Рисунок 1
Крылов А.Б.
Модуль предварительной
векторизации растровых
монохромных изображений
гибридного редактора SpotLight
Автоматическая векторизация представляет собой процесс преобразования растрового монохромного изображения в набор взаимосвязанных векторных объектов, таких как отрезок, дуга, окружность, полилиния, текст, штриховка и блок примитивов или символ. Базовый векторизатор состоит функционально из четырех модулей: скелетизатора, построителя топологической модели растра, генератора примитивов и постпроцессора разрешения объектных связей. Базовый векторизатор должен иметь отрытую архитектуру, обеспечивающую доступ к топологической модели растра, что позволит подключать внешние модули распознавания топологически сложных объектов, таких как, символы или блоки. Рассмотрим подробнее технологический процесс автоматической векторизации, реализованный в программе “SpotLight” (Copyright Consistent Software. Россия).
Постановка задачи автоматической векторизации.
Исходные данные:
Задаваемые оператором параметры изображения:
Width – максимальная толщина линейных объектов на изображении;
GapJump – максимальная величина игнорируемого разрыва линейных объектов на изображении;
Length – минимальный размер распознаваемых объектов на изображении:
VT(i) – задаваемое пользователем множество типов векторных объектов, содержащихся на изображении (отрезок, дуга, окружность, полилиния, контур, текстовая область, символ...).
Accuracy - точность, определяющая степень “следования” растру для получаемых векторных объектов и соответственно задающая предельные значения вероятности распознавания каждого типа объекта.
Задача: получить топологичекую модель растрового изображения, состоящую из набора векторных объектов заданных типов из множества VT и связей между ними, с заданной степенью соответствия растру.
Для решения поставленной задачи примем за аксиому следующие утверждения:
Укрупненный алгоритм векторизации состоит из нескольких этапов, которые рассмотрены ниже.
Истоньшение (скелетезация) изображения.
Истоньшение – процесс построения точек средней линии объектов, содержащихся на растровом изображении с целью их последующего использования для генереции математического представления объекта. Базовый алгоритм истоньшения, описанный в работе Павлидиса основан на определении группы равноудаленных точек с сохранением их растровой связности и поэтому как нельзя лучше подходит для построения топологической модели изображения. Описанный ниже алгоритм представляет собой логичное развитие базового алгоритма с попыткой минимизировать искажения остова, используя параметры минимального размера распознаваемого объекта Length и его максимальной толщины Width и оптимизировать скорость его работы, используя так называемое RLC-кодирование для хранения растра.
Структура хранения изображения.
Большинство операций в процессе векторизации производятся только с черными точками изображения и доступ к данным осуществляется построчно. К тому же, как правило, отсканированные оригиналы, на которых эффективно использовать векторизацию, это машиностроительные чертежи, электросхемы, поэтажные планы, топокарты и тому подобное, т.е. материалы содержащие меньшее количество черных точек по отношению к белым. Таким образом, для уменьшения объема используемой памяти и увеличения скорости доступа был выбран способ хранения изображения, использующий RLC-кодирование (Run Length Codes) или, иначе говоря, кодирование длин черного. Структура данных для хранения растра представляет собой массив указателей на строки, каждая из которых содержит в свою очередь динамический массив пар чисел, кодирующих левую и правую координаты каждой черной зоны в пределах каждой строки. Каждая строка завершается терминатором = 0xFFFF. Длина каждой строки является переменной величиной и определяется количеством черных зон в каждой строке. В частности, белая строка будет содержать только терминатор. Ниже приведен пример кодирования изображения:
Y0 -> (X0Start, X0End),( X1Start, X1End) .....( XNStart, XNEnd),0xFFFF.
Y1 -> (X0Start, X0End),( X1Start, X1End) .....( XNStart, XNEnd),0xFFFF.
.......
YN -> (X0Start, X0End),( X1Start, X1End) .....( XNStart, XNEnd),0xFFFF.
Эффективность подобного кодирования можно пояснить на простом примере: если для хранения отсканированного машиностроительного чертежа формата А0 (32 х 44 дюйма) с разрешением 400 DPI требуется около 28 мегабайт оперативной памяти (12800 точек * 17600 точек / 8 бит), то в случае RLC-кодирования это величина в 5-10 раз меньше в зависимости от плотности заполнения растра. При условии, что для большинства алгоритмов требуется две-три копии изображения, можно представить сколько времени займет свопинг памяти. К тому же, данная структура позволяет быстрее обращаться только к черным точкам, эффективно строить цепочки связности соседних пикселов и анализировать только крайние пикселы, что активно используется в алгоритме истоньшения. Существенным недостатком является медленный прямой доступ к данным, когда требуется определить или изменить цвет конкретной точки по ее координате. В таких случаях эффективней использовать карту бит. Описанные ниже алгоритмы достаточно эффективно используют преимущества RLC-кодирования.
Удаление растровых малоразмерных объектов.
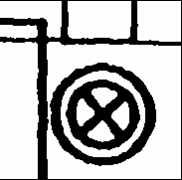
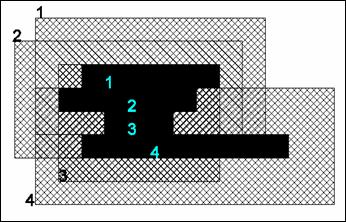
При сканировании изображения с не очень качественного оригинала, например, с так называемых “синек”, достаточно часто появляется эффект “ворситости” на границе порога бинаризации. Наличие на изображении небольших групп белых и черных, связанных между собой точек увеличивает время и ухудшает качество распознавания. На приведенном ниже примере (Рис.1) достаточно хорошо видны результаты истоньшения растра при наличии “ворсистости” на границах и “дырок” внутри объектов.
Объекты такого рода не должны распознаваться как векторы и участвовать в топологической модели изображения. Поэтому для исключения подобных объектов перед истоньшением запускается алгоритм удаления малоразмерных объектов непосредственно на растре. Основным критерием классификации паразитных объектов является заданный минимальный размер объекта. Задача работы алгоритма удаления – это поиск связанных групп черных и белых точек с последующей заливкой соответственно белым или черным цветом с целью исключения их из анализа до распознавания.
Алгоритм удаления малоразмерных объектов.
Процедура DeleleSmallRasterObjects
Начало
Для каждой строки изображения размером Cx x Cy
Начало (цикл по Y)
Для каждого черного и белого интервала строки
Начало (цикл по X)
Если длина интервала (Xend-Xstart) меньше заданной MinLength
Начало (меньше MinLength)
Дать размер окрестности, используя рекурсивную процедуру FloodFill для сборки соседних интервалов одного цвета на основании критерия связности с дополнительным условием выхода из цикла по превышению размера.
Если полученный размер окрестности меньше заданного,
То залить окрестность инверсным цветом,
Иначе размер больше заданного
Пометить окрестность как проанализированную, чтобы вычеркнуть из дальнейшего рассмотрения.
Конец (меньше MinLength)
Конец (цикл по X)
Конец (цикл по Y)
Конец
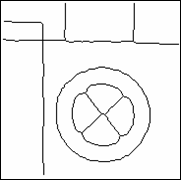
Результаты работы алгоритма можно увидеть на рис. 2.
Построение остова растра.
После удаления паразитных объектов используется типовой алгоритм истоньшения, который представляет собой итерационный классификатор крайних черных пикселов изображения по окружению соседних восьми пикселов. Для работы алгоритма требуется две копии изображения: первая представляет собой оригинал, с которого в процессе истоньшения удаляются крайние пикселы, обращение к которым происходит достаточно быстро за счет использования RLC-кодирования, вторая содержит только пикселы, классифицированные как остов. Для ускорения процедуры классификации пикселов строится одномерный массив размерностью 256, индекс которого является результатом кодирования 8-точечной окрестности пиксела, а содержимое – это булева переменная принадлежности к остову. Кодирование осуществляется по правилу цепочного кода. Все пикселы окружения пронумерованы против часовой стрелки вокруг текущего пиксела от 0 до 7. Номер означает индекс бита в байте кода. Бит взводится если пиксел черный. В процессе каждой итерации производится четыре прохода по растру: для всех левых, правых, верхних и нижних пикселов, что обеспечивает равномерность удаления остовных пикселов от краев. Каждый пиксел классифицируется на принадлежность остову и, либо переносится на вторую копию, либо удаляется с оригинала. Условием выхода из цикла является отсутствие пикселов на первой копии изображения, либо ограничение числа проходов путем задания максимальной толщины линейного объекта Width.
Распознавание площадных объектов
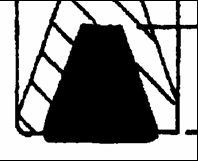
На рисунке ниже приведен типовой пример площадного объекта, связанного с группой линейных и результаты работы четырех проходов алгоритма истоньшения. Как было описано выше для деления объектов на линейные и площадные используется понятие максимальной толщины MaxWidth. При нулевом значении этого параметра все объекты изображения считаются площадными. Случай представленный на рисунке наиболее общий, поэтому рассмотрим его более подробно. Изображение справа является результатом объединения обоих копий растра при истоньшении, на нем можно видеть, что линейные объекты уже перенесены на копию остова (тонкие линии), а площадной объект все еще находится на оригинале, но при этом уменьшился в размере равномерно со всех сторон. Именно на этом этапе подключается алгоритм распознавания площадных объектов. Векторным прототипом площадного объект в общем случае является группа контуров с признаком закраски. Каждый контур задается последовательностью точек с координатами (X,Y). Точность аппроксимации контура задается параметром Accuracy и зависит от оптического разрешения растра. К примеру, разрешение 300 точек на дюйм обеспечивает точность расчета геометрических параметров ~0.08 мм и является достаточной для машиностроительных чертежей, где размеры объектов измеряются миллиметрами, а толщина линий колеблется от 0.25 до 5.00 мм. Алгоритм построения контура по границе цветов с последующей аппроксимацией позволяет минимизировать искажения, вызванные дискретностью представления растровых данных.
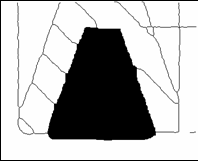
Для точной передачи формы объекта, представленного в нашем примере, необходимо применить алгоритм утолщения. Утолщение заключает в обходе контура и добавлении черных точек в количестве равном числу проходов истоньшения во всех направлениях для каждой его точки. Типовой алгоритм утолщения является многопроходным, в нашем случае количество проходов равно четырем. По завершении алгоритма объект восстановит свою форму и геометрические параметры с определенной точностью. После чего можно будет построить математическое описание формы объекта.
Алгоритм утолщения растра.
Использование RLC-кодирования позволяет гораздо эффективнее произвести утолщение растра за один проход. В общем случае, количество проходов с утолщением на одну точку можно заменить на один проход с утолщением на количество точек равным количеству проходов, что хорошо видно на рис. 4.
Черным изображены точки исходного растра, штриховкой – результирующий растр после утолщения на 2 точки. Таким образом алгоритм утолщения заключается в рисовании закрашенных квадратов для каждого черного интервала, размер которых увеличен на количество точек, равное количеству проходов алгоритма или в нашем случае количеству проходов алгоритма истоньшения. В результате работы алгоритма утолщения форма площадного объекта восстанавливается с достаточной степенью точности для его оцифровки или построения контура.
Алгоритм построения контура растрового объекта.
В отличие от алгоритма, приведенного в своей работе Павлидисом, который использует знание восьми-точечной окрестности пиксела и строит контур проходящий через центры белых или черных точек, описанный ниже алгоритм дает меньшую погрешность при вычислении геометрических параметров контура.
Как видно из рисунка, контура, построенные стандартным алгоритмом искажают геометрические параметры объекта, уменьшая реальные размеры, при построении по черным точкам, и увеличивая их в случае построения контура по белым точкам. Так же возможно “схлопывание” контуров в случае размеров объекта равных одной растровой точке по любой из координат. Из приведенного примера следует, что наиболее точная передача формы произойдет при следовании контура по границе между цветами. Принцип работы алгоритма проиллюстрирован на следующем рисунке 6.
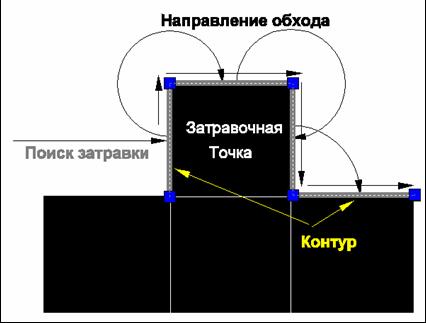
Для работы алгоритма необходимо две копии растра, так как алгоритм предполагает прямой доступ к изображению целесообразнее использовать битовую карту для хранения растра. Первая копия содержит оригинальный растр, вторая служит для маркировки точек растра уже включенных в один из контуров, чтобы исключить их из анализа и избежать зацикливания. Смысл алгоритма заключается в обходе контура по узлам виртуальной решетки, образованной границами между реальными растровыми точками. Координаты узлов решетки отличаются от координат точек ровно на половину величины растровой точки. Соответственно вторая копия растра имеет размеры на одну точку больше и равные количеству узлов решетки. Выбор направления движения осуществляется на основе анализа 4-точенной окрестности каждого узла. Перед началом обхода контура ищется затравочная точка, которой может быть только черная точка, примыкающая к белой левой стороной. Каждая точка контура помечается как черная на второй копии, чтобы не служить в качестве затравочной. Обход контура завершается по его замыканию на затравочную точку. Для минимизации количества точек используется один из стандартных алгоритмов аппроксимации, точность которого определяется заданным параметром Accuracy. Группа построенных контуров является векторным прототипом растрового площадного объекта.
Построение топологической модели растра
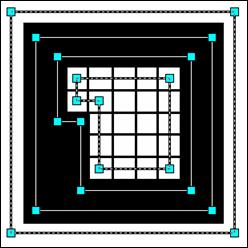
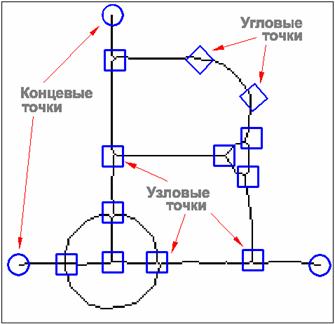
Топологическая модель растра представляет собой совокупность типизированных узлов, хранимых как точка с заданными координатами и связей между ними, представленных в виде цепочных кодов. Тип узла определяется количеством связей из него выходящих. Узловые и концевые точки определяются на основе анализа восьми-точечной окрестности каждого пиксела остова, угловые точки создаются алгоритмом поиска углов. На рисунке представлен фрагмент типичного остова изображения и визуальное представление его топологической модели.
Для ускорения доступа к узлам и связям графа структура данных использует дублирование информации, а именно, каждый узел знает о всех своих связях и каждая связь хранит ссылки на оба узла. Процесс создания топологической модели по остову растра состоит из следующих этапов: коллекционирования узлов, построения цепочек связей между узлами, сборка замкнутых объектов, классификации узлов и связей и поиска угловых точек. Рассмотрим подробнее структуру хранения и каждый из этапов создания графа связности.
Структура данных топологичекой модели
Узел графа связности
struct NODE_POINT
{
int x,y; - абсолютные координаты узла
int iType; - тип узла (конечная , угловая , узловая точка)
void* pChains[4]; - массив указателей на цепочки
};
Связь узлов графа.
struct CHAIN_CODE
{
int hypType; // вероятный тип объекта
int Width; // толщина
int iKnt1,iKnt2; // индексы узлов сети
int iPnt1,iPnt2; // индексы надежных точек
int iCpnt; // общее количество точек
char* pChainCode; // цепочное кодирование (0...7)
};
Коллекционирование узлов
Узлом считается растровая точка, которая имеет одну, три или четыре соседних точки. Для каждой точки остова строится восьми-точечная окрестность и в случае если выполняется данное условие, узел добавляется в динамический массив узлов. В зависимости от количества соседних точек узлу присваивается тип iType и сохраняются его координаты (х,y). На этом этапе возможно появление только концевых и узловых точек.
Построение связей графа
Для построения связей используется алгоритм под названием “жук”. Смысл его заключается в “поедании” точек остова между узлами, чтобы избежать дублирования связей и зацикливания алгоритма.
Для каждого узла графа производится проход в каждую из черных точек, пока не встретится другая узловая точка. По мере движения “жука” для каждой черной точки кодируется только направление движения (0-7), точка в которой побывал жук, удаляется с растра, за исключением самих узлов. Алгоритм завершает свою работу по окончанию обработки последнего узла массива. После чего все узлы удаляются с растра.
Сборка замкнутых объектов
После работы “жука” на растре могут остаться замкнутые объекты, не связанные с другими, например, изолированные окружности. Такого рода объекты не порождают узлов, которые могли бы служить затравочными точками. Чтобы не потерять такие объекты производится дополнительный проход по растру с поиском оставшихся черных точек. Как только “жук” находит черную точку, происходит добавление узла типа “угловая точка” в массив узлов и производится создание замкнутой цепочки со ссылками на один и тот же узел. Алгоритм завершает работу, когда растр пуст.
Классификация узлов и связей графа
На этом этапе происходит устранение искажений остова, удаление паразитных цепочек, замер толщин растровых объектов, предварительное распознавание надежных (высоковероятных) объектов, присваивание гипотетического типа каждой цепочке, поиск угловых точек и повторная типизация узлов. Результаты работы этого этапа существенно влияют на качество распознавания векторных примитивов. На этом этапе активно используется информация с оригинального растра и построенная на его базе топологичекая модель, поэтому для увеличения скорости работы алгоритмов целесообразнее использовать битовую карту для хранения растрового изображения.
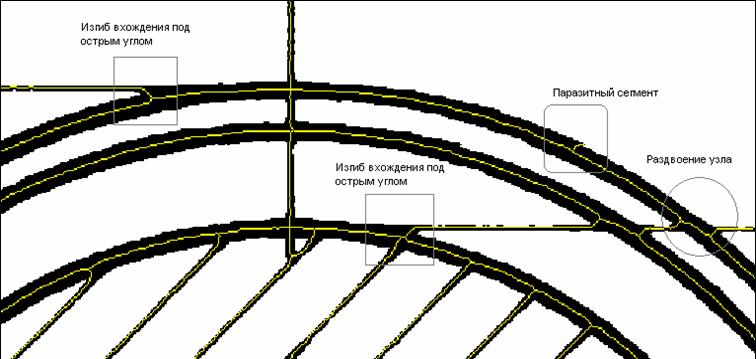
Чтобы использовать цепочки точек для генерации геометрических параметров объектов необходимо выделить в каждой из них группу так называемых “надежных” точек. Типовые искажения остова представлены на рисунке 8.
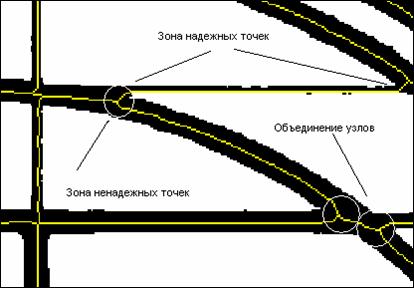
Достаточно очевидно, что использование подобных точек при распознавании формы объекта будет давать некорректный результат, а наличие паразитных узлов не позволит построить правильную топологическую модель. Несмотря на кажущееся многообразие случаев, большинство из них сводится к простому правилу: искажения формы остова (центральной линии) происходят в месте вхождения объектов друг в друга в пределах их толщин. Используя этот критерий можно минимизировать искажения, избавиться от паразитных узлов и объектов и выделить группы надежных точек. На этом принципе работает алгоритм коррекции топологии. А именно, для каждого узла сети определяется так называемый растровый радиус, т. е. минимальное расстояние от узла до белой точки. После чего все соседние узлы, расположенные друг от друга на расстоянии меньшем суммы их растровых радиусов, объединяются, а все точки цепочек в пределах радиуса узла считаются ненадежными и исключаются из процесса генерации объектов. Принцип работы алгоритма проиллюстрирован на следующем примере (рисунок 9).
После коррекции топологии производится повторная типизация узлов. Следующим шагом является означивание предполагаемых типов объектов для каждой цепочки на базе надежных точек. Цепочка может принадлежать одному из следующих классов: линейный сегмент, дуговой сегмент, сегмент неопределенного типа, остов площадного объекта. Класс линейный сегмент определяет набор точек, на основе которого может быть построен только отрезок. Примером такого сегмента является зона надежных точек, представленная на рисунке. Класс дуговой сегмент определяет набор точек, на основе которого может быть построена только дуга. Класс сегмент неопределенного типа определяет набор точек, на основе которого может быть построена как дуга, так и отрезок с равной степенью вероятности. Класс остов площадного объекта определяет набор точек, на основе которого не создаются линейные объекты и толщина которого превышает заданную максимальную. Цепочки данного класса служат исключительно для построения связей между объектами и идентифицируются при расчете растрового радиуса узлов алгоритмом, описанным выше.
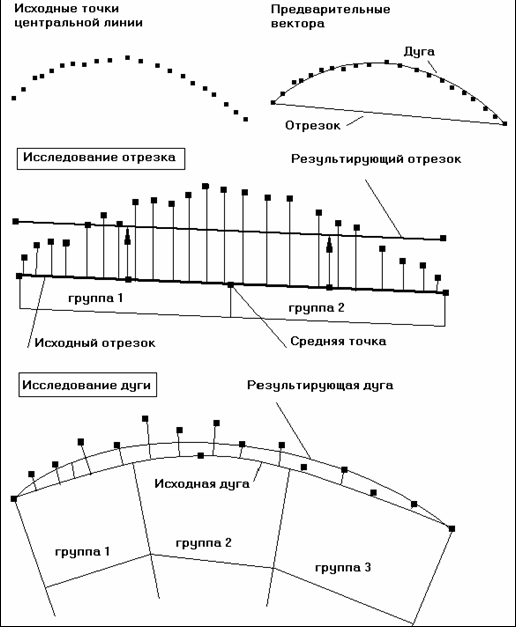
Алгоритм классификации заключается в выборе оптимальной формы объекта по заданному набору надежных точек. Сначала предпринимается попытка построить дугу и отрезок на заданном наборе точек. После чего рассчитывается среднее и максимальное отклонение точек остова от полученных геометрических параметров объекта и если его значение оказывается в пределах допустимого, гипотеза принимается.
Создание векторного прототипа объекта основано на принципе минимизации отклонения. Сначала создается произвольный отрезок (две крайних точки) или дуга (две крайних и средняя точки). После чего все исходные точки разбиваются для линии на две группы, разделенные серединой, для дуги на три группы в одну треть ее сектора и для каждой части вычисляется отклонение в каждой растровой точке (см. Рис). После чего для каждого из участков рассчитывается среднее отклонение, которое имеет знак. В середине каждого из участков вычисляются новые точки, которые будут скорректированы на величину среднего отклонения и использованы для создания нового вектора, который и будет результатом предварительного распознавания.
Приведем формальное описание Алгоритма моментов с предварительным эталоном:
В данном примере (см. рисунок выше) видно, что укладка дуги лучше нежели отрезка, поэтому в качестве базовой гипотезы будет принят вариант “дуга”. Исходные тексты алгоритмов генерации приведены в приложении.
Поиск угловых точек
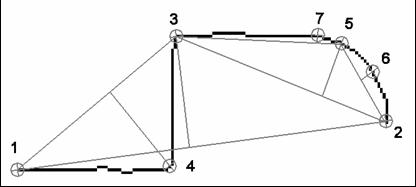
В процессе классификации цепочек возможны случаи, когда ни одна из гипотез не принимается, как например, в случае, представленном на рисунке ниже. Как видно из примера отклонение как для линии, так и для дуги, превышает максимально допустимое. Такие последовательности точек считаются полилинейными и разбиваются на линейные сегменты с помощью алгоритма поиска углов.
Принцип работы алгоритмы заключается в итерационном процессе поиска точки с максимальным отклонением. Точки под номерами 1 и 2 являются уже классифицированными узлами. Номера остальных точек соответствуют итерациям алгоритма поиска углов. В каждом итерационном цикле происходит расчет точки, имеющей максимальное отклонение по нормали к линии, соединяющей узлы текущего сегмента. Если значение отклонения превышает заданное предельное, точка классифицируется как угловая и добавляется в массив узлов. При этом цепочка разбивается в данной точке на две самостоятельные последовательности точек. В противном случае происходит переход к следующему сегменту. Процесс повторяется, пока все неклассифицированные цепочки не будут разбиты.
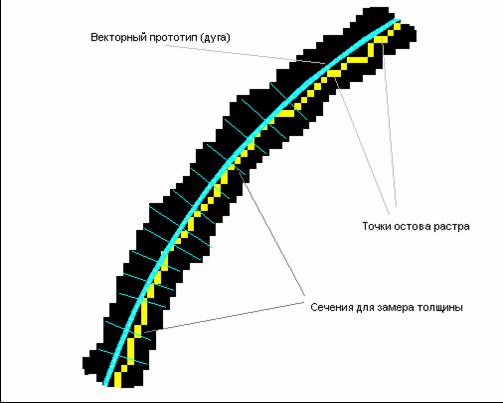
Замер толщин объектов
После разбиения и классификации цепочек производится замер растровой толщины объектов на основании принятой гипотезы о векторном прототипе растрового объекта. Для этого, в каждой точке последовательности в направлении, перпендикулярном предполагаемому объекту, в нашем случае это – дуга или отрезок, производится поиск дальней черной точки с обоих сторон объекта (см. рисунок). Для расчета координат растровых точек используется типовой алгоритм Брезенхема. Расстояние между этими двумя точками и считается растровой толщиной объекта в данной точке. После чего рассчитывается среднее значение толщины для всех точек. Рассчитанная толщина используется при сборе мелких объектов в более крупные, а также при нормировании толщин по заданной таблице, например, требования ГОСТ по оформлению машиностроительных чертежей.
Таким образом, созданная описанным выше способом топологическая модель является достаточно полным и эквивалентным представлением растрового изображения и служит базовой структурой данных для распознавания векторных объектов. Узлы имеют абсолютные координаты и содержат ссылки на цепочки , которые хранятся в виде байтовых смещений 0-7, и в свою очередь содержат ссылки на узлы и могут быть достаточно быстро преобразованы в последовательность точек с абсолютными координатами. Эти последовательности используются для создания векторных объектов с помощью описанных алгоритмов генерации. Каждому узлу сети присваивается статус, зависящий от количества связей, который в последующем используется при наборе объектов, для анализа разрывов растровых линий, расчета конечных точек, распознавания текстов, типов линий и топологически сложных объектов.