В данной статье представлен результат использования методики исследования естественно-языкового (ЕЯ) описания произвольной предметной области (ПО).
Применение методики проиллюстрировано на примере конкретной предметной области — автоматизированной системы обработки информации и управления (АСОИУ).
В качестве исходного ЕЯ материала, описывающего указанную ПО, был взят набор статей, опубликованных в журнале “ComputerWeek” №33 за 1995 г. “Computer Week” является печатным изданием, на страницах которого рассматривается широкий спектр вопросов, посвященных аппаратно-программному обеспечению, что в целом позволяет считать этот журнал источником информации, дающим достаточно верное ЕЯ описание АСОИУ.
Ниже приведен перечень этапов исследования ЕЯ описания ПО, осуществляемых в рамках данной методики:
Для проведения частотного анализа ЕЯ описания ПО были выполнены следующие виды работ:
Весь набор предложенных статей журнала “Computer Week” был разбит на четыре группы, исходя из следующего:
При построении частотных словников была выполнена следующая последовательность шагов:
Для упрощения обработки каждого из словников и вычисления ряда частотных характеристик был проведен импорт всех файлов, содержащих словники, в базы данных СУБД Visual FoxPro 3.0 (файлы с расширением *.dbf). С использованием собственных программных модулей для обработки каждой из баз данных были рассчитаны следующие частотные характеристики для каждой из групп и для всего журнала в целом:
В табл. 1 и 2 представлены основные частотные характеристики для базы данных, содержащей словник, построенный для всего журнала.
|
Ранг
слова r |
Абсолютная частота слова i
|
Количество разных слов
|
Общее количество слов
|
Слова–
примеры |
|
1
|
1334
|
1
|
1334
|
"в"
|
|
2
|
1305
|
1
|
1305
|
"и"
|
|
3
|
676
|
1
|
676
|
"на"
|
|
...
|
...
|
...
|
...
|
...
|
|
11
|
218
|
1
|
218
|
"доступ"
|
|
…
|
…
|
…
|
…
|
…
|
|
101
|
4
|
437
|
1748
|
"языков"
|
|
r
|
i
|
i/k
|
log (i/k)
|
log r
|
1/(10*r)
|
log (1/(10*r))
|
|
1
|
1334
|
0,029949
|
– 1,523614
|
0,000000
|
0,100000
|
– 1,000000
|
|
2
|
1305
|
0,029298
|
– 1,533159
|
0,301030
|
0,050000
|
– 1,301030
|
|
3
|
676
|
0,015177
|
– 1,818823
|
0,477121
|
0,033333
|
– 1,477121
|
|
...
|
...
|
...
|
...
|
...
|
...
|
...
|
|
11
|
218
|
0,004894
|
– 2,310313
|
1,041393
|
0,009091
|
– 2,041393
|
|
…
|
…
|
…
|
…
|
…
|
…
|
…
|
|
101
|
4
|
0,000090
|
– 4,046710
|
2,004321
|
0,000990
|
– 3,004321
|
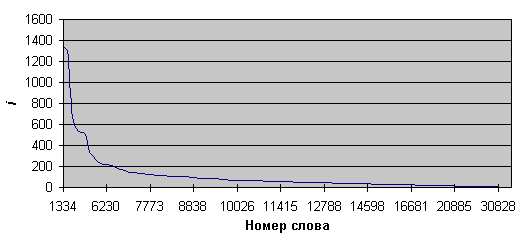
График ступенчатой функции (рис. 1)показывает тенденцию изменения общего количества слов при изменении абсолютной частоты слова со значения 1334 до 1. Зависимость близка к гиперболической.
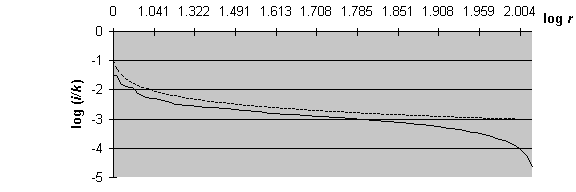
На графике распределения частот слов (рис.
2) представлен график закона Ципфа, изображенный штриховой
линией. При анализе поведения графика зависимости logr от logi/k)
и графика закона Ципфа ![]() нетрудно
заметить, что данный закон описывает значения для i/k достаточно хорошо
лишь на средних частотах. График ступенчатой функции и график распределения
частот слов были построены с использованием Microsoft Excel 7.0.
нетрудно
заметить, что данный закон описывает значения для i/k достаточно хорошо
лишь на средних частотах. График ступенчатой функции и график распределения
частот слов были построены с использованием Microsoft Excel 7.0.
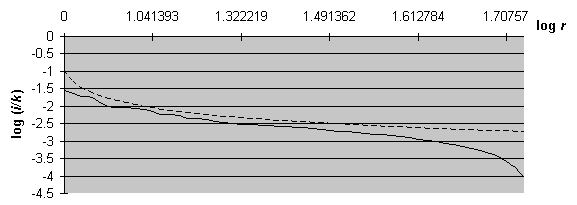
Графики распределения частот слов для каждой из групп похожи друг на друга, поэтому для наглядности представим на рис. 3 графики только для группы 1.
На представленном рисунке график закона Ципфа изображен в виде штриховой линии.
Как и для случая с графиком распределения частот слов для всего журнала, на
приведенном графике закон Ципфа описывает значения для i/k достаточно
хорошо лишь на средних частотах. Семейство графиков распределения частот слов
для групп было построено с использованием Microsoft Excel 7.0.
Для проведения исследования динамических характеристик ЕЯ описания ПО необходимо выполнить следующие работы:
Используя разбиение всего набора статей на отдельные группы, на данном этапе весь журнал был разделен на четыре текстовых фрагмента следующим образом:
T1 = t1;
T2 = t1 + t2;
T3 = t1 + t2 + t3;
T4 = t1 + t2 + t3 + t4,
где t1–t4 — группы текстов, полученные на первом этапе исследовательской работы.
С использованием программы Dialex по каждому из текстовых фрагментов были построены частотные словники. Для этого были созданы соответствующие групповые файлы с расширением *.grp : context1.grp, context2.grp, context3.grp, context4.grp, содержащие полный набор путей для каждого из фрагментов. Фактически, необходимо было правильным образом объединить групповые файлы, полученные на этапе 1.1. При построении словников были использованы те же самые параметры, что и на этапе 1.2. В результате были получены файлы частотных словников с расширением *.tw : context1.tw, context2.tw, context3.tw, context4.tw, которые были импортированы в отдельные базы данных СУБД Visual FoxPro 3.0 для их дальнейшей обработки в рамках данного пункта исследовательской работы. Все слова для каждого их фрагментов были условно разбиты на три частотные группы:
С использованием SQL–запросов СУБД Visual FoxPro была составлена табл. 3 для анализа фрагментной структуры текста, в которой приведены следующие параметры:
|
k
|
i
|
T1
|
T2
|
T3
|
T4
|
|
1
|
1
|
2754
0,24 |
4551
0,2 |
5924
0,18 |
7440
0,17 |
|
2
|
2...6
|
3191
0,29 |
5904
0,26 |
8333
0,25 |
10705
0,24 |
|
3
|
>6
|
5364
0,47 |
11982 0,54
|
19289 0,57
|
26397
0,59 |
|
|
е
|
11309
0,25
|
22437
0,5 |
33546
0,75
|
44542
1 |
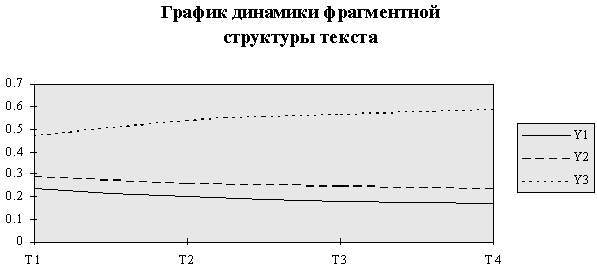
Анализируя данные, представленные в табл. 3, можно сделать вывод о том, что с увеличение размера текстового фрагмента темп роста высокочастотных слов над низкочастотными словами начинает значительно преобладать.
График, демонстрирующий динамику фрагментной структуры текста, представлен на рис. 4. Для всех частотных групп в приведенных на рис. 4 графиках использовалось свое условное обозначение:
С использованием SQL–запросов СУБД Visual FoxPro была составлена табл. 4 для анализа фрагментной структуры словника, в которой приведены следующие параметры:
|
k
|
i
|
S1
|
S2
|
S3
|
S4
|
|
1
|
1
|
2754
0,67 |
4551
0,64 |
5924
0,62 |
7440
0,61 |
|
2
|
2...6
|
1112
0,27 |
2064
0,29 |
2856
0,3 |
3662
0,3 |
|
3
|
>6
|
268
0,06 |
549
0,07 |
804
0,08 |
1065
0,09 |
|
е
|
4134
1 |
7164
1 |
9584
1 |
12167
1 |
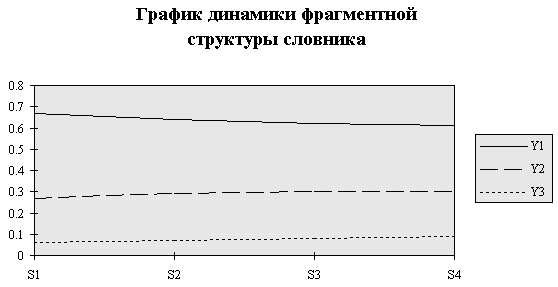
Анализируя динамику фрагментной структуры словника, можно сделать вывод, что темп роста низкочастотных слов снижается, а высокочастотных — возрастает. Это свидетельствует о том, что по мере приближения к концу журнала новая терминология используется в меньшей степени и читатель в основном встречается с общеупотребительной лексикой.
График, демонстрирующий динамику изменения фрагментной структуры словника, представлен на рис.5.
С использованием SQL–запросов СУБД Visual FoxPro была составлена табл. 5 для анализа фрагментного содержания словника, в которой приведены следующие параметры:
|
k
|
i
|
S1
|
S2
|
S3
|
S4
|
|
1
|
1
|
2754
0,37 |
4551
0,61 |
5924
0,8 |
7440
1 |
|
2
|
2...6
|
1112
0,3 |
2064
0,56 |
2856
0,78 |
3662
1 |
|
3
|
>6
|
268
0,25 |
549
0,52 |
804
0,75 |
1065
1 |
|
е
|
4134
0,34 |
7164
0,59 |
9584
0,79 |
12167
1 |
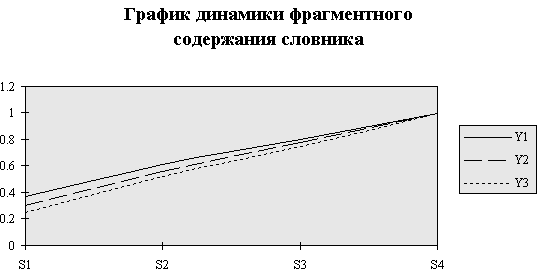
Анализируя динамику фрагментного содержания словника, можно сделать вывод о том, что с добавлением в текстовый фрагмент новой статьи увеличивается количество как низкочастотных, так и высокочастотных слов, т.е. с добавлением новой статьи вводится новая терминология и возрастает доля общеупотребительной лексики. При этом содержание словника изменяется равномерно.
График, демонстрирующий динамику изменения фрагментного содержания словника, представлен на рис. 6.
С использованием SQL–запросов СУБД Visual FoxPro была составлена табл. 6 для анализа полноты частотных групп, в которой приведены следующие параметры:
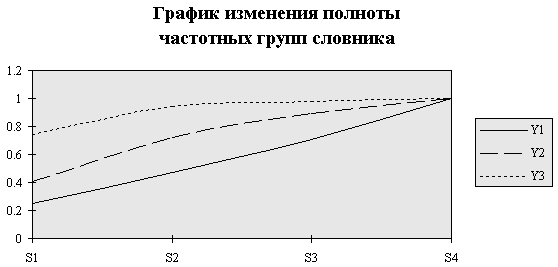
Анализируя данные этой таблицы, можно заключить, что запас высокочастотных слов практически исчерпывает себя уже на третьем фрагменте (0,98), а дальнейшее увеличение числа статей в текстовом фрагменте практически связано только с добавлением низкочастотных слов (новой терминологии). Это можно объяснить тем, что выборка сделана не случайная, а тематическая. Наиболее точно заполнение частотных групп можно было бы показать, если бы выбрали больше текстовых фрагментов, например 7 или 8.
|
k
|
i
|
S1
|
S2
|
S3
|
S4
|
|
1
|
1
|
1836
0,25 |
3505
0,47 |
5272
0,71 |
7440
1 |
|
2
|
2... 6
|
1508
0,41 |
2653
0,72 |
3271
0,89 |
3662
1 |
|
3
|
>6
|
790
0,74 |
1006
0,94 |
1041
0,98 |
1065
1 |
|
е
|
4134
0,33 |
7164
0,59 |
9584
0,79 |
12167
1 |
График, демонстрирующий динамику изменения полноты частотных групп словника, представлен на рис. 7.
“Цена” слова определяется по формуле:
|
“Цена” слова = Число слов / Число новых слов.
|
“Стоимостные” параметры словника приведены ниже:
|
Число новых слов
|
4134
|
3030
|
2420
|
2583
|
|
Число слов
|
11309
|
11128
|
11109
|
10996
|
|
“Цена” слова
|
2,7
|
3,67
|
4,59
|
4,26
|
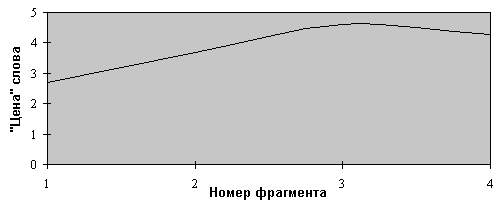
Видно, что наблюдается тенденция увеличения “стоимости” нового слова. Это означает, что с увеличением количества статей в текстовом фрагменте число новых слов снижается (возрастает “цена” за новое слово). То есть во всех текстовых фрагментах используется практически одинаковая лексика, за исключением специфичной терминологии, которая характерна для отдельных областей вычислительной техники (например, объектно-ориентированные языки программирования и компьютерные сети). График изменения “стоимостных” параметров словника представлен на рис. 8.
Для построения предметного указателя необходимо было отобрать 100 основных терминов и понятий, соответствующих ПО. В указатель должны входить сведения об имени файла и номере строки от начала текста.
Для построения именного указателя ЕЯ описания ПО необходимо было предварительно отобрать все имена собственные, которые встречаются в предложенных статьях журнала “Computer Week”.
Для корректного решения данного задания была проделана следующая работа:
1. Формирование двух файлов поисковых запросов для построения именного и предметного указателей.
Для этого из текстовых файлов каждой статьи были отобраны все имена собственные (имена, фамилии людей, названия фирм, названия программных продуктов, географические названия и т.п.) для построения именного указателя и порядка 150 понятий и словосочетаний, относящихся к ПО, для построения предметного указателя. Файлами поисковых запросов являются — pointname.pwl и pointobj.pwl для построения именного и предметного указателей соответственно.
2. Формирование исходного текстового файла.
Все предложенные текстовые файлы статей журнала были объединены в один текстовый файл sum.txt. Перед началом каждой статьи была проставлена ссылка следующего вида:
/<Имя файла><Номер страницы>,
где <Имя файла> — имя файла статьи журнала; <Номер страницы>— номер страницы журнала, где размещается данная статья. Включение номера страницы, где размещается данная статья в журнале, сделано на тот случай, если при работе с именным или предметным указателем потребуется обратиться к журналу.
Также в текстовом файле sum.txt были удалены все слэши (символ “ / ”) во избежание получения неправильной ссылки в предметном или именном указателе.
3. Формирование именного и предметного указателей с использованием системы Dialex.
При построении указателей с использование системы Dialex необходимо было задать исходный текстовый файл (sum.txt) и файл с поисковыми запросами (ponintnam.pwl или pointobj.pwl), а также такие параметры, как адресация (страницы, абзацы, строки), сравнение (по основе), формат ASCII, абзацный отступ. Построенные именной и предметный указатели представлены в файлах — nam_poin.lst и obj_poin.lst. Ниже приведены фрагменты этих указателей.
Фрагмент именного указателя:
Фрагмент предметного указателя:
Индексирование текстовых фрагментов (статей) журнала проводилось на основе анализа каждой статьи. После внимательного прочтения каждой статьи осуществлялся выбор 15–20 ключевых слов, словосочетаний, аббревиатур, имен. В результате были составлены поисковые образы для каждой статьи. Индекс представлен в виде таблицы, которая содержит следующие поля: имя файла статьи, заголовок статьи, ключевые слова (табл. 7).
|
Имя файла статьи
|
Заголовок
|
Ключевые слова
|
|
4gl.txt
|
Языки четвертого поколения становятся привычным инструментом
|
Средства разработки приложений, языки четвертого поколения,
Neuron Data, Trinzic, InSync Software, JYACC, Magic Software, инструментальные
средства, Visual Basic, PowerBuilder, Powersoft, SQLWindows, Gupta, платформы,
RAD, графический интерфейс пользователя
|
|
apps.txt
|
Windows 95 и специальные приложения
|
Windows 95, Microsoft, приложения, инструменты визуального
программирования, PowerBuilder, Visual Basic, SQLWindows, специализированный
код, С, С++, компоненты, библиотеки, независимые разработчики, устаревшие
программы, Windows 3.1, несовместимый, VBX
|
Целью данного этапа исследовательской работы является построение “словаря словосочетаний” и “словаря контекстов” для понятий, вошедших в предметный указатель.
Порядок построения словаря словосочетаний
“Словарь словосочетаний” должен включать все устойчивые словосочетания, вошедшие в предметный указатель, созданный на третьем этапе курсовой работы. “Словарь словосочетаний” имеет следующую структуру словарной статьи (ниже приведена запись структуры на языке Бекуса–Наура):
<лемма>где <лемма>— слово в основной форме из предметного указателя; <словосочетание> — двух-, трехсловное словосочетание из предметного указателя, являющееся термином или основным понятием ЕЯ описания ПО.
Фрагмент “Словаря словосочетаний” представлен в табл. 8. Общее количество устойчивых словосочетаний, вошедших в словарь, составляет 67, т.е. это примерно 46% от общего количества терминов и понятий, которые вошли в предметный указатель. При этом 58 словосочетаний связаны между собой лингвистическим отношением существительное – прилагательное (например, оперативная память) и только 9 словосочетаний отношением существительное – существительное (например, целостность данных).
| аппарат | факсимильный аппарат |
| графика | компьютерная графика, трехмерная графика |
| данные | базы данных, тиражирование данных, целостность данных, шифрование данных |
| диск | жесткий диск, оптический диск |
| игра | компьютерная игра |
Порядок составления словаря контекстов
Конкорданс ЕЯ описания ПО должен быть представлен
в виде словаря контекстов, имеющего следующую структуру словарной статьи:
|
< лемма /словосочетание> < контекст><
адрес>,
|
где < контекст >— ближайшее “окружение” словоформы или словосочетания, размер которого в большинстве случаев ограничен предложением (количество контекстов для одной леммы должно быть от трех до пяти, а для словосочетаний достаточно одного); < адрес >— указание на источник контекста — фрагмент текста (имя файла статьи, номер страницы, номер абзаца и номер строки от начала страницы).
Для конкорданса ЕЯ описания ПО был использован программный продукт Dialex. В качестве исходного текстового файла был использован файл sum.txt, а в качестве файла для организации поисковых запросов — файл objpoin.pwl. При построении конкорданса были установлены следующие параметры: адресация (страница, абзац, строка), формат (ASCII), сравнение (по основе слова); размер контекста был ограничен шестью предложениями. После обработки файла sum.txt с использованием системы Dialex был получен файл конкорданса sum_poin.set. В дальнейшем этот файл был обработан с помощью текстового редактора Microsoft Word 7.0. Целью данной обработки являлось установление оптимального количества предложений (в большинстве случаев одного) для каждого из терминов предметного указателя, чтобы было понятно в каком контексте употребляется данный термин. Небольшой фрагмент сформированного конкорданса представлен ниже.
Фрагмент словаря контекстов:
Кроме того, RISC–архитектура предлагает освоение следующего уровня параллелизма — одновременное исполнение множества операций с использованием концепции широкой команды VLIW (Very Long Instruction Word). В этом направлении ведутся совместные разработки Sun Microsystems и московского Центра SPARC–технологий, а также проект Intel и Hewlett–Packard по созданию процессора P7, который должен быть завершен в 1997 г. (risc 50.4.97)
При желании можно представить себе не один десяток программ, для которых RISC–архитектура просто противопоказана, и еще больше приложений, выполняемых CISC– и RISC–компьютерами с примерно равной скоростью. (risc 50.8.5)
Целью данного этапа исследовательской работы является составление словаря определений для понятий, относящихся к ПО. В начале была детально проработана и определена структура словарной статьи с использованием языка Бекуса–Наура.
Словарная статья определений терминов ПО включает следующие сведения: лемма/словосочетание, морфологическая информация, частотная информация, варианты определений (толкований), устойчивые словосочетания и эксцерпции (примеры контекстов из текстов ЕЯ описания ПО с указанием их источника).
За элементарную единицу словарной статьи был принят символ. На основе символа были разработаны следующие основные понятия:
Структура словарной статьи имеет следующий вид:
<cловарная статья> := <лемма /словосочетание> <пробел> <морфологическая информация> <пробел><частотная информация><перевод строки> <толкование><перевод строки ><примеры контекстов>После формирования структуры словарной статьи на ее базе был построен словарь определений. Основные структурные элементы словарной статьи:
Для словосочетаний морфологическая информация опускалась.
При построении словаря определений все толкования были взяты из следующих источников:
Фрагмент словаря определений для терминов ПО приведен ниже:
RISC–архитектура {ж} [3]
(Reduced instruction set computing) — микропроцессор с сокращенным набором
команд;
тип конструкции микропроцессора, нацеленного на быструю и эффективную обработку
небольшого набора команд.
Кроме того, RISC–архитектура предлагает освоение следующего уровня параллелизма — одновременное исполнение множества операций с использованием концепции широкой команды VLIW (Very Long Instruction Word). В этом направлении ведутся совместные разработки Sun Microsystems и московского Центра SPARC–технологий, а также проект Intel и Hewlett–Packard по созданию процессора P7, который должен быть завершен в 1997 г.(risc 50.4.97)
объектно-ориентированный подход [1]
парадигма программирования, в которой программа рассматривается как набор дискретных объектов, содержащих, в свою очередь, наборы структур данных и процедур, взаимодействующих с другими объектами. Класс определяет структуры данных и подпрограммы объекта; объект — образец класса, используемый как переменная в программе.
Объектно-ориентированный подход в новой версии языка также получил значительное развитие. Перечислим основные новшества. Во-первых, введено понятие класса, семантически близкое тому, которое использовано в языке Smalltalk. (delphi 32.8.11)
При составлении информационно-поискового терминологического тезауруса ЕЯ описания ПО были рассмотрены два вида отношений: лингвистические и экстралингвистические.
При рассмотрении лингвистических отношений были выбраны следующие виды отношений:
Для каждого вида отношений представим по пять примеров, взятых из статей журнала:
а) примеры синонимии:
емкость — объем;б) примеры антонимии:
быстрее — медленнее;в) примеры сокращений:
г. — город;г) примеры аббревиации:
OLE — Object Linking and Embedding;При рассмотрении экстралингвистических отношений были выбраны следующие виды отношений:
Для каждого вида отношений приведем по пять примеров, взятых из статей журнала:
а) класс–подкласс:
диск — магнитооптический диск;б) род–вид:
CISC–процессор — Intel Pentium;в) временные отношения:
DB2 — DB2/6000;База данных информационно-поискового тезауруса ЕЯ описания ПО представляет собой таблицу отношений между понятиями, состоящую из полей отношений для i-го и j-го понятий. Для каждого вида отношений была разработана своя собственная база данных.
Все базы данных имеют идентичную структуру:
|
Word1
|
Word2
|
Relation
|
|
C(32)
|
C(32)
|
C(2)
|
где Word1 — поле размером 32 символа для i-го понятия; Word2 — поле размером 32 символа для j-го понятия; Relation — поле размером 2 символа для хранения вида отношения.
Для обозначения вида отношения были использованы следующие обозначения:
| СИ — синонимия; | РВ — род–вид; |
| АН — антонимия; | КП — класс–подкласс; |
| СК — сокращение; | ВР — временное отношение. |
| АБ — аббревиация; |
Все файлы отношений были представлены в виде dbf-файлов:
synom.dbf — база данных для отношения вида синонимия;
anton.dbf — база данных для отношения вида антонимия;
abbrev.dbf — база данных для отношения вида аббревиация;
short.dbf — база данных для отношения вида сокращение;
class_pc.dbf — база данных для отношения вида класс–подкласс;
rod_vid.dbf — база данных для отношения вида род–вид;
time.dbf — база данных для отношения вида временное отношение.
В статье была использована следующая литература: Филиппович, лек.1; ТолСловарь, 1995; ТолСловарь, 1989; Dialex, 1996; LemmaLex, 1996; Докум. 3, 4, 8, 9.
Данная статья представляет собой сокращенный вариант курсовой работы по дисциплине "Интеграция программного обеспечения АСОИУ", выполненной ее авторами в 1996 г.