Типичная ЭС состоит из следующих компонентов:
База данных хранит исходные и промежуточные данные решаемой в текущий момент задачи.
База знаний предназначена для хранения долгосрочных данных, описывающих рассматриваемую область (а не текущих данных), и правил, описывающих целесообразные преобразования данных в этой области.
Решатель, используя исходные данные из РП и знания из БЗ, формирует такую последовательность правил, которые, будучи примененными к исходным данным, приводят к решению задачи.
Компонент приобретения знаний автоматизирует процесс наполнения ЭС знаниями, осуществляемый пользователем-экспертом, а также формирует знания на основе анализа прикладных ситуаций. Важной составляющей компонента приобретения знаний является интеллектуальный редактор базы знаний.
Объяснительный компонент объясняет, как система получила решение задачи (или почему она не получила решения) и какие знания она при этом использовала, что облегчает эксперту тестирование системы и повышает доверие пользователя к полученному результату.
Диалоговый компонент ориентирован на организацию дружелюбного общения со всеми категориями пользователей как в ходе решения задачи, так и приобретения знаний, объяснения результатов работы.
Экспертные системы как любой сложный объект можно определить только совокупностью характеристик. Рассмотрим классификацию ЭС по следующим признакам:
Все рассмотренные типы ЭС могут быть объединены в две группы — ЭС синтеза и анализа. Принципиальное их отличие состоит в том, что для систем анализа пространство решений детерминировано и ограничено определенным заранее множеством. Для систем синтеза множество решений потенциально, решение строится (конструируется) в процессе рассуждений.
К системам анализа относятся системы интерпретации, диагностики.
К системам синтеза — проектирования, планирования.
К комбинированным системам относятся ЭС обучения, мониторинга, прогнозирования.
В литературе можно также найти классификацию по назначению, проблемной области, глубине анализа проблемной области, по типу используемых методов и знаний, по классу системы, по стадиям существования, по инструментальным средствам.
По степени сложности структуры ЭС делят на поверхностные и глубинные. Поверхностные ЭС представляют знания об области экспертизы в виде правил (условие - действие). Условие каждого правила определяет образец некоторой ситуации, при соблюдении которой правило может быть выполнено. Поиск решения состоит в выполнении тех правил, образцы которых сопоставляются с текущими данными (текущей ситуацией в РП). При этом предполагается, что в процессе поиска решения последовательность формируемых таким образом ситуаций не оборвется до получения решения. Глубинные ЭС, кроме возможностей поверхностных систем, обладают способностью при возникновении неизвестной ситуации определять с помощью некоторых общих принципов, справедливых для области экспертизы, какие действия следует выполнить.
Можно выделить три поколения ЭС. К первому поколению относятся автономные поверхностные ЭС, ко второму — статические глубинные ЭС (сюда же, как правило относят гибридные ЭС), к третьему — динамические ЭС (вероятно, они будут глубинными и гибридными).
В последнее время выделяют два больших класса ЭС: простые и сложные. Простая ЭС может быть охарактеризована следующим набором основных параметров: поверхностная ЭС, автономная ЭС (реже гибридная), выполненная на ПЭВМ; коммерческая стоимость от 100 до 25.000 дол.; стоимость разработки от 50 тыс. до 300 тыс. дол.; время разработки от 3 мес. до 1 года (при развитых ИС); от 200 до 1000 правил. Сложная ЭС характеризуется таким набором параметров: глубинная ЭС, гибридная ЭС, выполненная либо на символьной ЭВМ, либо на мощной универсальной ЭВМ, либо на интеллектуальной рабочей станции; коммерческая стоимость от 50 тыс. до 1 млн. дол.; средняя стоимость разработки 5-10 млн. дол.; время разработки от 1 до 5 лет; от 1500 до 10 тыс. правил.
Выделяют следующие стадии существования ЭС:
На проектирование и создание одной ЭС ранее требовалось 20–30 чел.-лет. В настоящее время имеется ряд средств, ускоряющих создание. Эти средства называют инструментальными средствами (ИС). Использование ИС в настоящее время сокращает время разработки в 3–5 раз.
В широком толковании в инструментарий включают и аппаратные средства. ЭС выполняют на следующих типах ЭВМ: общего назначения, ПЭВМ, интеллектуальных рабочих станциях (типа Sun, Appolo и др., снабженных эффективными ИС для создания ЭС); последовательных символьных ЭВМ типа ЛИСП-машин (Symbolic-3670, Alpha, Explorer, Xerox 1100 и др.) и Пролог-машин; параллельных символьных ЭВМ (Connection, Dado, Faim, Hyper Cube и др.).
Программные ИС классифицируют по нескольким признакам.
По типу ИС делят на:
В приведенной классификации ИС перечислены в порядке убывания трудозатрат, необходимых на создание с их помощью конкретной ЭС. При использовании ЭС первого уровня в задачу разработчика входит программирование всех компонентов ЭС на языке сравнительно низкого уровня. Использование ИС второго типа позволяет значительно повысить уровень языка, что, как правило, приводит к некоторому снижению эффективности. Инструментальные средства третьего уровня позволяют разработчику не программировать все или часть компонентов ЭС, а выбирать их из заранее приготовленного набора. При применении ИС четвертого типа разработчик ЭС полностью освобождается от работ по созданию программ, так как берет готовую пустую ЭС.
При использовании ЭС третьего и четвертого типов могут возникнуть следующие проблемы: управляющие стратегии, вложенные в процедуру вывода ИС, могут не соответствовать методам решения, которые использует эксперт, взаимодействующий с данной ЭС, что может приводить к неэффективным, а возможно и неправильным решениям; язык представления знаний, принятый в ИС, может не подходить для данного приложения.
Развитие систем, автоматизирующих разработку ЭС, приводит к появлению ИС, которые можно назвать настраиваемыми оболочками. Эти ИС позволяют разработчику использовать оболочку не просто как нечто неизменное (как имело место раньше в EMYCIN, KAS), а генерировать оболочку из множества механизмов, имеющихся в ИС. Типичными примерами таких ИС являются Image Expert, KEE, ART, ЭКСПЕРТИЗА, ГЛОБ.
Универсальность задается совокупностью двух параметров: универсальностью представления знаний и универсальностью функционирования. Универсальность представления характеризует способ (модель) представления знаний в ИС и принимает следующие значения: единое представление — ИС использует одну модель, интегральное представление — ИС допускает интегральное использование нескольких моделей, универсальное представление — ИС допускает интегральное использование всех основных моделей представления. Примерами ИС, в которых используются: единое представление, является Пролог, интегральное представление — Image Expert, CENTAUR, а универсальное — KEE, ART.
К основным моделям представления знаний относятся:
В основе моделей такого типа лежит формальная система, задаваемая четверкой вида:
М = <Т, Р, А, В>.
Множество Т есть множество базовых элементов различной природы, например слов из некоторого ограниченного словаря, деталей детского конструктора, входящих в состав некоего набора и т.п.
Для множества Т существует некоторый способ определения принадлежности или непринадлежности произвольного элемента этому множеству. Процедура такой проверки может быть любой, но за конечное число шагов она должна давать положительный или отрицательный ответ на вопрос, является ли х элементом множества Т. Обозначим эту процедуру П(Т).
Множество Р есть множество синтаксических правил. Они определяют способ образования из элементов Т правильных совокупностей. Декларируется существование процедуры П(Т), которая дает ответ на вопрос, является ли Х синтаксически правильной совокупностью.
В множестве синтаксически правильных совокупностей выделяется подмножество аксиом А. Как и для других составляющих, должна существовать процедура П(А), которая определит принадлежность синтаксически правильной совокупности множеству А.
Множество В есть множество правил вывода. Применяя их к аксиомам, можно получать новые синтаксически правильные совокупности, к которым опять можно применять правила В.
Формируется множество выводимых в данной системе совокупностей. Если имеется процедура П(В), с помощью которой можно определить для любой синтаксически правильной совокупности, является ли она выводимой, то соответствующая формальная система является разрешимой.
Для знаний, входящих в базу знаний, можно считать, что множество А образуют все информационные единицы, которые введены в базу знаний извне, а с помощью правил вывода из них выводятся производные знания. Формальная система есть генератор порождения новых знаний, образующих множество выводимых в данной системе знаний. Это свойство позволяет хранить в базе лишь те знания, которые образуют подмножество А, а все остальные получать из них по правилам вывода.
В основе сетевых моделей этого типа лежит конструкция, названная семантической сетью. Сетевые модели формально можно задать в виде:
Н =< I, C1, C2,..., Cn, Г>.
Здесь I есть множество информационных единиц, C1, C2,... — множество типов связей между информационными единицами. Отображение Г задает между информационными единицами, входящими в I, связи из заданного набора типов связей.
В зависимости от типов связей, используемых в моделях, различают классифицирующие сети, функциональные сети и сценарии. В классифицирующих сетях используется отношение структуризации.
Такие сети позволяют в базах знаний вводить иерархические отношения между информационными единицами. Функциональные сети часто называют вычислительными моделями, так как они позволяют описывать процедуры “вычислений” одних информационных единиц через другие. В сценариях используются каузальные отношения, а также отношения типа “средство-результат”, “орудие-действие”. Если в сетевой модели допускаются связи различного типа, ее называют семантической сетью.
В моделях этого типа используются некоторые элементы логических и сетевых моделей. Из логических моделей заимствована идея правил вывода, которые называются продукциями, а из сетевых — описание знаний в виде семантической сети. В результате применения правил вывода к фрагментам сетевого описания происходит трансформация семантической сети за счет смены ее фрагментов, наращивания сети и исключения из нее ненужных фрагментов. Таким образом, в продукционных моделях процедурная информация явно выделена и описывается иными средствами, чем декларативная. Вместо логического вывода, характерного для логических моделей, в продукционных моделях появляется вывод на знаниях.
Отличие фреймовых моделей в том, что в них фиксируется жесткая структура информационных единиц, которая называется протофреймом. В состав протофрейма входят несколько слотов, имеющих определенные значения. Значением слота могут быть любые данные (числа, соотношения, тексты, ссылки на другие слоты). В качестве значения слота может выступать набор слотов более низкого уровня (иерархия).
При конкретизации фрейма происходит присвоение ему и его слотам конкретных имен и происходит заполнение слотов. На этом этапе из протофреймов получаются фреймы — экземпляры. Переход от протофрейма к экземпляру может быть пошаговым, путем последовательного уточнения значений слотов.
Связи между фреймами задаются с помощью специального слота с именем СВЯЗЬ.
Рассмотрим некоторые наиболее популярные ЭС, оказавшие наибольшее воздействие на создание других экспертных и инструментальных систем. Среди систем расширения знаний наиболее значительны PROSPECTOR, MYCIN и R1. Методы решения задач, разработанные при создании системы PROSPECTOR, легли в основу таких ИС, как KAS, SAGE, MICRO-EXPERT, SAVOIR. На основе системы MYCIN созданы ИС EMYCIN, S1, серия ЭС PUFF, SACON, VM, LIHO, ONCOCYN. Система R1 продемонстрировала возможности чисто продукционного языка OPS для построения как ЭС (XSEL, IDI, YES/MVS, MUD), так и ИС, использующих для представления знаний правила OPS.
Язык OPS имеет множество реализаций: OPS-4, OPS-5, OPS-83.
Основу всех реализаций составляет:
Язык OPS не является завершенным инструментом для создания ЭС, в нем отсутствуют средства объяснения и приобретения знаний, весьма ограничены средства тестирования, он труден для использования непрограммистами. Однако он является одним из самых быстрых ИС и реализован на различных типах ЭВМ. На базе OPS создана ЭС R1, предназначенная для определения конфигурации компонентов ЭВМ VAX 11/780, удовлетворяющей требования заказчика. Система достигла коммерческой стадии, ее объем 3000 правил языка OPS-5. Управление решением задачи осуществляется чисто продукционным способом.
Система PROSPECTOR решает задачи чисто поверхностным образом, не вникая в суть происходящих в проблемной области процессов. Состояние проблемной области описывается в виде утверждений о проблемной области. Решение задачи состоит в изменении априорно установленных оценок “вероятностей” утверждений, которое осуществляется по результатам наблюдений, поставляемых пользователем. Перерасчет оценок происходит на основе формулы Байеса, связывающей апостериорную вероятность гипотезы с ее априорной вероятностью и вероятностью наблюдения. Взаимосвязь гипотез и наблюдений представлена в виде сети, которую можно рассматривать как графическое представление правил. Для представления правил в сети имеются И и ИЛИ вершины, описывающие условия правил. Дополнительно для выражения таксономии имеется семантическая сеть. Во время решения задачи не выводятся новые утверждения о предметной области. Все утверждения должны быть априорно заданы экспертом.
Система MYCIN решает проблемы несколько иначе и не требует фиксированного набора утверждений о проблемной области.
Назначение системы — оказание помощи лечащим врачам при постановке диагноза и назначение лечения в сложных случаях инфекционных заболеваний крови. Система обладает сведениями о возможной структуре проблемной области, конкретизируемой в ходе консультации. В системе знания о предметной области хранятся в виде троек атрибут-объект-значение, снабженных коэффициентом определенности. Тройки группируются по объектам в соответствии с деревом контекстов, задающим возможную иерархию объектов в предметной области. Дерево контекстов используется для управление ходом консультации, создания в рабочей памяти новых объектов, отслеживания иерархических зависимостей между объектами (тройками) и использования их в ходе сопоставления. Система способна давать пояснения, почему требуется запрашиваемая информация и как получен результат. Создание системы MYCIN привело к развитию работы в следующих направлениях:
Экспертная система EL решает задачу доопределения. Она предназначена для вычисления неизвестных параметров электрических цепей по их структуре и значениям известных параметров. Расчеты осуществляются по формулам для линейных элементов. Нелинейные элементы сводятся к линейным методом аппроксимации. Разные участки цепи аппроксимируются разными уравнениями, причем аппроксимирующее уравнение в данной точке неизвестно. Система доопределяет состояние предметной области, выдвигая предположение о том, на каком участке характеристики находится нелинейный элемент, и проводит анализ исходя из этого предположения. Затем предположение проверяется на совместимость с другими параметрами. Выставление и просмотр предположений могут быть полезны не только как средство повышения эффективности решения задачи, но и как удобная форма формализации знаний эксперта, отличных от позитивных знаний, которые традиционно должен вводить эксперт в случае чисто продукционных систем. Для решения задач доопределения в ЭС реализуются системы поддержания истинности, обеспечивающие генерацию предположений, их пересмотр и поддержание непротиворечивости получаемых гипотетических альтернативных миров. Наиболее известные схемы поддержания истинности реализованы в виде систем TMS и ATMS.
Примером ЭС, решающей задачи преобразования, является система VM, предназначенная
для слежения за состоянием послеоперационных больных. Система создана на основе
системы MYCIN и использует частный подход к работе с изменяющимися во времени
данными. Представления системы о времени ограничены лишь текущими и предшествующими
состояниями. Знания в системе представляется в виде следующих типов правил:
перехода, инициализации, состояния, лечения. Система постоянно получает новые
показания приборов и запускает свои правила. Правила перехода определяют моменты
смены состояний больного, когда необходимо изменить порядок слежения за ним.
Моменты смены состояний определяются по выходу показателей за определенные границы.
С помощью правил инициализации устанавливается новый контекст, т.е. новые ожидаемые
значения. После установления контекста правила состояния определяют поведение
системы до тех пор, пока контекст не изменится. Ограниченность такого подхода
состоит в том, что при смене состояний учитывается информация только о двух
смежных состояниях пациента.
Рассмотрим класс интеллектуальных систем, ориентированных на знания. Такого рода системы отличаются тем, что в них упор делается не на данные в их классическом фактуальном представлении, а на знания — т.е. метаданные о характере и связях объектов и явлений какой-либо предметной области. Отметим, что указанное разделение не представляет собой абсолютный критерий классификации, это скорее качественный показатель. Каждая конкретная реализация достаточно мощной ИС содержит как признаки первого, так и второго рода. Однако описанное деление является весьма значимым при проектировании систем вследствие того, что оказывает определяющее воздействие на выбор метода реализации отдельных компонентов — от способа организации данных/знаний до реализации подсистемы пользовательского интерфейса.
Для систем, ориентированных на знания, характерен значительный по объему данных перевес компоненты, отвечающей за хранение правил и соотношений общего порядка. Фактуальная информация (как она представлена в базах данных) в явном виде в таких системах отсутствует. Она представлена неявно в виде уже сформулированных выводов и правил. И хотя практически задача накопления и анализа фактуального материала не выходит за рамки архитектуры этого класса систем, целесообразность такого механизма можно поставить под сомнение в силу следующих обстоятельств. Экспертные системы, содержащие знания специалистов высокого уровня в обслуживаемых предметных областях, в большинстве своем задействуются для анализа нетривиальных ситуаций, имеющих место в данной предметной области. Естественно, что для решения простой или типичной задачи специалист не будет прибегать к услугам ЭС. Таким образом, если и наделить рассматриваемую нами систему аппаратом сбора фактов об обработанных ситуациях и статистического анализа, результатом которого будет являться генерация правил и выводов, то можно с достаточной степенью уверенности предположить, что построенные таким образом модели будут отличаться от моделей, построенных экспертом, ибо он умозрительно включает в рассмотрение все ситуации предметной области, причем в нужных соотношениях частот их повторения.
В течение последних двадцати лет в литературе господствует мнение о том, что оптимальным способом взаимодействия пользователя с интеллектуальными системами является естественный язык, а ограничения, накладываемые на язык взаимодействия человека и компьютерных систем в некоторых реализациях подобного подхода (например, ОЕЯ), воспринимаются как вынужденная мера. Регламентированные языки (языки меню, запросов, форм и шаблонов) трактуются как еще более узкие и изначально ограниченные средства общения. При этом подразумевается, что в любой ситуации общения пользователя с системой ЕЯ обладает преимуществами на том основании, что он является наиболее привычным средством общения для человека. Принимая во внимание, что, по данным психологов, человек до 90% информации принимает по зрительному каналу, отметим, что ЕЯ как средство общения органичен в области коммуникации человека с человеком, а происхождение тезиса о том, что с помощью этого средства можно достичь и наибольшей эффективности при взаимодействии человека с компьютерными системами, явственно просматривается в стане апологетов искусственного интеллекта.
Два способа организации взаимодействия ЭС с пользователем отражают два подхода к разрабатываемым системам. Первый — подход от баз данных, когда основу системы составляет фактуальная информация, организованная и структурированная классическими методами СУБД, а “знаниями” нагружается ИПС, обеспечивающая доступ к БД. Второй — когда основное содержание системы составляют заложенные в нее концептуальные знания, а не чисто информационный набор фактов. На наш взгляд, только в первом случае уместно говорить о естественном языке как о наиболее приемлемом способе общения с системой, поскольку к системе (как к информационно-поисковой) предъявляется требование обработки запросов достаточно большой степени сложности (по совокупности нескольких параметров, с использованием условных конструкций и т.д.), кроме того, как правило, пользователи такого рода систем не обладают достаточным уровнем профессиональной подготовки. К системам другого рода, пользователями которых являются подготовленные специалисты (очевидно не только в своей предметной области, но также имеющие развитые навыки общения с компьютерными информационными системами), предъявляются несколько иные требования. В рассматриваемом классе ориентированных на знания систем (это в большинстве своем ЭС диагностики, анализа ситуации, поддержки принятия решения, мониторинга) на первый план выдвигается удобство и скорость обмена информацией участниками общения. Достаточный объем умолчаний, заранее определенная задача, которая известна участникам до начала процесса коммуникации, делают естественный язык преградой на пути повышения эффективности общения. В данном случае целесообразно использование регламентированных языков, использующих умолчания и соглашения, оперирующих специализированными понятиями, очевидными участникам общения в контексте решаемой ими задачи.
Помимо диалога с ЭС в процессе решения задачи, реализация объяснительной компоненты на регламентированном языке также способна в значительной мере повысить эффективность этой подсистемы. С одной стороны, в настоящее время очевидно, что даже простейшая гипертекстовая организация информации (в данном случае поясняющей компоненты) повышает удобство и значительно увеличивает скорость доступа к информации по сравнению с методом общения на естественном языке. С другой стороны, взаимодействие эксперта с системой в режиме отладки модели на естественном языке будет, мягко говоря, не вполне адекватно, ибо в процессе создания модели они оба уже прошли этап формулирования промежуточных понятий и абстракций, раскрытие которых естественно-языковым представлением повлечет за собой только усложнение (и, по всей видимости, существенное замедление) процесса понимания со стороны эксперта. Хорошо спроектированная интерфейсная компонента, реализованная с помощью регламентированного языка описания объектов и явлений предметной области, способна, на наш взгляд, вывести эксперта за рамки вербального способа представления информации, что во многих случаях повысит эффективность общения пользователя как в режиме консультации (эксплуатации) экспертной системы, так и в режиме наполнения баз знаний и отладки моделей знаний. Удачно подобранные графические образы способны вызывать реакцию пользователя быстрее, чем подробные словесные описания. Кроме того, компактность графического представления позволяет отобразить большее количество сущностей и видов связей между ними на единице экранного пространства, видеоряд активизирует большее количество ассоциативных связей, звуковой вывод позволяет акцентировать внимание на внештатных, аварийных ситуациях, в этих же случаях звуковой канал может служить наиболее приемлемым способом передачи односложной информации в систему.
Однако перечисленные способы представления информации существенно отличаются как по своей физической природе, так и по способам представления и обработки в компьютерных системах. Очевидно, что для разработчика интеллектуальной системы взаимодействия и для пользователя был бы приемлем в достаточной степени прозрачный аппарат описания и манипулирования образами объектов реального мира, представленными в текстовой, графической, динамической, звуковой формах.
Выделим два основных аспекта поставленной таким образом проблемы. Интересной, с одной стороны, представляется задача конструирования и описания интерфейса проектируемых интеллектуальных систем. С другой стороны, рассмотрим методику создания и наполнения такого рода систем и необходимые для этого инструментальные средства для поддержки процессов подготовки и обработки данных различных типов.
Так, к области экспертных систем с определенной степенью приближения можно отнести системы:
Требования к системам представления знаний (в том числе к интерфейсу взаимодействия человека с системой):
Требования к средствам проектирования интерфейса взаимодействия человека с
выделенным классом интеллектуальных систем:
Процесс создания ЭС заключается в описании структуры понятий ПО, выборе модели для представления знаний и формализации знаний с помощью выбранных средств описания (т.е. наполнения БЗ). На выбор типа модели наиболее значимое воздействие оказывают по крайней мере 2 фактора:
Опыт создания ЭС в разных ПО показывает, что часто оказывается целесообразным построение ЭС разных типов в одной ПО. Иными словами, перед разработчиками ЭС встает задача создания разнотипных моделей знаний на едином пространстве понятий и фактов.
Настоящее исследование ставит свой целью исследование и анализ проблем, возникающих при взаимодействии разнотипных моделей знаний, разработку структуры БЗ, ориентированной на поддержку разных моделей, разработку модели общения с различными категориями пользователей ЭС и методов и средств конструирования пользовательского интерфейса.
Для достижения поставленной цели был проведен сравнительный анализ различных моделей знаний. В процессе анализа выделена общая для всех моделей часть — описание понятий и фактов предметной области, которые выделены в инвариантную компоненту БЗ, поддерживающую функционирование моделей разных типов.
База знаний, помимо средств поддержки инвариантной компоненты, содержит средства хранения специфицированных знаний, ориентированных на представление моделей конкретных типов. Это хранение отношений, правил, формул, других специфических объектов, понятий верхнего уровня, присущих данному типу преставления знаний. Структура данных полностью определяется требованиями модели данных. БЗ поддерживает интерфейс между представлением моделей и инвариантными знаниями посредством единого метода сквозной идентификации элементов инвариантной компоненты.
В процессе реализации ЭС в режиме консультации выбор типа модели определяет, какой именно решатель из логической компоненты должен быть активизирован. Совокупность загруженной модели и конкретного решателя образуют процесс. Каждый процесс имеет доступ к данным только своей модели (это данные процесса), а также полный доступ к общей части БЗ.
Фреймовая модель представляет собой систематизированную в виде единой теории психологическую модель памяти человека и его сознания.
Для осознания того факта, что заданная информация имеет единственный смысл, человеческая память прежде всего должна быть способна увязывать эту информацию со специальными концептуальными объектами, в противном случае входную информацию не удастся систематизировать никаким образом. В основе теории фреймов лежит восприятие фактов посредством сопоставления полученной извне информации с конкретными элементами и значениями, а также с рамками, определенными для каждого концептуального объекта в нашей памяти. Структура, представляющая эти рамки, называется фреймом. Сложные объекты представляются комбинацией фреймов, образуя фреймовые системы или сети. С другой стороны, в состав одного фрейма могут входить несколько элементов (слотов), каждый из которых в свою очередь отображается на отдельный элемент модели знаний. Таким образом организованный фрейм будет описывать множество объектов и/или их характеристик. Например, в медицинской диагностической системе это может быть фрейм, содержащий шаблон для ввода первичной информации общего характера о пациенте. В качестве слотов будут выступать поля, определяющие шаблоны для ввода фамилии, пола, возраста, даты обследования. В модели данных эти элементы представлены как отдельные самостоятельные сущности, но логика интерфейсной модели указывает на желательность их объединения при вводе в одну форму. Такое объединение в рамках одного фрейма образует дискурсное пространство подмножества понятий ПО.
На каждом шаге взаимодействия у пользователя запрашивается очередной блок информации о рассматриваемой ситуации, при этом ему предъявляется некоторое количество поясняющих или определяющих характер ответа материалов, которые в свою очередь обладают широким спектром форм представления. С одной стороны это разные структурные формы — тексты, изображения, звуковые фрагменты, с другой стороны, они имеют качественную характеристику, определяющую их роль и значимость в контексте рассматриваемого кадра диалога. Так, схематическое изображение, на котором необходимо пометить какие-либо участки для ответа на вопрос, по результатам чего будет сформирован вектор выходных параметров кадра диалога, является необходимым и определяющим для правильного ответа, в то время как поясняющая картинка, предназначенная для вызова ассоциаций, способствующих более быстрому включению пользователя в контекст задаваемого вопроса и предотвращающего неверное понимание вопроса, и, как следствие, неверную интерпретацию ответа, очевидно обладает меньшей информативной ценностью и, следовательно, менее значима в контексте рассматриваемой модели взаимодействия.
Можно выделить по крайней мере два способа выделения подмножества объектов для организации кадра диалога:
Кадр состоит из определяемых признаков (которые нужно ввести) и предъявляемых фактов. Эти факты могут быть как простыми фактами предметной области, которые оказались означены к данному моменту диалога, так и сообщениями предупредительного характера, привлекающими внимание пользователя к особым характеристикам ситуации, которые необходимо либо подтвердить, либо на них нужна быстрая реакция, так как наличие факторов, означивших именно эту ситуации, может привести к серьезным последствиям. Это может быть поясняющая или наводящая информация. К особому классу относятся кадры, описывающие факт, являющийся подмножеством пространства решений. К сопроводительным и поясняющим относятся динамические кадры, где демонстрируется какой-либо процесс, протекающий во времени.
В процессе консультации, т.е. таком взаимодействии пользователя с интеллектуальной системой, когда диалог строится по сценарию, определенному на этапе конструирования системы, активным модулем выступает компонента логического вывода, она запрашивает кадры для означивания параметров. В режиме пояснения, когда пользователь сам проявляет инициативу для доступа к информации, определяющей состояние внутренних переменных системы логического вывода (для пользователя же это степень понимания интеллектуальной системы рассматриваемой проблемы на данном шаге диалога), интерфейсная компонента по запросам пользователя извлекает из модели шаблоны, содержащие фактическую информацию из описания ситуации, наполняя их сведениями из модуля логического вывода. При работе в режиме поддержке справочной компоненты, интерфейсный модуль выступает как в роли инициатора, так и в роли исполнителя запросов участника диалога. Обращений к логической компоненте в данном режиме не производится, поскольку вся необходимая информация для поиска шаблона и его заполнения расположена в пределах модели интерфейса.
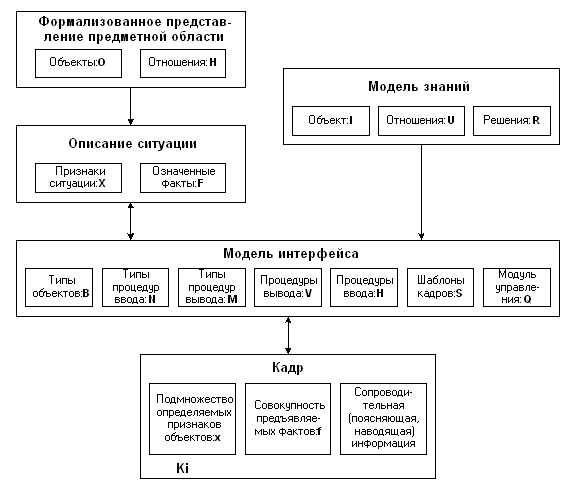
Обозначим множество объектов, используемых для получения информации о ситуации, через X, а объекты, означиваемые в процессе анализа ситуации, — через F.
Процесс взаимодействия пользователя с интеллектуальной системой носит дискретный характер. Каждый этап взаимодействия описывается структурой данных, которыми обмениваются система и пользователь. Определим эту структуру как кадр диалога K:
Ki = { x, f, s }, где
x (X,
f (F,
s (S, где S — множество шаблонов, описывающих структуру кадров
диалога.
Система поддержки диалога D может быть представлена парой:
D = { h, v }, где
h (H — процедуры организации ввода значений параметров объектов,
v (V — процедуры поддержки вывода фактуальной информации.
Вывод фактуальной информации может быть реализован различными способами:
M = { Vt, Vi, Va }, где
Vt — вывод текстовых сообщений. Необходимо отметить, что эту возможность можно реализовать несколькими способами, в зависимости от важности выводимой информации. Различные по содержанию текстовые сообщения в простейшем случае могут являться параметром для типового шаблона, при этом качество восприятия будет ниже, чем у специально созданных для данного вида сообщения шаблонов с использованием выделения различными шрифтами и цветом;N = { Hm, Hl, Hi, Ht, Hn, Hd, Hb, Hs }, где
Hm — выбор значений из текстового меню, представляющего собой статический (т.е. определенный в шаблоне s) список текстовых альтернатив;Предлагаемая структура интерфейсной компоненты интеллектуальных систем (рис. 1) позволяет определять на множестве введенных объектов широкий набор функционалов, качественно и количественно характеризующих определенную реализацию модели общения. Тогда задача построения оптимальной с точки зрения продуктивности общения интерфейсной компоненты сводится к оптимизационной задаче нахождения экстремума функции, построенной на базе введенных функционалов.
Рассмотрим одну из возможных постановок задачи оптимизации на базе следующих функционалов. Введем показатели, оценивающие процесс означивания произвольного параметра x посредством процедуры h.
Быстрота восприятия кадра k есть функционал:
P = FUNC (s, n, b, m), где
n (N,Скорость ввода G есть функционал:
G = FUNC (n, b).
Аналогично определяются показатели:
достоверности восприятия E=FUNC(s,n,b,m) и достоверности ввода Q=FUNC(n,b), (не вызывает сомнений, например, что при выборе из меню число ошибок будет меньшим по сравнению со способом ввода значения с клавиатуры).
При такой постановке оптимальной можно считать систему, построенную на наборе интерфейсных объектов, интегрированных в кадровую среду, обеспечивающую максимум функции:
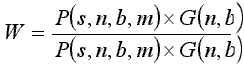 .
. Image Expert — интегрированная оболочка для создания экспертных, информационных и обучающих систем в предметных областях, описание которых представляется в виде графической и лексической информации.
Image Expert включает в себя:
Архитектуру системы Image Expert в общем виде можно представить следующим образом:
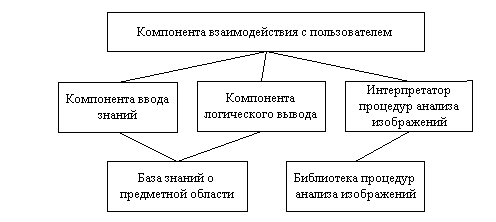
Компонента логического вывода, кроме интерпретации полученных в системе фактов на основе экспертных знаний, осуществляет также функцию общего управления процессом логического вывода. При этом определяются такие моменты ее функционирования, как:
Кроме того, в состав этой компоненты входят также средства пояснения хода рассуждения и принимаемых решений.
База знаний является основой для функционирования компоненты логического вывода и состоит из взаимосвязанных моделей знаний, адекватно отражающих конкретную предметную область.
Пространство фактов связывает систему по информации. Здесь содержатся все факты и параметры, полученные в результате:
Знания о предметной области в системе Image Expert могут быть представлены в форме:
Модель знаний или, иначе, модель предметной области представляет собой совокупность разного рода знаний специалистов о конкретной предметной области.
Модель знаний состоит из информационной и логической компонент.
Логическая компонента модели знаний имеет четыре уровня, заполняемые экспертом совместно с инженером по знаниям:
Взаимодействие уровней модели достигается за счет наличия ссылок в структурах данных одного уровня на объекты другого.
Уровень гипотез содержит множество конечных состояний (решений задачи). Характер связи с нижними уровнями модели и механизм подтверждения/опровержения гипотез отличаются от типа применяемой модели. В моделях нейлоровского типа эта связь имеет вероятностный характер, указывающий на то, как объекты нижнего уровня могут изменять текущее состояние множества гипотез. В моделях с жесткой логикой эта связь устанавливается по типу ЕСЛИ–ТО и записывается в виде решающего правила.
Уровни свидетельств и фактов — это множество характерных признаков анализируемой ситуации.
Объекты уровня свидетельств формируются из свидетельств и фактов, а также объектов уровня запросов с помощью решающих правил, а объекты уровня фактов — как арифметико-логическое выражение.
Уровень запросов предназначен для связи с информационной компонентой модели знаний, т.е. для организации взаимодействия с пользователем. В системе возможны следующие типы запросов:
Информационная компонента модели знаний организована в виде сети фреймов.
Помимо средств для описания знаний, модель содержит некоторые сервисные средства для организации диалога, консультации и фиксации результатов работы, а также средства связи с другими модулями оболочки, что позволяет в процессе работы модели вызывать другие модели, программы на языке обработки изображений, а также любые внешние программы.
В системе Image Expert определены 3 типа моделей: МЕНЮ, НЕЙЛОР, ЛОГИКА.
Модель типа МЕНЮ используется для организации в единую систему различных, как правило, не связанных по информации, но объединенных общей тематикой информационных единиц (моделей, процедур на языке обработки изображений и внешних модулей).
Модель типа НЕЙЛОР позволяет организовать процедуру логического вывода, представляющую собой итерационный процесс принятия решения, каждый шаг которого частично изменяет (подтверждает/ опровергает) вероятности гипотез.
Модель типа ЛОГИКА может быть использована для решения задач, характеризующихся полнотой описания предметной области, т.е. в тех случаях, когда есть возможность применить решающие правила. Для создания тестирующих систем в этот тип моделей заложена возможность организации диалога с тестируемым случайным образом.
Фрейм — информационная единица, отображающая шаг диалога в режиме выполнения модели. Фрейм состоит из графической, текстовой и речевой информации, выдаваемой пользователю, и описания полей запроса к пользователю. Запросы могут представлять собой требования ввода числа, текста, запрос речевого ввода, а также различные типы меню. Меню может быть представлено в виде текстового вопроса и нескольких вариантов ответа или в графической форме — в виде схемы, на которой необходимо пометить требуемые участки или выбрать какое-либо из отображенных состояний. В одном фрейме может находиться несколько слотов (например, речевое сообщение и несколько вопросов, каждый из которых имеет несколько альтернативных вариантов ответа).
Язык описания фреймов позволяет организовывать модели типа гипертекст со вставками графической и речевой информации.
Кроме того, средствами языка возможна организация динамических графических моделей (видеоряда), сопровождающегося звуковыми (речевыми) комментариями. Для этого необходимо описать последовательность кадров в виде имен картинок из библиотеки, причем имеется возможность задавать время отображения каждого кадра, а также сопровождать демонстрацию динамического процесса звуком.
Создание модели знаний включает в себя следующие этапы:
Поддерживаемая в настоящее время технология ввода знаний в ЭС, созданных и функционирующих в оболочке Image Expert, обеспечивает однонаправленный языковой интерфейс с моделью знаний. Практически под моделью подразумевается ее описание на ЯПЗ. В таком виде модель представляет собой статическую конструкцию, т.е. появление новых знаний влечет за собой необходимость внесения изменений в исходные тексты информационной и логической компоненты модели знаний, затем трансляцию этих описаний, после чего следует этап тестирования нового представления в режиме консультации с ЭС.
Компонента ввода знаний призвана решить проблему “отдаленности” формы описания знаний от самих знаний и, что более существенно, от процесса их использования. На нее возлагается задача преобразования модели знаний в базу знаний, структура которой не зависит от типа конкретной модели, а тип модели будет определять характер связей и отношений объектов этой базы. В качестве объектов (единиц хранения) базы на равных правах выступают понятия и объекты предметной области, их графические представления, речевые и текстовые описания и т.п. С помощью специальных средств, зависящих от модели организации знаний в конкретной ЭС, описывается механизм связи понятий и объектов. Интеллектуальный редактор базы знаний решает задачу визуализации знаний с учетом иерархических и сетевых отношений на множестве составляющих базу объектов. К нему предъявляются требования максимально возможной степени адекватности отображения знаний той модели, которая сформирована в сознании эксперта. Для этого предназначены средства настройки подсистемы визуализации на конкретного пользователя.
Приобретением знаний называется выявление знаний из источников и преобразование их в нужную форму, а также перенос в базу знаний ЭС. Источниками знаний могут быть книги, архивные документы, содержимое других баз знаний и т.п., т.е. некоторые объективизированные знания, переведенные в форму, которая делает их доступными для потребителя. Другим типом знаний являются экспертные знания, которые имеются у специалистов, но они не зафиксированы во внешних по отношению к нему хранилищах.
Экспертные знания являются субъективными. Еще одним видом субъективных знаний являются эмпирические знания. Такие знания могут добываться ЭС путем наблюдения за окружающей средой.
Для разработки методологии приобретения знаний необходимо различать две формы репрезентации знаний. Одна форма отражает то, как и в каких моделях хранятся эти знания у человека — эксперта. При этом эксперт не осознает полностью, как организована его модель знаний. Другая форма связана с тем, как инженер по знаниям собирается эти знания представлять и описывать в рамках проектируемой ЭС. От степени адекватности и согласованности этих двух моделей и зависит эффективность процесса приобретения знаний.
В когнитивной психологии различают несколько присущих человеку форм представления знаний — представления класса понятий через элементы, представления понятия класса с помощью базового прототипа, с помощью признаков и т.п.
Кроме понятий представляются и отношения между ними. Как правило, отношения между понятиями определяются процедурным способом, а отношения между составляющими понятий (определяющими структуру понятий) — декларативным. Наличие двух моделей заставляет в моделях представления знаний иметь одновременно обе компоненты, например семантическую сеть и продукционную систему.
Процесс приобретения знаний — наиболее сложный этап разработки ЭС, поскольку на этом этапе необходимо решать не только технические и специальные проблемы, а также рассматривать психологические, лингвистические и гносеологические аспекты проблемы.
В общем случае процесс приобретения знаний можно разделить на этапы:
На ранних этапах развития представлений о механизмах хранения и применения знаний сами знания не отделялись от механизма вывода. При таком подходе программист, занимающийся созданием ЭС, вынужден был детально изучать предметную область, подбирать или проектировать подходящую модель данных, реализовывать ее и самому наполнять знаниями. Ясно, что подняться до уровня эксперта созданная таким образом система не могла.
По мере развития представлений о знаниях появилась идея об отделении базы знаний от механизмов вывода знаний. Для создателей баз знаний этот подход существенно упростил модификацию знаний и поиск и устранение противоречий. При таком подходе задачи 1 и 2 решались уже совместно экспертом и инженером по знаниям, задача 3 — инженером по знаниям, и 4 — самой ЭС. Определим такую систему как систему извлечения знаний.
С появлением интеллектуальных редакторов баз знаний и введения в экспертные системы средств формирования и использования метазнаний (или, иначе говоря, метамоделей данных) эксперту был дан мощный диалоговый инструмент управления базой знаний, в результате чего нагрузки на создателей ЭС перераспределились следующим образом: задачи 1 и 2 решаются экспертом (самостоятельно или с помощью инженера по знаниям), задачи 3 и 4 решаются экспертной системой.
Заманчивой представляется перспектива при наполнении ЭС знаниями о предметной области смоделировать процесс обучения мыслящего существа. Это можно сделать по следующей схеме.
Фактические данные из предметной области (включающие выводы экспертов об имевших место ситуациях) поступают на вход ЭС и там соответствующим образом интерпретируются. Эту задачу может выполнять, например, индуктивная программа. Она и будет осуществлять получение глубинных знаний из примеров ситуаций и анализа сценариев и загружать их в базу знаний экспертной системы. Развивая эту идею, можно предложить в качестве входной информации для обработки тексты на естественном языке (словари, инструкции, учебные пособия, научные труды и т.п.). Для успешного решения этой проблемы необходимо спроектировать интегрированную базу знаний, включающую как знания о предметной области потенциальной ЭС, так и метазнания, и, что особенно важно, знания о языке, которые будут использоваться на этапе анализа входных текстов для извлечения прикладных знаний. Такую систему можно назвать системой формирования (приобретения) знаний.
Рассмотрим три режима взаимодействия инженера по знаниям с экспертом-специалистом: протокольный анализ, интервью и игровая имитация профессиональной деятельности. Протокольный анализ заключается в фиксации “мыслей вслух” эксперта во время решения проблемы и в последующем анализе полученной информации. В режиме интервью инженер по знаниям ведет с экспертом активный диалог, направляя его в нужную сторону. При игровой имитации эксперт помещается в ситуации, похожие на те, в которых протекает его профессиональная деятельность. Наблюдая за его действиями, инженер по знаниям формирует свои соображения об экспертных знаниях, которые впоследствии могут быть уточнены экспертом в режиме интервью.
Все эти способы имеют свои положительные и отрицательные стороны. При анализе протоколов инженеру по знаниям бывает сложно отделить важные, ключевые понятия от тех, которые упоминаются и высказываются экспертом случайно, по ассоциации. Рассуждения могут опускать важные этапы цепочки выводов, так как эксперт может считать это для себя само собой разумеющимся. Таким образом, этап интервью является необходимым при любой схеме.
Наиболее распространены три стратегии интервьюирования: разбиение на ступени, репертуарная решетка и подтверждение сходства.
При разбиении на ступени эксперту предлагается назвать наиболее важные, по его мнению, понятия предметной области и указать между ними отношения структуризации. Эти понятия фиксируются как базовые. Стратегия направлена на создание иерархии понятий предметной области, выделение в понятиях тесно связанных между собой групп — кластеров.
Стратегия репертуарной решетки направлена на выявление характеристических свойств понятий, позволяющих отделять одни понятия от других. Методика состоит в предъявлении эксперту троек понятий с предложением назвать признаки для каждых двух понятий, которые отделяли бы их от третьего. Так как каждое понятие входит в несколько троек, то на основании такой процедуры происходит уточнение объемов понятий и формируются комплексы понятий, с помощью которых эти понятия могут идентифицироваться в базе знаний.
Стратегия подтверждения сходства состоит в том, что эксперту предлагается установить принадлежность каждой пары понятий к некоторому отношению сходства (толерантности). Для этого эксперту задается последовательность достаточно простых вопросов, цель которых заключается в уточнении того понимания сходства, которое вкладывает эксперт в утверждение о сходстве двух понятий предметной области.
Процесс взаимодействия инженера по знаниям (аналитика) с экспертом-специалистом включает три основных этапа:
Процесс извлечения знаний начинается с получения от эксперта поверхностных знаний (таких, например, как представление признаков) и постепенно направляется аналитиком на формирование глубинных структур и более абстрактных понятий (таких, как прототипы).
Этот вид приобретения знаний экспертной системой называют также обучением экспертной системы. При этом активно используются модели обучения, известные в физиологии и психологии. Первые модели опирались на чисто физиологические методы обучения, позже появились более гибкие ассоциативные, согласно которым всякое обучение есть установление ассоциативных связей в нейроноподобных сетях.
На смену ассоциативной модели пришла лабиринтная модель, опирающаяся на идей когнитивной психологии. Модель предполагает, что процесс обучения состоит в эвристическом поиске в лабиринте возможных альтернатив и оценивании движения по лабиринту на основе локальных критериев. Наиболее исследованными на сегодняшний день являются модели, относящиеся к обучению по примерам.
Обучение как математическая задача может быть отнесено к классу оптимизационных проблем поиска описаний.
Индивидуальная оптимизационная задача L есть пятерка:
< X, Y, p, F, J>, где
X и Y — множество входных и выходных записей;Задача состоит в отыскании оптимального по J описания f из F.
Спецификация задачи часто оказывается неполной. Например, оператор качества J может быть плохо формализуемым, информация об отношении p может задаваться только примерами пар (x1, y1), (x2, y2), ..., (xn, yn), для которых выполняется функция p. Для задач, относящихся к обучению, характерна неполнота рассматриваемой спецификации.
Для решения задачи обучения можно применить следующие методы:
Человек или машина могут получать знания многими способами.
Можно вывести нужную информацию как логическое следствие имеющихся знаний, получить ее модификацией существующих знаний, рассчитывая на аналогичность ситуации, попытаться вывести общий закон из имеющихся примеров. Некоторые задачи, относящиеся к получению знаний по примерам:
Корректными способами генерации гипотез считаются такие, которые в пределе (при исчерпании всех примеров) приводят к решению задачи.
Предположение о предельной стабилизации гипотез является основой гипотетико-дедуктивного подхода, согласно которому решение задачи формирования знаний включает 4 этапа:
Считается, что процесс находит искомое описание, если оно было выдвинуто в качестве гипотезы при каком-либо прохождении второго этапа и при следующих прохождениях этого этапа не менялось.
В процессе выдвижения гипотез выясняются “разумные” способы выдвижения и критерии подтверждения гипотез.
Методы интервьюирования эксперта предметной области знаний с использованием нескольких различных стратегий применены при создании системы TEIRESIAS. В диагностической системе MORE предложена методика интервьюирования, направленная на выяснение следующих сущностей — гипотез, симптомов, условий, связей и путей. Гипотеза — событие, идентификация которого имеет своим смыслом диагноз. Симптом — событие, являющееся следствием существования гипотезы, наблюдение которого приближает последующее принятие гипотезы. Условие имеет диагностическое влияние на некоторые другие события. Связи — соединения сущностей. Путь — выделенный тип связи, который соединяет гипотезы с симптомами. В соответствии с этим используются следующие стратегии интервью — дифференциация гипотез, различение симптомов, симптомная обусловленность, деление пути и т.д.
В системе KRITON для приобретения знаний используются два источника — эксперт с его знаниями, полученными на практике (эти знания, как правило, неполны, отрывочны и плохо структурированы), и книжные знания, документы, описания, инструкции. Для извлечения знаний из первого источника в KRITON применена техника интервью, использующая методы репертуарной решетки и разбиения на ступени. Для выявления процедурных знаний эксперта в KRITON применен метод протокольного анализа.
Анализ текста используется в KRITON для выявления хорошо структурированных знаний из книг, документов, описаний, инструкций.
В системах SIMER и ДИАПС основным методом приобретения знаний является автоматизированной интервьюирование эксперта, которое управляет знаниями, приобретенными системой. В этих системах не выявляется предварительная модель области.
Предполагается, что на множестве объектов могут быть заданы ряд отношений из
известного (конечного) множества: элемент-множество, часть-целое, пример-прототип,
отношения структурного сходства, структурной иерархии и др. На выяснение свойств
отношений и направлено интервью.
В статье была использована следующая литература: Аверкин, 1990; Агафонов, 1993; Гаврилова, 1992; Ефимов, 1993; Кирсанов, 1990; Левин, 1990; Мартиросян, 1990; Михайлов, 1991; Попов, 1990; Попов, 1987; Хейер-Рот, 1987; Уотермен, 1989; Элти, 1987; Сборник ЭС, 1989; Vasa Cor, 1992; Image Expert, 1992; Chen, 1991.
1 Материалы данной статьи частично вошли в отчет по первому этапу научно-исследовательской работы "Инструментальная среда проектирования медицинских экспертных систем функциональной диагностики и оценки психофизиологических резервов летчиков с использованием мультимедиа-ориентированных CASE-технологий (шифр- МЕДЭКСПЕРТ, руководитель- Ю.Н. Филиппович)". НИР проводилась в 1994-1997 гг. в МГТУ им. Н.Э. Баумана, НПП "Фрегат" и Государственном научно-исследовательском испытательном институте (авиационной и космической медицины) Министерства обороны Российской Федерации.