А.С.Сигачёв
Модель текста
в виде набора числовых признаков
Введение
В настоящее время всё большее
применение находят интеллектуальные методы анализа текстовой информации:
получение сводной аналитической информации по массиву текстов; поиск целевой информации;
структурирование данных, содержащихся в разрозненном виде в массиве текстов;
автоматическая рубрикация документов; определения авторства или жанра
произведений и многие другие. В основе любой системы анализа документа лежит
определенная модель текста, совокупность характеристик документа, которые учитываются
системой при его обработке.
Под моделью текста понимается
его приближённое описание, выраженное с помощью математической символики.
Модель всегда проще самого текста, отражает лишь некоторые его свойства, стремиться
выделить главное, не отвлекаясь на детали. Наиболее распространенной моделью
является представление текста в виде набора числовых признаков, т. к.
подавляющее большинство алгоритмов обработки текста является числовыми [Кириченко К.М]
В прикладных областях
используются различные методики построения числовых моделей, однако можно
выделить несколько наиболее характерных подходов, которые следует принять во
внимание при разработке методики обработки текстовой информации в новой предметной
области.
В данной статье рассматриваются
используемые в настоящее время методы представления текстов различных типов в
виде набора числовых признаков, приводятся ссылки на работы посвящённые исследованию
их эффективности. За рамками обзора остаются модели структурированного текста
основанные на формализме регулярных выражений и контекстно-свободных грамматик; сложные ресурсоёмкие модели оперирующие
синтаксическими деревьями, семантическими сетями.
Информация о документе
Для построения модели текста
можно использовать разные виды информации о тексте, принято выделять два
основных вида такой информации: атрибуты, связанные с текстом и атрибуты не связанные
с текстом. К первым можно отнести [М. В. Губин]
1.
Частотные
характеристики элементов текста, в простейшем случае наличие или отсутствие в
тексте слов из некоторого списка.
2.
Взаимное
положение слов в документе. Слова располагаются в определенном порядке,
формируя группы и предложения. Их взаимное расположение, очевидно, содержит
некоторую информацию.
3.
Форматирование
текста документа. Текст, при подготовке для публикации, как правило, некоторым
образом оформляется. Отдельные слова, предложения или абзацы могут выделяться
шрифтом или положением, что может быть учтено.
4.
Логическая
структура текста документа. Текст обычно разделяется на разделы, главы, параграфы,
абзацы. Данное деление отражает смысл документа и поэтому может быть полезно
при его обработке.
5.
Ссылки на другие
документы. Документы часто содержат упоминания других документов, например, в
виде гипертекстовых ссылок или библиографических списков.
К атрибутам не связанным с
текстом, другими словами, метаинформации, относятся: информация об источнике,
авторе; время создания и модификации документа; тематическая рубрикация; поведение пользователя по отношению к
документу, например, частота обращений к документу и т. п.
В данной работе внимание,
главным образом, уделяется частотным характеристикам элементов текста,
рассматривается вопрос учёта взаимного положения слов.
Однородные признаки
Традиционным подходом
считается представление текста гистограммой наблюдаемых однородных признаков —
например, вектором количеств вхождений ключевых слов в документ [G. Salton]. В этом случае
ведётся словарь терминов, общий для всех анализируемых документов. Каждый
документ представляется в виде вектора, элементы которого представляют собой
число, определяющее количество появлений соответствующего термина из словаря в
документе. Размерность такого вектора очень велика и соответствует общему
количеству слов в словаре.
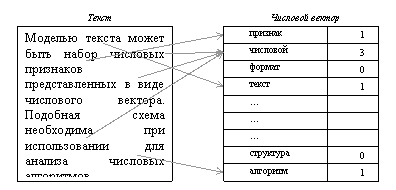

Пример простейшей векторной модели
представления текста.
В общем случае можно говорить
об элементе документа, служащим основой вектора, и важности, или информативном
весе, этого элемента. Вес элемента является безразмерной величиной, для удобства
обработки обычно нормируется. Для некоторых прикладных задач, например при
кластеризации текстов, вводится метрика близости между векторами признаков.
Элементом анализируемого
текста может быть [Ciya Liao, Цыганов И. Г.]: короткая последовательность букв (например, двухбуквенная
комбинация); слоги; слова; слова, приведённые к нормальной форме;
словосочетания.
За основу веса элемента
обычно берут какие-либо статистические характеристики его появления в тексте
документа, а в качестве модификаторов веса могут выступать коэффициенты, учитывающие оформление
элемента и его положение в документе.
Подобные модели находят своё
применение в системах автоматической рубрикации текстов, методах повышения
релевантности результатов поиска в поисковых системах, системах автореферирования
— всех тех системах, где одним из этапов является выделение из множества всех
слов документа набора наиболее характерных, отражающих основной смысл текста
слов.
Модель «множество слов».
Модель «множество слов» (англ. bag-of-words) была предложена в
1975 году [Солтон Дж.], и в настоящее время является одной из самых распространённых.
Согласно данной модели текст представляется как набор слов, без учёта порядка
их следования.
Для каждого слова из набора
указывается некоторый «вес». Таким образом, модель документа представляет собой
множество пар «слово — вес». При этом веса могут присваиваться словам или основам
слов.
Наиболее распространёнными
методами определения веса являются [М. В. Губин, М.В.Киселев, Ciya Liao]:
Бинарный метод
(распространённое обозначение — BI, от англ.
binary). Определяется только наличие или отсутствие некоторых терминов в документе. Применим для
логического информационного поиска. В работе [Андреев А.М.]
Количество вхождений слова в документ. Если слово чаще содержится в тексте документа, то, скорее
всего, этот документ более связан по смыслу с этим термином. Недостатком метода
оценки является несоразмерность оценки для документов разной длины — больший
вес будут получать более длинные документы, так как в них больше слов;
Частота появления слова в документе (TF — term frequency). Частота вычисляется как
отношение числа вхождения слова к общему количеству слов документа. При
относительной простоте эта характеристика обеспечивает приемлемый результат для
методов информационного поиска и классификации.
Недостатком является то, что в данном случае, наоборот, недооцениваются
длинные документы, так как в них больше слов и средняя частота слов в тексте
ниже.
Логарифм частоты вхождения слова (LOGTF). В данном случае вес входящего в текст
документа определяется как 1+log(TF), где TF — частота термина. Использование
логарифмической шкалы для назначения информационного веса слова позволяет
сделать модель более устойчивой к переоценке документов.
Обратная частота документов (IDF — inverse document frequency). Параметр является
инверсией частоты, с которой встречается термин в документах. ![]()