
CLAIM – научно-образовательный кластер
Г.А. Черкасова
Формальная модель ассоциативного исследования1
Содержание
Первый этап психолингвистического ассоциативного эксперимента
- Формирование списка слов-стимулов
- Генерация анкет эксперимента
- Технология АСИТ
- Технология САС и АНИРЯ
- Подготовка анкет к печати
- Создание базы данных эксперимента
- Ввод и проверка анкетных данных
- Ассоциативный тезаурус
Второй этап психолингвистического ассоциативного эксперимента
- Составление статей ассоциативного словаря
- Подготовка ассоциативного словаря к печати
- Исследование ассоциативного тезауруса
Введение
Данная статья посвящена описанию основных компонент формальной модели ассоциативного исследования на материале проведенных психолингвистических экспериментов: Ассоциативный тезаурус современного русского языка, Славянский полиязычный ассоциативный опрос, Испанский ассоциативный эксперимент, Русско-французский ассоциативный эксперимент в предметной области «Информатика и вычислительная техника». В результате обработки данных этих исследований были получены: «Русский ассоциативный словарь» (РАС), «Славянский ассоциативный словарь» (САС), «Ассоциативные нормы испанского и русского языка» (АНИРЯ) и материалы к «Ассоциативному словарю информационных технологий» (АСИТ).
Все указанные работы использовали один из вариантов ассоциативного эксперимента — так называемый свободный ассоциативный эксперимент с регистрацией первичного ответа. Цели, методика и организация таких психолингвистических исследований хорошо известны и широко представлены в литературе [см., например, Леонтьев 1977; Караулов 2002; РАС]. В последнее время для обработки экспериментальных данных активно используются средства вычислительной техники, при этом в качестве исследовательского инструментария применяются универсальные программные системы – текстовые редакторы, системы управления базами данных, электронные таблицы и т.п. Их, однако, недостаточно и требуется разработка специальных программных комплексов, создаваемых для поддержки, как отдельных этапов проведения анкетирования и обработки экспериментальных данных, так и для сопровождения всего исследовательского цикла работ научного коллектива.
Использование вычислительных, информационных и программных средств в перечисленных случаях требует некоторого обоснования эффективности, как с позиции более рационального использования ограниченных ресурсов исследовательского коллектива (материальных, временных и интеллектуальных), так и возможности обнаружения новых, ранее неизвестных фактов и закономерностей, на потенциальное открытие которых всегда направлен эксперимент. Основой такого обоснования является формальное описание информационной технологии эксперимента, позволяющее определить его ресурсную сложность – вычислительные затраты на компьютерную поддержку и рутинных, и интеллектуальных инновационных процессов обработки данных.
Психолингвистический ассоциативный эксперимент (ПАЭ) делится на два этапа, которые по основному конструктивному их результату назовем: «Разработка ассоциативного тезауруса» — 1-й этап; «Исследование ассоциативной вербальной сети» — 2-й этап.
Первый этап психолингвистического ассоциативного эксперимента
На первом этапе осуществляется собственно ассоциативный эксперимент и создается ассоциативный тезаурус, т.е. проводятся подготовка к опросу респондентов, опрос и первичная обработка полученных данных. Задачи этапа: разработка концепции и инструментария эксперимента, формирование списка стимулов, генерация анкет и печать их, проведение анкетирования, ввод и формальный контроль данных анкетного опроса, создание и заполнение базы данных исследования, статистический анализ базы данных, формирование компьютерной версии ассоциативного тезауруса. Рассмотрим более подробно постановку некоторых из перечисленных задач.
Формирование списка слов-стимулов
Любой ассоциативный эксперимент начинается с формирования списка стимулов, из рассматриваемых только первый — Ассоциативный тезаурус современного русского языка — осуществлен в широких масштабах, более того, проводился он в три этапа. Исходный список слов-стимулов первого этапа был подготовлен составителями в соответствии с практикой ассоциативных экспериментов [подробно см. РАС и Караулов 2002, 752]. Стимулы для каждого последующего этапа выбирались из реакций предшествующего по упорядоченным частотным спискам. Всего использовано разных 6624 слова и словосочетания, при этом список 1-го этапа включал 1277 слов 2 (среди них часть лексем даны в разных словоформах и с предлогом «о»), 2-го — 2685 стимулов, 3-го — 2935.
Славянский полиязычный и ряд двуязычных ассоциативных экспериментов, среди которых испанско-русский, использовали один список 112 стимулов, переведенных на соответствующие языки. Список составлен на основе анализа материалов РАС (1994–1998 гг.), и выбирался для исследования сходств и различий в образах сознания носителей различных культур.
Список слов-стимулов АСИТ был выбран из частотного словника корпуса текстов, представляющий предметную область «Информатика и вычислительная техника» и опубликованных в журнале «Computer Week» в 1995 г. Словоформы были приведены к основной грамматической форме, и из общего списка слов удалены слова общеупотребительной лексики, имена персоналий, наименования конкретных товаров, торговые марки и пр. Так были выделены самые употребляемые слова данной предметной области, например прилагательные — системный, двоичный, глаголы — отлаживать, эмулировать и существительные — дисковод, маршрутизация. Были сформированы два списка слов-стимулов: первый был предназначен для студентов компьютерных специальностей; второй — гуманитарных специальностей (подробно см. [Черкасова 2000, 269-272]).
Генерация анкет эксперимента
В большинстве ассоциативных исследований выводы строятся и обосновываются на основе статистических методов обработки данных, а это требует обеспечения репрезентативности (представительности) и взаимной независимости собранных и обрабатываемых экспериментальных данных, как исходно получаемых от респондентов, так и выбираемых путем направленного или случайного отбора. В связи с этим при анкетировании нужно стремиться к исключению факторов (внешних, организационных и др.), влияющих на ответы респондентов. Кроме этого важным является получение на каждое из слов-стимулов одинакового количества слов-реакций.
В числе внешних факторов отметим: а) факторы формы анкеты, влияющие на удобство работы с ней респондентов — геометрические размеры, начертание и шрифт текста и др.; б) факторы содержания анкеты — количество слов-стимулов и порядок их расположения, особые сочетания слов-стимулов, которые могут определять ответы опрашиваемых или оказывать влияние на них.
На количество ответов (слов-реакций) опрашиваемых влияет: во-первых, неравномерность представления слов-стимулов в анкетах; во-вторых, невозможность прочитать некоторые реакций из-за неразборчивого почерка отдельных респондентов. Эти факторы приводят к так называемым «перекосам», которые могут быть устранены либо дополнительным опросом, либо генерацией некоторого количества «избыточных» анкет.
Чтобы исключить влияние конкретных сочетаний (последовательностей) слов-стимулов на ответы испытуемых, в исследованиях использовались формальные методы генерации анкет, основанные на случайной выборки слов-стимулов из их общего списка.
Сформулируем задачу генерации анкет ассоциативного эксперимента в общем виде: необходимо из общего списка слов-стимулов, расположенных в алфавитном порядке, сгенерировать множество случайных подсписков, в которых разброс частот появления каждого слова-стимула был меньше некоторой первоначально заданной величины. Формальное описание задачи следующее.
Обозначим:
N - общее количество слов-стимулов;
n. - количество анкет;
м - количество слов, представленных опрошенному в анкете.
Пусть А - массив анкет.
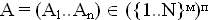 ,
,
где 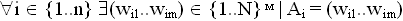 .
.
Суть задачи генерации анкет заключается в выполнении следующих двух требований:
- Запрещается повтор любого стимула wij в одной анкете i, т.е.
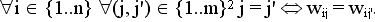 .
. - Максимальный разброс частоты fk появления стимула k ограничен: он должен быть как можно ниже. Идеальным считается случай, когда частоты имеют либо наперед заданное значение F, либо значение F+1, т.е
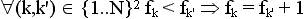 .
.
Для решения задачи генерации анкет ПАЭ могут быть предложены различные технологии и программные средства. Рассмотрим и сравним между собой некоторые из них, отметив при этом, что, прежде всего, следует различать технологии одноэтапных и многоэтапных экспериментов.
Требования к результатам работы программ генерации анкет следующие:
- выбор стимулов должен осуществляться случайным образом;
- в каждой анкете любое слово-стимул должно появляться не более чем один раз;
- суммарные частоты проявления слов-стимулов должны быть близкими по значению к заданному пороговой величине, иными словами, распределение стимулов в массиве анкет должно стремиться к равномерному.
Технологии получения анкет в рассматриваемых экспериментах различны, приведем их краткие описания.
Технология АСИТ
В основу функционирования программы генерации анкет положена следующая идея: можно удовлетворить требованиям 1– 3, формируя так называемые «матрицы» — набор всех слов-стимулов, расположенных в случайном порядке, который затем для получения анкет «разрезается» на части размера м = количество стимулов, содержащееся в одной анкете. Этот подход можно использовать при больших списках слов-стимулов. Более того, в идеальном случае, когда остаток деления N на м равен нулю, суммарные частоты появления стимулов в массиве анкет будут одинаковые.
Матрица представляет собой список всех слов-стимулов, перемешанных в случайном порядке, где каждый стимул встречается точно один раз. Для создания матрицы выбран следующий алгоритм. Сначала создается таблица допустимых, но пока невыбранных стимулов — t, содержащая все номера слов-стимулов. Переменной width («ширине» таблицы t, ее текущему объему) присваивается значение N. Затем в каждом очередном цикле: 1) от генератора случайных чисел получается значение переменной Z, лежащее в диапазоне [1...width]; 2) переменной X, которая является очередным создаваемым элементом матрицы, присваивается значение Z-го элемента таблицы t; 3) из таблицы t удаляется Z-й элемент и из переменной width вычитается единица.
Алгоритм формирования анкет представлен на рис. 1. Сначала формируются анкеты А1 и А2. На этом генерация матрицы М1 заканчивается, но номера слов, которые присутствуют в части анкеты А3, принадлежащей М1, сохраняются в специальной таблице ostatok. Генерация М2 начинается с формирования второй части анкеты А3. Когда она завершена, восстанавливаются номера слов, хранящиеся в таблице ostatоk.
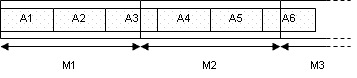
Рисунок 1. Алгоритм формирования анкет АСИТ
При завершении генерации рассчитываются статистические величины (список частот появления каждого стимула и средняя частота), характеризующие распределение слов-стимулов в массиве сгенерированных анкет, которые предоставляются пользователю.
Технология РАС
Формирование требуемого количества (нескольких тысяч) анкет по 100 стимулов в каждой, среди которых нет двух одинаковых, и все стимулы из исходного списка встречаются не менее заданного (порогового) числа раз, осуществлялась специальной программой. Алгоритм ее следующий. Задав количество необходимых для печати анкет и значение порога встречаемости, начинается генерация последовательности случайных номеров слов-стимулов для каждой формируемой анкеты, последовательность сохраняется в специальных файлах, используемых и при печати анкет, и в технологии ввода данных опроса, и в случае потери или порчи для перепечатки анкет. Параллельно с генерацией в «счетчиках встречаемости стимула» суммируются частоты попадания соответствующего слова-стимула в созданный массив анкет, и когда накопленное значение достигает порогового значения, соответствующий стимул блокируется в исходном списке слов-стимулов и далее при генерации не используется. После завершения процесса генерации партии анкет в специальной таблице для каждого номера стимула сохраняется его суммарная частота, т.е. значение «счетчика встречаемости». Эти данные используются при последующей генерации анкет.
Технология САС и АНИРЯ
Так как в полиязычном славянском ассоциативном эксперименте каждая из анкет включает все стимулы из исходного списка, то задача генерации анкет это формирование множества разных случайных последовательностей номеров всех стимулов.
При проведении испанского ассоциативного опроса использовались анкеты, в которых номера стимулов либо возрастали от первого до последнего (1, 2, 3... 108), либо, наоборот, уменьшались от последнего до первого.
Подготовка анкет к печати
Анкета ассоциативного опроса должна содержать следующие обязательные поля: титул, номер анкеты и список стимулов, а также может включать дополнительные поля: возраст, пол, специальность и родной язык респондента, дату, время начала и конца заполнения анкеты, место проведения опроса и т.п.
В анкете слева от каждого слова-стимула должен присутствовать его код, справа — свободное место, куда респондент записывает свое слово-реакцию. Код или номер стимула используется в технологии клавиатурного ввода данных, в которой набирается не само слово-стимул, а его код. Анкета должна иметь вид бумажного документа, а ее формальное описание имеет следующий вид.
Пусть 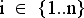 и
и 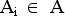 . Респонденту выдаются следующие данные (они уже присутствуют в бланке анкеты): номер анкеты; множество пар, состоящих из кода стимула и самого слова-стимула — (wij,swij).
. Респонденту выдаются следующие данные (они уже присутствуют в бланке анкеты): номер анкеты; множество пар, состоящих из кода стимула и самого слова-стимула — (wij,swij).
В результате заполнения анкеты получаются значения следующих полей: возраст (v); пол (p); специальность (q); родной язык (y); дата (d); время начала (t0); время конца (t1); множество реакций (rj)j , где rj является словом-реакцией на слово-стимул sj. То есть для
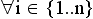
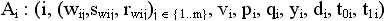 .
.
Анкеты ассоциативного опроса могут быть напечатаны:
- с помощью специальных программ (такая технология использовалась в РАС, а также для печати русских и болгарских анкет САС);
- с использованием функциональных возможностей СУБД по подготовке отчетов (так были напечатаны анкеты АСИТ);
- с использованием текстовых редакторов и последующей печатью (копированием) нужного количества (эксперимент АНИРЯ, украинская и белорусская части эксперимента САС).
При печати анкет с использованием СУБД предварительно создается база данных эксперимента, затем она автоматически заполняется содержанием сгенерированных анкет, далее разрабатывается печатная форма-отчет, и после этого распечатывается массив анкет. Такой вариант подготовки анкет предопределяет дальнейшую технологию обработки данных эксперимента, т.е. содержание заполненных в результате опроса анкет вводится сразу в базу данных.
Создание базы данных эксперимента
База данных эксперимента предназначена для эффективного хранения информации в виде, удобном для ее последующей обработки. При этом должны быть обеспечены минимальные затраты памяти на хранение данных и время выполнения операций над ними.
Для удовлетворения этих требований традиционным является использование систем управления базами данных. Использование реляционных моделей и СУБД при разработке БД эксперимента позволяет выполненить процедуры нормализации структур, которые приводят к получению рациональной модели хранимых данных.
Ввод и проверка анкетных данных
Для ввода сведений, содержащихся в бумажных анкетах, полученных после проведения опроса, использованы две технологии:
- технология непосредственного ввода содержания анкет в базу данных исследования, в которой используются инструменты ввода данных, предоставленные выбранной СУБД;
- технология ввода содержания анкет в текстовые файлы определенного формата и последующее импортирование их в базу данных используемой СУБД.
Ошибки ввода данных могут появляться в любом поле анкеты. Все возможные ошибки следует разделить на два типа: неформальные (а) и формально-логические (б).
К ошибкам типа (а) относятся в основном ошибки ввода слов-реакций, которые представляют собой рукописные записи респондентов, сделанные порой неразборчивым почерком. Их можно обнаружить только путем вычитки текстового файла введенных анкет либо по его распечатке, либо непосредственно с экрана дисплея, и сравнения с бумажной анкетой. Такие ошибки могут быть исправлены только путем клавиатурного перенабора.
Ошибки типа (б) могут быть обнаружены и в некоторых случаях автоматически исправлены путем формально-логического контроля вводимых данных. Ниже представлены поля, в которых можно обнаружить ошибки путем формально-логического контроля:
- значение поля возраст должно быть в некоторых пределах, в зависимости от выборки испытуемых;
- поле пол должно принимать значение или «м», или «ж»;
- значения полей время и дата должны быть отформатированы;
- значение поля код каждого стимула не может быть ни нулевым, ни превышать общее количество стимулов, а также невозможно присутствие любого кода больше одного раза в одной анкете. К тому же список стимулов, представленных на каждой анкете, заранее известен. Можно сравнить список введенных кодов со списком кодов, которые должны присутствовать, и указать на расхождения.
Допустим, что проверяется анкета № i, .
.
Можно, например, проверить истинность следующих предикатов:
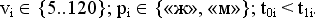
В результате решения всех рассмотренных выше задач формируется компьютерная версия материалов ассоциативного эксперимента, которая и есть ассоциативный тезаурус.
Ассоциативный тезаурус
Основным результатом первого этапа психолингвистического ассоциативного эксперимента является создание ассоциативного тезауруса, поэтому его формальное описание – это главная составная часть формальной модели ПАЭ. Приведем рассуждения, позволяющие сделать это описание, начиная с некоторых определений.
Все множество слов ПАЭ (стимулы и реакции)3 связаны условиями и технологией проведения эксперимента двумя типами отношений – SR RS (соответственно 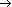 и
и  ), т.е. между парами слов может быть определено формальное ассоциативное отношение L, которое будет принимать значение L = {, }. Кроме этого, априори любое слово-реакция может оказаться словом-стимулом, и фактически для части слов-реакций апостериори это фиксируется. Следует отметить при проведении многоэтапных ассоциативных экспериментов экспериментаторы преднамеренно используют включение в списки слов-стимулов последующих этапов слов-реакций предыдущих. Таким образом, все слова в формальной модели могут быть разделены на четыре типа: слова-стимулы, среди них можно выделить те, которые не встретились в ответах испытуемых, слова-стимулы-не_реакции, слова-реакции, часть которых дублирует стимулы, т.е. есть слова-реакции-стимулы. Каждый из этих типов слов по результатам проведенного ПАЭ образует некоторое множество. Приведем в качестве примера характеристики этих множеств для некоторых экспериментов.
), т.е. между парами слов может быть определено формальное ассоциативное отношение L, которое будет принимать значение L = {, }. Кроме этого, априори любое слово-реакция может оказаться словом-стимулом, и фактически для части слов-реакций апостериори это фиксируется. Следует отметить при проведении многоэтапных ассоциативных экспериментов экспериментаторы преднамеренно используют включение в списки слов-стимулов последующих этапов слов-реакций предыдущих. Таким образом, все слова в формальной модели могут быть разделены на четыре типа: слова-стимулы, среди них можно выделить те, которые не встретились в ответах испытуемых, слова-стимулы-не_реакции, слова-реакции, часть которых дублирует стимулы, т.е. есть слова-реакции-стимулы. Каждый из этих типов слов по результатам проведенного ПАЭ образует некоторое множество. Приведем в качестве примера характеристики этих множеств для некоторых экспериментов.
эксперимент |
слова - стимулы |
стимулы - не_реакции |
слова-реакции - стимулы |
слова- реакции |
всего слов ПАЭ |
РАС |
6624 |
160 |
6464 |
103051 |
103211 |
1-этап РАС |
1277 |
126 |
1106 |
52349 |
52475 |
2-этап РАС |
2685 |
0 |
2685 |
50489 |
50349 |
3-этап РАС |
2935 |
34 |
2901 |
46948 |
46982 |
АСИТ (техн.) рус. (гуман.) |
128 253 |
38 118 |
90 135 |
4083 3358 |
4121 3476 |
АСИТ (фр.) |
118 |
39 |
79 |
2417 |
2456 |
САС (белор.) |
112 |
3 |
109 |
13866 |
13869 |
САС (болг.) |
113 |
2 |
110 |
11480 |
11493 |
САС (рус.) |
112 |
2 |
111 |
10099 |
10101 |
САС (укр.) |
112 |
6 |
106 |
9344 |
9350 |
Определим множество всех слов ПАЭ, связанных между собой названными отношениями, как первичную ( = первого уровня, = базовую) феноменологическую (наблюдаемую и зафиксированную) модель Ассоциативно-вербальной сети (АВС).
Во всех рассматриваемых ассоциативных экспериментах слова-стимулы оказываются сгруппированными в анкеты, т.е. связанными предикатным отношением «быть элементом анкеты», и тем самым образуют множества слов конкретной анкеты. Поскольку каждой анкете (группе слов) ставится в соответствие набор некоторых признаков респондентов (пол, возраст, язык, профессиональность и др.) и некоторая техническая характеристика условий эксперимента (титул, номер анкеты, номер этапа, время и др.), то предложенная модель усложняется. Фактически слово «нагружается» дополнительными отношениями и может рассматриваться как некий объект с набором свойств. В связи с этим будем определять все другие (последующие) модели АВС как вторичные, сохранив в названии слово «феноменологическая», объясняя это тем, что все эти признаки оказываются зафиксированными в материалах эксперимента.
Обобщим приведенные определения, введя понятие формальный тезаурус, под которым будем понимать все множество феноменологических моделей АВС. Иначе, формальный тезаурус ПАЭ – это множество всех слов (стимулов и реакций), связанных между собой формальными ассоциативными отношениями, зафиксированными в экспериментальных материалах, представляющих собой обобщенную феноменологическую модель АВС.
Для описания предложенных моделей и ассоциативного тезауруса могут быть использованы различные нотации (языки и формальные системы) — логики, реляционной алгебры, теорий: множеств, графов, алгоритмов, баз данных, программирования и др.
Теоретико-множественное описание тезауруса позволяет максимально подробно специфицировать все элементы моделей и тезауруса. В процессе описания отношения и множества именуются, а для множеств указывается их важнейший параметр – мощность, который в последующем используется для описания алгоритмов обработки экспериментальных данных и разработки соответствующих компьютерных программ. Теоретико-множественное описание позволяет построить функции оценки временной и емкостной сложности алгоритмов обработки данных и получить расчетные показатели затрат вычислительных ресурсов на поддержку исследований.
Описание тезауруса в виде графа является традиционным для наглядного представления сложных теоретико-множественных моделей. Графовая нотация ассоциативных отношений используется многими исследователями, см., например [Москович 1971; Караулов 1976; и др.]. Основным недостатком графового представления следует считать трудоемкость технического исполнения (рисования) схем, а также их громоздкость. В книгах они представлены на вкладках, а в компьютерном варианте занимают пространство более одного экрана и для просмотра требуют либо масштабирования, либо использования средств «прокрутки» изображения. Основным преимуществом представления ассоциативного тезауруса в виде графа является возможность последующей реализации алгоритмов его анализа с целью выявления ассоциативных цепочек, колец (циклических участков), деревьев, ветвящихся структур, независимых подграфов.
Так, например, анализ графа тезауруса РАС показывает, что в нем всего 103211 узлов, которые связаны между собой 462531 дугами. При этом 6464 узла (т.е. 6,26% от общего числа), определяющие множество слов-стимул-реакция, замыкаются между собой 269082 дугами, что составляет 58,2% от всех дуг графа. Большинство узлов — 96587 (93,58%) — это слова-реакции, у которых есть только входящие дуги, при этом их количество 4 изменяется от 1 до 443. Среди них узлов с одной входящей дугой — 65218, с двумя — 12801, с тремя — 5946, с четырьмя — 3463, … и т.д.
Рассмотрим оставшиеся узлы (0,16%) это 160 стимулов, не ставших реакциями, и имеющих только выходящие дуги. Среди них оказались стимулы первого и третьего этапов ассоциативного опроса.
Следующие 126 стимулов первого этапа не стали реакциями: аннулировать, бессвязный, вдовый, возьмете, деревней, деревням, длиннейший, добрейший, договорилась, договорился, договоритесь, договорится, договоришься, договорюсь, договорятся, древнейший, знамен, знаменам, знаменами, знаменем, известнее, известнейший, изменили, изменим, изменит, измените, изменишь, изменю, изменят, интереснейший, колхозам, колхозов, колхозу, листам, листами, листом, листу, магазинам, магазинами, магазину, минутам, минуте, мужьями, начнет, начнете, начнешь, начнут, немногословный, неотзывчивый, нищенский, ноге, носам, о воздухе, о девушках, о знаменах, о знамени, о колхозах, о колхозе, о листах, о листе, о магазинах, о магазине, о минуте, о ноге, о носах, о носе, о пальцах, о пальце, о пауках, о пауке, о пчелах, о пчеле, о свиданиях, о странах, о стране, о трудах, о чае, оказываться, остальной, отклонить, пальцу, пауку, песням, пиву, платила, платим, платите, платишь, попросил, попросила, попросите, попросишь, попросят, попрошу, появимся, появитесь, появишься, появлюсь, появятся, предоставлять, просили, просите, просишь, пчеле, пчелу, ребятенок, решу, свиданием, свиданиями, серьезнее, снимаете, снимаешь, снимал, снимала, снимали, снимают, современнее, современнейший, стоил, стоила, странами, терзание, товарищами, трудам, успеете, успеют.
Кроме этого 34 стимула третьего этапа, хотя и должны были быть реакциями 2-го этапа, но из-за корректировки авторами эксперимента формы или падежа, так как в анкетах стимулы включались в так называемых «основных формах», в итоге не встретились в ответах испытуемых. Это: взаимозависимость, Великая отечественная война, интеллигенция, лидерство, права человека, разыграться, вяленый, гарантировать, догорать, журчать, заряжать, захлопнуться, инвалидный, крепчать, минеральный, набегать, напрашиваться, несметный, одинешенький, отменяться, относительность, отпущение, перистый, прокиснуть, прорвать, разгореться, разомкнутый, расставлен, расшатан, сбываться, славянка, соболиный, хоровой, экстремальный.
Анализируя эти стимулы, можно отметить, что реакции не дают всех возможных словоформ для стимулов, заданных в так называемой «основной» форме.
Выделенные типы узлов можно представить графически, как показано на рис. 2. Там же приведены размеры множеств разных типов узлов в абсолютных величинах и процентах.
 |
 |
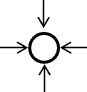 |
только выходящие дуги |
выходящие и входящие дуги |
только входящие дуги |
Рисунок 2. Типы узлов ПАЭ и их характеристики для РАС-2002.
Следует отметить, что дуги бывают разной «силы», которая определяется частотой ответа того слова-реакции, с которым «связана» дуга. Ниже, на рис. 3 даны четыре графика, показывающие зависимость количества узлов (слов-реакций) в графе от «силы связи» входящих дуг (=частот пар «стимул-реакция») для следующих случаев: Ряд 1 — одна входящая дуга в узел, Ряд 2 — две, Ряд 3 — три, и Ряд 4 — четыре. Аналогичные распределения и, соответственно, графики можно построить и для других типов узлов.
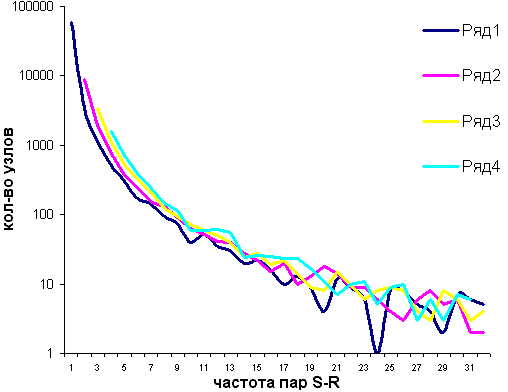
Рисунок 3. Зависимость количества узлов в графе РАС от «силы связи» дуг.
Алгоритмическое описание тезауруса — это пошаговое описание последовательности процедур и операций его формирования и преобразования в процессе исследований. Чаще всего это описание представляется в виде схемы их условно-графических обозначений, построенной по определенным правилам, например в соответствии с требованиями ГОСТ для изображения алгоритмов программ для ЭВМ.
Программное описание тезауруса наиболее подробно и точно описывает его преобразования, так как ориентировано на конкретную практическую реализацию в компьютерной среде. Данное описание выполняется на различных языках программирования и является так называемым программным обеспечением исследования. Например, в АСИТ программное описание тезауруса выполнено на языке программирования C++ и WordBasic; в РАС использовались Basic, ObjectPAL for Paradox, Delphi.
Второй этап психолингвистического ассоциативного эксперимента
На втором этапе разрабатывается инструментарий для проведения исследований ассоциативного тезауруса. Первым и непременным шагом является создание «Ассоциативного словаря», т.е. формирование и подготовка к печати двух его проекций: прямой — от стимула к реакции, и обратной — от реакции к стимулу.
Кроме этого задачами второго этапа являются: разработка интерфейса базы данных исследования и программных модулей, позволяющих сделать как построение проекций тезауруса и разнообразных выборок из него, так и добавление полей в базы данных (расширение АВС); разработка меры оценки «силы связи» между элементами сети и инструментария ее оценки и др.
Составление статей ассоциативного словаря
В базе данных эксперимента после ввода имеется множество ассоциативных пар (стимул-реакция), распределенных по анкетам. Статья ассоциативного словаря представляет собой запись слова-стимула (S) и соответствующего ему множества слов-реакций (R) — ассоциативную дефиницию, при этом для каждой из реакций указана абсолютная частота ее встречаемости в паре с данным стимулом. Для создания статей ассоциативного словаря нужно отсортировать множество ассоциативных пар по стимулу и для каждого стимула подсчитать частоту встречаемости соответствующих ему реакций.
Необходимо получить (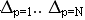 ) — ассоциативные дефиниции стимулов (s1..sN). Структура ассоциативной дефиниции следующая:
) — ассоциативные дефиниции стимулов (s1..sN). Структура ассоциативной дефиниции следующая:
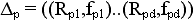
где:
Rpu — u-я реакция ассоциативной дефиниции стимула sp;
fpu— количество ответов Rpu на стимул Sp;
d = dp — «длина» ассоциативной дефиниции 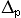 .
.
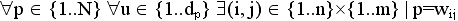 .
.
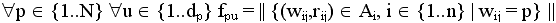 .
.
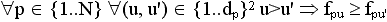 .
.
Подготовка ассоциативного словаря к печати
Средой разработки ассоциативного словаря является СУБД. Однако она не предназначена для формирования оригинал-макетов печатного издания словаря, удовлетворяющих требованиям полиграфии. Кроме этого использование функциональных возможностей СУБД по созданию отчетных печатных форм требует значительной последующей ручной работы из-за того, что автоматически списки слов в формах СУБД представляются в виде столбцов, а для удобства чтения и экономии места на страницах печатного ассоциативного словаря лучше разместить слова по строкам, используя традиционные разделители (точки, запятые и др.). Общая трудоемкость форматирования словарных статей и страниц в СУБД велика, ведь количество представленных слов огромно. Технология формирования страниц печатного ассоциативного словаря представляет собой самостоятельную задачу, требующую отдельного рассмотрения.
Исследование ассоциативного тезауруса
Описанный в какой-либо форме на первом этапе ПАЭ формальный тезаурус, затем на втором этапе оказывается объектом исследования, при этом возможны различные позиции наблюдения: системотехническая, психолингвистическая, когнитивная и др. Охарактеризуем одну из них – системотехническую, примерами конкретных направлений исследования.
Одно из направлений системотехнических исследований связано с представлением результатов ПАЭ в форме, позволяющей обеспечить:
- эффективный доступ экспериментаторов к анкетным данным;
- возможность обнаружения (нахождения, вскрытия) латентных отношений между лексическими единицами эксперимента (ранее говорилось о словах), путем применения конкретных методик, например, лингвистического конструирования новых лексикографических объектов.
Другим направлением является разработка эффективных информационных технологий печатного и электронного представлений формального тезауруса ПАЭ для исследователей не экспериментаторов, ученых и практиков конкретной профессиональной деятельности – переводчиков, учителей и преподавателей, менеджеров, технических писателей, имидж-мэйкеров, спич-райтеров, рекламистов, конструкторов информационных систем (словарных, поисковых, автоматического перевода и т.п.) и других.
Третье — обеспечение эффективности взаимодействия экспериментаторов с анкетными данными путем разработки рациональных форм их хранения, обработки и представления.
В рамках этих направлений исследований введем понятие латентного (скрытого) тезауруса, под которым будем понимать все потенциально возможные, неявные модели ассоциативных отношений между зафиксированными в АВС языковыми единицами.
В свою очередь, под неявной моделью ассоциативных отношений АВС будем понимать совокупность лексических единиц (слов), представленных в формальном тезаурусе и отношений между ними, известных экспериментаторам не из ПАЭ. Данные отношения могут быть «выявлены» в латентном тезаурусе путем эксплицитно задаваемых процедур полипараметрического анализа формального тезауруса, т.е. внесены в формальный тезаурус приписыванием некоторых признаков ( = параметров, = характеристик) соответствующим лексическим единицам. В числе таких отношений лингвистические и экстралингвистические.
Значения лингвистических отношений могут быть получены путем грамматико-категориальной идентификации лексем, состоящей в приписывании каждой лексической единице характеристик, которыми она может обладать: частотно-алфавитная, нарицательное или имя собственное (в том числе – антропоним, топоним, персонаж художественного произведения…), лексикологическая характеристика (иноязычное, диалектное, архаическое, фразеологизм...), категориальная принадлежность (имя существительное мужского рода, несклоняемое, местоимение, междометие...), морфологическая характеристика (сокращение, игра фонетическая или морфологическая, причастие, предикатив...), а также вся совокупность словоформ, в которых данная лемма встречается в ассоциативно-вербальной сети.
Элементам формального тезауруса могут быть приписаны и экстралингвистические отношения: дефиниции (толкования, определения, эксцерпции), семиотические структуры (знаки, формулы, образы), информационные технологии какой-либо свертки слов [Караулов 1982], лемматизации слов-реакций на основе автоматического морфологического анализа [Сидоров 1996], формальные переводы на другой язык [Черкасова 2001] и др.), синтагматические и парадигматические связи с другими элементами.
В последнем случае важное значение имеет способ «вскрытия» латентных ассоциативных отношений формального тезауруса – способ установления так называемых «сил связи». Выделим как возможные следующие способы: логико-интуитивный, дистрибутивно-статистический, компонентный, логико-семантический (первые три подробно описаны в [Москович 1971], последний представляет собой методику примененную Ю.Н. Карауловым при создании Семантического словаря русского языка). При этом возможен даже и выход за рамки вербального эксперимента.
Результаты некоторых проведенных исследований по материалам ассоциативных экспериментов приведены в литературе (см., например, сборники статей под ред. Н.В. Уфимцевой «Языковое сознание…» 1996, 1998, 2000, 2004).
Приведем пример использования последней разработки электронной версии «Русского ассоциативного словаря-тезауруса» на CD-ROM [см. Черкасова 2004]. Она позволяющая получать словарные статьи прямого и обратного ассоциативных словарей по всему корпусу, и по заданным значениям отдельных параметров респондентов, например, указав пол, можно получить гендерный ассоциативный словарь. На рис. 4 даны экранные формы, показывающие самые маленький узлы сети РАС. Стимул членский имеет всего четыре реакции: билет 54, взнос 49, кулич, облом 1, при этом первые две являются стимулами, но как видно из обратного словаря только стимул взнос имеет реакцию членский. Статья стимула гречневая включает шесть реакций, из которых два (каша и крупа), будучи стимулами породили реакцию гречневая.
В заключении назовем некоторые приложения, для которых формальное описание ассоциативного исследования и его составных частей является своеобразной точкой отсчета новых научно-технических разработок. Выделим два направления.
- Разработка интеллектуальных средств поддержки коммуникативного взаимодействия пользователей человеко-машинных систем. В рамках этого направления такими приложениями являются задачи создания словарно-тезаурусных и процессорных компонент лингвистических баз знаний интеллектуальных информационных систем различного назначения – автоматического перевода, обучающих и тестирующих, информационно-поисковых, разговорных, автоматического индексирования и реферирования и др.
- Разработка средств автоматизации различных технологических процессов, в первую очередь связанных со следующими задачами: введения в научный оборот результатов психолингвистических исследований в форме печатных и электронных словарей-тезаурусов, создания систем и разработки оптимальных технологий автоматизации экспериментов, проектирования автоматизированных систем научных исследований в прикладной лингвистике (лексикографии, психолингвистике и др.) и др.
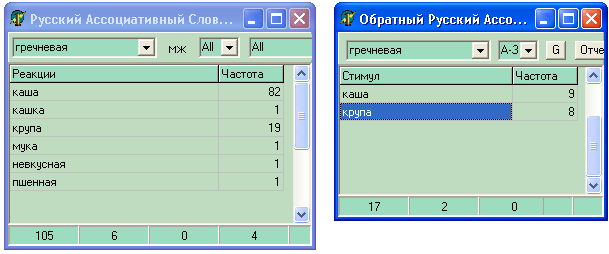
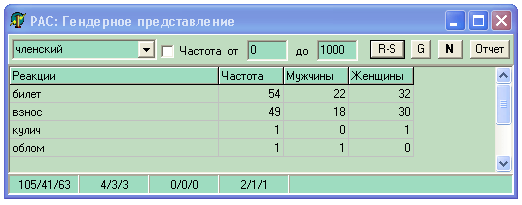
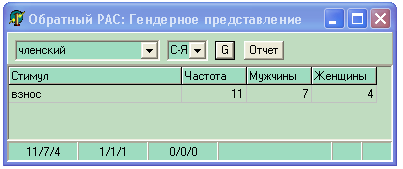
Рисунок 4. Исследование сети РАС на примере узлов гречневая и членский.
Приведенные в статье формальные описания и количественные оценки результатов ассоциативных экспериментов имеют значение, прежде всего, для разработки перечисленных прикладных задач.
Литература
1 Исследование проведено в рамках проектов: грант РФФИ № 01-06-80148 и Ведущая научная школа НШ № 1974.2003.6.
2 Часть исходного списка стимулов (около 7 000 слов) и испльзовалось для генерации серии анкет с тем чтобы получить на каждый стимул 500 реакций .
3 Хотя среди стимулов и реакций есть не только слова, но и словосочетания, при дальнейшем рассмотрении будем ля простоты называть все множество разных реакций словами реакциями.
4 Приведем некоторые узлы (слова-реакции) в порядке убывания количества входящих в него дуг: человека – 443; жизни –359; друга – 253; людей – 214; красивая — 212; стоит – 174 и т.д. Как видно из примеров, это словоформы слов-стимулов.
© НОК CLAIM, 2006-2012. Замечания, вопросы и сведения об ошибках просим сообщать в форуме или присылать администратору сайта.