![]()
статьи и тезисы |
Электронный ассоциативный словарь английского языка (1)
Содержание
Создание и ведение базы данных
Введение
Данная статья посвящена созданию электронной версии ассоциативного словаря английского языка (тезаурус Киша) [1]. Этот словарь — один из первых словарей такого рода. Он был создан в начале 70-х годов. Для его создания использовалась ЭВМ третьего поколения IBM 360. Этот словарь так и не был издан в виде книги, но в середине 90-х он в виде текста был опубликован в сети Internet . Это позволило использовать его в научных исследованиях в области лексикографии, лексической семантики, лингвистики, социологии, информатики, психиатрии и других областях современной науки.
Ассоциативные словари считаются словарями дескриптивного, т.е. описательного, а не нормирующего/предписывающего типа. По своей структуре они однотипны и представляют собой набор словарных статей, расположенных по алфавиту. Ассоциативная словарная статья стандартна: вслед за стимулом (заголовочным словом) даются реакции-ответы в порядке убывания их частотности [2]. Технология создания ассоциативных словарей и проведения экспериментов описаны в литературе [3]. Наиболее известным является ассоциативный эксперимент, проведенный коллективом ученых институтов русского языка и языкознания РАН в период с 1988–1998 гг. под руководством чл. корр. РАН Ю.Н.Караулова.
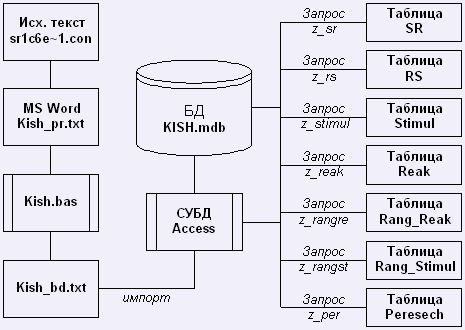
Для создания электронной версии ассоциативного словаря английского языка на первом этапе необходимо формирование его базы данных, то есть набора необходимых таблиц, запросов. Так как исходные данные были представлены в виде текстовых файлов, то при разработке БД словаря необходимо было решить две задачи: а) подготовка исходных данных и б) создание и ведение самой базы данных. Описание процесса создания ассоциативного словаря и его архитектура представлена в Схеме 1.
Подготовка исходных данных
Исходные данные «Ассоциативного словаря английского языка» представляли собой набор текстовых (DOS(*.txt) )файлов, включающих в себя распечатки как прямого, так и обратного словаря. В качестве первоисточника базы данных было решено взять текст прямого словаря. Текстовый файл ( sr1c6e~1.con), объемом 2.849.449 Байт содержал 8213 словарных статей, каждая из которых имела следующую структуру:
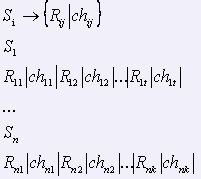
где S — слово-стимул; R — слово-реакция; ch — частота.
Пример:
MEN
WOMEN|72|WOMAN|5|FACES|2|MALE|2|WORK|2|
BEARDS|1|BOGS|1|BOYS|1|CLUBS|1|CROWD|1|LOVE|1|
MATES|1|NOCOMMENT|1|PEOPLE|1|REALITY|1|
RICHARD|1|SANITY|1|SEX|1|STRENGTH|1|TELL|1|YES|1|
Исходный текстовый файл ( sr1c6e~1.con) был загружен в MS Word. Необходимо было отделить слова-реакции друг от друга. С помощью операций замены ( «|число|» «|число|
«|число|  ») искомый файл был преобразован в Kish_pr.txt, структура которого имеет следующий вид:
») искомый файл был преобразован в Kish_pr.txt, структура которого имеет следующий вид:
MEN
WOMEN|72|
WOMAN|5|
FACES|2|
MALE|2|
WORK|2|
......
YES|1|
Используя язык BASIC была написана программа преобразования текстового файла Kish_pr.txt к виду, представленному далее. Результатом работы программы стал файл Kish_bd.txt
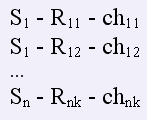
Пример:
MEN;WOMEN;72
MEN;WOMAN;5
MEN;FACES;2
MEN;MALE;2
....
MEN;YES;1
Создание и ведение базы данных
Для загрузки преобразованного текста словаря в БД была использована встроенная функция СУБД Access «импортирование текстовых файлов». Таким образом, была получена таблица первоисточник ( KISH).
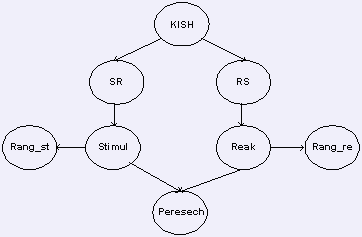
Схема 2. Граф-схема построения запросов
С помощью системы запросов, структура которых представлена в Таблице 1 были получены другие основные таблицы БД: «Стимул-реакция» «Реакция-Стимул», «Стимул», «Реакция», «Ранжирование стимулов», «Ранжирование реакций», «Пересечение». Механизм построения таблиц БД с помощью системы запросов описан в Схеме 2.
| Запрос | Таблицы | Поля | Сортировка | Групповые операции | Условия отбора | Таблица-результат |
| z_sr | KISH | Стимул | по возрастанию |
|
|
sr |
| Частота | по убыванию |
|
|
|||
| Реакция | по возрастанию |
|
|
|||
| z_rs | KISH | Реакция | по возрастанию |
|
|
rs |
| Частота | по убыванию |
|
|
|||
| Стимул | по возрастанию |
|
|
|||
| z_stimul | sr | Стимул | по возрастанию | группировка |
|
stimul |
| z_reak | rs | Реакция | по возрастанию | группировка |
|
reak |
| z_rangst | sr | Стимул |
|
группировка |
|
rang_stimul |
| Частота |
|
sum |
|
|||
| Реакция |
|
count |
|
|||
| z_rangre | rs | Реакция |
|
группировка |
|
rang_reak |
| Частота |
|
sum |
|
|||
| Стимул |
|
count |
|
|||
| z_per | stimul | Стимул |
|
|
[reak].[реакция] | peresech |
| reak |
|
|
|
|
Таблица 1. Структура запросов
На первый взгляд все таблицы БД выглядят одинаково. Но каждая из них имеет свои особенности. Для изучения ассоциативного словаря важную роль играют различные частотные, количественные характеристики. Главная роль в формировании большинства таблиц БД принадлежит процессу сортировки. Рассмотрим все таблицы по отдельности.
Таблица прямого словаря «Стимул-реакция» ( SR) характеризует прямую связь между словами стимулами и словами-реакциями. Она имеет три поля: стимул, реакция частота (структура аналогична структуре файла Kish_bd.txt который стал первоисточником БД).
Таблица обратного словаря «Реакция-Стимул» ( RS характеризует обратную связь между словами-стимулами и словами-реакциями. Говоря другими словами, каждой реакции соответствует множество слов-стимулов, которые ее породили:
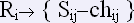
Установив взаимнооднозначное соответствие, получаем множество реакций и соответствующих стимулов с частотами следующего вида:
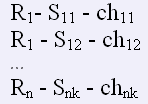
Для изучения ассоциативно-вербальной сети необходимо иметь не только данные прямого и обратного словарей, характеризующие связи между стимулами и реакциями, но и перечень всех стимулов и реакций. Это важно для сопоставления этих данных. Перечень всех слов-стимулов содержится в таблице «Стимул» ( stimul). Математически структура таблицы выглядит,как ![]() , где i = 1,n.
, где i = 1,n.
Таблица «Реакция» (reak) содержит перечень всех слов-реакций словаря. Структуру таблицы можно описать, как 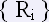 где i = 1,n.
где i = 1,n.
Рассматривая множества всех слов-стимулов и слов-реакций, можно найти те слова, которые являются одновременно и стимулами и реакциями. Таким образом, можно найти пересечение множества стимулов и множества реакций. Именно эта задача была поставлена при создании таблицы «Пересечение» (peresech).
Таблица «Ранжирование стимулов» (rang_stimul) содержит частотные и количественные характеристики для слов-стимулов. Она состоит из трех полей: стимул, суммарная частота и количество реакций. Поле «суммарная частота» позволяет определить общее количество ответов на данный стимул, а поле «количество реакций» — количество разных ответов. Математически структуру данной таблицы можно записать следующим образом.
Если структура прямого словаря это:
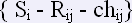
где i = 1,n j = 1,m.
то структура таблицы «Ранжирование стимулов»:
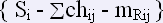
Таблица «Ранжирование реакций» ( (rang_reak) аналогична таблице «Ранжирование стимулов» и содержит частотные и количественные характеристики для слов-реакций. Она состоит из трех полей: реакция, суммарная частота и количество стимулов. Поле «суммарная частота» позволяет определить общее количество слов стимулов, вызвавших эту реакцию, а поле «количество стимулов» — количество разных стимулов. Структуру данной таблицы можно записать следующим образом.
Если структура обратного словаря это:
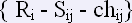
то структура таблицы «Ранжирование реакций»:
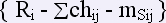
Кроме ассоциативного словаря английского языка существует множество ассоциативных словарей других языков: русский, украинский, латышский и другие. Поэтому в будущем предполагается использовать «словарь Киша» для сопоставительного анализа различных языков и, следовательно, закономерностей формирования языкового сознания людей в различных частях света. Кроме этого на базе словарей такого рода возможно создание программ обучения различным языкам, а также систем ассоциативного поиска и перевода.
Литература
| Associative Thesaurus of English, Kiss & all, 1972. | |
| Русский ассоциативный словарь. Книга 1. Прямой словарь: от стимула к реакции. Ассоциативный тезаурус современного русского языка. Часть 1. / Ю.Н.Караулов, Ю.А.Сорокин, Е.Ф.Тарасов, Н.В.Уфимцева, Г.А.Черкасова. М.: «Памовский и партнеры», 1994. | |
| Г.А.Черкасова. Русский ассоциативный тезаурус: компьютерная технология создания и издания // Этнокультурная специфика языкового сознания / Отв. ред. Н.В.Уфимцева. М.: 1996. С.181–190. |
[1] Статья написана в рамках курсовой работы по дисциплине «Информатика» на кафедре «Системы обработки информации и управления» МГТУ им.Н.Э.Баумана, руководитель — доцент Г.И.Ревунков, консультант — научный сотрудник Института языкознания РАН Г.А.Черкасова.
CLAIM
- научно-образовательный кластер it-claim.ru
Все вопросы и комментарии вы можете отправлять по
адресу: anna@it-claim.ru