
CLAIM – научно-образовательный кластер
Г.А. Черкасова
Русский ассоциативный тезаурус: компьютерная версия
| Книга РАС это не «иллюстративный материал», собранный составителями и представленный в такой форме, а алгоритмически сконструирован- ный лингвистический объект, являющийся одним из возможных способов представления языка. | |
| (Русский ассоциативный словарь. Предисловие) |
Содержание
Формирование «Русского ассоциативного тезауруса»
Состав и структура базы данных «Русского ассоциативного тезауруса»
«Русский ассоциативный словарь-тезаурус» на CD-ROM
Введение
На конференции в октябре 2003 г. в Звенигороде был продемонстрирован «Русский ассоциативный словарь-тезаурус» (РАСт) — первая компьютерная версия «Русского ассоциативного тезауруса» (РАТ), предназначенная для записи на CD-ROM.
Продемонстрированная разработка стала возможной, благодаря финансовой поддержке Совета по грантам Президента РФ, Российского фонда фундаментальных исследований, Российского гуманитарного научного фонда, средства которых (РГНФ № 96-04-16145; РФФИ № 93-06-11049, № 98-06-87047, № 96-15-98631, № 00-15-98826; НШ № 1976.2003.6) позволили: провести ассоциативный эксперимент, обработать собранные анкеты и создать базы данных; издать «Русский ассоциативный словарь» (РАС) в шести книгах; создать CD-ROM версию «Русского ассоциативного тезауруса».
Следует отметить, что на содержание и форму представления «Русского ассоциативного словаря-тезауруса» оказали влияние работы по подготовке оригинал-макета двухтомного «Русского ассоциативного словаря» (выпущенного в 2002 г. издательствами АСТ и Астрель), а также проводимые в настоящее время в рамках гранта РФФИ № 01-06-80148 лемматизация словарного корпуса РАТ и исследование семантико-категориальных структур языкового сознания русских.
Формирование «Русского ассоциативного тезауруса»
Данные для «Русского ассоциативного тезауруса» получены в результате трехэтапного анкетного опроса испытуемых (для которых родной язык русский) в ходе массового ассоциативного эксперимента, проведенного в период с 1988 по 1997 годы. РАТ является новым типом словаря, в котором представлен активный словарный фонд современного русского языка, используемый в определенном временном промежутке. Он моделирует вербальную память и языковое сознание «усредненного» носителя русского языка.
На каждом этапе ассоциативного эксперимента были составлены списки стимулов, сгенерированы и распечатаны анкеты, проведен опрос и материалы введены в компьютер с использованием текстовых редакторов. После выполнения специальной программы формального контроля введенных анкет, все пары «стимул-реакция» (S–R) занесены в базы данных исследования. Подробно технология проведения эксперимента и его параметры, а также программные компоненты описаны в работах [РАС; РАС-2002; Черкасова 1996, 1998].
На рис. 1 приведена диаграмма, показывающая соотношение объемов стимулов на каждом этапе в процентах к их общему количеству, а также даны некоторые параметры каждого этапа. Так как некоторые стимулы повторялись на разных этапах опроса, на диаграмме показаны размеры этих повторов (пересечений списков стимулов на разных этапах эксперимента).
| № этапа | Количество стимулов | Количество предъявлений стимулов | Количество анкет | |
| напечатанных | введенных в БД | |||
I |
1277 |
100 |
1500 |
~1300 |
II |
2685 |
100 |
3000 |
~2800 |
III |
2935 |
100 |
3500 |
~3150 |
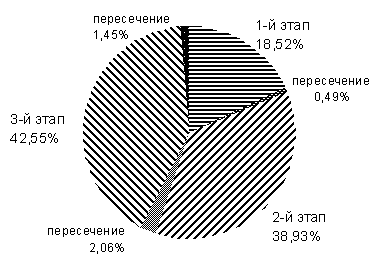
В результате объединения материалов трех этапов была подготовлена сводная компьютерная версия ассоциативного тезауруса, которая и будет рассматриваться в этой статье.
Приведем итоговые характеристики ассоциативного эксперимента и созданной базы данных (БД РАТ):
- 6624 разных стимула использовались в опросе, из которых 313 — словосочетания;
- 11,5 тысяч анкет подготовлено для опроса;
- 10 428 анкет введено в БД;
- 1 037 522 пары «стимул–реакция» включает БД РАТ, из которых 16 839 реакций это отказы от ответа;
- 1 млн. 160 тысяч словоупотреблений включают реакции, так как 76 044 из них неоднословны;
- 462 500 разных пар «стимул–реакция» включены в БД;
- 102 926 разных реакций определяют размерность обратного словаря;
- 30 тысяч понятий, т.е. лемматизированных (приведенных к основной форме) словоформ, получены из корпуса словаря.
Первая строка в этом списке фиксирует объем прямого словаря (от стимула к реакции), а предпоследняя — количество словарных статей в обратном словаре (от реакции к стимулу). Последняя строка — это размерность алфавитно-частотного и частотно-алфавитного лексиконов, полученных в результате этапа автоматической лемматизации данных РАТ и ее ручной коррекции.
Состав и структура базы данных «Русского ассоциативного тезауруса»
База данных «Русского ассоциативного тезауруса» включает следующие таблицы:
- Сводная таблица стимулов ассоциативного эксперимента — это алфавитный список <стимулов> и <номеров стимулов 1> всего 6624 записи (фрагмент дан на рис.2);
- Исходная (основная) таблица содержит записи, включающие следующие тройки: <номер стимула> <реакция> <номер анкеты> (фрагмент для стимула двоюродный дан рис.3);
- Таблица анкетных данных,котораядлякаждого <номера анкеты> включает сведения о респондентах, т.е. <пол>, <специальность> и <возраст> (10 428 записей);
- Таблица специальностей, содержит список из 34 <номеров> и <названий специальностей> респондентов, опрошенных в ассоциативном эксперименте.
- Производная таблица, получаемая путем обработки 2-й таблицы данных: сначала сортировки по первому полю (т.е. номеру стимула), а затем вычисления количества одинаковых ответов — реакций. Структура таблицы: <номерстимула><реакция><количествоответивших> (фрагмент для стимула квашенная приведен на рис.4).
Стимул |
Номер общий |
Номер из анкет |
а |
1 |
1 |
абзац |
2 |
3975 |
абсолют |
3 |
3976 |
абсолютный |
4 |
2 |
абсурд |
5 |
3977 |
авангардист |
6 |
3978 |
авария |
7 |
1292 |
авоська |
8 |
3979 |
Австралия |
9 |
3980 |
. . . |
. . . |
. . . |
двоюродный |
1169 |
4491 |
. . . |
. . . |
. . . |
квашенная |
2060 |
2098 |
Рисунок 2. Фрагмент таблицы стимулов.
Номер стимула |
Реакция |
Номер анкеты |
|
1169 |
/ |
11405 |
|
1169 |
брат |
5577 |
Всего |
1169 |
брат |
5729 |
|
. . . . |
. . . . |
. . . . |
|
1169 |
брат |
11905 |
|
1169 |
брат |
12001 |
|
1169 |
брать |
9330 |
|
1169 |
брать |
11901 |
|
1169 |
двоюродный |
10410 |
|
1169 |
дядя |
11099 |
|
1169 |
кузен |
9775 |
|
1169 |
кузен |
10569 |
|
1169 |
родной |
10690 |
|
1169 |
троюродный |
9726 |
|
1169 |
троюродный |
10109 |
Рисунок 3. Фрагмент основной таблицы для стимула двоюродный.
| Номер стимула | Реакция | Кол-во ответивших |
2060 |
голова |
1 |
2060 |
капуста |
90 |
2060 |
квашенная |
1 |
2060 |
кислая |
2 |
2060 |
кисло |
1 |
2060 |
кислый |
1 |
2060 |
морда |
2 |
2060 |
некогда |
1 |
2060 |
репа |
1 |
2060 |
свекла |
1 |
2060 |
скамья |
1 |
2060 |
физиономия |
1 |
Рисунок 4. Фрагмент производной базы для стимула квашенная.
После сортировки 5-ой таблицы по общему номеру стимула, по убыванию числа ответивших, реакциям по алфавиту, получается таблица «Прямого ассоциативного словаря», которая имеет вид, представленный в таблице 4.
Сортировка этой же 5-й таблицы по реакциям, по убыванию числа ответивших и номеру стимула формирует «Обратный ассоциативный словарь», фрагмент которой для реакции Лермонтов приведен на рис.5).
Реакция |
Частота |
Номер стимула |
Стимул |
Лермонтов |
11 |
4677 |
Пушкин |
Лермонтов |
8 |
2647 |
маскарад |
Лермонтов |
7 |
4348 |
поэт |
Лермонтов |
3 |
2510 |
лирик |
Лермонтов |
3 |
5538 |
стихотворение |
Лермонтов |
2 |
1460 |
дуэль |
Лермонтов |
2 |
2070 |
кинжал |
Лермонтов |
2 |
2605 |
Максимыч |
Лермонтов |
2 |
4347 |
поэма |
Лермонтов |
2 |
4566 |
пророк |
Лермонтов |
2 |
5534 |
стих |
Лермонтов |
1 |
397 |
вал |
Лермонтов |
1 |
1145 |
даром |
Лермонтов |
1 |
1428 |
дума |
Лермонтов |
1 |
2646 |
маска |
Лермонтов |
1 |
2893 |
мужьям |
Лермонтов |
1 |
3796 |
памятник |
Лермонтов |
1 |
3956 |
писатель |
Лермонтов |
1 |
4662 |
пустоголовый |
Лермонтов |
1 |
4879 |
рифма |
Лермонтов |
1 |
6012 |
узник |
Рисунок 5. Фрагмент базы обратного словаря.
Если производную базу отсортировать по убыванию значения поля <кол-во ответивших>, то получается список самых частотных пар «стимул-реакция», фрагмент которого приведен на рис.6.
Стимул |
Реакция |
Частота |
Стимул |
Реакция |
Частота |
язык |
родной |
226 |
убытки |
возмещать |
190 |
письмо |
написать |
223 |
словарь |
краткий |
187 |
дверь |
записать |
215 |
голос |
громкий |
183 |
друг |
настоящий |
215 |
дверь |
открывать |
180 |
домой |
вернуться |
209 |
книгу |
читать |
180 |
ложь |
неправда |
208 |
человек |
ничтожный |
178 |
ответ |
лаконичный |
204 |
имя |
называть |
177 |
голубое |
небо |
201 |
случай |
особый |
175 |
человек |
нужный |
201 |
человек |
деятельный |
174 |
друг |
милый |
197 |
улицу |
переходить |
174 |
за нос |
водить |
195 |
лес |
дремучий |
173 |
человек |
серьезный |
195 |
так |
просто |
173 |
письмо |
прислать |
194 |
воздух |
сжатый |
172 |
дорого |
стоить |
194 |
по течению |
плыть |
171 |
друг |
лучший |
193 |
зеленая |
трава |
171 |
красное |
знамя |
191 |
на помощь |
звать |
168 |
Рисунок 6. Фрагмент самых частотных пар «стимул-реакция».
Вычисления, проведенные по таблице «Обратного ассоциативного словаря», позволяют увидеть как самые частотные реакции, так и те, которые вызваны наибольшим количеством стимулов. Эти данные позволяет исследовать ядро языкового сознания «усредненного» носителя русского языка. В таблице на рис.7 приведены самые частотные реакции-леммы (слова-реакции, приведенные к основной форме в результате лемматизации корпуса РАТ), при этом они упорядочены по убыванию количества стимулов, их вызвавших.
|
Слово-лемма |
Класс |
Число форм |
Количество употреблений |
||
во всех анкетах |
в разных парах «стимул-реакция» |
порождено стимулами |
|||
человек |
мо; |
10 |
17553 |
3808 |
765 |
весь |
мс; |
10 |
5094 |
2379 |
755 |
быть |
нсв; |
15 |
3611 |
2122 |
747 |
я |
мс; |
10 |
3998 |
2085 |
714 |
как |
част.; |
1 |
1640 |
1174 |
708 |
длить |
нсв; |
2 |
1560 |
1006 |
585 |
что |
мс; |
6 |
2235 |
1551 |
556 |
он |
мс; |
22 |
3083 |
1781 |
498 |
эта |
мс; |
11 |
1190 |
795 |
456 |
ты |
мс; |
9 |
2203 |
1211 |
410 |
хороший |
п; |
18 |
5359 |
2282 |
409 |
что |
союз; |
1 |
1155 |
800 |
335 |
это |
част.; |
1 |
810 |
590 |
325 |
мой |
мс-п; |
12 |
3825 |
1294 |
320 |
жизнь |
ж; |
4 |
4739 |
1948 |
317 |
себы |
мс; |
4 |
3836 |
1214 |
295 |
деть |
св; |
6 |
6692 |
1515 |
294 |
а |
союз; |
1 |
411 |
330 |
269 |
та |
мс; |
14 |
763 |
470 |
267 |
нет |
част.; |
1 |
2110 |
1105 |
265 |
свой |
мс-п; |
12 |
981 |
542 |
260 |
свой |
мс; |
12 |
981 |
542 |
260 |
другой |
п; |
14 |
5717 |
1533 |
250 |
кто |
мс; |
10 |
1639 |
983 |
248 |
но |
союз; |
1 |
327 |
268 |
238 |
мыть |
нсв; |
14 |
3503 |
1099 |
231 |
дом |
м; |
9 |
7081 |
1900 |
227 |
нет |
предик; |
1 |
1819 |
954 |
226 |
дело |
с; |
9 |
3359 |
1122 |
225 |
рука |
ж; |
9 |
2994 |
1007 |
222 |
вода |
ж; |
8 |
3586 |
980 |
222 |
большой |
п; |
16 |
5140 |
1595 |
221 |
плохой |
п; |
14 |
3544 |
1729 |
217 |
что-то |
н; |
1 |
798 |
523 |
217 |
день |
м; |
9 |
4538 |
932 |
215 |
очень |
н; |
2 |
954 |
637 |
206 |
друг |
мо; |
10 |
6780 |
1797 |
205 |
любить |
нсв; |
32 |
2506 |
1153 |
201 |
времы |
с; |
7 |
2369 |
814 |
197 |
Рисунок 7. Исследование ядра языкового сознания.
Программная поддержка
Для проведения и обработки материалов ассоциативного эксперимента были разработаны специальные программные средства с использованием языков программирования и возможностей СУБД Paradox for Windows v.5.0 (rus). Они включают программы для формирования баз данных, выборки и сортировки необходимой информации, получения статистических показателей, подготовки данных для последующей автоматизированной верстки книг РАС и создания электронных изданий на CD-ROM.
Средства СУБД применялись для сортировки и объединения записей при создании производных баз данных, а также для получения выборок данных из БД РАТ при проведении различных научных исследований.
Основными возможностями системы являются:
- диалоговый режим взаимодействия с пользователями в виде иерархических "меню";
- поддержка запросов пользователей к базам прямого и обратного ассоциативного словарей;
- получение статистической информации о словах-стимулах и реакциях;
- получение проекций баз прямого и обратного ассоциативного словарей;
- введение лингвистических параметров, характеризующих стимулы и реакции в базы данных;
- получение подмножеств баз прямого и обратного ассоциативного словаря с учетом морфемной структуры слов-стимулов и реакций, введенных лингвистических параметров и сведений из исходной базы данных.
Например, проводя исследование встречаемости предлогов, частиц, союзов и др. в корпусе Ассоциативного тезауруса, были получены данные, которые сведены в таблицу на Рис. 8 .
Предлоги |
Количество |
Частота > 1 |
Самые частотные реакции с предлогами |
||
записей |
всего |
разных |
|||
в |
12074 |
25416 |
4448 |
2899 |
в море 143; в помощи 136 |
на |
7070 |
15197 |
2921 |
1733 |
на помощь 168; на лучшее 131 |
не |
7078 |
10147 |
3363 |
1003 |
не дура 141; не тетка 99 |
с |
4282 |
8323 |
2066 |
975 |
с начала 97, 96 |
и |
3784 |
6010 |
2921 |
619 |
и Маргарита 82; и молот 49 |
о |
2470 |
4846 |
908 |
577 |
о встрече 141; о бок 124 |
по |
2285 |
4866 |
1023 |
528 |
по течению 171; по улице 100 |
за |
1999 |
4069 |
882 |
483 |
за нос 195; за помощью 57 |
к |
1719 |
3426 |
735 |
431 |
к экзамену 78; к экзаменам 63 |
от |
1668 |
2941 |
795 |
368 |
от себя 49; от оспы 30; от яйца 30 |
из |
1310 |
2594 |
757 |
295 |
из могикан 51; из правил 48 |
как |
1085 |
1516 |
698 |
169 |
как рыба 25; как лошадь 22 |
для |
980 |
1532 |
581 |
166 |
для народа 28; для книг 28 |
у |
838 |
1101 |
452 |
113 |
у дома 26; у моря погоды 16 |
до |
822 |
1596 |
365 |
189 |
до зубов 32; до ушей 28 |
под |
402 |
593 |
231 |
66 |
под солнцем 26; под глазом 25 |
|
|
|
|
|
|
нет |
407 |
463 |
241 |
35 |
нет ответа 7; а может и нет 5 |
Рисунок 8. Встречаемость предлогов по базе РАТ.
Так как ассоциативный тезаурус существует только в компьютерной форме, и он постоянно изменяется и дополняется, то по его материалам были подготовлены и выпущены два разных издания «Русского ассоциативного словаря» (1994–1998, 2002).
Кроме этого в 2002 году Андреем Филипповичем в рамках ведущей научной школы № 00-15-98826 создана первая электронная версия «Русского ассоциативного словаря-тезауруса» на CD-ROM, позволяющая получать как словарные статьи прямого и обратного ассоциативных словарей по всему корпусу, так и по заданным значениям отдельных параметров респондентов (например, указав пол, можно получить гендерный ассоциативный словарь).
«Русский ассоциативный словарь-тезаурус» на CD-ROM
Рассмотрим как работает компьютерная версия РАСт и покажем на примерах ее возможности. Как и в книжном издании РАСт имеет два входа: прямой от стимула S  R и соответственно обратный — от реакции R
R и соответственно обратный — от реакции R  S.
S.
После запуска компьютерной версии РАСт появится следующий экран, представленный на Рис. 9.
где:
 поле, в котором выбирается или задается стимул;
поле, в котором выбирается или задается стимул;
 указатель, показывающий выборку испытуемых и принимающий значения: МЖ (все), М (мужчины), Ж (женщины);
указатель, показывающий выборку испытуемых и принимающий значения: МЖ (все), М (мужчины), Ж (женщины);
 поле, в котором задается номер специальности; по умолчанию задано All, т.е. для всех специальностей;
поле, в котором задается номер специальности; по умолчанию задано All, т.е. для всех специальностей;
 поле для задания возраста; по умолчанию задано All, т.е. для всех возрастов;
поле для задания возраста; по умолчанию задано All, т.е. для всех возрастов;
 кнопка «R-S» включаетя экран, отображающий «Обратный ассоциативный словарь»;
кнопка «R-S» включаетя экран, отображающий «Обратный ассоциативный словарь»;
 переключатель «G», задающий гендерное представление словаря;
переключатель «G», задающий гендерное представление словаря;
 кнопка «Отчет» — выводит результаты на печать;
кнопка «Отчет» — выводит результаты на печать;
 столбец «Реакции» показывает реакции на выбранный стимул;
столбец «Реакции» показывает реакции на выбранный стимул;
 столбец «Частота» содержит частоты соответствующих реакций.
столбец «Частота» содержит частоты соответствующих реакций.
Внизу таблицы в четырех клеточках приводятся следующие количественные характеристики (аналогично книжному изданию):
10 – общее число реакций на данный стимул;
11 – число разных реакций, т.е. количество строк в таблице;
12 – число отказов испытуемых от ответа на выбранный стимул;
13 – количество реакций, имеющих единичную частоту.
При исследовании гендерного представления данных ассоциативного тезауруса (нажав кнопку ) на экране поменяется часть полей, и он примет следующий вид:
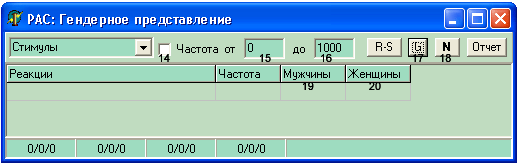
где:
14 поле, включающее задание интервала частот встречаемости реакций (при нажатии левой кнопки мыши в поле появляется знак «галка»); в этом режиме необходимо задать частоты «от» и «до» соответственно в полях 15 и 16;
17 – переключатель, задающий гендерное представление словаря, изменяет свой цвет;
18 – включение режима «нормирования»;
19 и 20 задают соответственно столбцы частот отдельно для мужчин и женщин.
В нижней части экрана в каждой из четырех ячеек, содержащих количественные характеристики, появляется уже по три числа (через разделитель «/»): первое — количество для всех, второе — количество для мужчин, третье — количество для женщин.
Второй вход от реакции может быть получен нажатием кнопки на экране, представленном на Рис. 9.

где:
21 – поле, в котором выбирается или задается реакция;
22 – в данном поле задается интервал, который включает первую букву реакции, так как количество разных реакций более 100 тысяч, для сокращения времени поиска весь массив разных реакций разбит на четыре части (на Рис.11, отображено данное поле раскрытым, т.е. после нажатия на «стрелку»);
23 – переключатель, задающий гендерное представление обратного словаря;
24 – кнопка «Отчет» — выводит результаты на печать;
25 – столбец «Стимул» показывает стимулы, вызвавшие заданную реакцию;
26 – столбец «Частота» содержит частоты стимулов;
27 – поле, в котором указано общее количество респондентов, ответивших данной реакцией;
28 – поле содержит число вызвавших указанную реакцию стимулов;
29 – поле указывает число единичных пар «стимул-реакция».
Задать стимулы в поле (1) и реакции в поле (21) можно двумя способами, либо при раскрытии соответствующих полей, либо
Литература
Технология и результаты обработки
Технология ассоциативного эксперимента всем хорошо известна и на первый взгляд проста и понятна. Это:
- выбрать для исследования слова-стимулы;
- разбить стимулы по анкетам и напечатать их в таком количестве, чтобы каждой стимул встречался не менее заданного числа раз;
- провести опрос испытуемых, предварительно выбрав контингент опрашиваемых;
- обработать полученные анкеты, сводя реакции по каждому отдельному стимулу, вычислить частоту пар «стимул-реакция» и, наконец, упорядочив сводные данные, получить прямой и обратный ассоциативный словарь.
Однако, при сопоставлении результатов (ассоциативных норм) для достоверности необходимо, чтобы выборки респондентов по каждому стимулу были одинаковыми как по количеству опрошенных (например, 100 или 500 чел.), так и по составу отвечающих. То есть, среди анкетируемых по каждому стимулу должно быть равное количество, например, мужчин и женщин; или разные возрастные группы, уровень образования, профессиональной ориентации, семейное положение и другие возможные характеристики респондентов также одинаково должны быть представлены в ответах испытуемых по каждому стимулу. Поскольку все перечисленные параметры контингента испытуемых накладывают отпечаток на его сознание, то рассматривать всех как просто «испытуемые» нельзя считать правомерным или даже правильным.
Если число стимулов невелико (например, при проведении славянского ассоциативного эксперимента авторы выбрали 112 стимулов), то все они размещаются в каждой анкете. Тогда можно проводить сопоставительные исследования внутри каждого отдельного языка, а при одинаковом количестве опрошенных и между всеми славянскими языками.
Для больших экспериментов достичь равновероятной представленности всех категорий испытуемых по каждому отдельному стимулу невозможно, так как каждая анкета содержит свой набор стимулов и нет двух одинаковых. Поэтому необходимо уже на этапе опроса необходимо зафиксировать те параметры, по значениям которых будет проводить сопоставительные исследования.
Например, при создании РАС, где использовалось 6624 разных стимула и было опрошено более 10 тыс. испытуемых, получены 1 037 522 пары «стимул–реакция», не удалось добиться равномерности выборок даже по показателю «пол», поэтому при рассмотрении гендерного разреза словаря, использования абсолютных частот встречаемости тех или иных ответов-реакций оказывается часто не правомерным или даже не правильным (см. об этом ниже).
Для более одного миллиона словоупотреблений проводилось сравнение частотного словника ассоциативного словаря с частотными словарями русского языка, построенными по корпусам текстов. Выявлено сходство употребительности большинства предлогов, например, предлоги «в» и «на» имеют во всех случаях самую большую частоту (см. таблицу ниже).
| Слово-лемма |
Класс |
Число форм |
Количество употреблений |
|||
во всех анкетах |
в разных парах «стимул-реакция» |
порождено стимулами |
||||
в |
предл. |
1 |
25586 |
12225 |
4539 |
|
человек |
мо; |
10 |
17553 |
3808 |
765 |
|
на |
предл. |
1 |
15342 |
7170 |
2954 |
|
не |
част. |
1 |
10191 |
7124 |
3378 |
|
с |
предл.. |
1 |
8410 |
4356 |
2083 |
|
дом |
м; |
9 |
7081 |
1900 |
227 |
|
друг |
мо; |
10 |
6780 |
1797 |
205 |
|
и |
союз; |
1 |
6092 |
3867 |
2956 |
|
другой |
п; |
14 |
5717 |
1533 |
250 |
|
хороший |
п; |
18 |
5359 |
2282 |
409 |
|
большой |
п; |
16 |
5140 |
1595 |
221 |
|
весь |
мс; |
10 |
5094 |
2379 |
755 |
|
о |
предл. |
1 |
4942 |
2569 |
935 |
|
по |
предл. |
4928 |
2329 |
1031 |
||
жизнь |
ж; |
4 |
4739 |
1948 |
317 |
|
за |
предл. |
1 |
4166 |
|
893 |
|
я |
мс; |
10 |
3998 |
2085 |
714 |
|
быть |
нсв; |
15 |
3611 |
2122 |
747 |
|
плохой |
п; |
14 |
3544 |
1729 |
217 |
|
к |
предл. |
1 |
3487 |
1767 |
756 |
|
он |
мс; |
22 |
3083 |
1781 |
498 |
|
от |
предл. |
1 |
2999 |
1703 |
799 |
|
что |
мс; |
6 |
2235 |
1551 |
556 |
|
Самое частотное понятие ассоциативного тезауруса «ЧЕЛОВЕК» включающее парадигмы форм человек и люди, зафиксированное в 17553 реакциях [что составляет 1,7% от общего числа ответов] на 2326 стимула [35%], содержится в 3808 разных парах «стимул-реакция» (1415 из которых словосочетания), при этом получено 765 разных реакции (747 словосоч.). Статистика по разным формам следующая в парах стимул-реакция:
человек мо; человек (2103); человека (651); человеке (43); человеком (97); человеку (101); людей (335); люди (305); людьми (50); людям (99); людях (24).
Есть также производные от данного понятия – человек-амфибия (3) жо; человек-бог (1) мо; человек-гора (1) ж; человек-индивид (1) мо; человек-лентяй (1) мо; человек-невидимка (1) мо-жо; человек-тормоз (1) м; человек-фантазер (1) мо; человечек (20) мо; человечишка (2) жо; человечище (1) со.
В результате этапа лемматизации и ее ручной коррекции подготовлены данные для построения алфавитно-частотного и полного частотно-алфавитного лексикона среднего носителя современного русского языка. Частотно-алфавитный словник сделан в трех разрезах, фрагменты которых даны в приложении.
Компьютерная технология АТРЯ
Компьютерная технология РАТ – это система, состоящая из программной оболочки и баз данных, приведена схематически.
Программная оболочка. Программные средства оболочки разработаны с использованием языка программирования Basic и средств СУБД. Они содержат программы для формирования баз данных, выборки и сортировки необходимой информации, получения статистических показателей, подготовки данных для последующей автоматизированной верстки книг РАС.
В настоящее время для работы используется Paradox for Windows v.5.0 (rus). Средства СУБД использовались для ввода данных в исходные БД, их сортировки и объединения, осуществления простейших выборок из баз исходных данных для анализа и исследования АВС.
Основными возможностями системы являются:
- диалоговый режим взаимодействия с пользователями в виде иерархических "меню";
- поддержка запросов пользователей к базам прямого и обратного ассоциативного словарей;
- получение статистической информации о словах-стимулах и реакциях;
- получение проекций баз прямого и обратного ассоциативного словарей;
- введение лингвистических параметров, характеризующих стимулы и реакции в базы данных;
- получение подмножеств баз прямого и обратного ассоциативного словаря с учетом морфемной структуры слов-стимулов и реакций, введенных лингвистических параметров и сведений из исходной (вспомогательной) базы данных.
Программная оболочка создает, обрабатывает и использует все базы данных АТРЯ.
- база данных прямого ассоциативного словаря;
- база данных обратного ассоциативного словаря.
1 Поскольку на каждом из трех этапов ассоциативного опроса использовался свой упорядоченный, т.е. отсортированный по алфавиту, список стимулов, то в анкетах номера изменялись для первого этапа от 1 до 1277, второго — от 1285 до 3965, а третьего от 3966 до 6895, поэтому в сводной таблице каждый стимул, на самом деле, имеет два номера: общий алфавитный и номер из анкет для опроса. В базе данных РАТ содержится не сам стимул, а его номер, что ускоряет компьютерную обработку материалов ассоциативного эксперимента.
© НОК CLAIM, 2006-2012. Замечания, вопросы и сведения об ошибках просим сообщать в форуме или присылать администратору сайта.