Существующие в настоящий момент инструментальные системы, в частности разнообразные СУБД, ориентированы на создание и использование баз данных с жесткой, полностью детерминированной структурой. Для создания разнообразных бизнес-приложений, систем учета кадров, ресурсов на складе, бухгалтерских систем такие СУБД вполне подходят, хорошо апробированы и широко используются. Но существует целый ряд предметных областей (ПО), которые выдвигают к инструментальным средствам дополнительные требования, касающиеся построения баз данных с нечеткой структурой.
В данной статье в качестве примера рассмотрены две такие предметные области. Первая — базы знаний, получаемые в результате проектирования прикладных информационных систем, вторая — словари разнообразного содержания. Сформулированы требования, выдвигаемые этими ПО к инструментальным средствам, которые можно использовать для их автоматизации. На основе этих требований введено понятие базы данных с нечеткой структурой и дается оценка пригодности распространенных в настоящее время моделей данных и соответствующих инструментальных систем для решения подобного класса задач.
Предложена модель данных, базирующаяся на объектно-ориентированном подходе, но имеющая, вместе с тем, ряд существенных отличий, позволяющих использовать ее для построения баз данных с нечеткой структурой.
В заключение представлены замечания по практической реализации инструментальной системы на основе предлагаемой модели и очерчен круг областей, в которых она может найти практическое применение.
Процесс проектирования любой прикладной информационной системы начинается с анализа предметной области. С анализом тесно связано концептуальное проектирование системы. В результате, как правило, получается некоторый набор спецификаций и документов, являющихся базисом для дальнейшей работы над проектом. Абстрагируясь от конкретной физической формы представления результатов, можно выделить следующие элементы знаний о проекте.
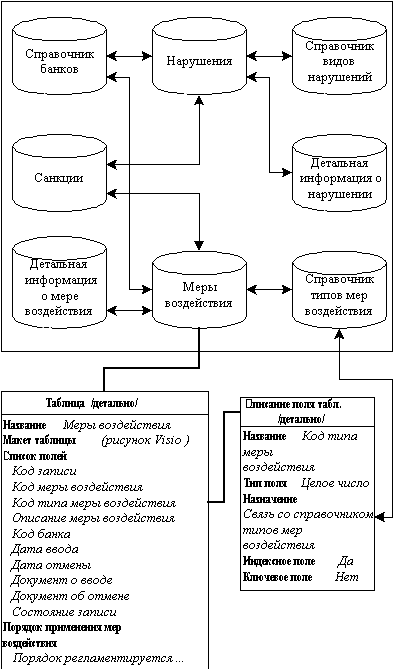
Информационно-логическая модель отражает сущности, относящиеся к рассматриваемой предметной области, их атрибуты и связи между ними. В ней представлена информационная структура объектов автоматизируемой задачи. Например, на рис. 1 приведена упрощенная схема инфологической модели для задачи, касающейся банковского надзора. Для больших задач число сущностей и связей между ними, а также сложность самих связей может быть очень высокой.
Структура баз данных строится на основе инфологической модели и представляет собой ее адаптацию для конкретной СУБД. При этом учитываются возможности этой СУБД для описания и манипулирования данными.
Функциональная структура приложения определяется на основе задач, которые хочет решать заказчик с помощью разрабатываемого приложения. Функции объединяются в группы. Группы функций могут быть связаны между собой по признаку взаимного использования.
Параллельно с разработкой функциональной структуры строится граф диалога. В узлах этого графа находятся описания экранных форм, а связи характеризуют порядок их вызова.
Любые элементы полученных структур могут быть привязаны к фрагментам документов, регламентирующих решение данной задачи, к формам входной и выходной информации.
Каждая из перечисленных выше структур имеет вид некоторого графа, в узлах которого располагаются элементы знаний, а ребра характеризуют разнообразные связи между ними. Эти графы, в свою очередь, связаны между собой. Элементы инфологической модели связаны с соответствующими элементами описания структуры базы данных и экранными формами в графе диалога, в которых отображается описываемая ими информация. Элементы функциональной структуры приложения связаны с экранными формами. В итоге все знания о проекте могут быть представлены графом произвольного вида, состоящим из перечисленных выше подграфов.
При анализе предметной области для человека характерна работа с разными уровнями абстракций. На отдельных шагах построения модели предметной области необходимо отвлекаться от ненужных деталей, иметь возможность рассматривать рабочие материалы послойно. В примере на рис. 1 выделены три уровня (слоя) абстракций: уровень инфологической модели в целом, уровень детального описания таблицы и уровень детального описания поля таблицы. Аналогичные уровни можно выделить и для других схем. Это означает, как правило, что в узлах графа знаний о проекте располагаются не атомарные (неделимые) элементы, а элементы, имеющие сложную многоуровневую структуру.
Методика выделения структур элементов строящегося графа и связей между ними
очень сильно зависит от конкретного разработчика, его опыта, знаний, представлений
о процессе проектирования. В результате анализа одной и той же предметной области
разными разработчиками могут получиться сильно различающиеся модели. Не представляется
возможным ограничить разработчиков только типовыми конструкциями (структурами),
так как это, во-первых, приводит к внутреннему конфликту, противоречию с естественными
представлениями человека о том, каким образом должен быть освещен тот или иной
вопрос. Во-вторых, при использовании только типовых конструкций многие нюансы
задачи, выявленные в процессе анализа, могут оказаться неучтенными.
С другой стороны, некоторые аспекты анализируемой предметной области и концептуального проекта системы можно представить в виде вполне определенных, регулярно повторяющихся структур. Так, в приведенном примере для каждого описания таблицы можно выделить такие поля как “Название” и “Список полей”. В то же время поле “Порядок применения мер воздействия” присуще описанию только одной конкретной таблицы “Меры воздействия” и не может быть включено в общую структуру данного вида элементов графа знаний. Поле “Макет таблицы” может как присутствовать, так и отсутствовать в описании таблицы.
В целом, для данной предметной области можно выделить следующие особенности:
Следует оговориться, что описанная база знаний со всеми ее сложными связями при современных подходах к процессу проектирования представляет собой не более чем гипотетическое построение. Во всей своей полноте она присутствует лишь в голове разработчика. Физически элементы этой базы знаний присутствуют в целом ворохе бумаг, распечаток, документов, в их разрозненных электронных копиях.
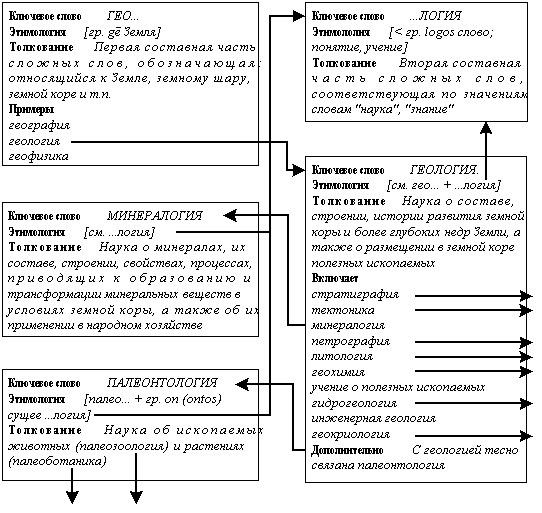
Многое из сказанного справедливо и для словарных баз данных. Прежде всего, это касается толковых и энциклопедических словарей разной тематики. На рис. 2 показано несколько статей из словаря иностранных слов [СловарьИС, 1987]. Словари такого типа представляют собой сеть взаимосвязанных словарных статей. В толкованиях одних понятий очень часто встречаются ссылки на другие слова. Это могут быть разъясняющие термины, примеры, термины, представляющие фрагменты или разделы понятия и многое другое.
В то же время, каждая словарная статья имеет некоторую внутреннюю структуру — набор полей. Причем часть полей присутствует во всех словарных статьях и образует базовую структуру словаря. В приведенном ниже примере к таким полям относятся “Ключевое слово”, “Этимология” и “Толкование”. Но от этой базовой структуры возможны многочисленные отступления. Формализовать их все не представляется возможным. Некоторые поля могут присутствовать у ограниченного числа словарных статей или вообще быть уникальными для конкретной статьи.
Для словарей характерно наличие множественных значений полей. Это свойство особенно заметно у словарей типа “язык-язык”, таких как англо-русский словарь [АнгРусСловарь, 1990]. Почти у любого слова английского языка или у сочетания этого слова с другими словами (например, с предлогами) есть несколько вариантов перевода их на русский язык. В примере на рис. 2 множественные значения имеют поле “Примеры” словарной статьи “ГЕО...” и поле “Включает” словарной статьи “ГЕОЛОГИЯ”.
Структуры словарей меняются с течением времени. Это связано с тем, что словари постоянно пополняются и редактируются. Этот процесс может быть очень продолжительным (многие годы или даже десятилетия) и структура более поздних словарных статей может сильно отличаться от первоначального варианта.
Словарные статьи можно группировать по самым разным признакам — тематике, областям знаний, ссылкам на источники и т.д. Фактически, такие множества образуют отдельные разделы словарей и соответственно объекты словарной базы данных. В качестве примера можно привести англо-русский идеографический словарь [Шаталова, 1994]. В нем представлено около 3500 слов современного английского языка, сгруппированных вокруг девяти тем, наиболее необходимых в устном общении. Внутри каждой большой темы выделяются несколько десятков подразделов для более детального разбиения слов на группы. Отдельный раздел словаря образует алфавитный указатель — множество всех слов, упорядоченное по алфавиту, со ссылками на их положение в группах.
Над словарем может работать группа лингвистов, что также предъявляет определенные требования к инструментальной системе, используемой для автоматизации работы со словарем, в части организации многопользовательского режима работы.
Аналогии между базами знаний, получаемыми в процессе проектирования и лингвистическими базами данных очевидны. Это и не удивительно, ведь словари — это тоже своего рода базы знаний. Они отражают знания человека об окружающем его мире в виде элементов естественного языка, устанавливают соответствие между элементами языка и объектами реального мира. И в том, и в другом случае мы имеем дело с сетью произвольным образом взаимосвязанных элементов знаний, каждый из которых может иметь некоторую внутреннюю структуру. Важно, что внутренние структуры элементов знаний могут частично или полностью совпадать, но, в то же время, некоторые фрагменты этой внутренней структуры могут быть уникальны и специфичны для конкретного элемента знаний.
Основываясь на приведенных особенностях рассматриваемых предметных областей, можно сформулировать понятие базы данных с нечеткой структурой. Оно имеет два аспекта. Первый заключается в том, что число вариаций структур элементов базы данных соизмеримо с числом всех элементов базы данных, выделить и четко описать все структуры нельзя. Второй аспект — существующие структуры постоянно видоизменяются, отражая изменения представлений пользователя об описываемых им объектах.
Распространенные в настоящее время модели данных и реализующие их инструментальные системы не в полной мере удовлетворяют требованиям, выдвигаемым указанными предметными областями.
Реляционные базы данных [Oracle7, 1992] поддерживают жесткие структуры. Они позволяют моделировать объекты реального мира только с помощью плоских отношений — таблиц. Главный их недостаток — неестественное представление данных со сложной, трудно формализуемой структурой. Попытка реализовать описанные базы знаний с помощью таблиц приведет либо к проблемам с избыточностью структур, либо к трудностям с администрированием большого числа таблиц, с поддержанием целостности связей между ними. Реляционные СУБД не предоставляют возможности работать с разными уровнями детализации данных (рассматривать их послойно).
Гипертекстовые системы, хорошо поддерживая перекрестные ссылки между фрагментами информации, не позволяют задавать структуры данных. Соответственно, они не поддерживают процедуры поиска по структурам. Их поисковые системы достаточно примитивны, как правило, они базируются на одном общем индексе, содержащем в себе заголовки всех кадров гипертекста или вообще все слова, встречающиеся в тексте (полнотекстовый поиск).
Системы объектно-ориентированного программирования (ООП), например, на базе широко используемого сейчас языка С++ [Страуструп, 1992; Страуструп, 1993], являются наиболее универсальным инструментом. Но за универсальность приходится платить. Такие системы предъявляют очень высокие требования к квалификации пользователя. К достоинствам систем ООП можно отнести великолепные возможности по описанию структур, наследованию, инкапсуляции данных, поддержки полиморфизма, шаблонов. К существенным недостаткам можно отнести то, что они не поддерживают динамического взаимодействия с пользователем — при внесении каких-либо изменений требуется перекомпиляция и повторная сборка проекта. Не поддерживаются функции специфичные для СУБД — нет унифицированного языка запросов, отсутствует встроенная развитая система поиска, не реализованы механизмы обработки транзакций. Безусловно, все указанные проблемы можно решить, но для этого потребуются высококвалифицированные программисты, и полученный результат будет системой принципиально иного уровня.
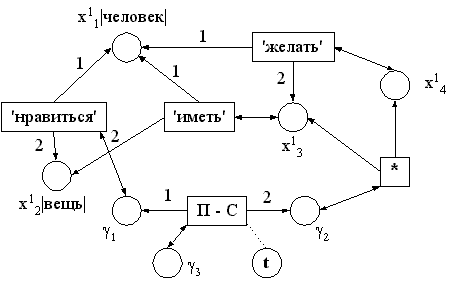
Семантические сети [Попов, 1982; Кузнецов, 1986] используются для представления смысла естественно-языковых фраз. Теоретически их можно использовать для представления знаний в любой предметной области. Семантические сети — “это хранилище разного рода структур (знаний), которые (без каких-либо ограничений) должны постоянно накапливаться, корректироваться, изменяться” [Кузнецов, 1986. С.14]. В качестве примера семантической сети на рис.3 приведено изображение сетевой продукции, представляющей фразу Если X1 нравится вещь X2, то он желает иметь ее [Кузнецов, 1986]. Не вдаваясь в подробности, можно выделить следующие положительные моменты данного подхода к представлению знаний — универсальность, гибкость, возможность создания любых (в том числе и очень сложных) структур на основе конечного набора базовых элементов, однородность и, как следствие, хорошая масштабируемость.
Вместе с тем, можно выделить и существенные недостатки. Главный из них — неочевидность
предложенных механизмов для обычного пользователя. Построение базы знаний с
помощью семантических сетей требует от пользователя определенной подготовки,
специальных знаний, опыта работы. Фактически, для решения задачи необходимо
наличие специально обученного инженера по знаниям. Другой существенный недостаток
— отсутствие сколько-нибудь продвинутых инструментальных систем, реализующих
такой подход к представлению знаний.
Объектно-ориентированные базы данных [Медников, 1994; Ким Вон, 1994; Стоунбрейкер, 1994; Давид Бич, 1994] представляются наиболее подходящим инструментом для решения задач в рассматриваемых предметных областях. Действительно, они сочетают в себе мощность и гибкость изобразительных средств систем объектно-ориентированного программирования с функциональными возможностями хорошо зарекомендовавших себя реляционных СУБД. От систем ООП были взяты такие механизмы как типы, определяемые пользователем, наследование (в том числе и множественное), инкапсуляция, полиморфизм, возможность строить сложные объекты, шаблоны. У реляционных СУБД были заимствованы не менее важные возможности: унифицированный непроцедурный язык запросов (например, спецификация SQL3), постоянное хранение объектов, динамическое изменение схемы БД, поддержка ограничений целостности, обеспечение конкурентного доступа к БД многих пользователей с контролем прав, обеспечение устойчивости к сбоям и т.д. Существуют два подхода к построению объектно-ориентированных баз данных. Первый заключается в расширении возможностей систем ООП с целью сделать стандартные объекты постоянными, хранимыми на жестком диске, и предоставить пользователю функции, специфичные для работы с БД (запросы, транзакции и т.д.). Реализация такого подхода может представлять собой, например, библиотеку классов С++ (СУБД POET [Медников, 1994]), реализующую указанные механизмы. Второй подход базируется на расширении стандартной реляционной технологии объектными возможностями, построении своеобразной объектной надстройки над реляционной СУБД. Такие продукты получили название объектно-реляционных СУБД. В частности, в этом направлении развивает свои продукты Oracle [Давид Бич, 1994], и сервер Oracle8 поддерживает некоторые объектные возможности.
Несмотря на несомненные достоинства объектно-ориентированных баз данных, существует ряд позиций, по которым они не удовлетворяют требованиям указанных ПО. Прежде всего, это жесткие структуры данных — объект БД строится в строгом соответствии со структурой своего класса. На уровне модели данных в недостаточной степени определены возможности организации связей между объектами и их фрагментами. Часть требуемых связей придется реализовывать на уровне приложения. Кроме того, указанные системы пока недостаточно распространены и апробированы. Как следствие этого, цены на них могут быть достаточно высоки для обычного пользователя.
На основании всего сказанного становится очевидной необходимость создания некоторой гибридной системы, объединяющей достоинства перечисленных систем и устраняющей их недостатки.
В основе предлагаемой модели данных лежит объектно-ориентированный подход. Центральным понятием и основной единицей хранения в базе данных является объект. Под объектом понимается совокупность полей-данных, процедур для их обработки и связей, соединяющих объект с другими объектами. Объекты, обладающие сходными наборами полей и процедур, могут рассматриваться как члены одного класса.
Поля-данные предназначены для хранения информационной составляющей объекта. Поле может иметь как один из стандартных типов данных (строка символов, число, дата, текст и т.п.), так и тип, определенный пользователем с помощью некоторого класса. В этом случае поле объекта содержит подобъект указанного класса, что позволяет работать с объектом на разных уровнях детализации. В общем случае объект представляет собой иерархию подобъектов любой сложности. Поле может иметь произвольное число значений. Такая возможность очень важна для рассмотренных предметных областей, но не поддерживается объектно-ориентированными инструментальными средствами, такими как язык С++.
Процедуры определяют действия, которые можно производить над объектом. С их помощью осуществляется инкапсуляция — привязка к данным методов для их обработки и скрытие самих данных от непосредственного доступа. Процедуры могут быть привязаны к некоторым событиям, например, изменению или удалению объекта. При наступлении события, для которого определена процедура обработки, она выполняется автоматически, без участия пользователя. Аналогичные функции в реляционных базах данных выполняют триггеры [Oracle7, 1992].
Следующим важным отличием от классического объектно-ориентированного подхода являются особенности реализации связей между объектами. Связь может соединять объект в целом, любое его поле, множество значений поля, подобъект, поля подобъекта (и так далее вниз по иерархии) с другим объектом или его элементом. Причем число связей для объекта или его элемента любого уровня может быть произвольным. Это позволяет строить как отношения 1 : М между объектами, так и более общие отношения M : N, присутствующие в реляционной модели. Но предлагаемый механизм является более гибким и выразительным, чем реляционный подход. Фактически, используя связи, можно построить граф любой сложности, в узлах которого будут расположены объекты и их элементы, а ребра будут представлять связи между ними. Именно такой вид базы данных получается в результате анализа предметных областей, описанных выше. С помощью связей можно, например, отразить перекрестные ссылки между словарными статьями.
Кое-что общее можно найти у описанного подхода к реализации связей и у гипертекстовых систем. Но если в гипертекстах связь устанавливается между страницами текста или их фрагментами (неструктурированная информация), то в предлагаемой модели связи устанавливаются между элементами структур, т.е. связываемые элементы менее аморфны, более детерминированы.
Связи между объектами могут иметь разный характер, выражать разные отношения. Связь может иметь направление, характеризоваться типом, силой, вероятностью перехода по ней. Для указания свойств связей в модель введены специальные средства. Каждая связь может характеризоваться произвольным набором атрибутов. Этот набор представляет собой объект, единственное отличие которого от других объектов — запрет на создание для него своих собственных связей. Такой объект является своеобразной биркой, которая вешается на связь для указания ее характеристик.
Объект строится на основе предварительно созданного класса. При описании класса задается базовый для объекта набор полей — данных, процедур и связей. При конструировании нового класса можно использовать механизм наследования атрибутов и поведения уже существующих классов — один из основополагающих механизмов объектно-ориентированного подхода. При этом множества полей-данных, процедур и связей нового класса образуются объединением множеств полей-данных, процедур и связей базовых классов с новыми полями-данными, процедурами и связями, определенными для создаваемого класса. Использование наследования значительно облегчает создание и модификацию новых типов данных.
Некоторые процедуры, определенные в базовых классах, могут быть переопределены в классах-потомках. В результате при вызове процедуры объекта базового класса, который является частью объекта класса-потомка, реально будет вызвана одноименная процедура класса-потомка. В ООП такой подход носит название полиморфизма.
Теперь, обозначив основные свойства предлагаемой модели и ее сходство с объектно-ориентированным подходом, можно перейти к изложению главного отличительного принципа — принципа неопределенности структуры. В ООП объект строится в строгом соответствии со структурой своего класса. В рассматриваемой же модели при построении объекта поля, описанные в классе, могут и не включаться в него, если явно не оговорено обратное. И, наоборот, в структуру объекта могут быть внесены поля, не описанные в классе. Все поля класса можно условно разделить на три группы:
При создании нового класса объектов единственное, что требуется от пользователя, — задать для этого класса имя. Поля-данные, процедуры и связи он может определить постепенно, по мере вставки в базу данных новых объектов данного класса. Если во вставляемом объекте присутствует поле, не определенное в классе, по которому он построен, то это поле в автоматическом или полуавтоматическом (в зависимости от настройки) режиме будет добавлено к одной из перечисленных групп полей. По мере заполнения базы данных пользователь может перемещать поля из одной группы в другую — уникальное поле переместить в категорию рекомендуемых, рекомендуемое сделать обязательным или наоборот. Таким образом, от пользователя не требуется предварительное определение структуры базы данных. Эта структура во многом получается автоматически на основе анализа структур вставляемых в базу данных объектов.
Таким образом реализуется принцип неопределенности структуры. Иными словами, строится база данных с нечеткой структурой. Такой подход позволяет пользователю гибко манипулировать структурами данных в условиях неопределенности, вызванной, например, недостаточной осведомленностью в предметной области, с которой он работает.
Вторым базовым понятием предлагаемой модели данных является понятие множества объектов. Множество представляет собой именованную совокупность ссылок на объекты, удовлетворяющие определенным условиям включения. Условия включения могут быть формальными, в этом случае множество представляет собой результат обработки некоторого формального запроса к базе данных, либо неформальными, в этом случае объекты явным образом включаются в множество пользователем. В качестве примера можно привести множества объектов, сгруппированных по источникам данных, по темам и т.п. Каждый объект может быть включен в любое число множеств. Множество может объединять другие множества. Ряд множеств формируется автоматически — это совокупности объектов, имеющих один и тот же базовый класс, объектов, имеющих то или иное поле, упорядоченные по возрастанию или убыванию (то есть индексы), совокупность всех объектов базы данных.
База данных представляет собой сеть произвольным образом взаимосвязанных объектов и множеств, построенных из этих объектов. Особый раздел базы данных составляют объекты, описывающие другие объекты базы данных. К таковым относятся описания классов, описания множеств, описания пользователей и групп пользователей с их правами доступа к базе данных и т.п.
Практическая реализация предложенной модели связана с разработкой соответствующей системы управления базами данных. Данная работа ведется с 1995 года. Рабочее название проекта — инструментальная система поддержки баз данных с нечеткой структурой WordHeap. Разрабатываемая система имеет архитектуру клиент-сервер. Такая архитектура оптимально реализует многопользовательский режим работы. Сервер баз данных разрабатывается как переносимое приложение. Это достигается за счет использования независимого от платформы интерфейса с операционной системой, выделенного в отдельный модуль. В разработке находятся версии этого интерфейса для платформ Win32 (Windows NT 3.51 и выше, Windows 95) и UNIX (Solaris, Linux). Помимо сервера баз данных разрабатываются две клиентские части — оболочка администратора и оболочка для интерактивного взаимодействия с базой данных. Последняя будет включать средства для навигации по сетевым структурам базы данных, средства автоматизированного формирования запросов на выборку объектов, функции просмотра и изменения объектов, классов объектов, множеств. Наличие указанных средств должно обеспечить комфортную работу с базой данных не только профессионального разработчика информационных приложений, но и обычного пользователя — специалиста в своей предметной области, не обладающего обширными знаниями по программированию и проектированию баз данных. Все сложные механизмы обеспечения целостности данных, обработки транзакций, построения запросов должны быть понятны для него.
Предлагаемая система построения баз данных с нечеткой структурой может использоваться для создания и использования баз знаний, лингвистических баз данных (словарей разнообразного содержания) в качестве компоненты различных интеллектуальных систем, таких как экспертные системы, лингвистические процессоры, системы машинного перевода, и ряда других систем. Очень перспективным направлением является использование разрабатываемой системы в качестве когнитивного инструмента — программного инструментального средства, облегчающего интеллектуальную, познавательную деятельность человека.