![]()
статьи и тезисы |
Автоматизированная технология корректуры переиздания Словаря Академии Российской 1789-1794 гг. на основе динамически пополняемого словаря спеллера
Содержание
Формальные модели технологий корректуры
Исследование количества ошибок
Исследование частотных характеристик слов на малом объеме
Исследование частотных характеристик слов на большом объеме
Введение
Одной из сложных проблем, с которыми сталкивается разработчик издания, является поиск и исправление ошибок в тексте. Исправление ошибок осуществляется на этапе корректуры текста. «Корректура, совокупность процессов, назначением которых является исправление ошибок и нарушений технических правил в наборе» [Гунько, 1995]. Корректура является одним из этапов допечатной подготовки издания, в результате которой формируется оригинал-макет издания.
В «традиционном классическом описании» корректура состоит из двух основных процессов: чтения корректурных оттисков и правки набора. Оттиски с набора читают корректоры, сличающие их с оригиналом или с предыдущими корректурными оттисками, а также авторы и редакторы, проверяющие правильность введенного текста по существу. При чтении оттисков ошибки отмечаются специальными корректурными знаками, повторяемыми на полях оттисков, причем рядом с этими знаками указываются правильные буквы, слова и т.п. [Гунько, 1995]. После этого правка с корректурных оттисков вносится в набор.
В современной технологии допечатного процесса на основе средств вычислительной техники корректура осуществляется в текстовых процессорах и программах верстки. В связи с этим понятия, описывающие корректуру, изменились. Так, говоря о наборе, подразумевают ввод и формирование электронного документа, а под оттиском набора - распечатку этого документа. Кроме этого современные текстовые процессоры содержат встроенные функции проверки текста на наличие грамматических, синтаксических и стилистических ошибок. Одна из них – функция спеллер (speller – сокращение от spelling checker – программа поиска опечаток, корректор [Борковский, 1989]) позволяет автоматизировать корректуру и редактирование текста, снизить временные затраты прежде всего на поиск ошибок в написании слов.
Процесс корректуры регламентирован лишь в основном, и на его конкретное содержание и результаты оказывают влияние множество различных факторов:
- во-первых, особенности издания (первое издание или какое-либо его переиздание);
- во-вторых, индивидуальные особенности текста (тема, предмет, язык, авторские цели, назначение и т.п.);
- в-третьих, профессионализм корректора (культурный уровень, знания, навыки, умения, психологические установки, социально-экономические факторы и др.);
- в-четвертых, технологические факторы (форма рабочего материала, инструментальные аппаратные и программные средства поддержки корректорской деятельности, временные и стоимостные ресурсные ограничения, методика и др.).
В настоящей статье представлены результаты исследований корректурных процессов при переиздании шеститомного Словаря Академии Российской 1789-1794 гг. (далее используется сокращения Словарь и САР). Проект переиздания осуществляется Московским гуманитарным институтом им. Е.Р.Дашковой с 2000 года. В настоящее время из печати вышло пять томов [САР, 2001-2005], завершается допечатная подготовка последнего шестого тома.
«Словарь Академии Российской» является первым результатом созданной в 1783 году Российской Академии. По оценке акад. В.В. Виноградова он — «один из замечательных трудов в русской лексикографии». В нем более 43 тысяч слов лексики XVIII века. В шести томах переиздания содержится наборный текст соответствующих частей «Словаря Академии Российской» и научный комментарий, в который входят: статьи и очерки с иллюстративным материалом к словарю ученых различных специальностей, биобиблиографические справочные данные, прямой и обратный словники Словаря. Словарь адресован широкому кругу специалистов — лингвистов, филологов, историков, этнографов, всем, кто изучает и исследует русскую духовную и материальную культуру XVIII века.
Переиздание Словаря Академии Российской 1789–1794 гг. — это наборное издание факсимильного типа с исправлениями и дополнениями. В переизданном словаре не набирались заново только титульные страницы и «Посвящение» из первой части. Они получены путем сканирования оригинальных листов Словаря и последующей компьютерной обработки изображений.
В переиздании сохранены: пагинация и ее элементы; формат страниц, столбцов (колонок), абзацев и строк; разметка текста (курсив, разрядка); стилевые особенности прямого и курсивного начертания букв основного шрифта; графические элементы оформления страниц.
К его отличиям от оригинального издания 1789–1794 гг. следует отнести: частичное несовпадение шрифтов и пробельных элементов в строках; изменения, внесенные в текст переиздания, связанные с незамеченными ошибками набора и корректуры в издании XVIII в. и другими неточностями; добавление в некоторые тома указателей, словников и комментариев [Филиппович Ю.Н., 2004].
Технология формирования оригинал-макетов томов переиздания Словаря Академии Российской 1789-1794 гг. состоит из следующих этапов допечатного процесса: ввод текста; верстка; корректура; формирование окончательной версии оригинал макета.
Ввод Словаря осуществлялся с ксерокопий оригинального издания с использованием клавиатуры в MS Word, а также с помощью сканеров с последующим распознаванием и сохранением текстовых файлов в формате *.doc. Далее осуществлялась верстка страниц в программе Page Maker. Введенный, а затем и сверстанный тексты словаря распечатывались. Корректура текста состояла из трех последовательных читок и внесения исправлений. Корректор осуществлял поиск ошибок и исправлял их в распечатке. Далее исправления вносились в электронную версию текста. После внесения первой правки, процесс повторялся – осуществлялась следующая читка и т.д. После завершения корректуры был сформирован окончательный вариант оригинал-макета.
Основной целью исследования являлось выявление возможности автоматизации корректуры с использованием спеллеров и определения ее эффективности. При этом решались следующие задачи:
- построение формальных моделей традиционной и автоматизированной технологий корректуры;
- статистические исследования ошибок в тексте Словаря;
- частотные исследования текста Словаря на малом и большом объемах.
Описание решаемых задач и полученные результаты представлены в соответствующих разделах статьи. В заключении сформулированы основные выводы и рекомендации по использованию выполненных расчетов.
Формальные модели технологий корректуры
Регламентация корректурных процессов носит в основном общий характер, прежде всего, из-за индивидуальных особенностей текстов и разнообразия собственных методик, которые используют корректоры. Во всех случаях в инструментарий корректора обязательно входят различные словари. Современная форма словарей – это не только последние печатные издания, но и различные электронные лексикографические ресурсы, в числе которых: электронные словари на CD ROM, Интернет-порталы, словарные базы данных, встроенные в текстовые редакторы и издательские системы орфо- и грамматические редакторы, программы спеллеры и т.п. Электронные ресурсы рассматриваются как современные средства автоматизации корректорской и редакторской деятельности. Однако величина эффекта от их использования может оказаться незначительной, или вовсе отсутствовать.
Например, в одних случаях удобно использовать спеллер, в других – нет. Спеллер обычно содержит наиболее часто употребляемые слова. Если мы имеем дело с текстами, содержащими специфическую лексику, то количество «ошибок», найденных автоматически будет достаточно велико. Эти «ошибки» - слова, которые отсутствуют в словаре спеллера. Поэтому тексты со специфической лексикой проверяют корректоры хорошо знающие эту лексику и с использованием предметных и терминологических словарей. Корректор опирается на собственный опыт и, имея дело с определенным текстом, быстро находит типовые ошибки.
Рассмотрим две технологии корректуры, условно названные нами «традиционной» и «автоматизированной». «Автоматизированная» технология отличается от «традиционной» тем, что в ней используется спеллер с функцией пополнения словаря. Оценим эффективность этих технологий путем исследования их формальных моделей (рис1).
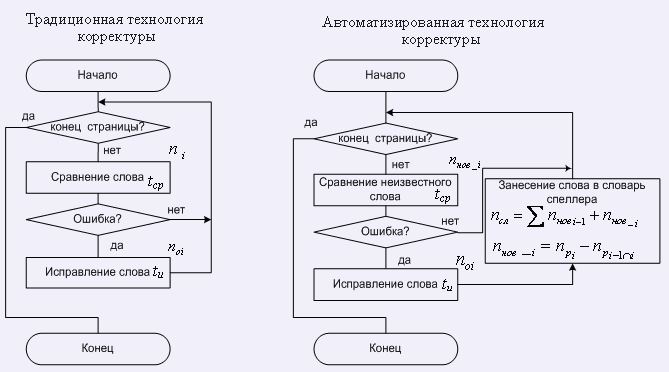
Рисунок 1. Технологии корректуры страницы текста.
Традиционная технология корректуры
Корректор проверяет текст последовательно страницу за страницей. Он сравнивает пословно текст с его оригиналом. Время, затрачиваемое на корректуру, определяет эффективность его работы. Обозначим время корректуры i-ой страницы текста как tki. Оно будет определяться через следующее выражение:
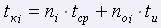 ,
,
где: tср – время сравнения слова, tu – время исправления ошибки, ni – общее количество слов на i-ой странице, noi – количество ошибок на i-ой странице.
Соответственно время корректуры всего текста определяется следующим выражением:
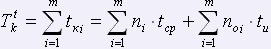 ,
,
где m – количество страниц всего текста.
Анализируя модель данной технологии, можно отметить, что здесь фигурируют два типа параметров: время, затрачиваемое на ту или иную деятельность корректора, и количество слов.
Время сравнения слова с оригиналом, и время исправления слова определяются профессионализмом корректора, его квалификацией. Другими параметрами, от которых зависит эффективность корректуры, является количество слов просматриваемых корректором – ni и количество ошибок на странице noi . Изменение этих параметров позволяет влиять на эффективность корректуры.
Автоматизированная технология корректуры
Технология корректуры с использованием спеллера позволяет автоматизировать процесс проверки ошибок. Корректор последовательно проверяет страницу за страницей текста. Однако он проверяет не все слова, а только слова, неизвестные компьютеру. Эти слова помечены, например, в Word они подчеркнуты волнистой цветной (красной) линией. Каждое правильное неизвестное слово после проверки заносится в словарь. Т.о., по мере пополнения словаря количество неизвестных слов уменьшается на каждой последующей странице.
Предположим, что словарь спеллера пустой, тогда все слова первой страницы будут новыми - неизвестными. На каждой последующей странице слова будут делиться на те, которые уже встречались – «старые» и те, которые не встречались ранее – «новые».
Тогда время проверки страниц определяется следующей формулой:
1-ая страница:
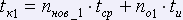 ,
,
где nнов1 – количество новых слов на 1-ой странице, no1 – количество ошибок на 1-ой странице.
Количество новых слов – занесенных в словарь: nсл = nнов_1 = np1 , где np1 – количество разных слов на 1-ой странице (неповторяющихся на странице).
2-ая страница:
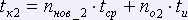 ,
, 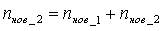 ,
, 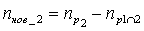 ,
,
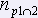 - количество общих разных слов 1-ой и 2-ой страниц.
- количество общих разных слов 1-ой и 2-ой страниц.
…
i-ая страница:
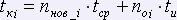 ,
, 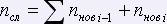 ,
, 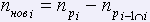
Исследование количества ошибок
Цель данного исследования – это выявить среднее количество ошибок в тексте словаря для того, чтобы оценить параметр noi (количество ошибок на i-ой странице).
В качестве источника исследования был взят фрагмент текста 1-го тома САР – раздел «Показание». Этот раздел представляет собой указатель слов словаря.
Для сравнения были взят текст показания, полученный при вводе текста и итоговый вычитанный вариант. Тексты были обработаны в Word с помощью замен для последующего импорта в таблицы БД. В результате были сформированы таблицы: Pok1tOsh и Pok1t. Далее с помощью запросов были выявлены количественные характеристики таблиц (см. табл.1.).
Таблицы имеют следующую структуру: <Wp,K>, где Wp– слово (словосочетание) показания, K – номер колонки. Фактически каждая запись таблицы Pok1t определяется следующим выражением: ZP = <WP,K>, а запись таблицы Pok1tOsh: ZP_ошиб = <WP_ошиб, Kошиб>.Пусть O – любая ошибка. Обозначим через OZ– ошибку в записи, соответственно OWp – ошибка в слове, OK – ошибка в номере колонки. Тогда количество ошибок в записях определяются по формуле:
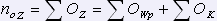 .
.
Обозначим через XZ отсутствие записи (пустую запись), соответственно XWp– отсутствие слова, XK – отсутствие номера колонки. Тогда количество отсутствующих записей вычисляется по формуле:
 .
.
Общее количество несоответствий (ошибок) в тексте показания:
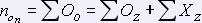 .
.
Расчет количества ошибок в записях:
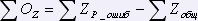 ,
,
где 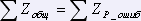 , таких, что ZP_ошиб = ZP .
, таких, что ZP_ошиб = ZP .
Аналогично рассчитывается количество ошибок в номерах колонок:
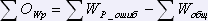 ,
,
где 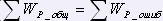 , таких, что WP_ошиб= WP .
, таких, что WP_ошиб= WP .
Расчет количества ошибок в номерах колонок:
 .
.
Для вычисления количества отсутствующих записей и слов используются следующие формулы:
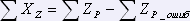 ,
, 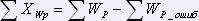 .
.
Результаты расчета (сравнения) ошибок в показании представлены в таблице 1.
| Характеристики сравнения (Количество) |
Введенный текст |
Вычитанный текст |
| Всего записей | 6092 |
6103 |
| Всего неповторяющихся записей | 6078 |
6094 |
| Всего слов | 6092 |
6103 |
| Всего неповторяющихся слов | 6031 |
6049 |
| Одинаковых записей | 5499 |
|
| Одинаковых неповторяющихся записей | 5477 |
|
| Одинаковых слов | 5731 |
|
| Одинаковых неповторяющихся слов | 5571 |
|
| Ошибок в неповторяющихся записях (OZ) | 601 |
|
| Ошибок в неповторяющихся словах (OWp) | 460 |
|
| Ошибок в номерах колонок (OK) | 108 |
|
| Отсутствующих записей (XZ) | 11 |
|
| Отсутствующих слов (XWp) | 11 |
|
| Отсутствующих номеров колонок (XK) | 33 |
|
Таблица 1. Результаты сравнения ошибок в «Показании» САР 1-го тома.
На рис. 2. представлена диаграмма ошибок разных типов. Из диаграммы видно, что большая часть ошибок 75% – ошибки в словах, 18% - ошибки в номерах колонок, 7% - отсутствующих слов и номеров колонок. Ошибки в номерах колонок соответствуют ошибкам в коротких словах.

Рисунок 2. Соотношение количества разных типов ошибок.
Общее количество несоответствий (ошибок) в тексте показания:
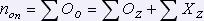 ,
,
это составляет 612 ошибок.
Общий объем текста Показания составляет 46 страниц. Таким образом, среднее количество ошибок на странице составляет 13,3. Если считать, что ошибки распределены равномерно по всему тексту словаря, тогда на одной странице будет встречаться 13 ошибок.
Исследование частотных характеристик слов на малом объеме
Данное исследование проводится с целью определить характер изменения количества новых слов на каждой последующей странице текста.
Исследование проводится на малом объеме текста. Суть исследования состоит в следующем. Рассматриваются 8 первых страниц САР 1-го тома. Каждая последующая страница сравнивается с предыдущими: вторая с первой, третья с первой и второй и т.д. В результате сравнения необходимо определить количественные характеристики слов: общее количество слов на странице; количество разных слов; количество слов, которые встречались ранее и соответственно количество новых слов, также рассматриваются слова, известные и неизвестные компьютеру (входящие и не входящие в словарь спеллера).
Технология проведения исследования следующая. Сначала были взяты тексты первых восьми страниц словаря. Далее они были обработаны в Word: удалены все знаки препинания, все пробелы заменены на знаки абзаца, удалены специфические символы верстки. Целью обработки было создание словника каждой страницы. В результате получилось 8 файлов формата rtf. С помощью программы AndrewTools [Филиппович А.Ю., 2002] были созданы частотные словники каждой страницы и последовательно нескольких страниц (слитые словники). Программа позволяет сохранять словники в виде текстового файла и таблицы Paradox. Далее все расчеты производились вручную. Таблицы частотных словников обрабатывались в Word и осуществлялось их сравнение. Для этого соответствующие слова маркировались цветом, осуществлялась сортировка слов и подсчет. Результаты расчетов и сравнений представлены в таблице 2.
| Характеристики сравнения | 1 стр. | 2 стр. | 3 стр. | 4 стр. | 5 стр. | 6 стр. | 7 стр. | 8 стр. |
Общее количество слов на странице |
228 |
256 |
279 |
268 |
265 |
294 |
276 |
288 |
Общее количество слов известных Word |
108 |
112 |
134 |
135 |
134 |
|
|
|
Общее количество слов не известных Word |
120 |
144 |
145 |
133 |
131 |
|
|
|
Количество разных слов |
188 |
201 |
227 |
211 |
215 |
233 |
222 |
226 |
Количество разных слов известных Word |
88 |
91 |
101 |
99 |
103 |
115 |
113 |
113 |
Количество разных не известных Word |
100 |
110 |
126 |
112 |
112 |
118 |
109 |
113 |
Общее количество ранее встречавшихся на странице слов |
|
51 |
86 |
103 |
101 |
130 |
107 |
125 |
Количество разных слов ранее встречавшихся на странице |
|
24 |
41 |
58 |
56 |
83 |
69 |
78 |
Количество разных слов ранее встречавшихся и известных Word |
|
13 |
26 |
32 |
34 |
46 |
38 |
51 |
Количество разных слов ранее встречавшихся и не известных Word |
|
11 |
15 |
26 |
22 |
37 |
31 |
27 |
Таблица 2. Характеристики слов.
Из таблицы видно, что общее количество слов на каждой странице примерно одинаково. Среднее количество слов составляет: ni_cp = 269 слов. Аналогично среднее количество разных слов npi_cp = 215 слов.
Если в процессе корректуры не пользоваться спеллером, то количество слов, которые просматривает корректор, будет равно общему количеству слов на странице. В среднем это 269 слов.
Приведем соотношение количества слов и разных слов известных и неизвестных Word. Эти соотношения примерно равны для той и другой группы.
Характеристики сравнения |
1стр. |
2 стр. |
3 стр. |
4 стр. |
5 стр. |
6 стр. |
7 стр. |
8 стр. |
Общее количество слов известных Word |
47% |
44% |
48% |
50% |
51% |
|
|
|
Общее количество слов не известных Word |
53% |
56% |
52% |
50% |
49% |
|
|
|
Количество разных слов известных Word |
47% |
45% |
45% |
47% |
48% |
50% |
51% |
50% |
Количество разных слов известных Word |
53% |
55% |
55% |
53% |
52% |
50% |
49% |
50% |
Таблица 3. Соотношение количества слов известных и неизвестных Word.
Если в процессе корректуры рассматривать только слова не известные Word, и не пополнять словарь, то количество сравниваемых слов каждой страницы будет примерно одинаковым и составлять в среднем 112 разных слов на странице. Это около 40% от общего количества.
Приведем все характеристики сравнения в процентном отношении (относительно общего количества слов).
Характеристики сравнения |
1 стр. |
2 стр. |
3 стр. |
4 стр. |
5 стр. |
6 стр. |
7 стр. |
8 стр. |
Общее количество слов на странице |
100% |
100% |
100% |
100% |
100% |
100% |
100% |
100% |
Количество разных слов |
82% |
79% |
81% |
79% |
81% |
79% |
80% |
78% |
Общее количество ранее встречавшихся на странице слов |
|
20% |
31% |
38% |
38% |
44% |
39% |
43% |
Количество разных слов ранее встречавшихся на странице |
|
9% |
15% |
22% |
21% |
28% |
25% |
27% |
Количество разных слов ранее встречавшихся и известных Word |
|
5% |
9% |
12% |
13% |
16% |
14% |
18% |
Количество разных слов ранее встречавшихся и не известных Word |
|
4% |
5% |
10% |
8% |
13% |
11% |
9% |
Количество слов проверяемых корректором |
82% |
70% |
66% |
57% |
60% |
51% |
55% |
51% |
Таблица 4. Характеристики сравнения в процентном соотношении (относительно общего количества слов).
Для наглядности представим графическую модель страниц словаря. Данная модель представляет процесс корректуры с использованием спеллера и динамическим пополнением его словаря.
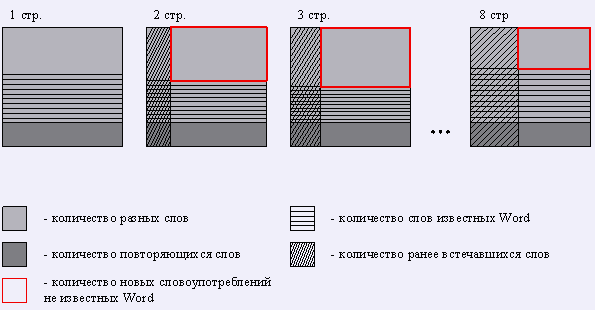
Первая страница содержит множество слов, часть из которых употребляются несколько раз, такие слова будем называть словоупотреблениями. Количество разных слов в среднем составляет около 80% от общего числа. Рассматривая разные слова, можно сказать, что около половины этих слов известны Word. В работе корректора эти слова исключаются из рассмотрения, так как они уже входят в состав словаря спеллера.
На второй странице появляется новая категория слов – слова, которые встречались ранее. Количество этих слов по мере пополнения словаря с каждой последующей страницей растет. Данная группа слов также исключается из рассмотрения, так как эти слова уже входят в состав словаря спеллера. Количество слов проверяемых корректором уменьшается с каждой последующей страницей. Экспериментальный график представлен на рис. 3.
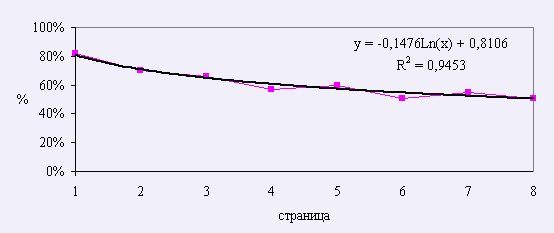
Рисунок 3. Количество слов проверяемых корректором.
Характеристики последней 570-ой страницы следующие:
- общее количество слов на странице: 244 (100%);
- количество разных слов: 190 (78%);
- количество разных слов ранее встречавшихся на странице: 144 (59%).
В итоге процентное количество слов, которые будет проверять корректор, составляет 19%.
В процессе проведения исследования для каждой страницы было выявлено соотношение слов, известных и не известных Word из числа ранее встречавшихся. Эти отношения весьма нестабильны на каждой странице (см. рис. 4.), хотя для общего количества слов и количества разных слов соотношение этих характеристик примерно 50/50 (см. табл.1. 5.).
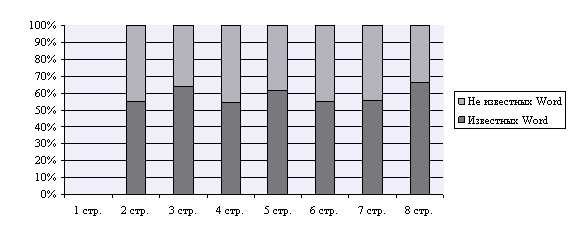
Рисунок 4. Соотношение количества ранее встречавшихся слов известных и не известных Word.
Рассмотрим, какие слова вошли в число неизвестных Word на 8-ой странице из числа тех, что встречались ранее. Большая часть слов – это слова метаязыка – слова, использующиеся для обозначения частей речи, окончания, стилистические пометы и т.п.; а также слова содержащие буквы, не входящие в современный алфавит, например «ять», «фита» и др.; а также слова, использующие старую форму написания, например оканчивающиеся на твердый знак.
Слова, неизвестные Word, распределены по страницам неравномерно, так, например если данная страница описывает слова на букву «ять», то количество неизвестных слов будет больше, чем на других страницах. Однако, несмотря на колебания соотношений известных и неизвестных Word слов из числа ранее встречавшихся, в среднем это соотношение соответствует отношению 50/50 для общего количества слов.
Исследование частотных характеристик слов на большом объеме
С целью уточнения количественных характеристик, полученных в результате исследования на малом объеме текста, было проведено исследование на большом объеме текста.
Суть исследования аналогична предыдущему. Текст САР 1-го тома был разбит на 10 частей – выборок по 54 страницы. Каждая последующая выборка сравнивается с предыдущими: вторая с первой, третья с первой и второй и т.д. В результате сравнения необходимо определить количественные характеристики слов: общее количество слов в выборке; количество разных слов; количество слов, которые встречались ранее и соответственно количество новых слов.
Технология проведения исследования следующая. Текст словаря был разбит на 10 частей – выборок. Далее все тексты выборок были обработаны в Word с помощью замен: были удалены все знаки препинания, все пробелы были заменены на знаки абзаца, были удалены специфические символы верстки. Целью обработки было создание словника каждой выборки. В результате получилось 10 файлов формата rtf. С помощью программы AndrewTools [Филиппович А.Ю., 2002] были созданы таблицы частотные словников каждой выборки и последовательно нескольких выборок (слитые словники). Характеристики словников представлены в Табл. 5, а слитых словников – в табл. 6. Среднее количество слов каждой выборки 15002.
Далее с помощью системы запросов в Paradox осуществлялось сравнение таблиц частотных словников. Согласно модели корректуры необходимо было найти количество слов, ранее встречающихся в предыдущей выборке. Для этого надо найти пересечение множеств этих слов. В исследовании рассматривались словники с учетом регистра и без учета регистра.
Результаты сравнений представлены в табл. 7.
Характеристики сравнения |
Выборки |
|||||||||
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
9 |
10 |
|
Общее количество слов в словнике |
15494 |
14540 |
14626 |
15488 |
14535 |
15485 |
15487 |
14533 |
15406 |
14429 |
Количество разных слов |
7275 |
6642 |
6758 |
7068 |
6208 |
6872 |
7029 |
6523 |
6906 |
6489 |
Количество разных слов без учета регистра |
6788 |
6108 |
6244 |
6567 |
5722 |
6389 |
6529 |
6013 |
6320 |
5966 |
Таблица 5. Характеристики словников.
Характеристики сравнения |
Выборки |
||||||||
1-2 |
1-3 |
1-4 |
1-5 |
1-6 |
1-7 |
1-8 |
1-9 |
1-10 |
|
Общее количество слов в словнике |
|
|
|
|
|
|
|
|
|
Количество разных слов |
12622 |
17584 |
22367 |
26368 |
30328 |
34509 |
38141 |
42057 |
|
Количество разных слов без учета регистра |
11585 |
15989 |
20244 |
23760 |
27240 |
30882 |
33975 |
37282 |
40268 |
Таблица 6. Характеристики слитых словников.
Количество разных слов ранее встречавшихся |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
9 |
10 |
С учетом регистра |
1295 |
1797 |
2287 |
2207 |
2913 |
2849 |
2892 |
2990 |
2950 |
Без учета регистра |
1311 |
1842 |
2314 |
2205 |
2909 |
2889 |
2920 |
3013 |
2980 |
Таблица 7. Количество ранее встречавшихся слов.
Из табл. 7. видно, что количество ранее встречавшихся слов в каждой последующей выборке постоянно растет. На рис. 5. представлен график, иллюстрирующий эту тенденцию.
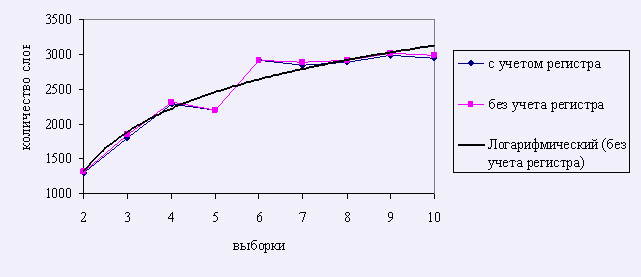
Рисунок 5. Рост количества ранее встречавшихся слов в выборках.
Для возможности сравнения результатов исследования частотных характеристик слов на большом объеме и на малом необходимо представить характеристики сравнения в процентном соотношении (относительно общего количества слов):
Характеристики сравнения |
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
9 |
10 |
Общее количество слов |
15494 |
14540 |
14626 |
15488 |
14535 |
15485 |
15487 |
14533 |
15406 |
14429 |
Количество разных слов |
44% |
42% |
43% |
42% |
39% |
41% |
42% |
41% |
41% |
41% |
Количество разных слов ранее встречавшихся на странице |
|
9% |
13% |
15% |
15% |
19% |
19% |
20% |
20% |
21% |
Количество слов, проверяемых корректором |
44% |
33% |
30% |
27% |
24% |
22% |
23% |
21% |
21% |
20% |
Таблица 8. Характеристики сравнения в процентном соотношении (относительно общего количества слов).

Рисунок 6. Соотношение количества слов, проверяемых корректором (относительно общего количества слов).
В данном исследовании количество слов в выборке значительно выше, чем в исследовании на малом объеме текста. Поэтому количество разных слов в выборке значительно меньше и составляет в среднем примерно 42 % (для сравнения на одной странице текста 80% разных слов).
Поэтому для сравнения экспериментальных графиков приведем характеристики сравнения в процентном соотношении относительно количества разных слов.
Характеристики сравнения |
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
9 |
10 |
На большом объеме слов |
||||||||||
Количество разных слов ранее встречавшихся на странице |
|
21% |
30% |
35% |
39% |
46% |
44% |
49% |
48% |
50% |
Количество слов, проверяемых корректором |
100% |
79% |
70% |
65% |
61% |
54% |
56% |
51% |
52% |
50% |
На малом объеме слов |
||||||||||
Количество разных слов ранее встречавшихся на странице |
|
12% |
18% |
27% |
26% |
36% |
31% |
35% |
|
|
Количество слов, проверяемых корректором |
100% |
88% |
82% |
73% |
74% |
64% |
69% |
65% |
|
|
Таблица 9. Характеристики сравнения в процентном соотношении (относительно количества разных слов).
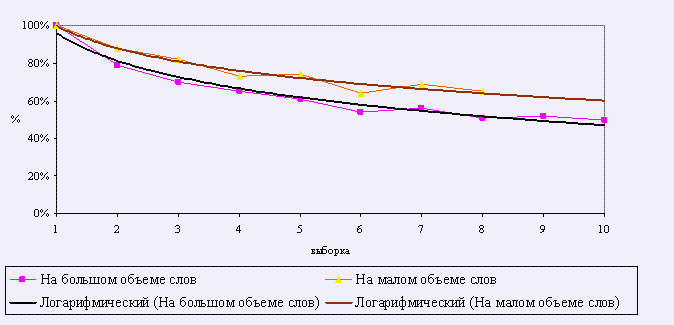
Рисунок 7. Соотношения количества слов, проверяемых корректором (относительно количества разных слов).
Из рис. 7. видно, что характер сравниваемых кривых одинаков. Однако экспериментальная кривая исследования на большом объеме слов проходит ниже. Это связано с тем, что соотношение количества слов на большой выборке меньше в среднем на 10 %.
Заключение
Подведем итоги проведенных исследований технологий корректуры с использованием словаря спеллера и без него.
Время корректуры текста традиционным методом определяется следующим выражением:
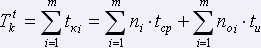 ,
,
где: m – количество страниц всего текста, tki– время корректуры i-ой страницы текста.
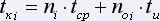 ,
,
где: tcp – время сравнения слова, tu – время исправления ошибки, ni – количество слов на i-ой странице, noi – количество ошибок на i-ой странице.
Согласно проведенному исследованию в САР количество слов ni на каждой странице мало изменяется и составляет в среднем около 269 слов. Считая, что ошибки распределены равномерно, среднее количество ошибок на странице будет равно 13 ( 5%). Время сравнения слова и исправления в нем ошибки неизвестно. Будем считать, что время исправления ошибки в K – раз больше времени сравнения слова, тогда, обозначив время сравнения как t, получим: tcp = t, tu = Kt .
5%). Время сравнения слова и исправления в нем ошибки неизвестно. Будем считать, что время исправления ошибки в K – раз больше времени сравнения слова, тогда, обозначив время сравнения как t, получим: tcp = t, tu = Kt .
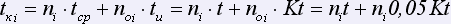 .
.
В итоге для средних значений количества слов и ошибок на странице получим, что
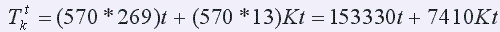 .
.
Время корректуры текста с использованием словаря спеллера определяется следующим выражением:
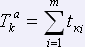 ,
, 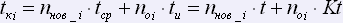 ,
,
где nнов_i – количество новых (неизвестных) слов на i-ой странице.
В результате исследования для первых восьми страниц был получен экспериментальный график изменения количества новых слов – слов, проверяемых корректором, по мере пополнения словаря спеллера. Логарифмическое аппроксимирующее уравнение экспериментальной кривой имеет вид:
y = -0,1476*Ln(x)+0,8106.
Для последующих страниц была применена линейная аппроксимация:
y = -0,000569(x)+0,51.
Иначе:
- для страниц 1-8
количество новых (неизвестных) слов на i-ой странице: nнов_i = -0,1476Ln(i)+0,8106,
время корректуры одной страницы tki = (-0,1476Ln(i)+0,=8106)*t + noi*Kt ; - для страниц 9-570
количество новых (неизвестных) слов на i-ой странице nнов_i = -0,000569(i)+0,51 ,
время корректуры одной страницы tki = (-0,000569Ln(i)+0,51)*t + noi .
Проинтегрировав соответствующие выражения по количеству страниц i, получим время автоматизированной корректуры всего текста:
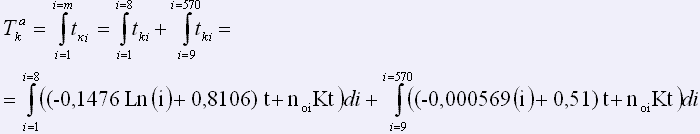 .
.
В итоге получим следующее выражение, при условии одинакового среднего времени на исправление ошибок:
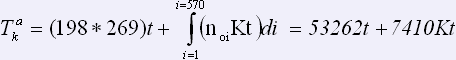 .
.
Сравним полученные результаты, вычислив насколько время автоматизированной корректуры отличается от традиционной по формуле:
 .
.
Сравнения позволяют сделать вывод об эффективности технологий корректуры с использованием словаря спеллера. Оценивая технологии корректуры можно сказать, что в случае использования словаря спеллера количество слов, сравниваемых корректором, уменьшается и по мере пополнения словаря на последней странице достигает ~20% общего объема.
Эффективность той или иной технологии корректуры зависит от соотношения величин времени сравнения слова и времени исправления ошибки. В случае их равенства (коэффициент K=1) суммарный выигрыш времени корректуры может достигнуть 62%, а при К=10 он равен 43%.
Оценивая эти показатели, следует отметить ряд допущений, которые были приняты в формальной модели корректуры. Во-первых, было принято, что ошибки распределены по тексту равномерно, поэтому количество ошибок на каждой странице постоянно. Во-вторых, рассматривались только орфографические ошибки, не рассматривались ошибки пунктуации и связанные с нарушением правил верстки. В данную модель не входят также ошибки в словах, входящих в состав словаря спеллера. Учет этих допущений позволит уточнить предложенную модель корректуры.
Полученные результаты, однако, позволяют рекомендовать технологию корректуры с использованием словаря спеллера применять при первой читке. Для обнаружения всех остальных ошибок целесообразно сохранить традиционную технологию корректуры. Кроме этого для более точной оценки эффективности той или иной технологии корректуры необходимо провести дополнительные исследования времени сравнения слова и времени исправления ошибок. Также необходимо исследовать типы ошибок и количество ошибок, найденных в каждой из трех читок.
Отметим как одно из актуальных исследование возможности повысить эффективность корректуры за счет формирования словаря типовых ошибок для автоматического их исправления. Типовые ошибки могут быть связанны с особенностями графем шрифта AndrewDashkova и процесса их распознавания.
Словарь Академии Российской 1789-1794 гг. называют словарем эпохи Екатерины II. Уже проведенные, а также названные возможные исследования технологии корректуры на примере этого словаря имеют особое практическое значение для выработки методики допечатной подготовки переизданий и других книг конца XVIII начала XIX веков.
Результаты представленного исследования можно применить также и к корректуре текстов, содержащих специфическую лексику. В их числе, например, древнерусские тексты, тексты научных произведений, использующих много специальных терминов и др.
Литература
CLAIM
- научно-образовательный кластер it-claim.ru
Все вопросы и комментарии вы можете отправлять по
адресу: anna@it-claim.ru