1. ОПИСАНИЕ ИНФОРМАЦИОННОЙ ТЕХНОЛОГИИ
Информационная технология, лежащая в основе создания компьютерной версии Указателя источников, имеет целью зафиксировать в электронной форме библиографические сведения об источниках Картотеки и Словаря. Однако перевод в электронную форму, т.е. на новые носители информации, ранее уже опубликованных и практически используемых библиографических описаний является только основной целью, но не единственной. Среди других, уже достигнутых и достигаемых, целей можно назвать:
· повышение качества самого Указателя путем устранения в нем формальных ошибок, авторских и технических неточностей;
· снижение затрат на его последующее обновление и уточнение;
· расширение круга пользователей Указателем за счет его применения в лексикографических технологиях и методиках создания других словарей, а также в смежных с исторической лексикографией научных областях;
· адаптация в новые полиграфические технологии издания словарей;
· использование в автоматизированной технологии создания завершающих томов Словаря русского языка XI_XVII вв.;
· исследование способов библиографического описания рукописных источников и древнерусских памятников письменности для дальнейшего формирования компьютерного источникового фонда и информационных систем на его базе.
Информационную технологию создания Указателя источников условно можно разделить на четыре этапа: файловой системы, базы данных, информационно-поисковой системы и оригинал-макета книги. Названия этапов указывают на тот основной результат, который получается по его завершению.
Этап создания файловой системы Указателя источников.
Этот этап завершается созданием на электронных носителях файлов данных, содержащих все библиографические сведения об источниках и их шифры. Фактически это этап ввода в ЭВМ книги “Указатель источников картотеки Словаря русского языка XI_XVII вв. в порядке алфавита сокращенных обозначений”, изданной в 1964 году, и ее последующих дополнений.
Ввод Указателя был осуществлен клавиатурным способом в 1994_1995 гг. В это время предполагалось осуществить переиздание Указателя источников в виде справочного (“нулевого”) тома Словаря русского языка XI_XVII вв. С этой целью была подготовлена двухколоночная черновая верстка с использованием настольной издательской системы Ventura Publisher v.2.0 (for DOS). Верстка была вычитана, а полученная корректура была внесена в файлы.
Файлы Указателя источников, подготовленные в настольной издательской системе Ventura Publisher v.2.0 (for DOS), содержат служебную информацию о шрифтовой разметке: <B> — начало выделения полужирным; <I> — начало выделения курсивом; <D> — конец шрифтового выделения и др. При дальнейшем использовании этих файлов для создания баз данных эту служебную информацию следовало удалить. С этой целью подготовленные файлы были обработаны в текстовом процессоре MS WORD v.6.0. Кроме удаления служебной информации было проведено форматирование текста Указателя источников, отвечающее требованиям последующего преобразования в файлы баз данных. Существо форматирования состояло в сведении в отдельные абзацы шифров источников и их полных описаний, а также разделени и их специальным символом — знаком табуляции. После выполнения этих операций текст Указателя источников был сохранен в виде текстового файла MS DOS.
Этап создания базы данных Указателя источников.
В результате работ на этом этапе была создана информационная система, функционирующая в среде системы управления базами данных (СУБД).
Разработка баз данных Указателя источников проводилась в рамках реализации проекта по переводу Картотеки на CD ROM. В качестве СУБД для реализации задач Проекта была выбрана разработка фирмы Borland Paradox v.5.0 (rus) из-за следующих основных преимуществ, выявленных в результате ее сравнения с другими аналогичными системами:
· поддержка различных графических форматов;
· поддержка форматируемых текстовых данных (MEMO-полей);
· наличие развитого объектно-ориентированного языка программирования (Object PAL).
Любая информационная система в среде Paradox состоит из следующих составных частей: таблиц, форм, отчетов и запросов . Эти части дают возможность пользователю различными способами взаимодействовать с базами данных.
Таблицы Paradox имеют стандартную форму независимо от их содержания и состоят из строк и столбцов. Столбцы — это поля базы данных или признаки, характеризующие информационный объект, в нашем случае — какой-нибудь источник. Строки — это отдельные записи базы данных, содержащие значения всех полей, т.е. значения всех признаков, характеризующих один информационный объект или какую-либо его часть, в нашем случае, — один конкретный источник.
База данных Указателя источников состоит из одной таблицы, содержащей сведения об источниках, которые использовались для выписки цитат на карточки и впоследствии для иллюстрации заголовочных слов в Словаре. В таблице базы данных шестнадцать полей (табл.1).
Таблица 1
Состав базы данных Указателя
источников
|
Наименование |
Тип |
Содержание |
|
Шифр источника |
A |
Сведения о кратком наименовании источника (шифре), цитата из которого приведена в словарной статье (это поле ключевое) |
|
Полное описание |
F |
Полное библиографическое описание изданного источника |
|
Синоним |
A |
Указывает на замену одного шифра источника другим, принятым в Словаре |
|
Название источника |
F |
Полное название источника |
|
Автор |
A |
Содержит имя средневекового автора |
|
Исследователь -изд. |
F |
Фамилия исследователя, издателя памятника |
|
Дата источника |
A |
Сведения о времени написания источника или о датировке списка |
|
Уточненная дата |
A |
Сведения о дате создания памятника или о наиболее раннем списке |
|
Язык оригинала |
A |
Сведения о языке, с которого сделан перевод памятника |
|
Оригинал перевода |
F |
Библиографические сведения об иноязычном оригинале переводного памятника |
|
Другие списки |
F |
Сведения о вариантах списков источника |
|
Издание рукописи |
A |
Библиографические сведения об издании рукописи |
|
Датировка состава |
A |
Сведения о датировках документов, входящих в состав сборников |
|
Переиздание |
A |
Библиографические сведения о других изданиях источника |
|
Место хранения |
A |
Сведения о месте хранения рукописного источника |
|
Примечания |
F |
Различные замечания и пометы, относящиеся к какому-либо полю таблицы или всей базе данных |
Обозначения типов
полей, используемые в таблице: A — текстовое; F — форматированное МЕМО.
В ЭВМ таблица базы данных Указателя источников представлена несколькими файлами, основным из которых является файл UKAZ.DB.
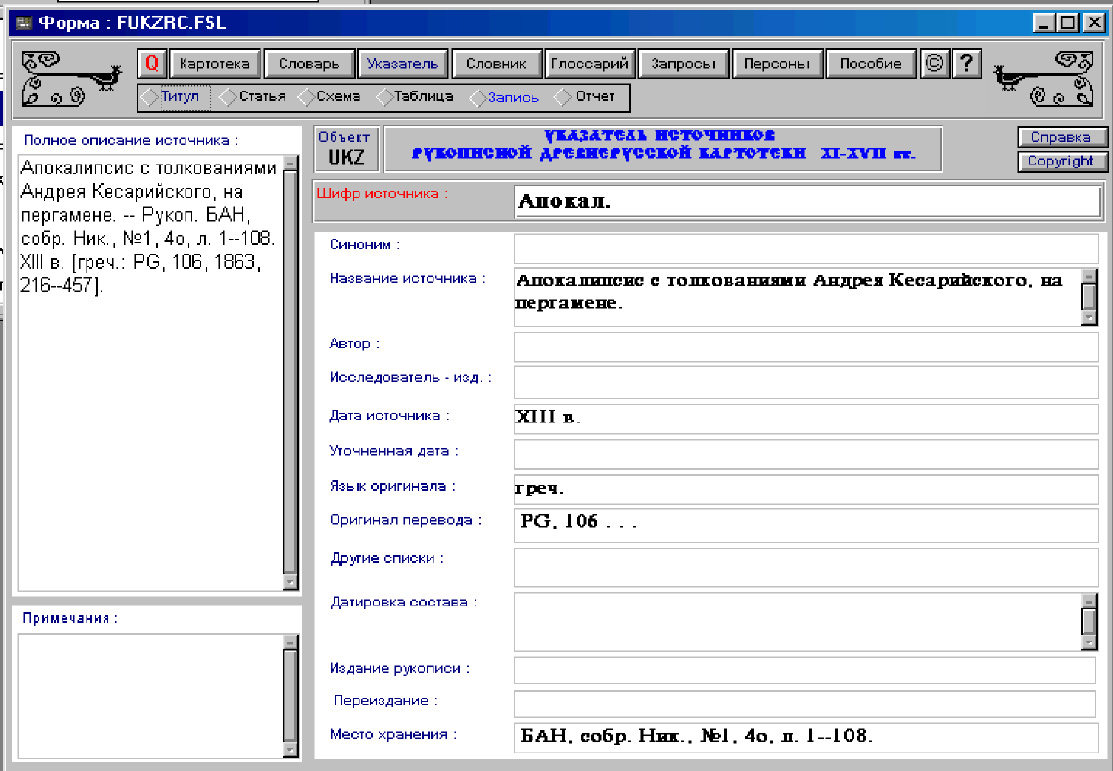
Рис. 1. Основное окно Информационной системы Указателя
источников
Формы Paradox, иначе — экранные формы, предназначены для удобного взаимодействия пользователя с базами данных, прежде всего, за счет более рационального расположения отдельных полей на экране дисплея. В экранной форме могут быть представлены не все поля базы данных, а только те, которые необходимы для конкретного этапа работы с таблицами, например ввода данных в базу или просмотра ее содержания (при этом соответственно различают формы ввода и просмотровые формы).
В информационной системе разработана одна экранная форма, которая использовалась для расписывания содержания поля Полное описание в другие поля; эта же форма является просмотровой. Форма представлена на рис. 1.
Отчеты Paradox, или печатные формы, предназначены для получения пользователем “твердых” (бумажных) копий базы данных. Они могут использоваться не только для последующего хранения некоторых результатов работы с базой данных или ее частей, но и в качестве промежуточной печатной формы, например черновой верстки или даже оригинал-макета малотиражного полиграфического издания.
В информационной системе Указателя источников использова лась одна отчетная форма, основное назначение которой — вычитка базы данных. Она представлена файлом UKAZ.RSL.
Запросы Paradox представляют собой, чаще всего, выборочные базы данных, построенные на основе одной или нескольких таблиц (исходных баз данных). В такой базе данных могут быть представле ны не все поля исходных таблиц, а лишь некоторые, да и содержание их может отвечать некоторым, заранее указанным условиям. Запросы создаются и выполняются с помощью специальных программных средств, называемых запросной системой. Основное назначение запросной системы состоит в поддержке пользователя при анализе в различных исследованиях содержания баз данных. Результаты запросов всегда представляются в табличной форме, но для них могут быть разработаны и экранные формы. В зависимости от целей, которые ставит перед собой пользователь информационной системы, он может работать как с таблицами, так и с формами.
Основными поисковыми запросами, осуществленными к базе данных Указателя источников, являются: запросы на выборку групп источников по отдельным полям, по определенным значениям некоторых полей (тематические запросы) и запросы на сортировку .
Запросы на выборку групп источников по отдельным полям используются для следующих целей: во-первых, для более эффективной вычитки текста Указателя источников; во-вторых, для анализа его содержания; в-третьих, для составления различных индексов. Запросы данного типа выполняются средствами запросной системы СУБД Paradox. Последовательность их реализации такая:
Шаг 1. Выбрать пункты Главного меню Paradox — Файл | Создать | Запрос. После этого на экране дисплея появится окно запроса.
Шаг 2. В окне запроса выбрать таблицу UKAZ.DB. После выбора на экране дисплея появится схема таблицы базы данных.
Шаг 3. В схеме таблицы UKAZ.DB пометить нужные поля.
Шаг 4. Выполнить запрос, нажав кнопку “Выполнение запроса” на главной панели.
Запрос на выборку авторов источников. Данный запрос позволяет составить список всех авторов источников, включенных в Указатель, и создать их индекс. Данный запрос сделан по одному и двум полям базы данных. Для составления списка всех авторов источников нужно пометить соответствующее поле — Автор. Для составления индекса источников по их авторам следует пометить еще одно поле — Шифр источника . При этом в поле Автор следует ввести значение Not blank, что позволит не включать в результирующую таблицу все шифры источников, для которых автор отсутствует или неизвестен.
При составлении индекса общее количество записей, т.е. число источников, имеющих авторов, в результирующей таблице оказалось 386, а самих авторов — 218.
Запрос на выборку всех мест хранения рукописных источников. Результаты данного запроса представлены в виде индекса. Общие количественные характеристики запроса представлены в табл.2.
Таблица 2
Характеристики запроса на выборку
мест хранения рукописных источников
|
Характеристика запроса |
Количество источников |
Доля в % от общего числа источников |
|
Общее количество обозначенных мест хранения источников |
30 |
— |
|
Kоличество источников в обозначенных местах хранения |
615 |
100 |
|
В том числе: РГБ СПб. ФИРИ РАН РГАДА ГИМ РНБ БАН Другие места хранения (областные б-ки, музеи, архивы, б-ки институтов и т.п.) |
175 95 82 77 68 47 71 |
28.4 15.5 13.5 12.5 11.0 7.5 11.5 |
Запрос на выборку всех исследователей-издателей источников. Результаты данного исследования использовались для построения соответствующего индекса. Основные характеристики этого запроса: общее количество исследователей издателей — около 640; количество источников, для которых указан исследователь-издатель , — 668.
Запрос на выборку сведений о языках оригиналов. Установление оригинала, с которого сделан тот или иной древнерусский перевод, является одной из самых трудных проблем в изучении древнерусских переводных произведений. В базе данных Указателя источников в поле Язык оригинала содержатся сведения о языке, с которого сделан перевод памятника. Запрос по этому полю позволяет получить индекс, который с указанием на язык оригиналов тех памятников Указателя источников, переводной характер и язык оригинала которых точно выявлены исследователями в ходе изучения того или иного переводного древнерусского памятника письменности. В ряде случаев индекс позволяет узнать об оригиналах источников, входящих в сложные по составу древнерусские сборники (Усп.сб., Выг.сб., ВМЧ и некоторые другие).
Запросы на выборку групп источников по значениям некоторых полей (жанрово-тематические запросы) могут быть также выполнены с целью более качественной вычитки текста Указателя источников, т.е. для поиска формальных ошибок и для их анализа. Далее будут приведены некоторые результаты анализа шифров источников. Эти результаты были получены при выполнении запросов на выборку источников, которые содержали в своем названии некоторые “ключевые” слова, характеризующие “тему” выборки. Результатом выполнения таких запросов является также и жанрово-тематический индекс. В качестве примера рассмотрим запрос на формирование тематической выборки “ДЕЛА”. Он был представлен ключевыми словами “дела” и “дело” с использованием скобок и операторов “..”, “OR”, означающих соответственно “любая группа любых символов”, “логическое условие ИЛИ”.
Множество составленных таким образом запросов позволяет формировать более сложные выборки. Примеры жанрово-тематических запросов приведены в табл.3.
Таблица 3
Примеры запросов
жанрово-тематического индекса
|
Тематическая группа |
Логическое выражение в поле “Полное описание источника” |
|
Акты |
..акт.. |
|
Архивы |
..архив.. |
|
Бумаги |
..бум.. |
|
Грамоты |
..грамот.. |
|
Дела |
(..дело..) OR (..дела..) |
|
Доклады |
..докл.. |
|
Летописи, летописные своды, ле тописцы |
..летопис.. |
|
Переписки, письма |
(..переписк..) OR (..письм..) |
|
Послания |
..послан.. |
|
Сказания |
..сказан.. |
|
Слова |
..слово.. |
|
Уложения |
..уложени.. |
|
Хождения |
хожден.. |
|
Хроники |
..хроник.. |
|
Челобитные |
..челобит.. |
Запросы на сортировку позволяют представить в ином порядке сведения как по нескольким полям, так и по какому-либо одному.
Запрос на сортировку источников по датам. При исследовании истории того или иного памятника письменности обычно по возможности устанавливаются дата его списка и дата возникновения самого источника или его наиболее раннего списка, поэтому полей с датами два. В поле “Дата источника” попадает дата списка памятника, определяемая на основании даты в самой рукописи (если рукопись датирована) или на основании палеографических данных (филиграней на бумаге, характера почерка и т.п.). В поле “Уточненная дата” представлена дата возникновения самого источника или его наиболее раннего списка. Работа с этими двумя полями в зап росной форме позволяет исследователю при необходимости выбрать источники какого-либо определенного периода.
Запрос на сортировку источников по датам предполагает выборку их шифров и последующую сортировку по значению поля Дата источника . Данный запрос может лежать в основе индекса по датам. Для его реализации первоначально необходимо создать производную базу данных источников, таблица которой содержала бы только два поля: Шифр источника и Дата источника, т.е. необходимо создать и выполнить запрос на выборку этих полей. Далее следует отсортировать полученную таблицу по полю Дата источника. После сортировки шифры источников в таблице будут расположены по возрастанию даты, причем сначала будут расположены источники, для которых дата задана арабскими цифрами (это, как правило, конкретный год или интервал годов), затем источники, для которых дата указана римскими цифрами (это конкретный век или интервал веков).
Завершать отсортированный список будут источники, дата которых содержит вербальные оценки: “ок.” — около, “к.” — конец, “н.” — начало, “сер.” — середина, “перв. пол.” — первая половина и др.
Информационная система Указателя источников в ЭВМ представлена файлами баз данных, форм, запросов и отчетов. Необходимой составной частью системы являются файлы самой СУБД Paradox или Runtime Paradox.
Основными файлами информационной системы Указателя источников являются файлы базы данных: UKAZ.DB, UKAZ.MB. Однако для удобного использования системы созданы вспомогательные базы данных и формы. Вспомогательные базы данных содержат сведения о разработчиках системы, справочную и методическую информацию. Эти сведения представляются пользователям посредством экранных форм, среди которых форма-заставка информационной системы, титульная форма, справочная форма и форма представления сведений о разработчиках. Перечисленные формы вызываются на экран дисплея при начале работы с системой и по его желанию. Для этого в формы введены специальные элементы управления — кнопки и переключатели. Полный перечень файлов информационной системы Указателя источников приведен в табл.4. Общий объем дисковой памяти, необходимый для размещения информационной системы (без СУБД Paradox или Runtime Paradox.), составляет ~10..20 Mb в зависимости от комплектации.
Таблица 4
Состав и назначение файлов
информационной системы Указателя источников
|
Имя файла |
Назначение (содержание) |
|
Файлы таблиц: |
|
|
UKAZ.DB, UKAZ.MB, UKAZ.FAM, UKAZ.VAL, UKAZ.PX, UKAZ.TV. |
Основная таблица базы данных Указателя источников, в которой хранятся все сведения о них |
|
COMMON.DB, COMMON.FAM, COMMON.MB, COMMON.PX, COMMON.TV, COMMON.VAL. |
Вспомогательная таблица, содержащая справочную информацию (help) по правилам и приемам работы с системой |
|
TITUL.DB, TITUL.DB, TITUL.DB, TITUL.DB, TITUL.FAM, TITUL.MB, TITUL.PX, TITUL.TV, TITUL.VAL. |
Вспомогательная таблица, содержащая титульные данные о разработчиках и назначении системы |
|
Q1.DB, ... - Q9.DB, ... |
Таблицы запросов |
|
Файлы форм: |
|
|
ZAST.FSL |
Форма-заставка информационной системы Указателя источников |
|
FUKZTI.FSL |
Титульная форма информационной системы Указателя источников |
|
FUKZRC.FSL |
Форма ввода и просмотра записей базы данных Указателя источников |
|
FUKZ.RSL |
Отчетная форма базы данных Указателя источников по двум полям (Шифр источника и Полное описание источника) |
|
FHLP.FSL |
Форма-справка по возможным действиям пользователей |
|
FUKZQ1.FSL - FUKZQ9.FSL |
Формы просмотра результирующих таблиц запросов |
Информационно-поисковая система Указателя источников.
Результатом работ на данном этапе является СУБД-независимый программный продукт, предназначенный для использования на ЭВМ типа IBM PC в операционной среде WINDOWS 95, 98 1.
Основным недостатком созданной на предыдущем этапе информационной системы является ее зависимость от СУБД. Передача баз данных, форм, запросов и отчетов другим пользователям возможна только лишь в случае наличия у последних собственной СУБД Paradox v.5.0 (rus), или Runtime Paradox. Это существенно снижает возможности по ее распространению. Кроме того, широкие возможности по обработке баз данных и реализации самых разнообразных поисковых запросов, которые СУБД Paradox предоставляет пользователям, полностью в большинстве случаев не используются. Эти два обстоятельства привели к постановке задачи по созданию запросно-поисковой системы, являющейся, во-первых, независимой от СУБД Paradox, во-вторых, более компактной и легко переносимой на другие ЭВМ.
В качестве инструментального средства для разработки информационно-поисковой системы Указателя источников использовался Borland C++ Builder, как одна из наиболее эффективных современных сред программирования.
Информационно-поисковая система Указателя источников состоит из программной и информационной частей. Информационная часть представлена файлами базы данных Указателя источников, полученными путем преобразования их из формата СУБД Paradox во внутренний формат системы. В программной части реализованы основные поисковые функции: просмотр записей базы данных, поиск точных значений по различным полям, фильтрация полей, формирование запросов на встроенном метаязыке, автоматический поиск синонимов и др.
Подробное описание информационно-поисковой системы Указателя источников приведено в гл. 3.
Подготовка книги Указателя источников.
Этап подготовки книги завершается созданием оригинал-макета полиграфического издания. Исходными данными для получения оригинал-макета полиграфической версии Указателя источников являются таблицы, полученные по результатам запросов к его базе данных. Основная таблица — это результат запроса на выборку двух полей: Шифр источника и Полное описание источника . Эта таблица лежит в основе оригинал-макета второй части настоящей книги. Другие таблицы — это результаты запросов, по которым строятся различные индексы. На их основе создан оригинал-макет третьей главы первой части.
Последовательность создания оригинал-макета второй части включает следующие процедуры: 1) сортировку шифров источников в заданном алфавитном порядке, 2) преобразование отсортирован ной таблицы в текстовый файл формата RTF, 3) формирование текстовых таблиц Указателя источников, 4) верстку полос издания.
Сортировка шифров источников. Данная процедура выполнена с использованием программы Andrew Sort, входящей в пакет прикладных программ ANDREW's TOOLS2. Программа Andrew Sort позволяет сортировать таблицы баз данных Paradox в соответствии с предварительно заданным алфавитом. При этом может быть установлен произвольный лексикографический порядок, в том числе некоторые символы могут быть удалены. При сортировке шифров Указателя источников не учитывались такие символы: точка, запятая, тире, скобки, пробелы и др.
Преобразование отсортированной таблицы в текстовой файл формата RTF. Данное преобразование выполнено в связи с тем, что подготовка оригинал-макета книги выполнялась с использованием текстового процессора MS Word v.7.0. В СУБД Paradox отсутствуют средства конвертирования форматированных MEMO полей баз данных в текстовый формат, обеспечивающий сохранение шрифтовой разметки и использование различных фонтов. Вместе с тем, именно эти особенности характеризуют поле Полное описание источника . В этом поле используются символы различных шрифтовых таблиц (Times New Roman Cyr, Times New Roman Ce, KDRS old Cyr, Andrew Greek, Izhitmut) и начертаний (Bold, Italic, Bold Italic). В качестве формата, сохраняющего перечисленные особенности форматируемых MEMO полей, был выбран Rich Text Format (RTF). Данный формат описан в литературе и поддерживается MS Word. Выполнение преобразования было осуществлено программой Andrew Convert, функционирующей в среде Borland C++ Builder, исходными данными для которой являются поля таблицы Paradox, а результатом — текстовый файл с разделителями формата RTF.
Формирование текстовых таблиц Указателя источников и верстка полос. Эти процедуры выполнялись в текстовом процессоре MS Word с использованием известных операций, первыми из которых были замена символов разделителей полей на символ табуляции и преобразование текста в таблицу.