2.
РАЗРАБОТКА АССОЦИАТИВНОГО СЛОВАРЯ
Состав списка слов-стимулов
Список слов-стимулов ассоциативного эксперимента был получен следующим образом.
Сначала был определен корпус текстов, представляющий предметную область "Информатика и вычислительная техника". Этот корпус текстов составили статьи различных авторов, опубликованные в журнале "Computer Week" в 1995 году. После обработки этих текстов был составлен частотный словник, который представляет собой список слов текста, расположенных в порядке убывания их частоты проявления. При построении частотного словника все словоформы текста были приведены к основной грамматической форме (например, существительные — именительный падеж, единственное число; глаголы — инфинитив т.д.). Из общего списка слов были удалены слова общеупотребительной лексики, имена персоналий, наименования конкретных товаров, торговые марки и пр. Так были выделены самые употребляемые слова данной предметной области, например прилагательные — "системный", "двоичный", глаголы — "отлаживать", "эмулировать" и существительные — "дисковод", "маршрутизация".
Далее были сформированы два списка слов-стимулов для двух ассоциативных экспериментов. Первый список предназначен для испытуемых, имеющих более высокий уровень знания о предметной области, для студентов компьютерных специальностей ("технарей" — специалистов). Второй список предназначен для студентов, хуже знакомых с предметной областью "Информатика и вычислительная техника", для студентов гуманитарных специальностей ("гуманитариев" — неспециалистов).
Оба списка использовались для опроса русскоязычных респондентов ("русский ассоциативный эксперимент"). Второй список после перевода на французский язык использовался для опроса франкоязычных респондентов ("французский ассоциативный эксперимент").
Оба русских списка и французский перевод второго приведены в приложении.
Респонденты
В эксперименте в качестве испытуемых принимали участие студенты трех высших учебных заведений: Московского государственного технического университета им. Н.Э. Баумана — МГТУ, Московского государственного университета печати — МГУП, Ecole Centrale de Lyon (Высшей инженерной школы г. Лион, Франция) — ECL.
Количественные характеристики
экспериментов
Русский ассоциативный эксперимент на основе первого списка слов-стимулов
(для специалистов):
|
Количество стимулов |
253 |
|
Количество стимулов в анкете |
100 |
|
Количество заполненных анкет |
126 |
|
Общая частота предложения стимула |
от 43 до 53 |
|
Количество разных ассоциативных пар |
7331 |
|
Количество разных реакций |
4057 |
Распределение респондентов по специальностям:
|
ВУЗ |
Направление и специальность |
Количество |
|
МГТУ |
Направление: “ …” — 46. Специальность “Автоматизированные системы обработки информации и управления” — 220200 (студенты кафедры “Системы обработки информации и управления” — ИУ5) |
91 |
|
МГТУ |
Направление: “….” — …. Специальность: Инженерный бизнес и менеджмент (студенты кафедры ….. — ИБМ5) |
14 |
|
МГУП |
Автоматизация издательства (студенты кафедры “Информационные технологии”, группа АМ45) |
19 |
|
МГУП |
Другие специальности |
2 |
Русский ассоциативный эксперимент на основе второго списка слов-стимулов:
|
Количество стимулов |
128 |
|
Количество стимулов по анкете |
100 |
|
Количество заполненных анкет |
111 |
|
Общая частота проявления стимула |
от 122 до 141 |
|
Количество разных ассоциативных пар |
5328 |
|
Количество разных реакций |
3318 |
Распределение респондентов по специальностям:
|
ВУЗ |
Направление, специальность |
Количество |
|
МГУП |
редакторы (...) |
39 |
|
МГУП |
экономисты (Э5) |
28 |
|
МГУП |
другие |
44 |
Французский ассоциативный эксперимент на основе перевода с русского языка
на французский большинства слов-стимулов второго списка:
|
Стимулов |
118 |
|
Стимулов по анкете |
60 |
|
Заполненных анкет |
113 |
|
Общая частота проявления стимула |
от 62 до 74 |
|
Разных ассоциативных пар |
3906 |
|
Разных реакций |
2459 |
Распределение французских респондентов по курсу:
|
Курс: |
1 |
2 |
3 |
|
Количество: |
64 |
61 |
8 |
2.2. Описание функционирования программ
Программа генерации анкет: AnkGen
Требования к программе
Требования к результатам работы программы "генерации анкет" следующие:
1. выбор стимулов должен осуществляться случайным образом;
2. в каждой анкете любое слово-стимул должно появляться не более чем один раз;
3. суммарные частоты проявления слов-стимулов должны быть близкими по значению, иными словами, распределение стимулов в массиве анкет должно стремиться к равномерному.
Основные идеи
Следующая идея положена в основу функционирования программы генерации анкет: можно удовлетворить требованиям (1) – (3), формируя так называемые "матрицы" — набор всех слов-стимулов, расположенных в случайном порядке, который затем для получения анкет "разрезается" на части размера m (m = количество стимулов, содержащееся в одной анкете).
Этот подход, прежде всего, обеспечивает выполнение условия (2). Более того, в идеальном случае, когда остаток деления N (общего количества слов-стимулов, или размера матриц) на m (размер анкеты) равен нулю, суммарные частоты проявления стимулов в массиве анкет одинаковы, т.е. выполняется требование (3).
Под "одинаковыми" здесь понимаются такие значения частот проявления слов-стимулов, о которых можно сказать, что они "равны с допускаемой погрешностью [+0,+1]". Абсолютную равномерность распределения получить нельзя, кроме тех случаев, когда, уже находясь в выше названном "идеальном" случае, все анкеты из последней генерируемой матрицы оказываются нужными, т.е. когда
Res ( N/m ) = Res ( m´ n/N ) = 0,
где n — количество генерируемых анкет.
Теоретически реализация рассмотренного подхода представляется весьма простой, но на самом деле при произвольных значениях параметров N, m и n в большинстве случаев достаточно сложно получить результат, удовлетворяющий требованию (3). Как это достигается, рассматривается далее, но сначала следует рассмотреть алгоритм генерации самих матриц.
Генерация матриц
Матрица представляет собой список всех слов-стимулов, перемешанных в случайном порядке, в ней каждый стимул встречается точно один раз.
Можно было бы создать матрицы следующим образом:
шаг 1 — получить число z от генератора случайных чисел в диапазоне [1..N];
шаг 2 — проверить, что z ранее не получалось, и в случае если — да, то перейти к шагу 1, если нет — к шагу 3;
шаг 3 — записать z как очередной элемент матрицы и перейти к шагу 1, чтобы выбрать следующий элемент.
При использовании такого алгоритма создания матрицы время ее генерации не огранивается, оно практически может оказаться очень долгим. А если учесть, что требуемое число матриц может быть немалым, то такой алгоритм оказывается неприемлемым.
Для создания матрицы выбран следующий подход. Сначала создаётся таблица допускаемых, но пока невыбранных стимулов — t, содержащая все номера слов-стимулов. Переменная width ("ширина" таблицы t, её текущий объём) загружается значением N. Далее в каждом цикле: 1) получается от генератора случайных чисел значение переменной z, лежащее в диапазоне [1..width]; 2) переменной x, которая является очередным создаваемым элементом матрицы, присваивается значение z-го элемента таблицы t; 3) из таблицы t удаляется z-й элемент (он равен значению переменной x) и из переменной width вычитается единица.
На самом деле алгоритм выглядит иначе, он немного усложнен для того, чтобы программа его реализации функционировала быстро. В программе описан класс "offset_table", имеющий таблицу t и снабженный методами clear() — очистить, pick() — получить x, предоставив z.
//класс offset_table
// предназначен для управления таблицей table, содержащей 'offsets'// номеров слов, которые ещё не были взяты.// Элементы таблицы table называются 'offsets' ('переместителями'),// потому что, если i в диапазоне [head,tail], то x = i+table[i] -// это номер 'свободного слова'.class offset_table
{protected:
int head; //индекс начала полезной (действующей) зоны таблицыint tail; //индекс конца полезной зоны таблицыint middle; //индекс середины полезной зоны таблицыint nbr_stimuli; //первоначальный размер таблицыint *table; //таблица, содержащая оффсеты public:int pick(const int); //аргумент: z, результат: x
//удалить из таблицы z-й элемент //и выдать через х его значениеint zap(const int); //аргумент: x, результат: z
//вызвать pick с аргументом, равным позиции
//z-го номера слова х в таблице.int pop(const int); //аргумент: х, результат: 0
//восстановить номер слова хvoid clear(void); //убрать таблицуvoid display(void); //показать информацию о таблице на экране
void display(FILE *); //записать информацию о таблице в файле
int get_head(void); //читать числовое значение headint get_tail(void); //tail (индекс конца действующей зоны)int get_middle(void); //middleint get_width(void); //tail-head+1 ('ширина' действ. зоны)int getsize(void); //nbr_stimulioffset_table(const int);
~offset_table(void);
};
Также описан класс "xfilter", предназначенный для вывода последовательности значений x через метод feed() к файлу "ag_out.txt", и сохранению её для того, чтобы потом подсчитать указатели распределения.
//класс xfilter
// предназначен для вывода номеров слов.// Его название указывает на понятие 'вывод' (x: eXit) и на слово// 'фильтр', потому что он выводит лишь нужное количество номеров// слова, так как самые последние, генерируемые главной программой,// являются лишними. // Дополнительно к функциям фильтра и вывода, xfilter предостав-// ляет возможность рассчитать и выдать указатели распределения// слов.class xfilter
{protected:
int nmax; //нужное количество слов
int n; //счётчик выведенных номеров слова (НС)
FILE *fh; //file handler
int *xx; //таблица для хранения последовательности НС
// (для расчётов процедуры report() ).
public:int feed(int ); //предоставить один НС
// объекту xfilter ('кормить').
int report(FILE *,int ,int ,int ); //записать в (отдельном) файле
// информацию о распределении НС.
xfilter(const int ,FILE *); ~xfilter();};
Если output типа xfilter и T типа offset_table, то одна матрица генерируется в результате работы следующей группы инструкций:
while ( (width=T.get_width()) > 0 ) //пока матрица не исчерпана...{z = random(width); //получение случайного индекса zx = T.pick(z); //извлечение z-го элемента матрицы: xoutput.feed(x); //вывод x};
Функционирование программы
Допустим, что ненулевыми являются остатки деления N на m и m*n на N (общий случай).
Сначала генерируются анкеты А1 и А2. На этом генерация матрицы М1 заканчивается, но номера слова, которые присутствуют в той части анкеты А3, которая принадлежит М1, не только записываются как остатки в файле ag_sequ.txt, но и сохраняются в специальной таблице x_ostatka[].
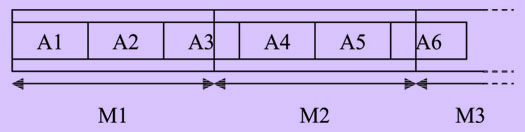
До начала генерации М2 с помощью метода zap() инициируют таблицу допустимых стимулов, являющуюся членом объекта типа offset_table, тем самым удаляют номера таблицы x_ostatka[] для того, чтобы во второй части А3 не оказались стимулы, уже присутствующие в первой части.
Генерация М2 начинается с генерацией второй части А3. Когда она завершена, посредством функции pop() восстанавливаются ранее удаленные номера слова, хранящиеся в x_ostatka[] (они не могли появиться во второй половине А3, но должны быть где-нибудь в остатке матрицы М2).
Результаты работы программы
Программа сохраняет все коды. По завершении генерации рассчитываются статистические величины, характеризующие распределение слов-стимулов в массиве генерируемых анкет, которые потом предоставляются пользователю в виде отдельного файла. Речь идет о списке частот проявления каждого стимула и о средней частоте. Другой файл содержит саму последовательность кодов слов-стимулов, которая затем импортируется базой данных.
Программа проверки и
преобразования файлов, содержащих ассоциации, для применения 2-й технологии
ввода данных
Формат исходного файла
Оператор ввода данных ассоциативного эксперимента набирает на клавиатуре всю информацию, относящуюся к конкретной анкете, а именно: номер анкеты, возраст респондента, его пол, родной язык, специальность, дату опроса, время начала и конца заполнения анкеты, а затем пары "код стимула — слово-реакция". Набранные данные записываются в текстовый файл.
При вводе данных оператор должен соблюдать следующие ограничения:
· номер анкеты имеет следующую структуру: <код группы>—<номер анкеты>, при этом в программе можно указать допустимые значения кода группы и номеров анкеты;
· пол принимает значение "ж" — женский или "м" —мужской;
· возраст должен быть целым числом и отражать полное число лет, прожитых респондентом, это число должно находиться в заранее указанных пределах;
· дата и время начала и конца заполнения анкеты должны быть введены обязательно;
· код стимула должен быть в диапазоне [KODSLOVA_MIN, KODSLOVA_MAX] — эти значения задаются программе в качестве параметров;
· слово-реакция записывается после кода стимула;
· каждое из всех вышеупомянутых сведений должно быть указано в отдельной строке файла;
· если испытуемый не ответил на какой-то вопрос или стимул, т.е. в анкете отсутствуют соответствующие сведения, то вводится знак отсутствия ответа: "–" — "минус";
· после ввода последней реакции (т.е. после 100-й реакции) нужно ввести маркер конца текущей анкеты (разделитель анкет) — "***".
Формально-логический контроль выполнения перечисленных требований осуществляется программой проверки и преобразования исходного файла — preobraz.
Обнаружение разделителей анкет и чтение заголовочных данных
Исходный файл целиком загружается в оперативную память. Первая часть программы preobraz ищет разделители анкет "***" и читает заголовочные данные (возраст, пол и т.д.). Эти данные сразу записываются в файл po_ank.txt. Для каждой анкеты адрес начала области памяти, где находятся ассоциации, сохраняется в специальном объекте типа assoc_zone.
После завершения работы первой части программы в файле сообщений po_info.txt записывается найденное количество анкет.
Чтение ассоциаций
Дальше работает вторая часть программы, которая выполняет чтение и преобразование ассоциаций, а также обнаружение ошибок в них. Для каждой анкеты программа начинает чтение ассоциаций с места, которое было сохранено в объекте assoc_zone. Ожидается последовательность пар строк "код стимула, слово–реакция". Если обнаружен ненормальный код стимула или досрочное появление разделителя анкет, то соответствующее сообщение записывается в файл po_info.txt.
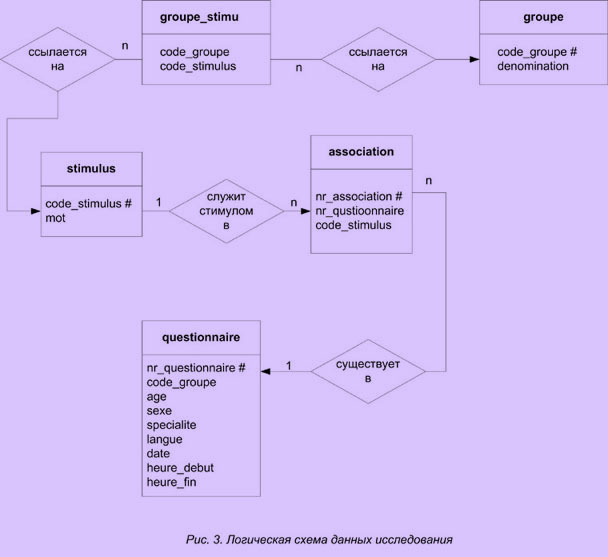
Структура БД
База данных исследования состоит из следующих основных таблиц:
Таблица groupe (группа) предназначена для работы с различными списками слов-стимулов. В нее входят следующие поля: код_группы* (символ "*" показывает, что данное поле ключевое), наименование.
Таблица stimulus (стимул) содержит список слов-стимулов. В нее входят поля: код_стимула*, слово_стимул.
Таблица groupe_stimulus (группа_стимул) связывает слово-стимул со своей группой. В нее входят поля: код_стимула, код_группы.
Таблица questionnaire (анкета) содержит анкетные данные. Ее полями являются: номер_анкеты, возраст, пол, язык, дата, время_начала, время_конца.
Таблица association (ассоциация) предназначена для хранения распределения слов-стимулов по анкетам и соответствующих слов-реакций (ассоциаций).
В ее составе следующие поля: код_ассоциации*, номер_анкеты, код_стимула, слово-реакция.
Логическая схема базы данных исследования представлена на рис. 3.
Инициализация
Содержание таблиц "группа", "стимул" и "группа_стимул" вводится пользователем.
Для инициализации таблиц "анкета" и "ассоциации" импортируется результат программы генерации анкет, т.е. последовательность код-стимулов, во вспомогательную временную таблицу AG_OUT. Запросы "иниц_анкеты" и "иниц_ассоц" обрабатывают ее, распределяя блоки стимулов по анкетам и вставляя соответствующие строки в таблицы "анкета" и "ассоциации". После этой операции таблица AG_OUT может быть удалена.
Инструменты ввода и проверки
введенных данных
Ввод данных в таблицы "анкета" и "ассоциация" осуществляется с помощью функции СУБД Access "Маска ввода данных".
Технология ввода данных на основе текстовых файлов анкет допускает много различных видов ошибок. Ошибки, относящиеся к определенным классам, обнаруживаются программой preobraz. К недопустимым ошибкам, которые значительно влияют на результаты обработки данных эксперимента, относятся, прежде всего, ошибки набора кодов слов-стимулов. Опишем функционирование средства устранения этих ошибок, схема представлена на рис. 4.
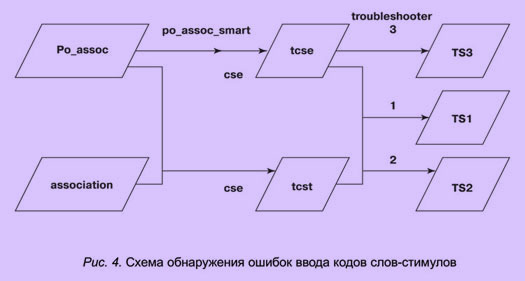
Для обнаружения и исправления ошибок набора кодов слов-стимулов сформированный текстовый файл анкетных данных предварительно импортируется в служебную таблицу Po_assoc. Перед тем как ее содержание будет переписано в таблицу association, в ней необходимо устранить все ошибки.
Обнаружение ошибок осуществляется путем сопоставления списка введенных кодов слов-стимулов (далее "введенный список" — ВС) и списка кодов, присутствующего в БД (далее "исходный список" — ИС). Сначала находятся коды в ВС, которые отсутствуют в ИС (ошибка типа О1), и наоборот (код имеется в ИС, но его нет в ВС — О2), затем проверяется по ВС выполнение требования о запрещении повтора кода слова-стимула в анкете (О3). Необнаруженными остаются ошибки, которые соответствуют следующей ситуации: оператор ввел код2 вместо код1, и далее, когда встретился код2, снова ошибся и набрал код1. В результате обнаружения ошибок оператору ввода данных предъявляются три таблицы, содержащие найденные ошибки каждого типа. Эти таблицы называются troubleshooter1, troubleshooter2, troubleshooter3 (на схеме, TS1, TS2, TS3).
Таблицы troubleshooter1 (присутствие "чужих" кодов) и troubleshooter2 (отсутствие кодов) создаются после сравнения содержания таблиц cse и cst. Таблица tcse содержит ВС, а tcst — ИС. Заметим, что cse показывает, где находится "чужой" код слова-стимула на анкете (колонка №X, строка №Y), что делает проверку весьма удобной. Позиции (X,Y) каждого кода на анкете рассчитывает запрос po_assoc_smart.
Запрос cse извлекает список кодов стимулов и их позиции из Po_assoc_smart и из самой Po_assoc:
cse
SELECT
[po_assoc].[jnr_quest] & "-" & [po_assoc].[jcode_stim] AS cse, po_assoc_smart.position, po_assoc_smart.КодINTO
tcseFROM
po_assoc_smart, po_assocWHERE
(((po_assoc_smart.Код)=[po_assoc].[Код]))ORDER BY
[po_assoc].[jnr_quest] & "-" & [po_assoc].[jcode_stim];
Запрос cst выводит список кодов, который служил источником для создания анкет, в Po_assoc ожидаются именно эти коды:
cst
SELECT
association.nr_association, association.nr_questionnaire & "-" & association.code_stimulus AS cstINTO
tcstFROM
associationWHERE ((
(association.nr_questionnaire) In (SELECT DISTINCTROW po_assoc.jnr_quest FROM po_assoc GROUP BY po_assoc.jnr_quest )))ORDER BY
association.nr_questionnaire & "-" & association.code_stimulus;
Запросы troubleshooter1 и 2 аналогичны:
troubleshooter1
SELECT
tcse.position AS Выражение1, tcse.cse AS Выражение2, tcse.КодINTO
tb1FROM
tcseWHERE
(((tcse.cse) Not In (SELECT tcst.cst FROM tcst)));troubleshooter2
SELECT
tcst.nr_association AS Выражение1, tcst.cst AS Выражение2INTO
tb2FROM
tcstWHERE
(((tcst.cst) Not In (SELECT tcse.cse FROM tcse)));
Запрос troubleshooter3 ищет повторяющиеся коды стимула в анкете:
troubleshooter3
SELECT DISTINCTROW
tcse.cse, tcse.position, tcse.КодINTO
tb3FROM
tcseWHERE
(((tcse.cse) In (SELECT [cse] FROM [tcse] As Tmp GROUP BY [cse] HAVING Count(*)>1 )))ORDER BY
tcse.cse;
Инструменты упорядочения
ассоциаций для разработки словаря
В прямом ассоциативном словаре каждому слову-стимулу соответствует список реакций, сгруппированных по частоте встречаемости. В конце словарной статьи указаны количественные характеристики, а именно:
— количество заполненных анкет, в которых присутствует данный стимул (иными словами, общее количество реакций на этот стимул, в том числе и нулевых);
— количество разных реакций на данный стимул;
— количество пропусков (т.е. сколько раз опрошенные не записывали никакой реакции на этот стимул).
Расчет перечисленных количественных характеристик осуществляется путем исполнения нескольких запросов, схема расчета представлена на рис. 5. В результате расчетов создается несколько таблиц.
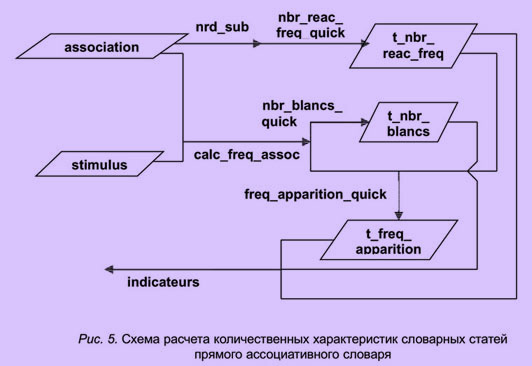
Таблица "количество разных реакций" — t_nbr_reac_diff. Служебный запрос nrd сначала извлекает от таблицы "ассоциация" нужные поля "код стимула" и "слово-реакция", которые группируются по коду стимула и подсчитываются, при этом для каждого стимула получается число разных реакций.
nrd_sub
SELECT DISTINCT
association.code_stimulus AS cs, association.mot_reactionFROM
associationWHERE
(((association.mot_reaction) Not Like "-"));
Запрос calc_freq_assoc вычисляет частоту встречаемости каждой ассоциативной пары, далее из этих данных запрос nbr_blancs_quick (количество пропусков) отбирает те ассоциативные пары, реакция которых является пропуском ответа респондента ("–"). Результат сохраняется в таблице "t_nbr_blancs".
nbr_blancs_quick
SELECT
calc_freq_assoc.code_stim AS code_stimulus, calc_freq_assoc.freq_assoc AS nbr_blancsINTO
t_nbr_blancsFROM
calc_freq_assocWHERE
(((calc_freq_assoc.mot_reac)="-"));
Другая таблица t_freq_apparition (частота проявления), которую создает запрос freq_apparition_quick, содержит данные о частоте проявления стимулов в массиве заполненных анкет. Эти результаты получаются посредством сложения частот тех ассоциативных пар, стимулом которых является рассматриваемый стимул. Частоты ассоциативных пар читаются в calc_freq_assoc.
freq_apparition_quick
SELECT
nbr_reac_diff.cs AS code_stimulus, Sum(calc_freq_assoc.freq_assoc) AS frequenceINTO
t_freq_apparitionFROM
calc_freq_assocINNER
JOIN nbr_reac_diffON
calc_freq_assoc.code_stim = nbr_reac_diff.csGROUP BY
nbr_reac_diff.cs;
Все три количественные характеристики (общее количество реакций, количество разных реакций, количество пропусков) выдаются запросом indicateurs (указатели), который связывает, соответственно, таблицы t_freq_apparition, t_nbr_reac_diff и t_nbr_blancs.
indicateurs
SELECT
t_nbr_reac_diff.cs AS code_stimulus, t_nbr_blancs.nbr_blancs AS nbr_blancs, t_nbr_reac_diff.nrd AS nbr_reac_differentes, t_freq_apparition.frequence AS frequenceFROM
(t_nbr_reac_diff INNER JOIN t_freq_apparition ON t_nbr_reac_diff.cs = t_freq_apparition.code_stimulus)INNER JOIN
t_nbr_blancsON
t_nbr_reac_diff.cs = t_nbr_blancs.code_stimulus;
Представление данных: анкета и
словарь
Элемент базы данных типа "отчет" предоставляет возможность представить в наглядном виде результаты запросов.
Анкеты
Для распечатки анкет разработан отчет questionnaire (анкета). Он используется для составления не только бланков анкет для проведения эксперимента, но и для представления заполненных анкет, так как их распечатанный вид является более разборчивым, чем подлинник.
Составление этого документа требует представить и связать данные, имеющиеся в трех таблицах: анкета, ассоциация и стимул. Соответствующий запрос выглядит так:
SELECT DISTINCTROW
[association].[nr_questionnaire],[association].[nr_association],
[association].[code_stimulus], [association].[mot_reaction],
[stimulus].[code_stimulus], [stimulus].[mot]&'...' AS mot_stim,
[questionnaire].[nr_questionnaire], [questionnaire].[code_groupe],
[questionnaire].[age],[questionnaire].[sexe],[questionnaire].[specialite],
[questionnaire].[langue], [questionnaire].[date], [questionnaire].[heure_debut],
[questionnaire].[heure_fin]
FROM ([stimulus]
INNER JOIN ([questionnaire] INNER JOIN [association] ON [questionnaire].[nr_questionnaire] =[association].[nr_questionnaire]) ON [stimulus].[code_stimulus] =[association].[code_stimulus]);
Формат экспорта в текстовый редактор
Объекты типа "отчет" представляют собой кортежи данных в виде столбца, один под другим. В случае ассоциативного словаря получаются длинные списки-колонки слов-реакций, в которых каждое слово-реакция ограничено символом "конец абзаца" — ^р. Такое оформление неприемлемо, так как оно занимает много места (много страниц), и не соответствует традиционной верстке словарей. В то же время объект "отчет" позволяет управлять шрифтами, и его можно экспортировать в формате RTF в текстовый редактор, где возможна окончательная верстка, которая заключается в преобразовании столбцов в строки.
В словарной статье прямого ассоциативного словаря слова разделены знаком "точка с запятой". Простановка данного разделителя слов из-за значительного объема словаря весьма трудоемка, поэтому для ее автоматизации используется встроенная функция "найти/заменить" текстового редактора. Замене в нужных местах подлежит символ "конец абзаца". Для правильных замен текст словаря должен быть предварительно размечен специальными маркерами. Синтаксис маркировки выглядит так:
\\<знак до/после><выражение1>\<выражение2>\
В маркере:
<знак до/после> указывает на нахождение <выражение1> перед или после маркировки, его значение может быть либо "+", либо "–",
<выражение1> указывает на то, что надо искать, и может состоять из любой непустой последовательности букв и знаков;
<выражение2> указывает на то, чем следует заменить поисковый контекст, и может состоять из любой последовательности букв и знаков, даже пустой.
При выполнении автоматической замены в диалоговом окне текстового редактора оператор набирает:
в поле "найти":
если <знак до/после>="–", то "<выражение1> \\ <знак до/после> <выражение1> \ <выражение2> \",
если <знак до/после>="+", то "\\<знак до/после> <выражение1> \ <выражение2> \ <выражение1>";
в поле "заменить" — <выражение2>.
Например, если в тексте имеется:
слово_1\\+^р\; \
слово_2
то оператор в поле "найти" диалогового окна записывает "\\+^р\; \^р", а в поле "заменить" — "; ". В результате замен получается: слово_1; слово_2
Подготовка отчета для экспорта ассоциативного словаря в текстовый редактор осуществляется на основе выполнения следующего запроса:
SELECT DISTINCTROW stim_reac_freq.code_stim,stim_reac_freq.mot_stim,[stim_reac_freq].[mot_reac]&"; \\+^p\\"ASxmot_reac,stim_reac_freq.freq_assoc,
indicateurs.code_stimulusASВыражение1,
"\\-; \\ (o" &[indicateurs].[frequence] & ", d" & [indicateurs].[nbr_reac_differentes] &
", v" &[indicateurs].[nbr_blancs] & ")" AS xtrail
FROM stim_reac_freq INNER JOIN indicateurs ON stim_reac_freq.code_stim = indicateurs.code_stimulus WHERE (((stim_reac_freq.code_stim)=[indicateurs]![code_stimulus]));