Анализ знаний в ERP-системах
Принципы построения ERP-систем
ERP представляет собой не класс систем управления, а методологию организации бизнес-процессов предприятия. В связи, с чем для российских условий внедрение подобной технологии подразумевает коренные изменения вcей деятельности компании. Важной особенностью проектирования систем управления предприятием на принципах ERP является направленность на планирование ресурсов производства. Вот почему большинство функций учета, реализованных в этих системах, служат лишь дополнением к основной задаче — составлению планов поставок материалов, производства и пр.
ERP (Enterprise Resource Planning) означает планирование ресурсов предприятия. Исторически назначение автоматизированных систем, построенных по этому принципу, претерпевало изменения. В 60—70-х годах ХХ в. был разработан стандарт управления предприятием, получивший название MRP (Material Requirements Planning) — планирование потребностей в материалах для производства. Дальнейшая его эволюция и привела к появлению стандарта ERP. Системы MRP создавались для производственных предприятий и очень редко использовались при планировании материальных потребностей организаций, оказывающих различные услуги.
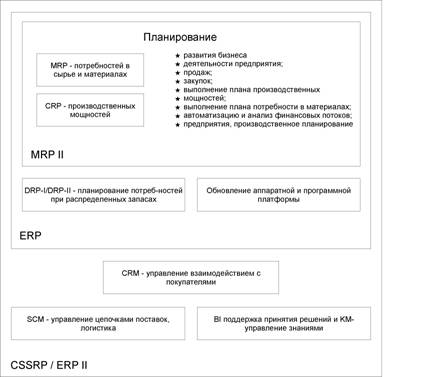
Довольно часто составляющей MRP-систем являлась система планирования производственных мощностей CRP (Capacity Requirements Planning). Данный стандарт разрабатывался только как средство оптимизации и учета движения материалов на производстве. При последующем развитии системы был сформирован стандарт MRPII (Manufacturing Resource Planning) — планирование ресурсов предприятия [2]. Эволюция функционального развития стандартов представлена на схеме. (Рис.1)
На смену MRPII пришел новый стандарт – собственно ERP. Однако он ориентирован уже на работу с сетью удаленных производственных и непроизводственных объектов. Обладая всеми перечисленными в MRPII возможностями, ERP-системы включают еще и механизм планирования потребностей при распределенных запасах (DRP-I/DRP-II — Distribution Requirements Planning), позволяющий определить потребность в пополнении запасов в случае территориально распределенных автономных складов. И, кроме того, эти системы допускают обновление аппаратной и программной платформы (в отличие от MRP/MRPII).
Рис. 1. Схема функционального развития стандарта ERP
Последним словом в развитии систем управления предприятием является стандарт CSRP (Customer Synchronized Resource Planning) — планирование ресурсов во взаимодействии с покупателем. Иногда в литературе этот стандарт называют ERPII. Его отличает направленность на потребителя: если раньше построение системы было связано с необходимостью оптимизации внутренних процессов компании, то теперь эта проблема решена, и на первый план выходит структуризация процессов взаимосвязей с внешними субъектами. Подобные системы имеют такие функциональные блоки, как CRM (Customer Relationship Management) — управление взаимодействием с покупателями; SCM (Supply Chain Management) — управление цепочками поставок, логистика; BI (Business Intelligence) — поддержка принятия решений и KM (Knowledge Management) — управление знаниями.
Необходимость анализа и управления знаниями в ERP-системах
Появление новых модулей BI и КМ было обусловлено тем, что успешно даже функционирующие системы ERP не обеспечивают пользователей систем необходимыми инструментами для работы с огромным объемом хранящихся оперативных данных. Управляющему персоналу компаний постоянно требуется получение аналитической информации, необходимой для принятия стратегических рыночных решений. Сведения в ERP-системах носят внутренний характер и касаются лишь данной компании. В целях отбора, обобщения и систематизации данных компании стали востребованными возможности систем сбора, управления и анализа бизнес-информации (Business Intelligence, BI) [5]
Исторически системы KM создавались для накопления корпоративных знаний и использовались для внутреннего потребления. С развитием CRM-систем оказалось, что KM-системы идеально подходят для создания автоматизированных справочных бюро (Help Desks) и решения задач интеллектуального анализа информации по клиентам [4] (выявление потребительских пристрастий, профилирование и тд.)
Интегрированные аналитические данные обеспечивают предприятия необходимыми типами отчетностей и инструментальными средствами для принятия решений, устраняя ограничения, накладываемые EPR-системой [7]. Например, финансовая информация представлена во многих ERP-продуктах в транзакционной форме, а пользователям нужен быстрый доступ к ней и возможность анализа на различных уровнях детализации. Кроме того, в традиционных ERP-системах применяются реляционные базы, которые структурированы для эффективной обработки входных данных, имеющих одномерное представление. В принципе, допустимо и многомерное представление, но оно требует высокой технической квалификации, а производительность в оперативном режиме часто оказывается невысокой. Те же данные в многомерном представлении доступны в аналитических приложениях, которые ориентированы как раз на создание многомерных отчетов. Хранилища данных служат этой цели самостоятельно и независимо от ERP-решений.
Таким образом, сложились все предпосылки для наращивания ERP-систем инструментами Business Intelligence и поиска методов и алгоритмов для удовлетворения требований и запросов по извлечению и организации знаний в ERP-системах.
Средства Business Intelligence
К категории средств Business Intelligence относят средства представления данных в более удобном для восприятия виде (графики, сводные таблицы, отчеты), позволяющем принимать обоснованные решения (например, о дальнейших направлениях развития бизнеса компании)[6].
Классификация современных средств Business Intelligence позволяет выделить: генераторы отчетов, средства аналитической обработки данных -клиентские и серверные OLAP- средства, средства поиска закономерностей (Data Mining), средства разработки BI-приложений (BI Platforms) и так называемые Enterprise BI Suites — средства анализа и обработки данных масштаба предприятия, которые позволяют осуществлять комплекс действий, связанных с анализом данных и созданием отчетов, и нередко включают в себя интегрированный набор BI-инструментов и средства разработки BI-приложений.
Интеллектуальный анализ данных (ИАД, Data Mining) представляет собой новое направление в области информационных систем, ориентированное на решение задач поддержки принятия решений на основе количественных и качественных исследований сверхбольших массивов разнородных ретроспективных данных.
Принципиальное отличие ИАД от известных методов, используемых в существующих системах поддержки принятия решений, состоит в переходе от технологии оперативного анализа текущих ситуаций, характерной для традиционных систем обработки данных, к методам, опирающимся на мощный аппарат современной математики.
ИАД имеет самые разнообразные практические применения: в экономике, торговле, системах здравоохранения, страхования и других областях. Он используется для решения таких задач, как выявление скрытых закономерностей в архивных финансовых данных при создании прогностических моделей, верификация данных о курсах валют, выявление новых потенциальных клиентов, определение зависимостей между основными показателями и характеристиками сегментов рынка при проведении маркетинговых исследований, выявление счетов потенциально платежеспособных дебиторов, в различных задачах прогнозирования, например при определении возможных невыплат в сделках с недвижимостью и многих других.
В настоящее время инвестиции в разработку систем ИАД достаточно велики, однако выигрыш от их внедрения может достигать 1000%, а расходы при правильном использовании системы могут окупиться за несколько месяцев.
Все вышеперечисленные достоинства ИАД, доказательства его эффективного применения в силу специфики требований ERP-систем обуславливают выбор именно этого направления для поиска алгоритмов и методов извлечения знаний.
Однако, несмотря на значительный прогресс в области ИАД, практическая реализация этой технологии сопряжена с рядом трудностей. В настоящее время ИАД использует достижения многих разделов современной математики. Как правило, большинство фирм-разработчиков концентрируют свои усилия на одном-двух конкретных методах, никак не связывая свои продукты с разработками других фирм в этой области. Каждая из фирм создает собственный интерфейс, собственную систему ввода-вывода и отображения информации, собственную технологию общения с программным продуктом. В результате внедрение средств ИАД существенно усложняется, поскольку подобное вавилонскому смешению языков многообразие и программных продуктов ИАД, и применяемых в них математических методов затрудняет выбор базового комплекта алгоритмических средств.
Методы и средства
интеллектуального анализа данных
Проведем некоторую условную классификацию средств анализа данных, разбив все их множество на четыре направления по методам, реализованным в этих системах.
Методы статистической обработки данных
Предварительный анализ природы статистических данных (проверка гипотез стационарности, нормальности, независимости, однородности, оценка вида функции распределения и ее параметров).
Выявление связей и закономерностей (линейный и нелинейный регрессионный анализ, корреляционный анализ).
Многомерный статистический анализ (линейный и нелинейный дискриминантный анализ, кластер-анализ, компонентный анализ, факторный анализ).
Динамические модели и прогноз на основе временных рядов.
Наиболее известные и популярные средства статистического анализа: пакеты Statistica, SPSS, Systat, Statgraphics, SAS, BMDP, TimeLab, Data-Desk, S-Plus, Scenario (BI).
Недостатки: требование к специальной подготовки пользователя, большинство методов, основываются на парадигме, в которой главными фигурантами выступают усредненные значения, которые при исследовании реальных сложных жизненных феноменов часто оказываются фиктивными величинами.
Особое направление в спектре аналитических средств ИАД составляют методы, основанные на нечетких множествах. Их применение позволяет ранжировать данные по степени близости к желаемым результатам, осуществлять так называемый нечеткий поиск в базах данных. Однако платой за повышенную универсальность является снижение уровня достоверности и точности получаемых результатов. Поэтому число специализированных приложений данного метода по-прежнему невелико, несмотря на то, что на протяжении последних 35 лет математики-прикладники проявляли к нему повышенный интерес.
Методы нейронных сетей. Формируются путем построения иерархической сети, узлами которой являются модели нервных клеток (нейронов), у которых выходной сигнал определяется взвешенной суммой входных сигналов. В свою очередь, входные сигналы представляют собой выходные сигналы нейронов предыдущего уровня. Входными сигналами всей сети являются параметры текущих рядов наблюдений. Ретроспективные данные используются в качестве обучающих выборок, формирующих значения весовых коэффициентов входных параметров нейронов (Рис.2).
Основным недостатком нейросетевой парадигмы является необходимость иметь очень большой объем обучающей выборки. Другой существенный недостаток заключается в том, что даже натренированная нейронная сеть представляет собой черный ящик. Знания, зафиксированные как веса нескольких сотен межнейронных связей, совершенно не поддаются анализу и интерпретации человеком [1](известные попытки дать интерпретацию структуре настроенной нейросети выглядят неубедительными – система “KINOsuite-PR”)
Эволюционное программирование. Суть метода состоит в получении оптимального решения путем имитации процесса эволюции популяции. В исходный вариант решения вносятся различные, возможно случайные, изменения; совокупность модифицированных решений образует новое поколение возможных решений, которое подвергается «естественному отбору», основанному на «критерии выживания» (критерии допустимости решения). Сохранившиеся после отбора решения вновь модифицируются («размножаются»), образуя третье поколение, и процесс итерационно повторяется. При этом образуется самоорганизующаяся оптимизационная последовательность, приводящая к наилучшему решению (прогнозу) самым неожиданным образом: наиболее эффективное решение может оказаться результатом последовательной эволюции далеко не лучшего (хотя и допустимого) решения. Разновидностью эволюционного программирования является метод группового учета аргументов, позволяющий эффективно оценивать динамические характеристики исследуемого процесса путем последовательных уточнений результатов статистической подгонки наблюдений. При этом из ретроспективной выборки наблюдений выделяется часть, используемая для контроля результатов подгонки.
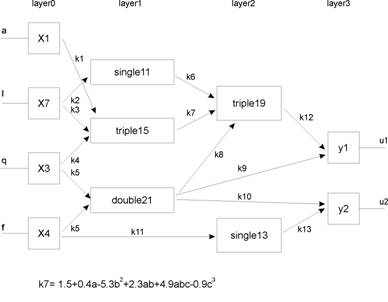
Рис.2. Полиномиальная нейросеть
Генетические алгоритмы. Во многом напоминают эволюционное программирование. Здесь также происходит генерация, отбор и селекция возможных решений, интерпретируемых как генетические информационные структуры с заданным набором параметров («хромосом»). При этом помимо случайных изменений генной структуры («мутаций») происходит и направленная модификация, т. е. «скрещивание хромосомных наборов» решений предыдущего поколения. Генетические алгоритмы также являются самоорганизующимися и позволяют получать качественно новые, неожиданные результаты.
Однако новые достоинства порождают и новые проблемы. В частности, решения, полученные кибернетическими методами, часто не допускают наглядных интерпретаций, что усложняет жизнь предметным экспертам.
К программным продуктам, использующим кибернетические методы ИАД, относятся системы PolyAnalyst(2.2), GeneHunter(2.3), (2.1): NeuroShell, BrainMaker, OWL, 4Thought.
Алгоритмы ограниченного перебора. Предложены в середине 60-х годов М.М. Бонгардом для поиска логических закономерностей в данных. С тех пор они продемонстрировали свою эффективность при решении множества задач из самых различных областей.
Эти алгоритмы вычисляют частоты комбинаций простых логических событий в подгруппах данных. Примеры простых логических событий:
X = a; X < a; X > a; a < X < b и др.,
где X — какой либо параметр,
“a” и “b” — константы.
Ограничением служит длина комбинации простых логических событий (у М. Бонгарда она была равна 3). На основании анализа вычисленных частот делается заключение о полезности той или иной комбинации для установления ассоциации в данных, для классификации, прогнозирования и пр. Наиболее ярким современным представителем этого подхода является система WizWhy. Ее недостаток- система выдает решение за приемлемое время только для сравнительно небольшой размерности данных. Тем не менее, система WizWhy является на сегодняшний день одним из лидеров на рынке продуктов Data Mining. Это не лишено оснований. Система постоянно демонстрирует более высокие показатели при решении практических задач, чем все остальные алгоритмы.
Традиционные методы решения оптимизационных задач
Включают в себя вариационные методы, методы исследования операций, включающие в себя различные виды математического программирования (линейное, нелинейное, дискретное, целочисленное), динамическое программирование, принцип максимума Понтрягина, методы теории систем массового обслуживания. Программные реализации большинства этих методов входят в стандартные пакеты: MathCAD и MatLab.
Средства, связанные непосредственным использованием опыта эксперта.
Метод «ближайшего соседа», лег в основу таких программных продуктов, как Pattern Recognition Workbench или KATE tools.
Для осуществления прогноза на будущее или выбора правильного решения в прошлом находятся близкие аналоги наличной ситуации и выбирают тот же ответ, который был для них правильным. Показывают неплохие результаты в самых разнообразных задачах. Главными их недостатками являются: отсутствие, обобщающих предыдущий опыт, поэтому неизвестно, на основе каких конкретно факторов системы строят свои ответы[1], а также произвол, который допускают системы при выборе меры "близости". От этой меры зависит объем множества прецедентов, которые нужно хранить в памяти для достижения удовлетворительной классификации или прогноза.
Деревья решений.. Связан с построением последовательного логического вывода - дерева решений, в каждом узле которого эксперт осуществляет простейший логический выбор («да» - «нет»). В зависимости от принятого выбора, поиск решения продвигается по правой или левой ветви дерева и в конце концов приходит к терминальной ветви, отвечающей конкретному окончательному решению. Здесь процесс статистического обучения выведен за пределы программы и сконцентрирован в виде некоторого априорного опыта, заключенного в наборе ветвей-решений.
Алгоритм деревьев классификаций и регрессии является одной из разновидностей метода деревьев решений предлагающий набор правил для дихотомической классификации совокупности исходных данных. Данный метод обычно применяется для предсказания того, какие последовательности событий будут иметь заданный исход. На основе метода разработаны программные продукты: как IDIS, See5/С5.0 и SIPINA.
Предметно-ориентированные системы. Это системы анализа ситуаций и прогноза, основанные на фиксированных математических моделях, отвечающих той или иной теоретической концепции. Роль эксперта состоит в выборе наиболее адекватной системы и интерпретации полученного алгоритма. Достоинства и недостатки таких систем очевидны - предельная простота и доступность применения и расплата достоверностью и точностью за эту простоту. Программные продукты: Wall Street Money, MetaStock, SuperCharts, Candlestick Forecaster.
Методы визуализации данных. Нацелены на визуализацию и результатов их анализа, позволяющие наглядно отображать полученные выводы для создания у предметных экспертов и/или руководителей проектов единой картины ситуации. Программные продукты: DataMiner 3D, Mineset и Impromptu (BI). (рис. 3)
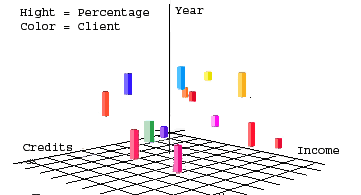
Рис.3. Пример визуализация данных. Зависимость доходов от кредитов под различные проценты и сроки
Проблемы хранения и поиска данных
Несмотря на многочисленные достоинства средств ИАД, построение систем хранения данных, предназначенных для использования средствами ИАД, порождает целый спектр проблем. Здесь и согласование разнотипных форматов данных, и необходимость получения, согласования и верификации данных из разнородных внешних источников, и задача привязки к единой шкале времени, и проблема управления сверхбольшими объемами информации (от десятков и сотен гигабайт до терабайт), и многомерность структуры запросов, и нестандартизуемость запросов экспертов-аналитиков.
В качестве возможного варианта решения можно рассматривать концепцию хранилищ данных (ХД, Data Warehouse) Б. Инмона и концепцию информационных хранилищ (Information Warehouse), разработанную IBM еще в 80-х гг. При этом в основу концепции ХД были положены принципы наличия предметной ориентации, средств интеграции данных, неизменности и хронологизации данных.
Однако даже в модифицированном виде вариант единого, монолитного и неизменного источника данных не вполне конструктивен. В частности, анализ поведения изучаемого объекта в разнообразных условиях предполагает генерацию разнообразных виртуальных ситуаций и отвечающих им данным; загромождение такими данными все запоминающего ХД было бы по меньшей мере, нерационально. Таким образом, появилась идея двухуровневой структуры хранения данных. На первом уровне используется неизменное хранилище сверхбольшого объема и ограниченной оперативности при обработке запросов. При этом информации каталогизируются тематически, охватывая весь спектр возможных интересов корпорации и связанных с ними смежных областей деятельности безотносительно какой-либо конкретной задачи. Данному уровню, в принципе, может отвечать соответствующим образом модифицированная реляционная база данных.
На втором уровне предполагается иметь менее емкую, но более оперативную базу данных, строго ориентированную на всеобъемлющее обеспечение информацией конкретной предметной задачи. Для этих целей больше подходят многомерные базы данных.
Другим подходом к построению второго уровня ХД является концепция витрин данных (Data Mart), предполагающая, что эксперт работает только с теми данными, которые нужны для решения конкретной задачи. Целевая база данных витрин максимально приближена к конечному пользователю и не требует сверхбольшой памяти, характерной для первого уровня ХД.
Такая многоуровневая схема ХД постепенно становится стандартом де-факто, позволяя наиболее полно реализовать и использовать достоинства каждого из подходов.
Проблемы эффективного применения ИАД
Приведенное выше описание математического арсенала ИАД наглядно иллюстрирует многообразие предлагаемого инструментария. При этом одну и ту же задачу оказывается вполне допустимо и возможно решать различными методами. Возникает вопрос: какому инструменту отдать предпочтение в каждом конкретном случае?
Разумеется, можно попытаться сравнить различные аналитические методы для некоторого набора возможных ситуаций и дать общие рекомендации по выбору того или иного алгоритма. Однако практически любая задача повседневной практики обладает спектром характерных особенностей, из-за которых априорные указания часто оказываются полезными с точностью «до наоборот»!
Кроме того, качество формируемого решения часто зависит от установки ряда параметров, правильный выбор которых требует предварительного исследования природы имеющихся данных и понимания применяемого математического аппарата.
Так, например, аппроксимация изучаемого процесса на основе метода наименьших квадратов (МНК), используемого во многих пакетах ИАД, достаточно эффективна для гауссовской последовательности исходных данных. Однако если реальные наблюдения подчинены другому распределению (например, распределению Лапласа) или просто содержат аномальные данные, эффективность МНК существенно снижается, что неизбежно скажется на достоверности оценки ситуации или точности прогноза. В этом случае оказывается целесообразным использовать метод наименьших модулей или, еще лучше, специальные робастные методы параметрического оценивания.
Коммерческие программные средства ИАД, несмотря на все их разнообразие, представляют собой универсальные математические инструменты. Более того, эксперт, использующий такой продукт, имеет дело лишь с указанием на применяемый математический метод (например, метод главных компонент) и самым общим описанием входных/выходных данных и рабочих параметров. Сами алгоритмы остаются недоступными. Таким образом, эксперт, по существу, работает с некоторым «черным ящиком», который должен обеспечить решение некоторого класса задач, не допуская и не требуя каких-либо модификаций.
Причин для такого подхода более чем достаточно. Это и коммерческая защита дорогостоящей разработки, и обеспечение возможности работы со сложной математикой предметным экспертам, и специфика рынка программных продуктов. А недостаток один -- универсальный инструмент в каждом конкретном случае, как правило, проигрывает в эффективности специализированному средству, ориентированному на применение именно в этой ситуации. В отдельных случаях разница в эффективности может достигать десятков процентов.
Естественным выходом из этого положения является включение в состав экспертной группы специалиста в области ИАД -эксперта-аналитика с необходимой математической подготовкой, который должен понимать содержательную часть решаемой задачи на уровне рабочего взаимодействия с предметным экспертом, уметь работать с готовыми программными продуктами ИАД и должен быть способен постепенно формировать собственную систему аналитических исследований с открытой алгоритмикой, допускающей модификацию и адаптацию процедур анализа и прогноза с учетом конкретных ситуаций и особенностей.
Заключение
Возрастающие требования и запросы по извлечению знаний в ERP – системах обуславливают необходимость использования современных инструментов Business Intelligence с целью получения аналитической информации, поддержки принятия решений и прогнозирования. Достоинства методов ИАД определяют основное направление поиска методов и алгоритмов для решения проблем извлечения знаний в ERP-системах.
Несмотря на обилие методов ИАД, приоритет в эффективных современных разработках смещается в сторону логических алгоритмов поиска в данных if-then правил. С их помощью решаются задачи прогнозирования, классификации, распознавания образов, сегментации БД, извлечения из данных “скрытых” знаний, интерпретации данных, установления ассоциаций в БД. Результаты таких алгоритмов эффективны и легко интерпретируются.
Вместе с тем, существуют проблемы по поиску данных и эффективному использованию методов ИАД. Основной проблемой логических методов обнаружения закономерностей является проблема перебора вариантов за приемлемое время. Известные методы либо искусственно ограничивают такой перебор, либо строят деревья решений, имеющих принципиальные ограничения эффективности поиска if-then правил [1]. Известные методы поиска логических правил не поддерживают функцию обобщения найденных правил и функцию поиска оптимальной композиции таких правил. Таким образом, решением перечисленных проблем можно добиться новых более успешных результатов в области разработок Data Mining.
Литература
1. [Дюк В., Самойленко А., 2001]
4. [Соколов Н.]
5. [Программы планирования ресурсов (ERP) необходимы, но недостаточны., 2000]
6. [Федоров А., Елманова Н., 2001]
7. [Шроэк М., Зинн Д., Берг Б.]
8. [Треппер Ч.]
10. [Румянцев К.]
11. [ERP и B2B. Интеграция или слияние?]
12. [ERP умер - да здравствует ERP издания InSide GartnerGroup]