При построении концептуальной модели предметной области на основе ее естественно-языкового описания можно воспользоваться различными методами — логико-аналитическим, дистрибутивно-статистическим, компонентного анализа, ассоциативного эксперимента.
Прежде чем приступить к сравнению этих методов, стоит рассмотреть способы описания языка. При описании искусственных языков, построенных по четким, жестко заданным правилам, проблем не возникает. Достаточно просто перечислить эти правила. Естественный же язык, формировавшийся веками, характеризуется целым рядом особенностей. Практически любое правило обладает рядом исключений. Одно и то же слово в разном контексте может иметь различный смысл, а каждый из синонимов имеет свою определенную смысловую окраску. Получается, что из трех составляющих языка — алфавита, синтаксиса и семантики — не возникает проблем только при описании алфавита. Таким образом, требуется язык — описатель языка, метаязык.
Под метаязыком словаря в широком смысле понимается совокупность лексикографических параметров, отражающая все сведения, передаваемые словарями о структуре данного языка, его истории, распространении, функционировании и изучении. Метаязыком в узком смысле этого термина можно назвать семантический метаязык, т.е. язык описания значений в толковом или переводном словаре, язык дефиниций [Караулов, 1982].
В каждом языке можно выделить две группы лексикографических параметров.
При создании словаря появляется существенное ограничение — вход в словарь выбирается только по одному параметру, и он характеризует данный словарь (толковый — по алфавиту, частотный — по частоте употребления и т.п.). Но нельзя построить словарь, в котором присутствует только одна группа параметров. До сих пор не найдено оптимальное соотношение между способами задания степени глубины лингвистических и структурогенных параметров [Караулов, 1982].
Чтобы задать язык полностью, требуется создать универсальный словарь, охватывающий в идеале все сведения о данном языке, в том числе грамматические, синтаксические и экстралингвистические. Эта задача окончательно не решена.
Далее речь пойдет о трех типах словарей: толковом, ассоциативном и семантическом. Остановимся подробнее на каждом из них.
Простейшее формализованное представление языка — это толковый словарь. Он “является руководством к правильному употреблению слов, к правильному образованию их форм, к правильному произношению, а также к правильному написанию слов в современном... литературном языке” [Ожегов, 1953].
В соответствии с задачами словаря в него, как правило, не включаются:
Если в многозначных словах имеются такие значения, которые соответствуют перечисленным выше, то такие значения в словарь также не включаются [Ожегов, 1953].
В словаре раскрывается значение слова в кратком определении, достаточном для понимания самого слова и его употребления в речи. Краткие определения для слов с одним или несколькими значениями охватывают только те значения и смысловые оттенки слов (в том числе переносные), которые являются устойчивыми в литературном языке.
В словаре наличествуют различные пометы, характеризующие употребление слова в данном значении, например, ирон., устар., прост. [Ожегов, 1953].
Словарную статью толкового словаря можно представить в следующем виде:
<СЛОВО> [<транскрипция>],<морфологические
сведения> [(<помета>)].
1. <толкование 1> [(<помета>)]. [<примеры>.... n. <толкование
n> [<помета>)]. [<примеры>.] [<знак-разделитель><устойчивое
выражение> [(<помета>)] — <толкование>.] [<знак-разделитель><родственное
слово>.]
По схожим принципам строятся словари терминов — частные толковые словари по различным предметным областям.
Толковый словарь не задает правил образования предложений, то есть, он не задает грамматики языка. Традиционная лингвистика делит язык на словарь и грамматику, на названия и способы содинения названий, и изучает эти части по отдельности. Но подобный подход не дает объяснения тому факту, что такие словосочетаниея, как “глокая куздра” тем не менее воспринимаются довольно спокойно [Караулов, 1993].
Грамматику и словарь языка разделить можно, но функционируют они лишь в тесной взаимосвязи. Для понимания этой связи хорошо бы знать, как грамматические знания хранятся в памяти носителя языка. В связи с этим Ю.Н. Карауловым была выдвинута следующая гипотеза [Караулов, 1993. С.6]: “... правила словоизменения, соединения слов и словообразования, т.е. грамматика, которая находится в распоряжении стихийного носителя языка, вся сплошь лексикализирована, привязана к отдельным лексемам, как бы распределена между ними и целиком разлита, “размазана” по ассоциативно-вербальной сети (АВС). Последняя есть признанный способ субъективного, интериоризированного существования лексики, но поскольку лексика не существует в отрыве от грамматики, грамматика языка также должна быть представлена в этой сети в виде отдельных словоизменительных (и словообразовательных) форм и лексем, в своей совокупности — типически, в образцах — отражающих всю грамматическую систему”.
Существует достаточно надежный прием объективирования типовой, стандартной для носителей языка АВС — это построение ассоциативных словарей и тезаурусов.
Структуру словарной статьи ассоциативного словаря можно представить следующим образом:
<СТИМУЛ>: <реакция> [,<реакция>,... <реакция>] <частота появления реакции>;... <реакция> [,<реакция>,...<реакция>] <частота появления реакции>.
Семантический словарь строится на основе компонентного анализа, поэтому целесообразно сказать несколько слов об этом методе.
Компонентный анализ заключается в последовательном сравнении терминов с их словарными дефинициями. По количеству общих элементов в словарных дефинициях двух терминов можно судить о степени их связанности. Словарная дефиниция (в толковых словарях) представляет собой разложение смысла термина на его смысловые составляющие. Термины, обозначающие конкретные объекты, объясняются с помощью терминов с более общим значением и так далее. В результате получаются наиболее общие понятия, так называемые элементарные понятия (семантические множители) [Москович, 1971].
Семантические множители возникают в предположении о дискретности семантического пространства языка и о том, что набор элементов в этом пространстве конечен и обозрим, тогда как число их комбинаций является потенциально бесконечным. Общие черты семантических множителей:
Входные слова словаря составляют два множества, отличающиеся по своему объему, характеру, а также по способу определения набора множителей для составляющих каждое из них слов. Первое — перечень дескрипторов (основных понятий, “идей”, заглавных слов или названий статей в тезаурусе), второе — словник, или перечень слов, подлежащих распределению по дескрипторам.
Список дескрипторов (заглавных слов статей словаря) был получен методом компиляции классификационных схем наиболее крупных идеографических словарей разных языков и составил более 1600 единиц. Словник содержит около 10000 слов. В его состав входят заглавные слова статей Краткого толкового словаря русского языка (для иностранцев) и дескрипторы. Семантические множители для каждого из слов, входящих в словник, устанавливались по словарю С.И.Ожегова, а для дескрипторов — суммировались по двум словарям: С.И.Ожегова и Д.Н.Ушакова [Караулов, 1980].
При составлении семантического словаря семантическими множителями являлись полнозначные слова, использованные в правой части толкового словаря.
Словарь строился на основе феноменологической модели — связь между словами фиксировалась по факту совпадения хотя бы одного слова в их словарных статьях. При построении словаря использовалась ЭВМ, что было очень удобно при обработке столь обширного объема информации (например, лишь 170 словарных статей словаря Ожегова представляют собой свыше 100 тыс. печатных знаков). Для учета словоизменительных и словообразовательных модификаций при вхождении в словарную статью семантических множителей они приводились к квазиосновам.
Квазиоснова — это набор букв слева от начала графического слова до некоторой буквы корня или суффикса, который позволяет однозначно идентифицировать группу словоформ и слов–дериватов, представляющих одну гиперлексему. Квазиоснова — это своеобразный представитель, заместитель, знак гиперлексемы [Караулов, 1982].
Определение квазиосновы слова происходит на основе эмпирических правил.
Каждый семантический множитель характеризовался двумя показателями: частотой на массиве дескрипторов и частотой на массиве слов.
Для включения слова в семантическое поле дескриптора было достаточно либо совпадения дефиниций в одном множителе с частотой менее 7, либо совпадения в двух множителях независимо от их частоты [Караулов, 1980].
Это ограничение по частоте происходит вследствие того, что самые частые в языке слова семантически пусты, поэтому совпадение в высокочастотных словах не несет никакого смысла.
Структуру словарной статьи Семантического словаря можно представить в следующем виде:
семантические множители: <номер>. <множитель в виде квазиосновы> —<частота множителя на массиве дескрипторов>,...<номер>. <множитель в виде квазиосновы> — <частота множителя на массиве дескрипторов>.
<слово><кол-во собственных сем.мн.>* <номер совп.мн> [,
<номер совп.мн>,...<номер совп.мн.>]
...<;слово><кол-во собственных сем.мн.> *<номер совп.мн> [,
<номер совп.мн>,...<номер совп.мн.>]
Отметим, что в Ассоциативном словаре слова описываются полнее. Сравним словарные статьи слова “рука” в Семантическом и Ассоциативном словарях. В семантическом словаре четко прослеживаются парадигматические связи с включенными в статью словами: “кисть”, “кулак”, “локоть”, “палец” и т.д. В Ассоциативном словаре помимо этих слов находятся также “правая”, “рабочая”, “тяжелая”, “нечистая”, “длинная”, “умелая”. Это, с одной стороны, свидетельствует о недостаточности описания, даваемого Толковым словарем (на основе которого строился Семантический), а с другой — доказывает выгоду получения описания понятия непосредственно из сознания человека.
Для сравнения методов компонентного анализа и ассоциативного эксперимента был проведен частотный анализ четырех словарей: Толкового, Семантического, Словаря ассоциативных норм Леонтьева и Ассоциативного словаря [Ожегов, 1953; Леонтьев, 1977; РАссСловарь, 1994; РСемСловарь, 1982].
Статьи отбирались по их заглавиям. В результате были отобраны 170 словарных статей двух ассоциативных и толкового словарей; в семантическом словаре наличествовало лишь 38 статей. Это связано с особенностями его формирования.
Для проведения частотного анализа были построены словники для каждого из словарей. Словник представляет собой список словоформ с указанием абсолютной частоты встречаемости слова в тексте. Для создания словников использовалась система создания и ведения лексикографических карточек Dialex [Dialex, 1996].
Для словников в Microsoft Excel 5.0 были построены таблицы, содержащие основные частотные характеристики текста (ранг слов, абсолютная частота, относительная частота), и графики зависимости частот слов от их ранга и зависимости количества слов от частоты их употребления.
Для полученных экспериментальных кривых были построены аппроксимирующие прямые и по ним вычислены параметры распределения закона Мандельброта:
i(k,r) = pk(r+v)-b,
где i(k,r) — частота встречаемости слова с рангом r из выборки объемом k;
p, v, b — параметры закона.
Общие данные по всем словарям приводятся в табл. 1 (приложение).
Далее с помощью программы LemmaLex [LemmaLex, 1996] была проведена лемматизация словарных статей. На основе результатов лемматизации были построены аналогичные графики. Общие результаты по всем словарям приводятся в табл. 2. Показательно, что параметр b закона Мандельброта неизменно уменьшается.
Интерес представляют также наиболее часто употребляемые слова. В табл. 3 приводятся первые 10 слов из словарей (до лемматизации) и для сравнения начало частотного словаря Засориной [М, 1977]. Обращает на себя внимание тот факт, что слово человек в обоих ассоциативных словарях попадает в число слов с высокой частотностью употребления. Можно сделать вывод, что это слово является весьма общим понятием.
В табл. 4 приводятся первые 10 слов после лемматизации. Заметим, что слово человек продвинулось на несколько позиций выше. В первую десятку попали также весь и друг (для ассоциативных словарей).
Выделим часто встречающиеся слова — не предлоги (табл. 5). Заметим, что первые пять слов ассоциативных словарей одинаковы с точностью до номера.
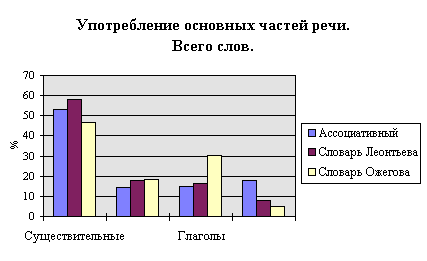
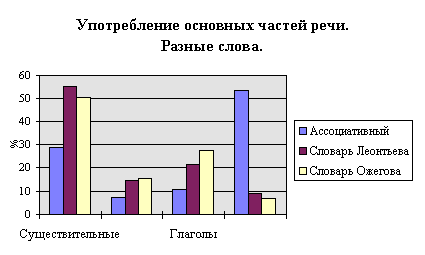
Общие результаты грамматического анализа словарей приведены в табл. 6. Диаграммы 1, 2 иллюстрируют употребление основных частей речи. Ассоциативный словарь характеризуется большим количеством наречий, значительно большим, чем в словарях Леонтьева и Ожегова. Глаголов же и существительных в ассоциативном словаре меньше, в то время как в толковом словаре употребляется значительно больше глаголов, чем в обоих ассоциативных. Трудно объяснить такое различие. Не исключено, что здесь сказывается время составления словарей (толковый — 1953, словарь Леонтьева — 1977, ассоциативный — 1994). Было бы интересно провести анализ текстов, относящихся к соответствующим годам, и проверить, не наблюдается ли и в них увеличение употребления наречий и снижение употребления глаголов. Тем не менее, существенное сходство Толкового словаря и словаря Леонтьева по употреблению основных частей речи наводит на мысль об адекватности представления в ассоциативном словаре частеречного состава языка.
| Состав |
Словарь
|
||||||||
| Ожегова | Леонтьева | Ассоциативный | Семантический | ||||||
| Всего слов | 12682 | 26517 | 39627 | 3894 | |||||
| Max частота | 465 | 731 | 1201 | 9 | |||||
| Min частота | 1 | 1 | 1 | 1 | |||||
| Число единиц | 3113 | 5713 | 8062 | 1394 | |||||
| % единиц | 24,54660148 | 21,54466946 | 20,34471 | 35,79866 | |||||
| Всего
слов/ слов max частоты |
27,27311828 | 36,2749658 | 32,995 | 432,6667 | |||||
|
Параметры
закона Мандельброта
|
|||||||||
|
p
|
5,22531E-06 | 3,23203E-07 | 1,9E-07 | 9,59E-07 | |||||
|
b
|
0,0304 | 0,0278 | 0,0214 | 0,1089 | |||||
| v | 0 | 0 | 0 | 0 | |||||
|
Словарь
|
||||||||||
|
Частотный
|
Толковый
|
Леонтьева
|
Ассоциативный
|
Семантический
|
||||||
|
слово
|
слово
|
частота
|
слово
|
частота
|
слово
|
частота
|
слово
|
частота
|
||
| в(во) | в | 465 | в | 731 | в | 1201 | история | 9 | ||
| и | на | 270 | на | 543 | на | 737 | место | 9 | ||
| не | с | 168 | не | 316 | не | 536 | строй | 9 | ||
| на | не | 163 | с | 239 | с | 380 | исторический | 8 | ||
| я | или | 132 | по | 155 | и | 338 | представлять | 8 | ||
| быть | и | 109 | к | 141 | по | 258 | фигура | 8 | ||
| что | о | 102 | и | 114 | о | 215 | опыт | 7 | ||
| он | к | 101 | человек | 108 | за | 163 | право | 7 | ||
| с (со) | разг | 95 | о | 88 | к | 152 | производство | 7 | ||
| а | по | 91 | дом | 80 | человек | 121 | пройти | 7 | ||
|
Словарь
|
|||||||
|
Толковый
|
Леонтьева
|
Ассоциативный
|
|||||
|
слово
|
частота
|
слово
|
частота
|
слово
|
частота
|
||
| в | 465 | в | 731 | в | 1201 | ||
| на | 270 | на | 543 | на | 737 | ||
| с | 168 | не | 316 | не | 536 | ||
| не | 163 | с | 239 | с | 380 | ||
| что-нибудь | 137 | человек | 212 | и | 338 | ||
| или | 132 | по | 155 | по | 258 | ||
| и | 109 | друг | 153 | человек | 229 | ||
| рука | 109 | весь | 142 | о | 214 | ||
| о | 102 | к | 141 | весь | 188 | ||
| к | 101 | хороший | 141 | друг | 184 | ||
|
Словарь
|
|||||||
|
Толковый
|
Леонтьева
|
Ассоциативный
|
|||||
| слово | частота | слово | частота | слово | частота | ||
| что-нибудь | 137 | человек | 212 | человек | 229 | ||
| рука | 109 | друг | 153 | весь | 188 | ||
| какой-нибудь | 101 | весь | 142 | друг | 184 | ||
| идти | 89 | хороший | 141 | дом | 156 | ||
| что | 86 | дом | 110 | хороший | 142 | ||
| дать | 76 | он | 103 | жизнь | 141 | ||
| он | 75 | книга | 102 | он | 135 | ||
| человек | 69 | мой | 101 | дело | 134 | ||
| место | 62 | что | 98 | что | 130 | ||
| быть | 61 | дело | 94 | себя | 112 | ||
|
Состав
|
Словарь
|
||||||
|
Ожегова
|
Леонтьева
|
Ассоциативный
|
|||||
| Общее количествораспознанных слов | 11684 | 25673 | 38158 | ||||
| Количество разных слов | 3044 | 5923 | 8188 | ||||
| Max частота | 465 | 731 | 1201 | ||||
| Min частота | 1 | 1 | 1 | ||||
| Количество
слов, употребленных один раз |
1640 | 2998 | 4119 | ||||
| Количество
слов, употребленных один раз% единичных слов |
14,03629 | 11,677638 | 10,7946 | ||||
| Средняя
частота употребления слов |
3,838371 | 4,3344589 | 4,66023 | ||||
| Отношение
общего количества слов к частоте |
25,12688 | 35,120383 | 31,7719 | ||||
|
Параметры
закона Мандельброта
|
|||||||
| p | 1,38E-06 | 3,414E-07 | 1,3E-07 | ||||
| b | 0,0237 | 0,0191 | 0,0151 | ||||
|
Словарь |
Кол-во слов |
Существительные
|
Прилагательные
|
Глаголы
|
Наречия
|
Итого |
||||||
|
частота
|
%
|
частота
|
%
|
частота
|
%
|
частота
|
%
|
|||||
|
Ожегова
|
разных | 195 | 28,59238 | 50 | 7,33138 | 72 | 10,5572 | 365 | 53,52 | 682 | ||
| всего | 5594 | 53,09911 | 1513 | 14,3589 | 1545 | 14,6626 | 1885 | 17,89 | 10537 | |||
|
Ассоциа-
ивный |
разных | 160 | 55,17241 | 42 | 14,4828 | 62 | 21,3793 | 26 | 8,966 | 290 | ||
| всего | 3838 | 57,88839 | 1173 | 17,6923 | 1083 | 16,3348 | 536 | 8,084 | 6630 | |||
|
Леонтьева
|
разных | 91 | 50,55556 | 28 | 15,5556 | 49 | 27,2222 | 12 | 6,667 | 180 | ||
| всего | 1485 | 46,83065 | 576 | 18,1646 | 959 | 30,2428 | 151 | 4,762 | 3171 | |||