![]()
статьи и тезисы |
Среда обработки данных полиязычного ассоциативного эксперимента
Содержание
Славянский ассоциативный словарь
Славянский ассоциативный словарь
В 1998-2000 году по гранту РГНФ 08-06-08139а “Сопоставительное исследование национального языкового сознания славян” сотрудниками Института языкознания РАН проводился ассоциативный эксперимент среди носителей белорусского, болгарского, украинского и русского языков. По результатам этого эксперимента был построен славянский ассоциативный словарь.
Технология ассоциативного эксперимента традиционна. Эксперимент проводится в виде анкетирования, где испытуемому предлагается список слов (как правило, не более 100) из исходного множества слов-стимулов. В славянском ассоциативном словаре исходное множество слов-стимулов (112) совпадает со списком слов анкеты. Испытуемый должен ответить, не задумываясь, на каждое слово-стимул первым приходящим в голову словом или словосочетанием – реакцией. Таким образом, получается множество пар стимул-реакция, которое составляет основу будущего ассоциативного словаря.
Традиционно принято разделять ассоциативный словарь на два типа – прямой и обратный. В прямом словаре входом служит слово-стимул. Соответственно словарная статья прямого словаря строится следующим образом: заголовочное слово – стимул, дефиниция – множество реакций, расположенных по мере убывания их частоты встречаемости среди ответов испытуемых, например, ЖИЗНЬ: смерть 62; прекрасна 30; и т.п. Обычно в конце словарной статьи приводятся количественные показатели: ЖИТЬ... 508+198+3+134; ЧЕРТЕЖ... 109+72+3+55. Первая цифра указывает на общее число реакций на слово-стимул, вторая — на число разных реакций, третья — на число отка¬зов испытуемых и четвертая — на число единичных реакций, то есть на число ответов с частотой 1 [РАС, 2002].
В обратном словаре все наоборот, и в качестве заголовочного слова выступает уже не стимул, а реакция. Дефиниция статьи обратного словаря – это множество слов-стимулов, которые породили эту реакцию, с соответствующими частотами.
В настоящее время существует множество ассоциативных словарей. Первый словарь вербальных ассоциативных норм был опубликован в США 1910 году Кент и Розановым. Список слов-стимулов состоял из слов высокой частотности (100 слов), испытуемые были 1000 человек [Ассоциации, 2002. С. 3]. Один из самых крупных ассоциативных экспериментов в России был предпринят сотрудниками Института русского языка им. В.В. Виноградова РАН и Института языкознания РАН. В ходе массового ассоциативного эксперимента было опрошено 11 тысяч студентов, в основном первых-третьих курсов разнопрофильных вузов из всех регионов России. Родной язык всех испытуемых – русский. Всего было получено более одного миллиона ответов-реакций, содержащих почти 1 млн. 200 тысяч словоупотреблений. В результате обработки собранных материалов получено около 105 тысяч разных словоформ, 30 тысяч различных лексических единиц (слов в основной форме). [РАС, 2002].
В настоящее время все более широкое распространение получают двуязычные ассоциативные словари: русско-французский [Ассоциации, 2002], русско-испанский [Санчес Пуиг, 2001]. Именно материал этих словарей наиболее интересен для изучения особенностей образов мира носителей разных языков и культур. Славянский ассоциативный словарь охватывает целую группу языков: белорусский, болгарский, украинский и русский, что позволяет его назвать полиязычным. Не смотря на это, славянский ассоциативный эксперимент - это сравнительно небольшое исследование: по каждому из четырех исследуемых языков было опрошено порядка 500 человек (мужчины и женщины примерно в равном количестве). [Уфимцева, 2000. С. 209]. К сожалению, славянский ассоциативный словарь не был издан в виде книги и существует только в виде Базы данных.
Обработка данных полиязычного ассоциативного эксперимента сопряжена с определенными трудностями. Поэтому по опыту сотрудников института русского языка и института языкознания можно с уверенностью говорить о необходимости создания специализированной среды обработки данных. Опыт создания подобных программ существует. Так для формирования Русско-французского ассоциативного словаря была создана целая система, позволяющая формировать анкеты и строить тезаурус ассоциативных норм [Ассоциации, 2002]. В рамках проекта «Ведущая научная школа Ю.Н. Караулова, РФФИ № 00-15-98826» была создана электронная версия [РАС, 2002]. То есть необходимость в подобных системах существует.
Хотелось бы отметить некоторые особенности славянского ассоциативного эксперимента, которые явились предпосылками создания электронного славянского ассоциативного словаря (САС).
Во-первых, эксперимент по каждому из языков проводили разные люди. В Белоруссии эксперимент проводила со студентами Белорусского государственного университета (г. Минск) Савицкая Ирина Ивановна. В Болгарии эксперимент со студентами Софийского государственного университета (г. София) проводили Пенка Илиева-Балтова, Андриана Ефтимова, Анна Липовска, Красимира Петрова, Наталия Деренжи. В Украине эксперимент со студентами Нежинского педагогического университета (г. Нежин) проводила Крыга Тамара Ивановна [Уфимцева, 2000. С. 209]. Результатом этого явились некоторые несоответствия выходных данных эксперимента по разным языкам. Кроме этого перевод некоторых слов не однозначен. И для одного и того же слова может быть два эквивалента перевода. Так получилось при формировании списка стимулов болгарского языка. Поэтому в нем 113 слов-стимулов, а не 112 как в остальных языках.
Во-вторых, базы данных словарей по разным языкам работают автономно, т.е. таблиц, связывающих языки нет. Электронных переводных словарей с русского на белорусский, болгарский или украинский языки пока не существует, что тоже осложняет сопоставление.
Другой важной проблемой является то, что все данные по эксперименту записаны в виде таблиц СУБД Paradox, поэтому исследователю необходимо хорошо знать особенности СУБД для составления соответствующих запросов. А исследователями в нашем случае являются специалисты в области языка – лингвисты, которые зачастую не владеют в совершенстве этим инструментом.
Обобщая все вышеперечисленное, хотелось бы отметить цели, которые были поставлены при проектировании САС. Необходимо было систематизировать данные по эксперименту, связать вместе словари по разным языкам и создать достаточно простую среду обработки данных по ассоциативному эксперименту, которая позволила бы пользователю осуществлять поиск и фильтрацию данных без составления запросов или использования SQL языка.
Функциональная модель
Как показал опыт создания электронной версии РАС, одной из главных функциональных задач электронного ассоциативного словаря является организация эффективного поиска и фильтрации данных. Основные категории поиска соответствуют трем характеристикам словаря: стимул, реакция и частота соответственно в прямом и обратном словаре. Исходя из этого, был выявлен минимальный состав функций САС:
Состав функций:
- Вывод таблиц прямого словаря по русскому, белорусскому, украинскому и болгарскому языкам;
- Вывод таблиц обратного словаря по русскому, белорусскому, украинскому и болгарскому языкам;
- Поиск по выбранному слову-стимулу и диапазону частот в прямом словаре русского, белорусского, украинского и болгарского языках;
- Поиск по введенному слову-реакции и диапазону частот в обратном словаре русского, белорусского, украинского и болгарского языках;
- Вывод списка слов-стимулов для русского, белорусского, украинского и болгарского языков;
Загрузка словарей
Исходные данные по славянскому ассоциативному эксперименту представлены в виде таблиц Paradox. Для системы САС были использованы только таблицы прямых словарей белорусского (PR_BEL1), болгарского (PR_BOL1), украинского (PR_UKR1) и русского (PR_RUS1) языков. Структура таблиц одинакова для всех языков:
Имя поля |
Тип данных |
Stimul |
Строка - A(16) |
Reak |
Строка - A (32) |
Chastota |
Целое число - S |
Программа САС была написана на языке Borland Delphi 6. Выбор среды программирования обусловлен тем, что Borland Paradox тесно интегрирован с Delphi и не требует дополнительных средств связи.
Для загрузки прямых словарей использовались SQL запросы. Так как структура таблиц одинакова для всех языков, то и методы загрузки не отличаются друг от друга. В качестве примера приведен фрагмент кода для загрузки прямого белорусского словаря:
{вывод таблицы прямого белорусского словаря}
Query1.Active:= False;
Query1.SQL.Clear; {очистка поля запросов}
Query1.SQL.Add('select *');
Query1.SQL.Add('from Pr_bel1.db');
Query1.Active:= True;
Традиционно исследователями используется обратный словарь. Он характеризует обратную связь между словами-стимулами и словами-реакциями [Филиппович, 2001]. Но отдельно хранить обратный словарь не целесообразно, так как фактически он полностью повторяет прямой. Поэтому эта функция была реализована программно. Для формирования обратного словаря необходимо отсортировать поля таблицы прямого словаря следующим образом:
Прямой словарь |
Обратный словарь |
|||||
№ |
Имя поля |
Сортировка |
№ |
Имя поля |
Сортировка |
|
1 |
Stimul |
По возрастанию |
|
1 |
Reak |
По возрастанию |
2 |
Chastota |
По убыванию |
|
2 |
Chastota |
По убыванию |
3 |
Reak |
По возрастанию |
|
3 |
Stimul |
По возрастанию |
В качестве примера приведен фрагмент кода для загрузки обратного белорусского словаря:
Query1.Active:= False;
Query1.SQL.Clear; {очистка поля запросов}
Query1.SQL.Add('select Reak,Stimul,Chastota'); {выбрать все поля из таблицы Pr_bel}
Query1.SQL.Add('from Pr_bel1.db');
Query1.SQL.Add('order by Reak asc, Chastota desc, Stimul asc');
Query1.Active:=True;
Организация поиска
Основной функцией САС является поиск и фильтрация данных. В прямом словаре поиск осуществляется по выбранному слову-стимулу и диапазону частот. Для формирования списка слов-стимулов были использованы стандартные методы построения запросов в Paradox.
Таким образом, были получены таблицы стимулов для каждого из языков, которые были импортированы в текстовый формат. Во всех языках количество стимулов составило 112, кроме белорусского – 113.
В качестве примера представлен фрагмент кода для процедуры поиска в прямом болгарском словаре:
{поиск по прямому болгарскому словарю} Query3.Active:=False; Query3.SQL.Clear; {очистка поля запросов} Query3.SQL.Add('select Stimul,Reak,Chastota'); {выбрать все поля из таблицы Pr_bel} Query3.SQL.Add('from Pr_Bol1.db');
{проверка поля стимул} if CBoxUkr.text<>'all' then Query3.SQL.Add('Where Stimul='''+CBoxBol.text+'''') else Query3.SQL.Add('Where Stimul like''%''');
{проверка полей частоты} if (Edit1.text<>'') and (Edit2.text='') then Query3.SQL.Add('and Chastota>='''+Edit1.text+''''); if (Edit2.text<>'') and (Edit1.text='') then Query3.SQL.Add('and Chastota<='''+Edit2.text+''''); if (Edit2.text<>'') and (Edit1.text<>'') then begin Query3.SQL.Add('and Chastota>='''+Edit1.text+''''); Query3.SQL.Add('and Chastota<='''+Edit2.text+''''); end; Query3.Active:=True; |
Процедура поиска в обратном словаре аналогична процедуре поиска в прямом. Только в качестве условий поиска выступает соответственно не стимул, а реакция. Множество слов-реакций существенно больше множества слов стимулов: в болгарском словаре – 11737 слов, в белорусском – 13829, в украинском – 9344 и в русском – 10084. Поэтому не целесообразно хранить список реакций отдельно и пользователь сам вводит нужное ему слово в поле реакция.
Проектирование интерфейса
Проектирование интерфейса имеет множество аспектов, это касается в первую очередь восприятия человека: эргономических характеристик, вопросов эстетики и т.д. Но эти вопросы не будут рассмотрены, так как относятся к другой научной области и будут выбиваться из общей тематики статьи. Принципиальной проблемой, которая встает перед программистом при проектировании нестандартного интерфейса – это вопросы скорости работы программы. При работе с большими объемами данных – БД, содержащими несколько миллионов записей, проблема загромождения памяти встает очень остро. Конечно БД славянских ассоциативных норм, как уже отмечалось ранее, сравнительно не велика, но форма САС содержат до 50 различных изображений. В связи с этим программа работает медленно. Некоторые приемы позволили значительно улучшить скорость выполнения запросов. Во-первых, наилучшим выбором формата изображений является формат jpg. Во-вторых, при создании формы используется процедура, позволяющая удвоить объем памяти, который оперативно используется программой (Doublebuffered:= true).
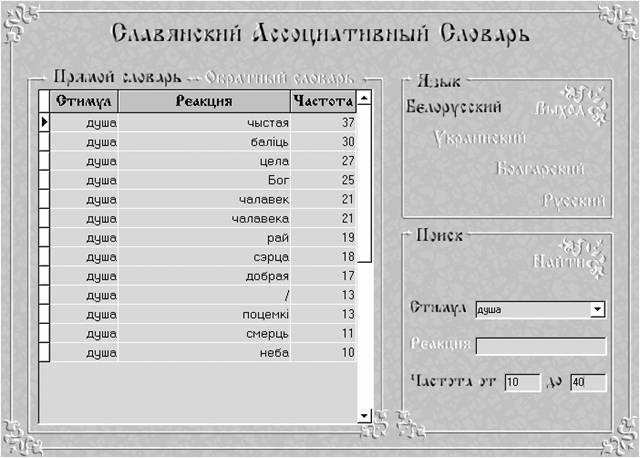
Форма прямого белорусского словаря: поиск по значению стимула (душа) и диапазону частоты (10-40).
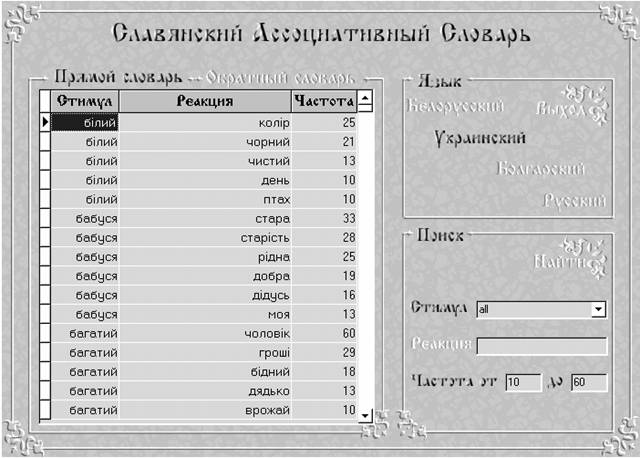
Форма прямого украинского словаря: поиск по диапазону частоты (10-60).
В заключение хотелось бы отметить, что в данной статье представлены первые результаты работы САС. Были реализованы поиск и фильтрация данных по введенным значениям слов и диапазоне частот. Вообще данные по эксперименту более обширны. Анкета испытуемого содержит информацию о поле (мужской или женский), возрасте и специальности. Славянский ассоциативный эксперимент проводился среди учащихся 11 наиболее распространенных университетских специальностей: математики, физики, химики, биологи, экономисты, философы (богословы), психологи, юристы, журналисты, педагоги [Уфимцева, 2000. С. 206]. Эти данные могут быть условиями поиска. Кроме этого проблема связи таблиц разных языков не была решена. Это связано с тем, что номера слов-стимулов были перепутаны, поэтому оказалось, что стимулы с одинаковыми номерами не соответствуют друг другу (не являются переводом друг в друга). Поэтому в САС словари работают автономно.
Литература
Русский ассоциативный словарь. В 2 т. Т. 1 . От стимула к реакции: Ок. 7000 стимулов / Ю.Н.Караулов, Г.А.Черкасова, Н.В.Уфимцева, Ю.А.Сорокин, Е.Ф.Тарасов. – М.:ООО «Издательство Астрель»: ООО «Издательство АСТ», 2002. - 784 с. |
|
Филиппович А.Ю. Электронный ассоциативный словарь английского языка /Проблемы построения и эксплуатации систем обработки информации и управления |
|
Языковое сознание и образ мира. Сборник статей /Отв. ред. Н.В. Уфимцева. – М., 2000. – 320 с. |
|
Филиппович Ю.Н. Черкасова Г.А. Дельфт Д. Ассоциации информационных технологий: эксперимент на русском и французском языках. С предисловием Н.В. Уфимцевой – М.: МГУП, 2002. – 304 с. |
|
М. Санчес Пуиг, Ю.Н. Караулов, Г.А. Черкасова. Ассоциативные нормы испанского и русского языков. Москва-Мадрид: «Азбуковник», 2001. – 496 с. |
CLAIM
- научно-образовательный кластер it-claim.ru
Все вопросы и комментарии вы можете отправлять по
адресу: anna@it-claim.ru