
CLAIM – научно-образовательный кластер
Филиппович Андрей
Информационно-поисковая система “Указатель Источников”
Содержание
Проблемы представления дат в “Указателе источников”
Введение
При работе с древними текстами можно использовать два способа ввода информации в компьютер: графический и текстовый. Первый способ призван к сохранению уникальных оригиналов и защиты их от неумолимого времени, второй — необходим для систематизации и обработки текстовой информации. Ввод графической информации (сканирование) производится значительно быстрее, чем набор текста (его могут осуществлять лишь немногочисленные специалисты в области исторической лексикографии), поэтому важно оптимизировать процессы ввода.
Одним из таких способов является OCR-распознавание. К сожалению, существующие системы FineReader и CuneiForm работают только с современными алфавитами и словарями языков. Например, даже использование упрощенного древнерусского алфавита (с буквами i, # и надстрочным символом титло) крайне затруднено. Система не позволяет смешивать существующие в ней символы из разных языков и определять размеры неизвестных символов по высоте. При обучении она тратит много времени и не приносит желаемого результата из-за отсутствия словаря языка. В настоящее время не существует не только компьютерных версий таких словарей, но и полноценных печатных изданий.
Следовательно, для качественного и эффективного распознавания необходимо ввести словарь вручную. Для этого нужно создать компьютерные шрифты, которые позволяют это сделать. Были переработаны существовавшие шрифты (Times New Roman Cyr и WP Courier Greek) и созданы два новых функциональных варианта. Весной этого года, спустя пять лет, были доработаны печатные версии шрифта KDRS old Cyr по заказу издательства “Наука” для 25-го тома “Словаря русского языка XI–XVII вв”. Этот шрифт принципиально отличается от существующих шрифтов типа Izhitsa функциональностью, то есть он приспособлен для ввода и вычитки текстов.
После создания текстового файла можно осуществлять обработку информации. Для подготовки словарей исходный текст нужно перевести в базу данных. С помощью СУБД можно сортировать, делать запросы (выборки) и производить быстрый поиск. Перед разработчиками встал вопрос о том, какую из существовавших на тот момент систем выбрать. Мощные сетевые СУБД: Oracle, Informix, Sybase — требуют много ресурсов и постоянного администрирования. Для локального использования подходят более “простые” системы: Borland Paradox, Microsoft Access и FoxPro.
После ввода текста в базу данных необходимо его обработать, для этого его нужно отсортировать. Это не так просто: современные системы не поддерживают все возможные языки и алфавиты, тем более такие редкие, как древнегреческий или древнеславянский. А если еще учесть, что различные исследователи имеют различные мнения о порядке букв, то задача кажется совсем неразрешимой. Разрабатывать новую программу для сортировки, которая поддерживает существующие форматы баз данных, не рационально. Она, скорее всего, будет не такой быстрой и, следовательно, менее эффективной. Был выбран другой путь и создана система сначала в среде СУБД, а потом независимо, в среде C++Builder.
Кроме сортировки, необходимо реализовать такие функции, как: поиск, создание запросов, экспорт/импорт в текстовый редактор или в другую систему управления базами данных. Все разработки были сделаны в различных системах, и их можно объединить под единой технологией — технологией обработки текстов, представленных нестандартными шрифтами (рис. 1).
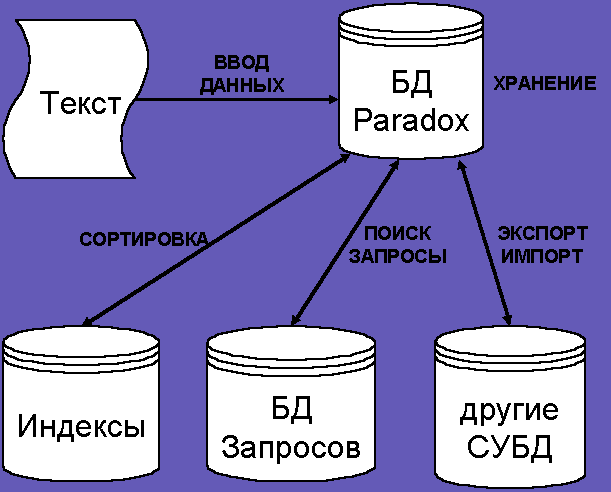
Рис.1. Структура работы с полиязычными текстами
Каждая из компонент системы реализована отдельно в виде программы, метода или шрифта. Для ввода можно использовать шрифты KDRS old Cyr, KDRS и Andrew Greek, а также модификации гарнитур Izhitsa (Izhitmut) и Flavius (Andrew Flavius). Чтобы создать словники, указатели и переводные словники (словари) можно использовать программу Andrew SLOV. Сортировку таблиц по произвольному алфавиту, языку или шрифту осуществляет программа Andrew Sort. Технологию хранения и поиска многоязычной текстовой информации в СУБД обеспечивает PolyTechnology. Для преобразования в другие форматы (экспорта) используется комплекс программ Andrew Conv.
“Указатель источников”
Информационно-поисковая система “Указатель источников” пытается ответить на вопросы: где можно использовать перечисленные достижения и разработки?
Под источником здесь понимается любое произведение письменности: древняя рукопись, свиток, книга. Указатель источников содержит их алфавитный перечень и библиографическое описание. Компьютерный вариант указателя представляет собой базу данных, состоящую из нескольких таблиц и содержащую 13 основных полей: шифр источника, полное описание, синоним, название источника, автор, исследователь-издатель, дата источника, уточненная дата, язык оригинала, издание рукописи, датировка состава, переиздание, место хранения.
Указатель источников составлен на основе Картотеки “Словаря русского языка XI–XVII вв.” и дважды издавался (1975, 1984). Для повторного издания и создания электронной версии книга была введена в текстовом редакторе MS Word. Указатель содержит описания источников на русском, польском, латинском, немецком и древнегреческом языках. Для их набора использовалось три шрифта: Arial Cyr, Arial CE и Andrew Greek.
Введенные тексты являются исходными данными для создания базы данных и информационно-поисковой системы. Единственной СУБД, которая поддерживает текстовой тип данных с шрифтовой разметкой, является Paradox. Тем не менее, даже она не имеет возможности импорта таких текстов из файла, но позволяет работать с буфером обмена. Последовательно было заполнено поле Полное описание, после чего оно было расписано по всем остальным полям (рис. 2). Для этого была разработана специальная форма в среде СУБД, которая ускорила процесс работы.
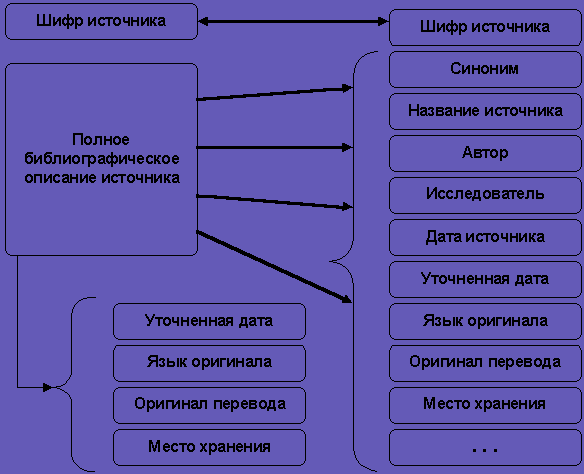
Рис. 2. Структура базы данных “Указателя источников”
Поле, способное хранить многошрифтовую информацию, является MEMO-полем (Formatted MEMO) и его нельзя сделать ключевым, а также осуществлять по нему поиск или запросы. Поля Название источника и Исследователь-издатель могут содержать текст, представленный различными шрифтами, которые не смешиваются в пределах одной записи. В Paradox и Access можно установить произвольный шрифт только для всей таблицы целиком: нельзя задать разные шрифты каждому полю или набору записей. Сейчас существуют шрифты Unicode, которые могут содержать до 256 старых шрифтов (теперь они называются наборами символов или CharSet-ами). К сожалению, большинство современных СУБД не поддерживают новые возможности при работе с ними и при выборе Unicode шрифта обязательно нужно указать используемый CharSet.
Ввод данных, заполнение базы данных, вычитывание, дополнение и корректировка выполнялись в течение нескольких лет. За это время СУБД Paradox версии 5.0 в значительной степени устарела, то есть с ее помощью нельзя создать современную и независимую информационную систему. Кроме того, прекратился выпуск ее русских версий. Неожиданно фирма Borland выпустила серию языков программирования, которые позволяют быстро и эффективно создавать приложения баз данных в среде Windows. Кроме того, Delphi и C++Builder имеют внутреннюю поддержку таблиц Paradox и мощные средства для работы с ними на основе механизма BDE.
Первые версии этих продуктов не позволяли хранить тексты с разметкой в базе данных. Эта возможность появилась только в третьей версии, но в другом формате, отличном от FMEMO СУБД Paradox. Пришлось написать программы на PalObject и на C++Builder, которые помогли осуществить преобразование из одного формата в другой. Для работы с форматированными текстами в Delphi (VCL) существует класс TRichEdit и его “родственник” TDBRichEdit. Принципиально новых возможностей не появилось: все так же нельзя вставлять тексты из файлов (только через буфер) и выполнять запросы.
В сентябре 1998 года было принято решение о создании информационно-поисковой системы “Указатель источников” в среде С++Builder 3.0. После преобразования базы данных для работы в новой среде, перед автором встал вопрос сортировки. Необходимо было упорядочить все записи по полю Шифр источника. Шифр — сокращенное обозначение источника, используемое в “Словаре русского языка XI–XVII вв.” Примеры шифров приведены на рисунке 3.
Рис. 3. Примеры шифров источников
Особенностью алфавита “Указателя источников” является наличие в нем служебных символов (пробела, точки, скобки, звездочки), некоторые из которых не должны учитываться при сортировке. Кроме того, в алфавите не должны различаться строчные и прописные буквы, а римские цифры должны находится после арабских, располагаясь в порядке возрастания. Порядок сортировки (алфавит) указателя приведен в табл.1.
После составления алфавита “Указатель Источников” был отсортирован программой Andrew Sort, а в базе данных было создано служебное индексное поле.
Табл. 1. Порядок сортировки указателя.
Слева указан символ, а справа — номер (порядок следования). Все символы, которые отсутствуют в алфавите, игнорируются: при сортировке не учитываются
| * | 11 |
| 0 | 1 |
| 1 | 2 |
| 2 | 3 |
| 3 | 4 |
| 4 | 5 |
| 5 | 6 |
| 6 | 7 |
| 7 | 8 |
| 8 | 9 |
| 9 | 10 |
| I | 12 |
| II | 13 |
| IV | 14 |
| IX | 16 |
| V | 15 |
| X | 17 |
| а | 18 |
| А | 18 |
| б | 19 |
| Б | 19 |
| в | 20 |
| В | 20 |
| г | 21 |
| Г | 21 |
| д | 22 |
| Д | 22 |
| е | 23 |
| Е | 23 |
| ё | 23 |
| Ё | 23 |
| ж | 24 |
| Ж | 24 |
| з | 25 |
| З | 25 |
| и | 26 |
| И | 26 |
| й | 27 |
| Й | 27 |
| к | 28 |
| К | 28 |
| л | 29 |
| Л | 29 |
| м | 30 |
| М | 30 |
| н | 31 |
| Н | 31 |
| о | 32 |
| О | 32 |
| п | 33 |
| П | 33 |
| р | 34 |
| Р | 34 |
| с | 35 |
| С | 35 |
| т | 36 |
| Т | 36 |
| у | 37 |
| У | 37 |
| ф | 38 |
| Ф | 38 |
| х | 39 |
| Х | 39 |
| ц | 40 |
| Ц | 40 |
| ч | 41 |
| Ч | 41 |
| ш | 42 |
| Ш | 42 |
| щ | 43 |
| Щ | 43 |
| ъ | 44 |
| Ъ | 44 |
| ы | 45 |
| Ы | 45 |
| ь | 46 |
| Ь | 46 |
| э | 47 |
| Э | 47 |
| ю | 48 |
| Ю | 48 |
| я | 49 |
| Я | 49 |
После подготовки базы данных началось создание информационной части системы.
Поля Название источника и Исследователь-издатель имеют формат FMEMO, но каждая запись содержит менее 255 символов. Фактически, нам нужно не MEMO поле, а текстовое с разметкой. Так как каждая запись этих полей содержит только один шрифт, то для хранения в базе данных можно воспользоваться следующей простой моделью: поместить в одно поле информацию о языке (шрифте), а в другое — сам текст без форматирования. В этом варианте можно выделить следующие недостатки:
1. Размер таблицы возрастает. Для двух полей это примерно 5–10%, но для базы данных “Указателя источников” это несущественно. Можно сократить эту цифру, используя вместо названия шрифта некий числовой кодификатор. Например:
Andrew Greek — 1;
Arial Cyr — 2;
Arial CE — 3.
Для пользования такой структурой необходимо разработать новые механизмы работы с данными.
2. Сложности разработки механизма отображения информации. В некоторых случаях способ хранения информации в FMEMO более рационален, так как каждая запись пишется последовательно в BLOB поле, заполняя все свободное пространство. При использовании простого текстового поля в таблицу записывается одинаковое количество символов, соответствующее размеру поля, независимо от содержимого.
3. Ограниченность использования. Этот вариант хорош для хранения отдельной информации о шрифте, но для полного описания нужны еще поля размера, начертания, цвета и др. Более того, при появлении полиязычности в одной записи такое хранение может оказаться совсем неэффективным.
Среди достоинств модели следует выделить следующие:
1. Поиск и сортировка. Появление дополнительных полей позволяет не только осуществить поиск вообще, но и значительно его ускорить. Например, при поиске в таблице с 10000 записей, содержащих информацию на 10 языках (шрифтах), средняя скорость увеличивается в пять раз.
2. Экспорт и хранение в других форматах. Такой способ хранения позволяет использовать любые СУБД, а также осуществлять экспорт.
При реализации “Указателя источников” не возникло необходимости экспорта в формат другой системы управления базами данных. К моменту разработки этой технологии уже была создана сложная система запросов, структура которой не позволяла увеличить скорость поиска. Кроме того, количество записей, содержащих русский язык, значительно превосходит все остальные вместе взятые. Все это не оправдывает усилия, необходимые для реализации системы.
Было найдено еще более простое решение: создать в базе данных два служебных поля, в которые занести содержимое полей Название источника и Исследователь-издатель без разметки. В операциях поиска или запросов используются новые поля, а в интерфейсе отображаются исходные поля с разметкой (рис. 4).
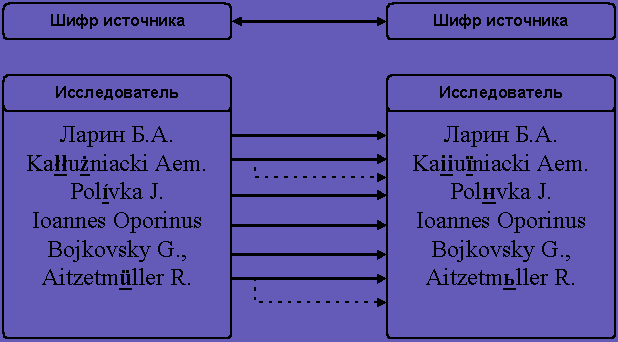
Рис. 4. Корреляция полиязычных полей.
Пунктирная стрелка указывает на возможную неоднозначность
Был проведен ряд экспериментов и анализ используемых языков, в результате которых выяснилось следующее:
1. В базе данных используется пять языков и три шрифта для их отображения. Каждый шрифт содержит в себе две раскладки, одна из которых всегда является латинской.
2. Для набора латинского текста можно использовать два из трех шрифтов (Arial Cyr или Arial CE). Очевидно, что русские буквы шрифта не пересекаются с латинскими, так как располагаются на другой раскладке.
3. Греческие буквы шрифта Andrew Greek находятся на латинской клавиатуре. Многие из них совпадают по расположению с буквами латыни (примерно на 70%), но корни слов и их конструкции отличаются. Помимо букв, греческий язык содержит около 15 надстрочных знаков, которые располагаются на служебных символах шрифта. На практике греческие названия используют из-за невозможности передачи их латинскими или русскими вариантами. Можно сделать вывод, что вероятность совпадения греческих и латинских слов (шрифтовая корреляция) очень мала.
4. Сложнее обстоит дело с польским языком. Его алфавит почти полностью совпадает с латинским (по расположению на раскладке клавиатуры), но в польском языке часто встречаются надстрочные знаки. Для их набора используется родная (не латинская) раскладка. Из этого следует, что польский язык не пересекается с русским по раскладке, а с латинским и немецким — по корреляции слов, так как польский язык принадлежит славянской группе.
5. Остается немецкий язык, много унаследовавший от латыни. В нем присутствуют дополнительно буква SS и три умляуты. Некоторые особенности в написании и многовековая история развития языка формируют существенные отличия от латинских слов.
6. Все рассуждения основаны на том, что поиск осуществляется по слову целиком. Если выполнять запросы с использованием шаблонов, то вероятность совпадения уменьшается с количеством используемых символов.
7. Для набора немецкого, польского и латыни используется один шрифт и одна (латинская) раскладка. Отличить один язык от другого можно либо по уникальным буквам, либо по словарной принадлежности. Большинство пользователей не знают, как отображаются символы на экране монитора и что при этом происходит в компьютере. Поэтому для них играет роль лишь графический вид буквы или знака. Разработчик информационной системы не знает содержания тех или иных записей и не может автоматически определить язык.
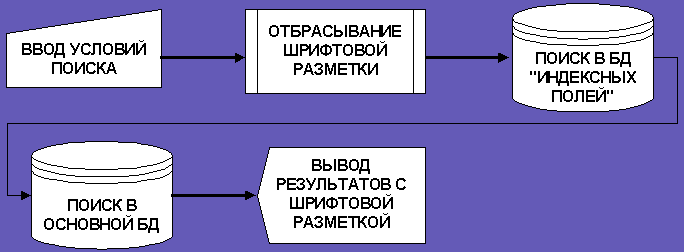
Рис. 5. Механизм поиска в “Указателе источников”
Предложенная модель поиска (рис.5) является отнюдь не совершенной. Если бы база данных “Указателя источников” содержала большое количество записей на других языках, то система имела бы существенный недостаток. Тем не менее, данная модель хорошо показала себя на экспериментах. В общем случае вероятность совпадения не превышает 10% порога.
Проблемы представления дат в “Указателе источников”
Одной из особенностей “Указателя источников” является наличие в нем приблизительных дат написания памятников. При этом около 10% датировок содержат вербальные описания (конец, начало, середина, первая четверть, вторая половина, около и др.). Остальные представления делятся приблизительно пополам по использованию арабских и римских цифр (рис. 6).

Рис. 6. Использование вербальных представлений
Было проведено исследование о соответствии между вербальным и количественным представлением в полях Дата источника и Уточненная дата. Выяснилось, что исследователи использовали разбиение века на четверти в основном для обозначения 20–40-х и 60–80-х годов, а разбиение века на трети (начало, середину и конец) — в остальных случаях. Например, середина века охватывает период 40–60 гг., а начало и конец — 1–15 и 85–99 года соответственно. Частота использования четвертей в три-четыре раза меньше, чем третей. Наиболее часто используется слово конец (примерно в два раза чаще, чем середина и начало).
При проектировании и создании электронной версии “Указателя источников” были учтены результаты данных исследований. Все многообразие вариантов свелось к единому интервальному представлению в годах. Визуально словесное представление дат было сохранено, а для поиска и запросов могут использоваться количественные параметры (рис. 7).
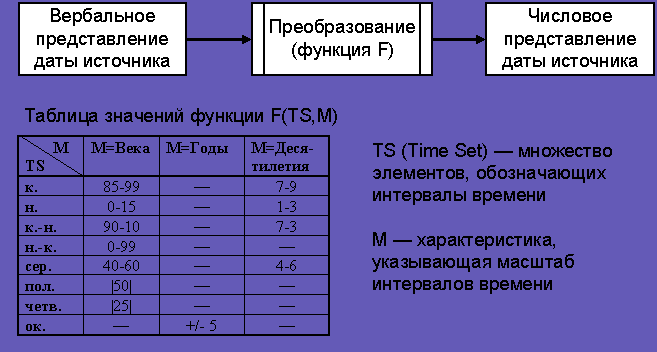
Рис. 7. Интервальное представление
Заключение
Хотелось бы отметить важность и перспективность исследований в области обработки многоязычной текстовой информации. Проводимые разработки были направлены большей частью на поддержку деятельности в области исторической лексикологии и лексикографии. Есть ли необходимость использовать их в других областях? На наш взгляд, это очевидно.
В первых компьютерных шрифтах можно было использовать только символы с одинаковой шириной, потом появилась возможность “накладки” символов для ввода надстрочных и подстрочных знаков, еще позже появились кернинг и трекинг. Форматы шрифтов прошли путь от экранных до Unicode. Появилось такое количество различных гарнитур, что современные операционные системы неспособны работать со всеми ними. Меняются со временем средства выделения в тексте. Внимание уделяется не только начертанию, но и цвету, фону, подчеркиванию и анимации. В современных электронных изданиях и Интернете очень активно это используется. А что такое выделение как ни очередная характеристика текстовой информации? Со временем складываются некоторые правила выделения, например, подчеркивание стало атрибутом гиперссылок.
Для структурирования информации, для поиска информации нужно использовать СУБД. Попробуйте это сделать, и проблемы филологов не покажутся Вам такими далекими и непонятными.
© НОК CLAIM, 2006-2012. Замечания, вопросы и сведения об ошибках просим сообщать в форуме или присылать администратору сайта.