4.
ИСПОЛЬЗОВАНИЕ РАЗРАБОТАННОГО ПРОГРАММНОГО КОМПЛЕКСА
В схемах технологического процесса обработки информации используются следующие условные обозначения:
4.1. Технология решения задач этапа "создания
ассоциативного словаря"
Подготовка анкет и основных таблиц
базы данных ассоциативного эксперимента
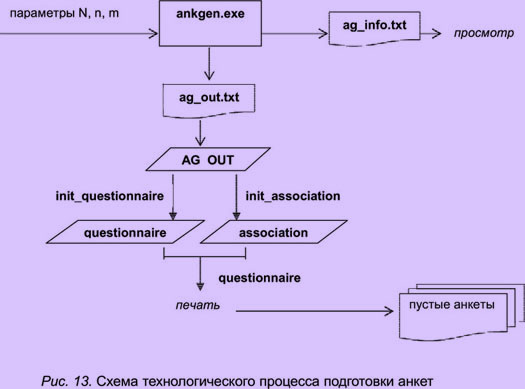
Работа с программой ankgen.exe
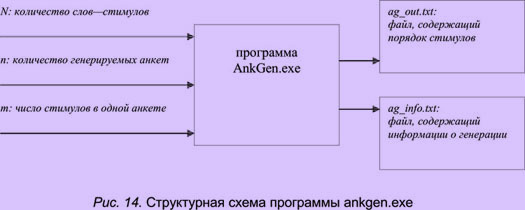
Для генерации информационного содержания анкет нужно запустить программу ankgen.exe . Ее можно запустить непосредственно с параметрами, но если они не указаны, то после начала работы программы они запрашиваются у пользователя. Параметрами программы являются: N — количество слов-стимулов; n — количество анкет; m — число стимулов по анкете. На рис. 14 приведена структурная схема работы программы генерации анкет.
Рассмотрим на простейшем примере результаты работы программы. Например, если имеется всего 6 слов-стимулов и требуется сформировать 5 анкет по 2 слова-стимула в каждой, то, запустив программу с аргументами, на экране дисплея будет выведено сообщение о введенных данных в следующем виде:
|
итоговое количество слов-стимулов (N): |
6 |
|
количество анкет (n): |
5 |
|
число слов в одной анкете (m): |
2 |
Если аргументы не указаны, то на экран дисплея будет выведено сообщение о необходимости ввода параметров аналогичного вида. После ввода последнего параметра программа начинает генерацию "матриц". В процессе генерации на экран выводится сообщение о номере текущей "матрицы" и их общее количество, которое предстоит сформировать. Это сообщение фактически является указателем степени исполнения работы:
матрица № 1 / 2
матрица № 2 / 2
В результате работы программы генерации анкет создаются два файла:
1. Файл ag_out.txt, который содержит список пар <порядковый номер> <код слова-стимула>, где <порядковый номер> — номер слова-стимула в списке, предназначенный для дальнейшего использования в базе данных.
В рассматриваемом примере (N=6, n=5, m=2) ag_out.txt имеет следующий вид:
это значит, что
|
1\6 |
в 1-й анкете присутствуют стимулы |
№ 6 и 4, |
|
2\4 |
|
|
|
3\2 |
во 2-й |
№ 2 и 3, |
|
4\3 |
|
|
|
5\5 |
в 3-й |
№ 5 и 1, |
|
6\1 |
|
|
|
7\2 |
в 4-й |
№ 2 и 5, |
|
8\5 |
|
|
|
9\4 |
в 5-й |
№ 4 и 1. |
|
10\1 |
|
|
2. Файл ag_info.txt содержит информацию о генерируемой последовательности кодов слов-стимулов:
***
AnkGen ***
N = 6
n = 5
m = 2
### Отчёт по результатам генерации. ###
Расчёт частоты проявления каждого слова:
f[ 1]= 2 f[ 2]= 2 f[ 3]= 1 f[ 4]= 2
f[ 5]= 2 f[ 6]= 1
частота проявления...
минимальная : частота[номер_слова= 3] = 1
максимальная: частота[номер_слова= 1] = 2
средняя : = 1.67
‘standard deviation’ 1/N*sqrt(sigma((частота—средняя)^2)) = 0.192
### Конец отчёта. ###
Импорт результатов работы программы генерации
Файл, содержащий последовательность кодов слов-стимулов (ag_out.txt), импортируется в таблицу Ag_out базы данных (меню Файл/Внешние данные/Импорт/от файла, в таблицу Ag_out).
Первичное заполнение таблицы анкет (questionnaire)
Таблица Ag_out является временной и служебной, так как она содержит данные в формате, удобном только для генерации анкет.
Формирование таблицы анкет осуществляется с помощью запроса init_questionnaire (инициировать анкеты). При выполнении запроса сначала с клавиатуры осуществляется ввод параметра m (количество слов в анкете), затем подсчитывается количество строк в Ag_out, результат делится на m и создается соответствующее число анкет. Каждой анкете присваивается уникальный номер, который хранится в таблице questionnaire. Кроме этого с клавиатуры вводится код группы, который записывает в каждую создавшуюся строку таблицы.
Первичное заполнение таблицы ассоциаций (association)
Таблица association включает следующие поля: номер ассоциации (ключевое поле), номер анкеты, код слова-стимула, слово-реакция. Она формируется запросом init_association (инициировать таблицу "ассоциация"). Суть работы запроса состоит в создании записи в этой таблице и заполнении трех первых полей. Поля "номер ассоциации" и "код стимула" непосредственно переписываются из соответствующих полей таблицы Ag_out. Значение поля "номер анкеты" вычисляется по номеру ассоциации и значению введенного параметра "число слов в анкете".
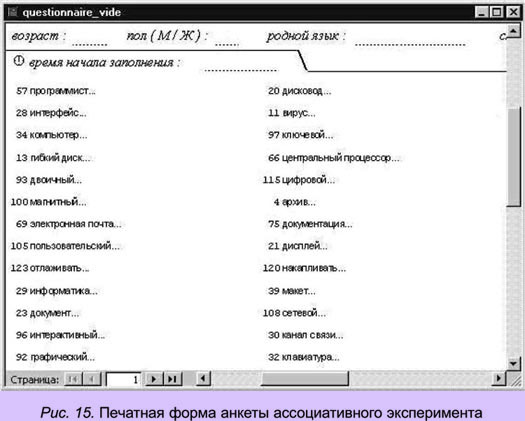
Печать анкет
Печать анкет осуществляется с помощью отчета "анкета", который на основе созданных и заполненных таблиц, а также вводимого параметра m (количества анкет) формирует печатную форму, представленную на рис. 15.
Ввод результатов анкетного опроса
(заполненных анкет)
Для ввода результатов анкетного опроса могут использоваться две технологии. Первая (основная) ориентирована на непосредственную работу с созданной базой данных исследования, которая использовалась для распечатки анкет. Вторая (альтернативная) предполагает независимый ввод анкет сначала в текстовый файл, а затем его импорт в базу данных.
Основная технология ввода данных: через маски ввода
Ввод данных анкет непосредственно в таблицы базы осуществляется с использованием масок ввода таблицы "анкета" и является самым удобным и защищенным от ошибок способом. Для ввода данных достаточно набрать на клавиатуре в окнах соответствующих масок значения заполненных респондентами полей анкеты. На рис. 16 представлена схема технологического процесса ввода данных с использованием первой технологии, а на рис. 17 — внешний вид экрана дисплея во время ввода.
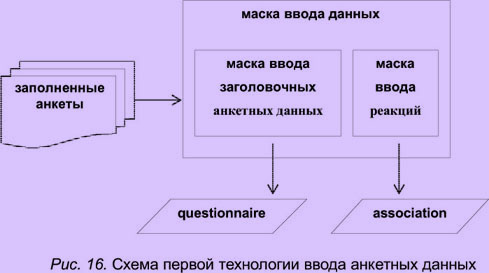

Рис.
17. Маски ввода анкетных данных
Альтернативная технология ввод данных: через текстовый файл.
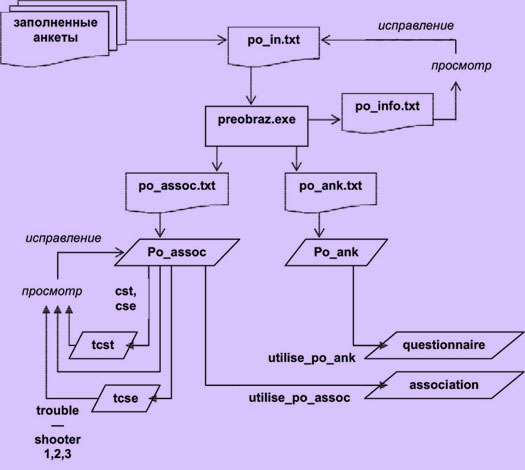
Этот способ сложный и гораздо менее удобный, чем первый. Это отрицательно сказывается на качестве ввода: оператор быстрее утомляется и допускает ошибки. Вместе с тем, он более гибкий и позволяет распределить работы по вводу данных между несколькими операторами и тем самым сократить сроки ввода. Кроме этого он не требует использования самой базы данных исследования и навыков работы оператора с СУБД (достаточными являются навыки работы с простейшими текстовыми редакторами).
Ввод анкет.
Итак, допустим, что существуют две анкеты:
номер анкеты: 1—0001
возраст: 20 / пол: ж / специальность: ИУ5—51
/ родной язык: русский / дата: 30.05.99 / время начала заполнения: 15:00 /
время конца заполнения: 15:15
|
12 операционная система… |
Unix |
|
97 настольный… |
компьютер |
|
4 поиск… |
файла |
|
21 переменная… |
тип данных |
…
номер анкеты: 1—0014
возраст: 23 / пол: м / специальность:
технолог / родной язык: русский / дата: 06.06.99 / время начала заполнения:
10:50 / время конца заполнения: 11:00
|
52 массовая память… |
RAM |
|
66 концентратор… |
Ethernet |
|
71 оптимизировать… |
алгоритм |
|
2 первичный ключ… |
таблицы |
…
Оператор ввода должен записать эти данные (например, в файле А0001.txt) как последовательность строк, а в каждой строке — значение только одного из полей анкеты, заполненных респондентом. При вводе слов-реакций необходимо сначала ввести код слова-стимула. После ввода всех данных необходимо ввести маркер конца анкеты "***".
1—0001
20
ж
ИУ5—51
р
30.05.99
15:00
15:15
12
Unix
97
компьютер
4
файла
21
тип данных
***
1—0014
23
м
технолог
р
06.06.99
10:50
11:00
52
RAM
66
Ethernet
71
алгоритм
2
таблицы
***
Предварительная проверка файла и преобразование его формата.
Перед записью введенных анкет в базу данных содержащаяся в них информация должна быть разделена. Программа preobraz сначала последовательно извлекает из текстового файла заголовочные данные и ассоциации, далее осуществляет их раздельное форматирование, контроль и выявление ошибок, а потом записывает в два различных файла. В процессе работы программы обнаруживаются ошибки нескольких видов, сообщения о них фиксируются в специальном файле, доступном пользователю. Перед запуском программы preobraz.exe нужно переименовать исходный текстовый файл с введенными анкетами в "po_in.txt". В результате работы программы создаются следующие файлы:
po_info.txt — файл сообщений программы;
po_ank.txt — файл, содержащий отформатированные заголовочные анкетные данные;
po_assoc.txt – файл, содержащий отформатированные ассоциации.
Ниже представлены примеры этих файлов:
//po_info.txt:
***
PREOBRAZ: info ***
входный файл ‘po_in.txt’ загружен
— — — накопление данных заголовков анкет — —
—
read_ank_data() — ошибка в заголовке анкеты
2—98
read_ank_data() — ошибка в заголовке анкеты
2—105
количество найденных блоков ассоциаций: nzones
= 30
— — — накопление ассоциаций — — —
main — внимание — 99 (<>100) ассоциаций
читалось в анкете 2—91
main — ошибка — в анкете 2—100 два раза
встретился код слова 71
main — ошибка при чтении ассоциации анкеты
2—100
после кода слова читался разделитель блока
***
main — ошибка — в анкете 2—110 два раза
встретился код слова 118
main — внимание — 99 (<>100) ассоциаций
читалось в анкете 2—110
main — ошибка — в анкете 2—112 два раза
встретился код слова 15
main — ошибка при чтении ассоциации анкеты
2—120
неверный код слова: 1054
— — — КОНЕЦ — — —
//po_ank.txt:
2\86\22\ж\гр. 15—2\р\02.06.99\20.15\20.30
2\87\22\ж\Г — 15\р \02.06.99\20.15\—
2\88\22\ж\ЭВ—5—81\Р\2.06.99\20.15\20.35
2\89\21\ж\ЭВ—5—2\р\02.06.99\20.12\20.30
2\90\23\ж\ЭВ—5—2\р\02.06.99\20.15\20.30
2\91\21\ж\экономист\р\02.06.99\20.15\20.35
2\92\22\ж\экономист\р\02.06.99\20.15\20.30
//po_assoc.txt:
2\86\5\хранилище
2\86\20\дискета
2\86\11\болезнь
2\86\121\регулировать
2\86\21\экран
2\86\75\файл
2\86\125\начать с начала
...
После выполнения программы следует прочитать сообщения в файле po_info.txt, посмотреть содержание файлов po_assoc.txt и po_assoc.txt для того, чтобы понять, где находятся ошибки в исходном файле po_in.txt, а затем их исправить.
Импорт введенных анкет и вторичная проверка
После предварительной проверки, преобразования и исправления введенных анкет оператор загружает файлы "po_ank.txt" и "po_assoc.txt" в таблицы "Po_ank" и "Po_assoc". На этом этапе ввода анкетных данных они вторично проверяются на соответствие наборов кодов слов-стимулов и только потом записываются в основные таблицы. Для этого необходимо:
1. Вызвать запросы cse и cst. Они создают служебные таблицы tcse и tcst.
2. Вызвать запросы troubleshooter1, troubleshooter2 и troubleshooter3. Они создают служебные таблицы tb1 (список неправильных кодов), tb2 (список отсутствующих кодов) и tb3 (список повторяющихся кодов).
3. Открыть таблицы Po_assoc, tb1, tb2 и tb3. В таблицах tb1 и tb3 указаны номера ошибочных строк таблицы Po_assoc и позиция "подозрительных" кодов в анкете ("координаты" — колонка, строка). В таблице tb2 выдаются номера ассоциаций.
4. Найти ошибки и исправить Po_assoc.
5. Анкетные данные запросами utilise_po_ank и utilise_po_assoc (utilise – использовать) переписываются из Po_assoc и Po_ank в таблицы "ассоциация" и "анкета".
6. Записи вспомогательных таблиц Po_assoc и Po_ank удаляются.
Визуальная проверка сопоставлением бумажной и электронной анкет
Можно сделать еще одну проверку, направленную на обнаружение ошибок при вводе слов-реакций. Она заключается в визуальном сопоставлении бумажных анкет с ее электронным представлением, являющимся результатом операций ввода. При этом все поля и ассоциации должны совпадать. Для этого достаточно открыть отчет "questionnaire" (анкета) — тот самый, который используется для составления пустых анкет. На экране дисплея появится заполненная анкета. Внешний вид экрана представлен на рис. 18.

Формирование ассоциативного
словаря
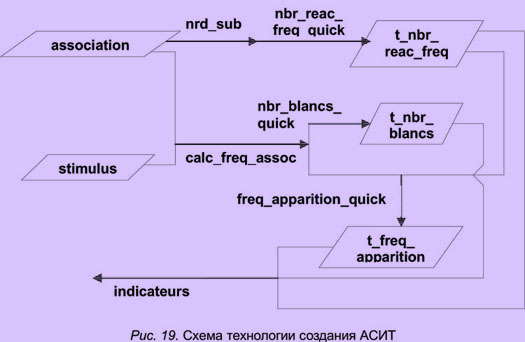
Формирование ассоциативного словаря информационных технологий состоит в расчете количественных характеристик слов-реакций слов-стимулов, формировании словарных статей и их печати. Схема технологического процесса создания АСИТ представлена на рис. 20.
Расчет количественных характеристик
Для каждого слова-стимула рассчитываются количественные характеристики: количество его проявлений в анкетах, количество разных реакций на него, количество пропусков.
Эти данные являются результатом запроса indicateurs ("указатели"). Indicateurs базируется на записях трех таблиц: t_nbr_reac_diff, t_freq_apparition, t_nbr_blancs, которые созданы тремя запросами nbr_reac_diff_quick, freq_apparition_quick, nbr_blancs_quick. Необходимо запустить эти три запроса.
Формирование прямого и обратного словарей
Можно просмотреть прямой и обратный словари непосредственно в базе данных, открыв отчеты "dico_direct" и "dico_indirect".
Полуавтоматическая предварительная верстка словарей в текстовом
редакторе
Основной средой составления ассоциативного словаря является текстовый редактор Microsoft Word. Для экспорта, например, отчета прямого словаря dico_direct нужно выбрать опцию меню "Сохранить как / экспорт" и сохранить его с именем dd_xport в формате RTF. Далее в Microsoft Word открыть этот файл, открыть окно модуля "найти / заменить" и совершить последовательно такие операции:
|
искать |
заменить |
|
^m |
(ничем) |
|
^t\\-^^t\: \ |
: |
|
\\+^^p^^t\\^p^t |
(ничем) |
|
\\+^^p\\^p |
(ничем) |
|
; \\-; \\ |
(ничем) |
В результате этого словарные статьи примут следующий вид:
5: Калашникова 4: конечный 3: Калашников; оружие; пистолет; пулемет 2: машина; экзамен 1: автоматная очередь; АК; аппарат; банковский; вода; война; ВПГ; газир. вода; газировка; запах; зачет; игровой; интеллект; компьютер; не человек; первичный; прибор, устройство; робот; теория автоматов; теория формальных языков; язык (o47, d29, v1)
|
Автомат |
адаптер |
|
5: Калашникова 4: конечный 3: Калашников; оружие; пистолет; пулемет 2: машина; экзамен 1: автоматная очередь; АК; аппарат; банковский; вода; война; ВПГ; газир. вода; газировка; запах; зачет; игровой; интеллект; компьютер; не человек; первичный; прибор, устройство; робот; теория автоматов; теория формальных языков; язык (o47, d29, v1) |
9: сетевой 4: видео 3: переходник; сеть 2: драйвер; устройство 1: VGA; батарейка; блок питания; видеокарта; группа микросхем; диск; карта; комплектующие; модем; оборудование; объединение; плата; помощник; прибор; приспособить; приспособлять; программа; регулировщик; связи; совмещение; устройство преобразования; фаза; хорошо (o48, d29, v2) |
|
агрегат |
администратор |
|
7: машина 4: аппарат 2: прибор; устройство 1: большой станок; большой; груда железа; двигатель; завод; комбайн; компьютер; мощный; напыление; огородный; отладки; помощник; работает; самовар; силовой; сложный; сломался; стандартный; станок; трактор; турбо; установка; холодильник; часть машины (o45, d28, v6) |
17: сети 10: сеть 2: системный; супервизор 1: Sysop; UNIX; БД; большой начальник; все права; главный; казино; контролер; начальник; ответственное лицо; пользователь; ректор; сетевой; системы; управляющий; человек (o48, d20, v1) |
4.2. Технология создания ассоциативного тезауруса
Предварительная подготовка АСИТ к
кластеризации
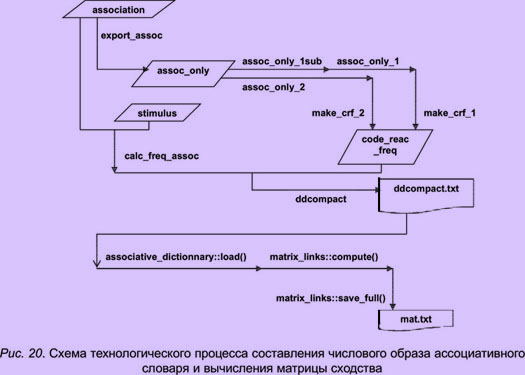
Форматирование ассоциативного словаря в числовом виде
Ассоциативный словарь экспортируют в модуль кластеризации в специальном числовом виде. Это осуществляется путем выполнения следующих операций: сначала запускается запрос export_assoc, затем make_crf_1 и make_crf_2. В результате получается таблица слов-реакций, снабженных кодом реакции и частотой встречаемости, которая представлена на рис. 21. Далее остается экспортировать результат запроса ddcompact во внешний текстовый файл ddcompact.txt.
Расчет дополнительных указателей
Некоторые меры связи используют следующую информацию для расчета силы связи между стимулами: сходство ("суперсвязь") слова-реакции со словом-стимулом, частоту встречаемости слов-реакций и количество слов-стимулов, в ассоциативных дефинициях которых имеются данные реакции.
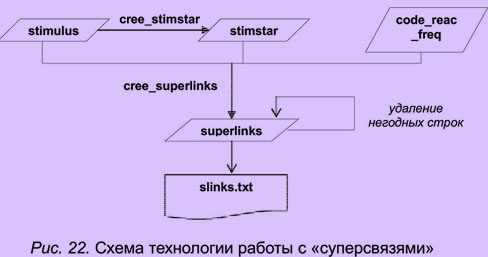
Для создания файла частотных характеристик слов-реакций достаточно экспортировать результат запроса popularite.
Для составления списка "суперсвязей" нужно вызвать запросы cree_stimstar и cree_superlinks. Открыть таблицу superlinks и удалить записи, которые не удовлетворяют представлению исследователя о сходстве. Затем можно экспортировать полученный файл. Схема технологического процесса обработки "суперсвязей" представлена на рис. 21.
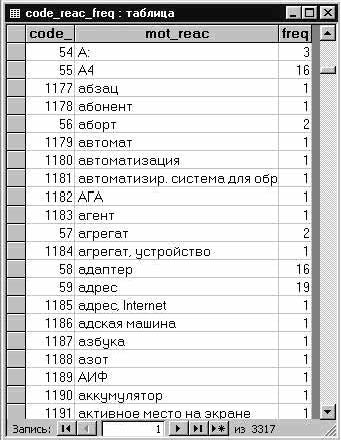
Рис.
21. Таблица частот слов-реакций
Мера связи и подготовка данных к
кластеризации
Схема технологии подготовки данных к кластеризации приведена на рис. 22.
Описание меры связи
Меру связи исследователь пишет на языке C++ в файле plug_ins.hpp в виде класса, наследующего абстрактному классу measure. Нужно написать свою методику d(), в которой вычисляется значение меры связи.
Вычисление матрицы сил связи
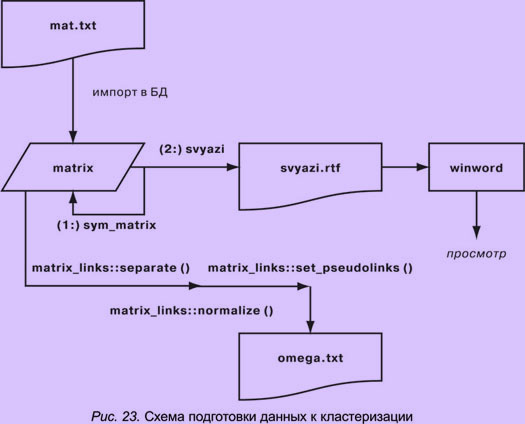
Первым этапом построения тезауруса является ввод ассоциативного тезауруса из файла, который был экспортирован из базы данных.
Для этого нужно создать объект типа "ассоциативный словарь" и загрузить файл:
associative_dictionnary ad;
ad.load(fn_ad);
Следующий шаг — создание объекта "мера" и объекта "матрица связей", при этом указывается, на основе какого ассоциативного словаря и какой меры строится матрица.
svyaz_M sm(0, "коэффицент связанности ‘svyaz_m’");
matrix_links Z(ad,sm);
Далее автоматически запускается процедура вычисления элементов матрицы, т.е. значений меры связи. Можно сохранить матрицы в файл, чтобы затем изучать установленные связи между стимулами:
Z.save_full("zf.txt");
Анализ значений меры
Файл zf.txt импортируется в таблицу БД "матрица". Но он содержит только одну "верхнюю половину" симметричной матрицы. "Нижняя половина", нужная для упрощения последующей обработки данных, восстанавливается запросом sym_matrix.
Затем полученная таблица экспортируется в текстовый редактор как результат отчета "svyazi" для его автоматического оформления в виде печатного документа (аналогично верстке ассоциативного словаря). Этот документ представляет каждый стимул, снабженный списком связанных стимулов с указанием значения меры оценки связи.
Предварительное разбиение.
Матрица, полученная в результате описанных преобразований, содержит множество нулей. При их изучении можно обнаруживать подсети стимулов. Это изучение осуществляется процедурой separate(). После ее выполнения выдаются отдельные подмножества стимулов. Если таких подмножеств больше одного, то это значит, что были обнаружены подсети. Поэтому дополнительно следует создать соответствующие матрицы связи, которые нужно будет обрабатывать отдельно.
Установление псевдосвязей
Автоматическое установление псевдосвязей обеспечивает метод set_pseudolinks. Его параметр — функция оценки цепочек связей path_value, который нужно описать в файле plug_ins.hpp. В результате работы метода получается новая матрица, не содержащая ни одного нуля.
Z_=Z.set_pseudolinks(path_value);
Преобразование в матрицу расстояний и нормализация
Затем необходимо преобразовать матрицу сил связи в матрицу расстояний между стимулами с помощью процедуры normalize. Заодно набор значений расстояний распределяется по диапазону, заданному пользователем, и сохраняется в виде текстового файла.
Z_.normalize(999,1);
Z_.save("z_.txt");
Кластеризация
Схема работы модуля кластерного анализа представлена на рис. 24.
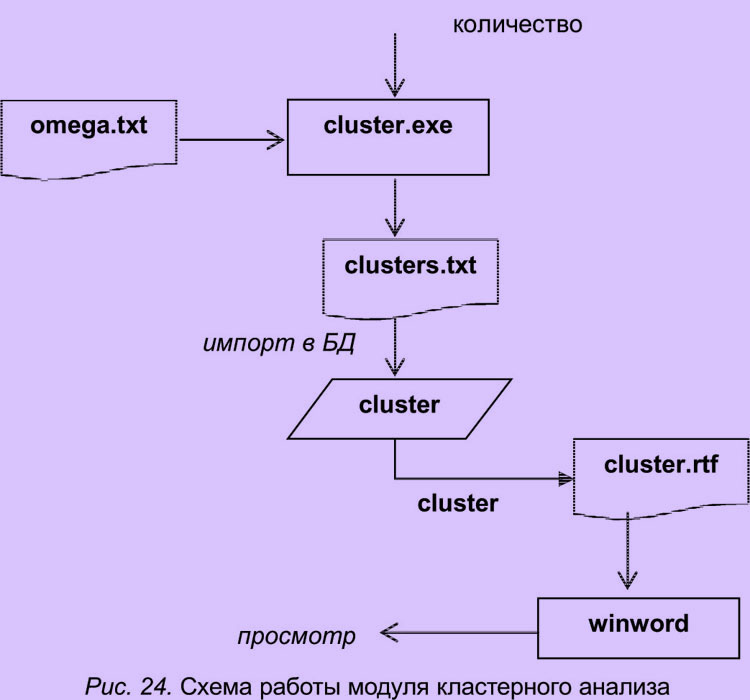
Взаимодействие с модулем кластеризации
Процессом кластеризации управляет объект типа clusterizator, поэтому он сначала создается. Конструктору передается матрица расстояний.
clusterizator C(Z_);
Сам процесс кластерного анализа запускается вызовом метода clusterize для этого объекта. В качестве параметра принимается желанное количество кластеров.
C.clusterize(nbr_of_clusters);
Далее экспортируют результат кластеризации в БД через текстовый файл, используя процедуру save.
C.save("cluster.txt");
Представление полученных кластеров
Загрузив файл cluster.txt в таблицу "кластер" базы данных, можно просматривать содержание ассоциативного тезауруса с помощью отчета "кластер", в котором представляются отдельные группы наиболее связанных между собой слов-стимулов.