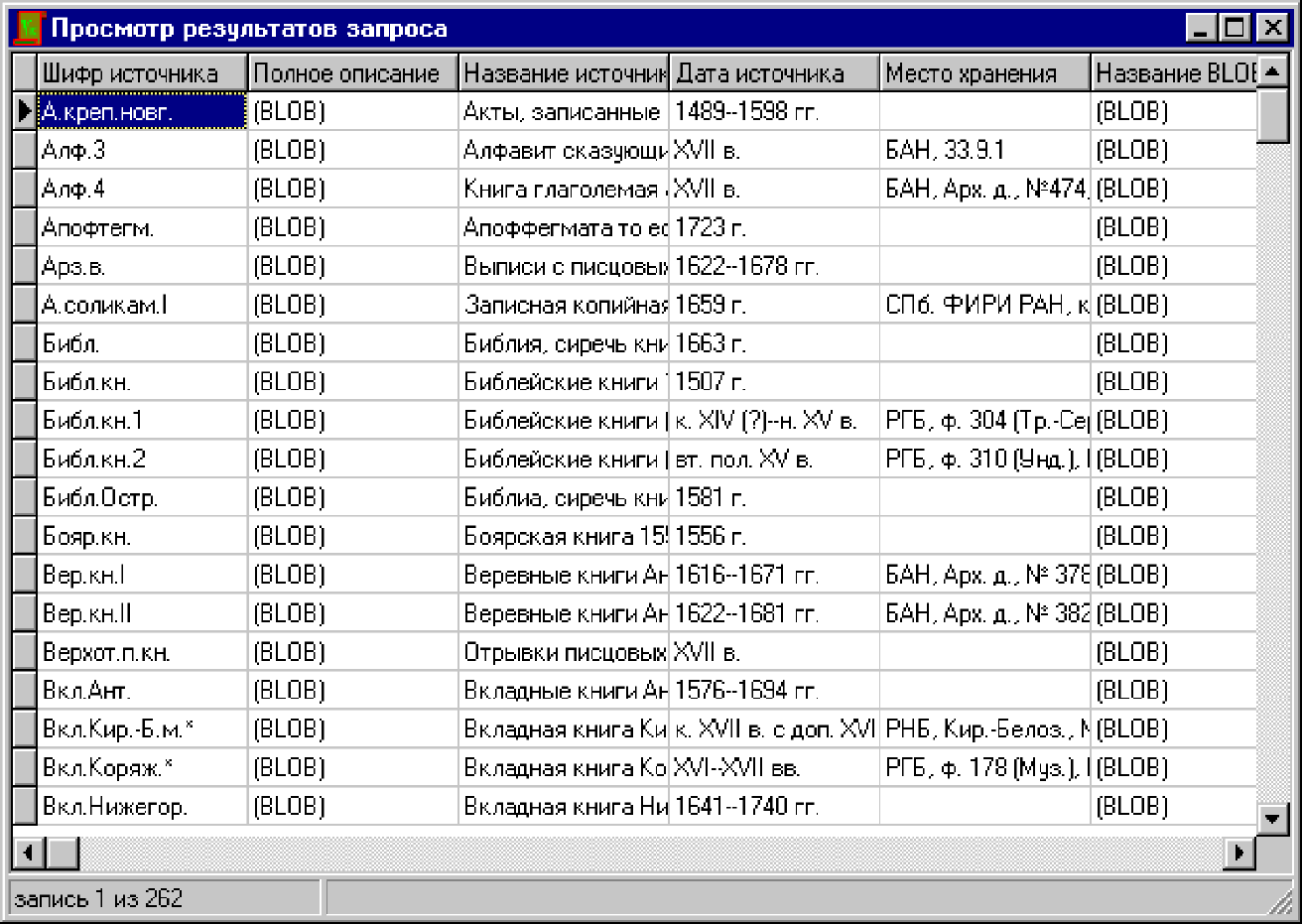
Экранная форма состоит из рабочей области, полос прокрутки и строки состояния. Рабочая область представляет собой таблицу, верхняя строка которой отображает имена выбранных в запросе полей. Первый столбец содержит указатель на текущую запись. Первая строка и первый столбец имеют оттенок, отличный от остальной области. В стандартной цветовой гамме Windows — серый цвет, а остальные ячейки имеют белый фон. При выборе ячейки она выделяется подсветкой.
Вертикальная полоса прокрутки позволяет перемещаться по записям Указателя источников, а горизонтальная — по полям. Размеры формы могут изменяться пользователем. Если количество записей или полей небольшое, то полосы прокрутки могут не отображаться.
В нижней части окна находится строка состояния. Она содержит информацию о количестве записей в выборке и о текущем расположении указателя на запись.
Перемещаться по таблице можно пользуясь управляющими клавишами на клавиатуре, клавишей TAB или мышью. В форме имеет ся возможность изменения расположения и ширины полей (столбцов).
Чтобы изменить ширину столбца, необходимо переместить мышь на границу-разделитель названия полей (на серую область), нажать левую клавишу мыши (при этом появится тонкая вертикальная черта) и, удерживая кнопку, переместить курсор вправо или влево.
Для изменения расположения столбца необходимо переместить мышь на название поля (на серую область), нажать левую клавишу мыши (при этом появится толстая вертикальная черта) и, удерживая кнопку, переместить линию левее или правее другого поля.
Форма Просмотра результатов запроса имеет контекстное меню, которое открывается нажатием правой кнопки мыши. Меню состоит из двух частей и содержит 7 пунктов:
· просмотр;
· добавить в отчет;
· переход в режим Книга;
· переход в режим База данных;
· добавить в список шифров;
· добавить все в список шифров;
· очистить список шифров;
Все пункты меню, за исключением последних двух, выполняют ся только для выделенной записи или ячейки.
Пункт меню Просмотр позволяет просматривать содержимое ячейки в отдельном окне. Окно просмотра может быть открыто одновременно с экранной формой Просмотра результатов запроса. При перемещении по различным записям в таблице содержимое окна просмотра будет изменяться в соответствии с текущей записью. Окно просмотра может отображать только одно поле. Поэтому, чтобы просматривать другое поле, нужно установить на него курсор и выполнить соответствующий пункт контекстного меню.
Три поля (Полное описание, Название BLOB,
Исследователь BLOB) не могут отображаться в табличном виде, поэтому
содержат в каждой строке значение BLOB. Для просмотра содержимого этих полей
нужно воспользоваться пунктом меню Просмотр.
Поля Исследователь и Название источника имеют небольшое количество записей на различных языках (на греческом, немецком и др.). Поэтому в таблице отображается сразу два поля, содержимое которых отличается только наличием шрифтового форматирования.
Пункт меню Добавить в отчет предназначен для добавления информации об источниках в отчет. Пункт активен только тогда, когда в выборке имеется поле Полное описание . Более подробно см. Создание отчетов.
Пункт меню Переход в режим Книга предназначен для автоматического перехода в режим Книга. При этом осуществляются поиск и установка текущей записи, соответствующей шифру, выбранному в режиме Просмотра результатов запроса.
Пункт меню Переход в режим База данных предназначен для автоматического перехода в режим База данных. При этом осуществляются поиск и установка текущей записи, соответствующей шифру, выбранному в режиме Просмотра результатов запроса.
Пункт меню Список выбранных шифров предназначен для создания рабочей выборки источников, с которыми осуществляется работа пользователя. В него могут добавляться как результаты нескольких запросов, так и одиночные шифры. Список можно просматривать в режиме Книга, а редактировать в режиме Просмотра результатов запроса.
Пункт меню Добавить в список шифров предназначен для добавления шифра источника текущей записи в список выбранных шифров.
Пункт меню Добавить все в список шифров предназначен для добавления всех шифров источников, полученных в результате запроса.
Пункт меню Очистить список шифров предназначен для очистки списка выбранных шифров. Если список пустой, то пункт меню Выбранные шифры в режиме Книга неактивен.
Создание отчетов
Отчеты предназначены для создания списка литературы на основе Указателя источников. Во всех режимах просмотра имеется возможность добавления информации об источнике. В специальный файл копируется содержимое поля Полное описание . Для добавления информации об источнике необходимо переместиться на нужную запись, установить курсор на поле Шифр источника , нажать правую кнопку мыши и выбрать пункт меню Добавить в отчет. В режиме Просмотра результатов запроса пункт меню работает в любом месте, т.е. независимо от выбранного поля. Пункт активен только тогда, когда в список полей запроса включено поле Полное описание .
Работа с режимом Отчет
Чтобы просмотреть или изменить отчет, необходимо выбрать в режиме Книга или База данных в главном меню пункт Отчет | Просмотр. На экране появится экранная форма для просмотра отчетов.
Режим Отчет представляет собой встроенный текстовой редактор, имеющий стандартный интерфейс. Экранная форма содержит главное меню, панель управления с кнопками, рабочую область и шкалу форматирования.
Главное меню состоит из трех пунктов: Файл, Правка и Помощь. В подменю Файл содержатся пункты для создания, открытия, сохранения, закрытия и печати файлов. Редактор не может работать с несколькими файлами одновременно.
Чтобы передать файл в другой текстовой редактор, необходимо сохранить файл в формате RTF. Если сохранить файл в формате TXT, то шрифтовая разметка пропадет. Можно также скопировать содержимое файла в буфер и вставить его в другом текстовом редакторе.
Подменю Правка содержит пункты для работы с буфером обмена и меню задания параметров шрифта. Пункт Отмена позволяет отменять операции. Отменить можно только одну операцию, восстановить которую снова нельзя.
Подменю Помощь содержит пункты для работы со справочной системой Указателя источников.
Панель управления содержит кнопки, дублирующие некоторые функции главного меню. Они позволяют открывать, сохранять и печатать файл; работать с буфером обмена и отменять операции, изменять гарнитуру, размер и начертание шрифта; изменять форматирование абзацев и установку элементов списка.
В рабочей области можно вводить и редактировать текст. Размер области можно изменять вместе с размером окна.
Шкала форматирования позволяет изменять отступы абзацев и строк. Для этого необходимо перемещать стрелочки вдоль шкалы.
Работа со справочной системой
Для удобства пользователей в Указателе источников имеется справочная система. Она состоит из HELP-файла и всплывающих подсказок.
Всплывающие подсказки — это небольшие сообщения, которые появляются при установке курсора на элемент управления формы (поле, кнопку). Если сообщение исчезло, то необходимо переместить курсор мыши в сторону и снова навести на нужный объект.
HELP-файл представляет собой гипертекстовый документ. Самый простой способ открыть (вызвать) его — это нажать кнопку на клавиатуре F1. Справочная система откроется в отдельном окне и работает независимо от программы, поэтому можно выйти из Указателя источников и оставить справочное окно открытым.
HELP-файл состоит из нескольких фрагментов (страниц). Открытие той или иной страницы зависит от того, в каком режиме работает программа и где находится курсор мыши. Например, если пользователь открыл режим База данных и вызвал HELP, то справочная система откроется на соответствующей странице.
В режимах Книга, База данных есть пункт меню Помощь, который содержит два подменю: Содержание и О программе .
Если выбрать пункт меню О программе , то появится форма с заставкой программы и информацией о версии программного продукта, а также о создателях системы.
Пункт меню Содержание открывает справочную систему на первой странице, на которой располагается содержание.
5 У фирмы Borland возникли финансовые трудности, и они вынуждены были продать Paradox фирме Corel. Paradox продолжал развиваться. В его восьмой версии существует возможность подключения DLL Delphi, а также создавать независимые от СУБД приложения.
6 BDE — Borland Database Engine. Раньше он назывался ODAPI, потом IDAPI, а после продажи Paradox получил свое новое имя. Сейчас существует уже пять версий этого продукта.
7 MEMO-поле предназначено для хранения больших объемов текстовой информации.
8 При работе с шрифтами все программы используют не графическое начертание символов, а их коды (ASCII, ANSI, Unicode). Каждая раскладка соответствует определенному диапазону кодов.
9 Основным синонимом считается шифр источника, который используется в словаре.
10 Данный шаблон позволяет не вводить в условия поиска все возможные варианты начала, конца или даже середины слова. Программа автоматически выбирает все существующие варианты.