
CLAIM – научно-образовательный кластер
Практические занятия по дисциплине
"Лингвистическое обеспечение АСОИУ"
Работа в OCR-системе ABBY Fine Reader.
Цель занятия:
Приобретение навыков работы в пакете ABBY FineReader. Распознавание и корректура текста хорошего качества на русском языке. Распознавание с обучением текста, набранного декоративной шрифтовой гарнитурой.
Задание 1: Распознавание простого текста.
Необходимо осуществить обработку простого текста в пакете ABBY FineReader: распознавание и корректуру.
Порядок выполнения:
1. Запустить программу ABBY FineReader.
2. Создать новый пакет, сохранить его.
Для этого необходимо использовать следующие команды: Файл
Новый пакет ( Ctrl+ N).
3. Открыть отсканированное изображение страницы текста. В качестве такого текста может выступать любой русский текст хорошего качества без рисунков, таблиц и схем.
Для этого необходимо нажать либо кнопку
, либо
.
После этого возникает окно с изображением страницы, окно «текст» и окно укрупненного изображения,которые впоследствии будут использованы при корректуре.
4. Распознать текст.
Для распознавания текста необходимо нажать кнопку
.
После распознавания возникает окне «текст» появится сам распознанный текст.
5. Осуществить корректуру текста.
Для этого необходимо нажать кнопку
При этом появится окно проверки текста:
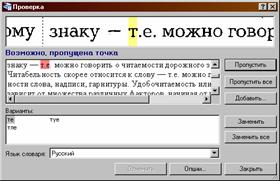
6. Передать полученный текст в Microsoft Word и сохранить полученный текстовый файл.
Для этого необходимо нажать кнопку
. После этого будет запущена программа Microsoft Word и проверенный текст появится на экране. Его следует сохранить в формате *. doc, для этого в меню «Файл» необходимо выбрать «Сохранить».
Задание 2: Распознавание и корректура текста со сложной верстки.
Необходимо осуществить обработку текста со сложной версткой в пакете ABBY FineReader: распознавание и корректуру.
Порядок выполнения:
1. Вернуться в программу ABBY FineReader.
2. Открыть отсканированное изображение страницы текста. В качестве такого текста может выступать любой русский текст со сложной версткой, содержащий рисунки, таблицы и схемы.
3. Распознать текст.
Для наилучшего результата рекомендуется вручную выделить и отредактировать элементы для распознавания. Для этого в окне «Изображение» необходимо выделить текстовые фрагменты, рисунки, таблицы с помощью соответствующих инструментов на панели слева.
Рекомендуется настроить опции распознавания, для этого в падающем меню кнопки «Распознать» необходимо выбрать опции, при этом появится следующее окно:
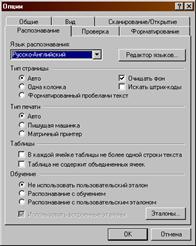
4. Осуществить корректуру текста.
Для наилучшего результата необходимо настроить опции проверки текста, для этого в падающем меню кнопки «Проверить» необходимо выбрать опции.
5. Передать полученный текст в Microsoft Word и сохранить полученный текстовый файл.
Задание 3: Распознавание с обучением.
Необходимо осуществить обработку текста, набранного декоративной (старинной) шрифтовой гарнитурой в пакете ABBY FineReader.
Порядок выполнения:
1. Запустить программу ABBY FineReader.
2. Создать новый пакет, сохранить его.
Для этого необходимо использовать следующие команды: Файл
Открыть отсканированное изображение страницы текста. В качестве такого текста может выступать любой русский текст хорошего качества без рисунков, таблиц и схем.
Для этого необходимо нажать либо кнопку
.
После этого возникает окно с изображением страницы, окно «текст» и окно укрупненного изображения,которые впоследствии будут использованы при корректуре.
3. Распознать текст.
Программа ABBY FineReader обучена распознаванию стандартных шрифтов и не предназначена для распознавания декоративных шрифтов, например, FuturisXShadowC, ParagmaticaShadowC, CyrillicGoth.
Для повышения качества распознавания данного документа воспользуемся специальным режимом распознавания: распознавание с обучением. Обычно в данном режиме распознаются 1-2 страницы, в результате чего создается пользовательский эталон, который в дальнейшем подключается для распознавания остальных страниц. При этом важно помнить, что созданный эталон можно использовать только для распознавания текстов, использующих тот же шрифт и размер шрифта и отсканированных с тем же разрешением, что и документ, на основе которого данный эталон создавался.
Выделите блоки на изображении (меню Процесс
Установите режим Распознавание с обучением (на закладке Распознавание, меню Сервис
Установите язык распознавания (Русский) .
Нажмите кнопку
.
Обучите эталон, распознав страницу в режиме распознавания с обучением. Обучаемые символы заносятся в эталон, создаваемый системой по умолчанию. По окончании обучения система сохранит созданный эталон (default.ptn) в папке, где хранится пакет.
Отредактируйте эталон .
Отмените режим Распознавание с обучением (на закладке Распознавание в группе Обучение установите переключатель в положение Распознавание с пользовательским эталоном).
После распознавания возникает окне «текст» появится сам распознанный текст.
4. Осуществить корректуру текста.
Для этого необходимо нажать кнопку
При этом появится окно проверки текста:
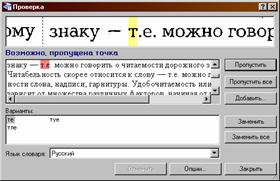
5. Передать полученный текст в Microsoft Word и сохранить полученный текстовый файл.
Для этого необходимо нажать кнопку
. После этого будет запущена программа Microsoft Word и проверенный текст появится на экране. Его следует сохранить в формате *. doc, для этого в меню «Файл» необходимо выбрать «Сохранить».
© НОК CLAIM. Замечания, вопросы и сведения об ошибках просим сообщать в форуме или присылать администратору сайта.