Холодова С.А.
Математические принципы
автоматизации построения
частного тезауруса по предметной области на основе общего как основы гипертекстовой
системы.
Математические выкладки статьи имеют своей основой математическую модель гипертекста и тезауруса, изложенные в статье автора: «Некоторые принципы и методики автоматизации проектирования электронных изданий на основе печатных текстов по предметной области» [Холодова, 2001].
Автоматизация выделения терминов предметной области из текста при наличии тезауруса.
Пусть мы имеем общий тезаурус предметной области. To. Все термины, выражающие понятия этого тезауруса, представляют собой множество Zo, W — множество терминов, присутствующих в тексте Q. Стоит задача нахождения
При этом предполагается, что исходный тезаурус избыточен, т.е. в идеальном случае, множество его терминов должно включать все терминологические словосочетания, используемые в тексте. Для практической реализации метода достаточно наличие большинства терминов в тезаурусе. Точное значение параметра коэффициента присутствия терминов текста в тезаурусе по отношению к общему количеству терминов в тексте не удастся определить, так как на сегодняшний день отнесение или не отнесение термина к предметной области является экспертным решением и для части терминов разнится для разных экспертов.
Проблемы выделения терминологии в текстах на естественном языке как одно из ограничений, накладываемых на возможность использования метода.
Наибольшая сложность на этапе выделения терминологии предметной области из текста не в определении пересечения множеств, а в определении самих множеств Zo и W.
И если все термины тезауруса, как это будет показано в третьей главе, являясь терминологической составляющей тезауруса, изначально при построении тезауруса должны быть выделены в отдельную базу данных. То выделение множества терминов в самом тексте Q представляется более проблематичным в силу ряда особенностей естественно-языкового описания предметной области [Михеев, 1990]. Естественно-языковому описанию любой предметной области характерны некоторые конструкции, которые используются для свертки текста, такие как однородные члены, анафористические и эллиптические свертки. Дополнительную проблему создает омонимия. Часть проблем, связанных с однородными членами, анафористическими и эллиптическими свертками могут достаточно эффективно быть решены путем ввода в исходный тезаурус широкой базы синонимов, проблемы с разрешением вопросов омонимии могут быть эффективно решены только с помощью статистического анализа текста ближайшего окружения термина, подозрительного на омонимию. К тому или другому синонимическому узлу тезаурусного графа термин может быть отнесен исходя из наибольшего количества терминов, найденных в этом окружении, совпадающих с ближайшими терминами подозрительного на омонимию из тезауруса. В качестве ближайших терминов тезауруса, то есть близости, радиуса 1, выбираются термины, связанные с подозрительным любыми типами связей. Если этого недостаточно, можно расширять как отрезок текста, подвергаемый анализу, на котором встречается термин, подозрительный на омонимию, так и радиус окружения термина из тезауруса.
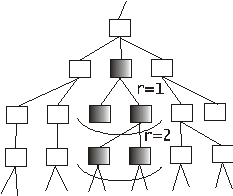
Рисунок 1. Тезаурусный радиус для термина.
Рисунок 1 иллюстрирует правила выделения в общем тезаурусе терминов для проведения анализа, целью которого является снятие омонимии. Метод успешно применялся в системах машинного перевода с той разницей, что для всех возможных значений омонимов составлялся отдельный список возможных слов окружения [Вишнякова, 1973]. И эффективность метода доходила до 98%. В случае использования семантического тезауруса такая база для любого термина может генерироваться на основании самого тезауруса описанным выше методом. Однако, статистическими методами полностью преодолеть трудности выделения терминологии, связанные с естественно-языковыми свертками и омонимией не удается. В этой особенности проявляется одно из ограничений использования предлагаемых методик по автоматизации проектирования гипертекста на основе текста с использованием семантического тезауруса. Для решения таких проблем обычно пользуются методами контент-анализа [Барышников, 1999] , что эффективно, но дорого и долго.
Построение частного тезауруса.
Введем понятие матрицы AMo. Строки и столбцы этой матрицы соответствуют понятиям mi, а элементами матрицы является наличие или отсутствие связи rk между ними. AMo строится для каждого из видов отношений из R.
Akij=1 — существует связь типа k между понятиями mi и mj.
Akij=0 — не существует связь типа k между понятиями mi и mj.
матрицы обратных отношений
,
k — количество семантических отношений, т.е. элементов пространства R.
Объединение осуществляется путем операции логического или над элементами матриц отношений.
Принцип формирования матриц отношений частного тезауруса:
Порядок матрицы AМч определяется размерностью массива M.
mio=mjч, если
,
если mio=mjч и mlo=mkч, то rilo=rjkч,
Так определяются элементы матрицы отношений по видам для частного тезауруса. То есть берется значение, равное значению пересечения строки и столбца исходной матрицы.
Построенный таким образом частный тезаурус является подмножеством общего. Он содержит терминологию текста и тезаурусные связи между терминами текста. Частный тезаурус, имеющий структуру графа, ляжет в основу графа связей проектируемой гипертекстовой системы.
Если в исходном тексте существует хотя бы один термин, присутствующий в общем тезаурусе, то можно построить для этого текста частный тезаурус. Однако, не по каждому частному тезаурусу удастся автоматизированно построить гипертекстовую систему так, чтобы при этом еще был учтен принцип общезначимости, поскольку ассоциативные связи поддерживают свойство связанности графа гипертекстовой системы, а семантический поиск по ним затруднен. В связи с этим ниже обсуждаются ограничения на использование метода в зависимости от свойств частного тезауруса.
Проверка тезаурусного графа на связанность.
Связанность гипертекстового графа устанавливается в общем случае методом перебора при поиске в глубину или в ширину на графах, а для иерархической матрицы, формирующей главное поисковое дерево гипертекстовой системы, необходимым и достаточным условием возможности построения связанного графа является:
,
где
— соответствующий mi столбец обратного семантического
отношения для терминов, характеризующих понятие mi.
Для традиционного понимания гипертекстовой системы достаточно выполнения только первого условия — связанности графа, для гипертекстовой системы с улучшенной эффективностью поиска второе дополнительное условие также необходимо.
Проверка связанности гипертекстового графа.
Метод поиска в ширину.
Проверка осуществляется по объединенной матрице Amч.
Объединенная матрица по технологии формирования содержит как прямые, так и обратные семантические связи.
Занести номер первой строки в массив F.
Занести в массив G все номера столбцов, на пересечениях с которыми данная строка имеет единицу.
Пока G не пуст:
{
Для каждого элемента массива G
Если
Fi=Gj,
то добавить Gj в F,
Для каждого элемента массива G
Заменить каждый элемент массива G номерами столбцов, на пересечении с которыми строка с номером G имеет 1, не являющихся элементом F.
}
если количество элементов массива F < n, где n — порядок объединенной матрицы отношений, то граф не является связанным и по нему нельзя автоматизировано построить гипертекстовую систему.
Существуют и другие математические методы проверки графа на связанность, такие, например, как поиск в глубину на графах, или умножение матрицы связанности самой на себя и анализ полученного результата, однако, этот методы более сложны для программной реализации чем метод, использующий алгоритм поиска в ширину на графах.
Автоматизированная коррекция частного тезауруса
Вышеописанное ограничение использования частного тезауруса можно преодолеть, используя методики коррекции частного тезауруса.
Методики коррекции частного тезауруса сводятся к следующим основным: 1. Отсечение несвязанных подграфов. 2. Связывание фреймов в сеть путем добавления в существующий граф путей из общего тезауруса, обеспечивающих связанность системы.
Первая методика предполагает выбор из всех связанных графов частного тезауруса единственный, количество узлов графа которого наибольшее.
Вторая методика предполагает для каждого из выделенных подграфов отыскание в иерархическом графе вершин, для которых нет входящих иерархических связей, а затем реконструкцию недостающих минимальных путей в иерархической матрице до состояния связанного графа. При реконструкции связывающих путей в частный тезаурус добавляются дополнительные вершины из общего тезауруса, а также связи между этими вершинами и терминами. Реконструкция осуществляется от «висячих» вершин строго снизу вверх до тех пор, пока вышестоящая вершина не будет последней в иерархии общего тезауруса или будет принадлежать частному тезаурусу и не будет висячей. Затем удаляются все вершины и дуги полученного связанного графа, начиная с единственной висячей вершины (единственность этой вершины обеспечивается алгоритмом реконструкции частного тезауруса по общему, приведенному в третьей главе диссертации.) в направлении прямых иерархических связей до тех пор, пока не встретится вершина, для которой имеется более одного нижестоящего термина в иерархическом отношении. Эту вершину и следует оставить первой в иерархии для полученного скорректированного частного тезауруса. Рисунок 2 иллюстрирует принципы использования обеих методик.
Очевидно, что при применении обеих этих методик возможно получение связанного тезаурусного графа, охватывающего все термины предметной области, присутствующие в исходном тексте, и в обладающего некоторой терминологической избыточностью.
Поэтому, построить по такому частному тезаурусу гипертекстовую систему, соблюдающую принцип общезначимости возможно при условии связанности общего тезаурусного графа. Поскольку в вырожденном случае систему можно построить по всему общему тезаурусному графу целиком. При этом для некоторых фреймов системы не будет информационных статей. По-видимому, в этой ситуации следует ставить вопрос не о возможности автоматизированного формирования гипертекстовой системы, а о целесообразности формирования ее таким методом.
Например, возможно, в ситуации, когда количество терминов связывающих путей превосходит количество терминов частного тезауруса, очевидна нецелесообразность формирования системы данным методом. Такая ситуация, например, возможна, если в качестве исходного текста системе на анализ поданы два или более семантически несвязанных отрывка или связанных только по ассоциации. Здесь имеет смысл говорить о семантической близости связываемых подграфов, критерием которой может являться длина минимального пути в общем графе, связывающего корневые вершины подграфов.
В качестве наиболее оптимального решения целесообразности или нецелесообразности собирания «висячих» вершин видится ограничение длины связывающего пути одним или двумя узлами. Если связующий путь длиннее, то принимается решение о нецелесообразности построения гипертекстовой системы данным методом.
Можно также сочетать методы усечения и реконструкции по общему тезаурусу для получения связанного графа иерархического тезауруса. Усечение следует применять для тех связанных подграфов графа частного тезауруса, связывающие пути которых превосходят максимально допустимую длину. Если количество отсекаемой терминологии значимо меньше ее общего количества, то по такому частному тезаурусу целесообразно строить гипертекстовую систему указанным методом.

А. Приведение графа частного тезауруса
к связанному виду методом усечения.

Б. Приведение графа частного тезауруса
к связанному виду методом реконструкции по общему тезаурусу. Заштрихованные
узлы графа восстанавливаются по общему тезаурусу.
Рисунок 2. Методы коррекции частного
тезауруса.
Значения величин, максимально допустимой длины пути
, связывающего семантически далекие подграфы частного тезауруса, и коэффициент
отношения количества отрезаемых узлов частного тезауруса к их общему количеству
, являются критериями целесообразности построения по текстовому материалу гипертекстовой
системы тезаурусным методом. Значения этих коэффициентов могут быть выявлены
только в результате накопления опыта практического использования данного метода
путем статистического анализа этих величин либо с помощью некоторых экспертных
оценок. Экспертные оценки данных величин автора методик
.
Таким образом, свойства связанности графа частного тезауруса, полученного на основании исходного текста, позволяют сделать выводы о пригодности источника текста для автоматизации построения гипертекстовой системы тезаурусным методом.
Литература.